给定公司名称excel列表,在天眼查搜索爬取企业工商信息(改进1) |
您所在的位置:网站首页 › 天眼查如何批量导入企业信息 › 给定公司名称excel列表,在天眼查搜索爬取企业工商信息(改进1) |
给定公司名称excel列表,在天眼查搜索爬取企业工商信息(改进1)
|
上一篇写了天眼查公司详情页单页面爬取公司基本信息(https://ask.hellobi.com/blog/jasmine3happy/6200),这里改进一步。 需求提供公司名称,需要获取公司工商注册信息,欲查找的公司名称存储在excel里。 步骤分解1.读取excel数据(1)打开工作簿 import xlrd def open_excel(file): try: book = xlrd.open_workbook(file) return book except Exception as e: print ('打开工作簿'+file+'出错:'+str(e))(2)读取工作簿中所有工作表 def read_sheets(file): try: book = open_excel(file) sheets = book.sheets() return sheets except Exception as e: print ('读取工作表出错:'+str(e))(3)读取某一工作表中数据某一列的数据 def read_data(sheet, n=0): dataset = [] for r in range(sheet.nrows): col = sheet.cell(r, n).value dataset.append(col) return dataset2.打开浏览器因为是采用selenium+浏览器,首先先打开浏览器(可用火狐、谷歌等浏览器,只要配置好环境),这里采用了phantomjs这个无头浏览器,并使用了useragent代理。此外,service_args参数可调用ip代理。 from selenium import webdriver from selenium.webdriver.common.desired_capabilities import DesiredCapabilities def driver_open(): dcap = dict(DesiredCapabilities.PHANTOMJS) dcap["phantomjs.page.settings.userAgent"] = ( "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36" ) service_args = [ '--proxy=122.228.179.178:80', '--proxy-type=http' ] open_driver = webdriver.PhantomJS(executable_path='D:/Anaconda2/phantomjs.exe', desired_capabilities=dcap # , service_args=service_args # ip代理 ) return open_driver3.获取网页源代码根据提供的url和等待加载时间,返回网页源码的BeautifulSoup对象。 欲获取源代码的网页url有两种类型,一种是搜索结果页面的url,一种是公司详情页的url。根据分析,公司详情页的url末尾是一串数字,表示公司的id,这个id是要保存下来,作为唯一识别码,因此增加一步判断,判断url是否为公司详情页的url(最后一个'/'后面全是数字), 如果是,同时返回公司的id。 import time from bs4 import BeautifulSoup def get_content(url, waiting=3): open_driver = driver_open() open_driver.get(url) # 等待waiting秒,使js加载,时间可延长 time.sleep(waiting) # 获取网页内容 content = open_driver.page_source.encode('utf-8') print content open_driver.close() res_soup = BeautifulSoup(content, 'lxml') com_id = url.split('/')[-1] if com_id.isdigit(): return res_soup, com_id else: return res_soup4.根据搜索词搜索如果输入的公司名,能查到完全对应的公司名(可能是曾用名),则返回其url地址, 如果不存在,则返回空。 import urllib def search(keyname): key = urllib.quote(keyname) search_url = 'http://www.tianyancha.com/search?key=' + key + '&checkFrom=searchBox' # print search_url res_soup = get_content(search_url) # print res_soup # 解析搜索结果的第一个记录 ifname = res_soup.select('div.search_result_single > div.row > div > a > span') name = ifname[0].text if len(ifname) > 0 else None ifcym = res_soup.find_all(attrs={"ng-bind-html": "node.historyNames"}) cym = ifcym[0].text if len(ifcym) > 0 else None if name == keyname or cym == keyname: company_url = res_soup.select('div.search_result_single > div.row > div > a ')[0].get('href') return company_url else: # print "不存在该公司" return5.公司详情页数据获取并存储(1)在数据库中建表 首先分析要获取哪些数据,并设计好表,我这里共涉及3张表(采用mysql)。 