数据挖掘机器学习[七] |
您所在的位置:网站首页 › 天气预测数学模型图 › 数据挖掘机器学习[七] |
数据挖掘机器学习[七]
|
2021年中国研究生数学建模竞赛B题:空气质量预报二次建模 大气污染系指由于人类活动或自然过程引起某些物质进入大气中,呈现足够的浓度,达到了足够的时间,并因此危害了人体的舒适、健康和福利或危害了生态环境[1]。污染防治实践表明,建立空气质量预报模型,提前获知可能发生的大气污染过程并采取相应控制措施,是减少大气污染对人体健康和环境等造成的危害,提高环境空气质量的有效方法之一。 目前常用WRF-CMAQ模拟体系(以下简称WRF-CMAQ模型)对空气质量进行预报。WRF-CMAQ模型主要包括WRF和CMAQ两部分:WRF是一种中尺度数值天气预报系统,用于为CMAQ提供所需的气象场数据;CMAQ是一种三维欧拉大气化学与传输模拟系统,其根据来自WRF的气象信息及场域内的污染排放清单,基于物理和化学反应原理模拟污染物等的变化过程,继而得到具体时间点或时间段的预报结果。WRF和CMAQ的结构如图 1、图 2所示,详细介绍可以在附录提供的官网中进行查询 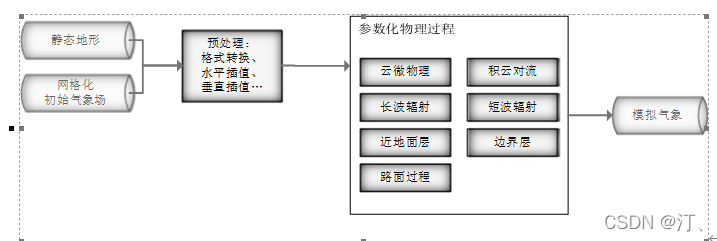 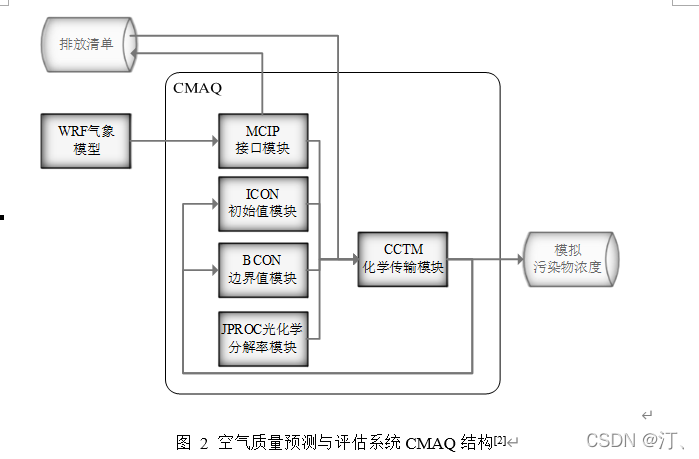 但受制于模拟的气象场以及排放清单的不确定性,以及对包括臭氧在内的污染物生成机理的不完全明晰,WRF-CMAQ预报模型的结果并不理想。故题目提出二次建模概念:即指在WRF-CMAQ等一次预报模型模拟结果的基础上,结合更多的数据源进行再建模,以提高预报的准确性。其中,由于实际气象条件对空气质量影响很大(例如湿度降低有利于臭氧的生成),且污染物浓度实测数据的变化情况对空气质量预报具有一定参考价值,故目前会参考空气质量监测点获得的气象与污染物数据进行二次建模,以优化预报模型。二次模型与WRF-CMAQ模型关系如图 3所示。为便于理解,下文将WRF-CMAQ模型运行产生的数据简称为“一次预报数据”,将空气质量监测站点实际监测得到的数据简称为“实测数据”。一般来说,一次预报数据与实测数据相关性不高,但预报过程中常会使用实测数据对一次预报数据进行修正以达到更好的效果。 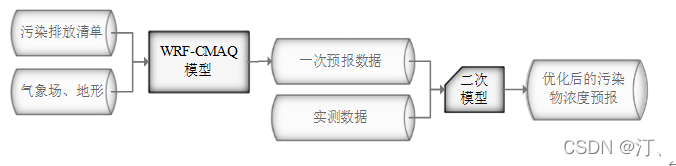 问题1. 使用附件1中的数据,按照附录中的方法计算监测点A从2020年8月25日到8月28日每天实测的AQI和首要污染物,将结果按照附录“AQI计算结果表”的格式放在正文中。 问题2. 在污染物排放情况不变的条件下,某一地区的气象条件有利于污染物扩散或沉降时,该地区的AQI会下降,反之会上升。使用附件1中的数据,根据对污染物浓度的影响程度,对气象条件进行合理分类,并