其一,基础信息 CREATE TABLE `tianyancha_qyjc` ( `id` int(11) NOT NULL AUTO_INCREMENT, `nbxh` varchar(20) DEFAULT NULL comment 't+天眼查上公司id', `qymc` varchar(50) DEFAULT NULL comment '企业名称', `qyzch` varchar(20) DEFAULT NULL comment '工商注册号', `fddbr` varchar(50) DEFAULT NULL comment '法定代表人', `qylx` varchar(50) DEFAULT NULL comment '企业类型', `zt` varchar(20) DEFAULT NULL comment '状态', `zczb` varchar(50) DEFAULT NULL comment '注册资本', `zs` varchar(100) DEFAULT NULL comment '注册地址', `jyfw` varchar(1000) DEFAULT NULL comment '经营范围', `gxdw` varchar(50) DEFAULT NULL comment '登记机构', `xkksrq` varchar(12) DEFAULT NULL comment '营业开始时间', `xkjsrq` varchar(20) DEFAULT NULL comment '营业结束时间', `slrq` varchar(20) DEFAULT NULL comment '注册日期', `hy` varchar(50) DEFAULT NULL comment '行业', `zzjgdm` varchar(20) DEFAULT NULL comment '组织机构代码', `hzrq` varchar(20) DEFAULT NULL comment '核准日期', `tyshxydm` varchar(20) DEFAULT NULL comment '统一社会信用代码', `cym` varchar(50) DEFAULT NULL comment '曾用名', `rksj` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP comment '获取时间', PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8;其二,高管信息 CREATE TABLE `tianyancha_gg` ( `id` int(11) NOT NULL AUTO_INCREMENT, `nbxh` varchar(20) DEFAULT NULL comment 't+天眼查上公司id', `xm` varchar(20) DEFAULT NULL comment '姓名', `zw` varchar(30) DEFAULT NULL comment '职务', `rksj` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP comment '获取时间', PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8;其三,投资信息(包含股东和对外投资) CREATE TABLE `tianyancha_tzf` ( `id` int(11) NOT NULL AUTO_INCREMENT, `nbxh` varchar(20) DEFAULT NULL comment 't+天眼查上投资方公司id,如果股东为自然人,则为空', `xm` varchar(50) DEFAULT NULL comment '姓名/企业名称', `btzfnbxh` varchar(20) DEFAULT NULL comment 't+天眼查上被投资公司id', `rksj` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP comment '获取时间', PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8;(2)连接mysql数据库,写插入数据函数 import MySQLdb conn = MySQLdb.connect(host='localhost', port=3306, db='test', user='root', passwd='admin23', charset='utf8') def insert_data(sql, datas): cursor = conn.cursor() cursor.execute(sql, datas) cursor.close() conn.commit()(3)获取基础信息,并插入数据库表“tianyancha_qyjc” 根据提供的网页源码BeautifulSoup对象和公司id,返回基础信息。 def get_basic_info(res_soup, com_id): company = res_soup.select('div.company_info_text > p.ng-binding')[0].text.replace("\n", "").replace(" ", "") cym = company.split('曾用名:')[-1] if "曾用名:" in company else None qymc = company.split('曾用名:')[0] # 企业名称 fddbr = res_soup.select('.td-legalPersonName-value > p > a')[0].text # 法定代表人 zczb = res_soup.select('.td-regCapital-value > p ')[0].text # 注册资本 zt = res_soup.select('.td-regStatus-value > p ')[0].text.replace("\n", "").replace(" ", "") # 状态 slrq = res_soup.select('.td-regTime-value > p ')[0].text # 注册日期 basics = res_soup.select('.basic-td > .c8 > .ng-binding ') hy = basics[0].text # 行业 qyzch = basics[1].text # 工商注册号 qylx = basics[2].text # 企业类型 zzjgdm = basics[3].text # 组织机构代码 yyqx = basics[4].text # 营业期限 xkksrq = yyqx.split('至')[0] # 营业开始日期 xkjsrq = yyqx.split('至')[1] # 营业结束日期 gxdw = basics[5].text # 登记机构 hzrq = basics[6].text # 核准日期 tyshxydm = basics[7].text # 统一社会信用代码 zs = basics[8].text # 注册地址 jyfw = basics[9].text # 经营范围 # 内部序号为t+公司id datas = ('t'+str(com_id), qymc, qyzch, fddbr, qylx, zt, zczb, zs, jyfw, gxdw, xkksrq, xkjsrq, slrq, hy, zzjgdm, hzrq, tyshxydm, cym) sql = '''INSERT INTO tianyancha_qyjc(nbxh, qymc,qyzch,fddbr,qylx,zt,zczb,zs,jyfw,gxdw,xkksrq,xkjsrq,slrq,hy,zzjgdm,hzrq,tyshxydm,cym) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)''' insert_data(sql, datas)(4)获取高管信息,并插入数据库表“tianyancha_gg” 根据提供的网页源码BeautifulSoup对象和公司id,返回高管信息。 def get_gg_info(res_soup, com_id): ggpersons = res_soup.find_all(attrs={"event-name": "company-detail-staff"}) ggnames = res_soup.select('table.staff-table > tbody > tr > td.ng-scope > span.ng-binding') for i in range(len(ggpersons)): xm = ggpersons[i].text # 高管姓名 zw = ggnames[i].text # 高管职务 datas = ('t'+str(com_id), xm, zw) sql = '''INSERT INTO tianyancha_gg(nbxh,xm,zw) values(%s,%s,%s)''' insert_data(sql, datas)(5)获取股东信息,并插入数据库表“tianyancha_tzf” 根据提供的网页源码BeautifulSoup对象和公司id,返回股东信息。 def get_gd_info(res_soup, com_id): tzfs = res_soup.find_all(attrs={"event-name": "company-detail-investment"}) for i in range(len(tzfs)): tzf_split = tzfs[i].text.replace("\n", "").split() tzf = ' '.join(tzf_split) # 投资方名称 tzf_id = tzfs[i].get('href').split('/')[-1] # 投资方url末尾记为tzf_id # 如果tzf_id全是数字,则认为是法人,否则为自然人 if tzf_id.isdigit(): datas = ('t'+str(tzf_id), tzf, 't'+str(com_id)) else: datas = (None, tzf, 't'+str(com_id)) sql = '''INSERT INTO tianyancha_tzf(nbxh,xm,btzfnbxh) values(%s,%s,%s)''' insert_data(sql, datas)(6)获取对外投资信息,并插入数据库表“tianyancha_tzf” 根据提供的网页源码BeautifulSoup对象和公司id,返回对外投资信息。 def get_tz_info(res_soup, com_id): btzs = res_soup.select('a.query_name') for i in range(len(btzs)): btz_name = btzs[i].select('span')[0].text # 被投资方法人名称 btz_id = btzs[i].get('href').split('/')[-1] # 被投资方法人id datas = ('t'+str(com_id), btz_name, 't'+str(btz_id)) sql = '''INSERT INTO tianyancha_tzf(nbxh,xm,btzfnbxh) values(%s,%s,%s)''' insert_data(sql, datas)6.输出查询失败的日志将查询失败的企业名称company_name记入日志文件logfile def write_into(logfile, company_name): with open(logfile, 'a') as f: f.write(company_name+'\n')7.主函数logfile为存储查询失败的日志文件,company_file为欲查询的公司名单的excel文件。 def main(logfile, company_file): now = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())) with open(logfile, 'a') as f: f.write('\n当前时间:' + now + '\n') sheets = read_sheets(company_file) cornames = [] for sheet in sheets: dataset = read_data(sheet) cornames.extend(dataset) for i in range(len(cornames)): url = search(cornames[i].encode("utf-8")) if url: soup, company_id = get_content(url) get_basic_info(soup, company_id) get_gg_info(soup, company_id) get_gd_info(soup, company_id) get_tz_info(soup, company_id) print '查询成功。' else: print cornames[i] + ' 查询失败。' write_into(logfile, cornames[i])8.调用主函数if __name__ == '__main__': logfile = 'failed_log.txt' filename = 'D:\\Users\\Administrator\\Desktop\\qymc.xlsx' main(logfile, filename)测试数据:
结果: 基础信息
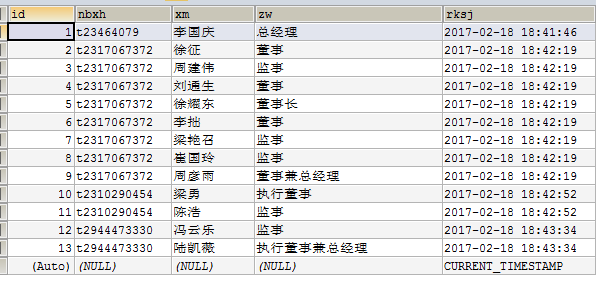
高管信息
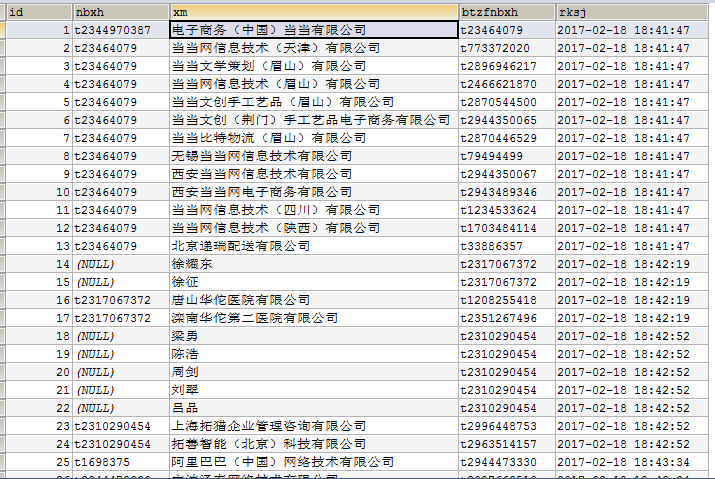
投资信息
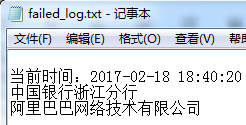
查询失败日志
这一篇比上一篇改进的地方是提供了搜索的入口,将查询结果存储下来,并输出查询失败的日志。 还需改进的地方: (1)ip代理虽然可以调用,但没有解决ip失效的问题。 (2)调用selenium和phantomjs缓慢,可以采用分布式。 还有不到之处,欢迎各位大牛指点。 |


【本文地址】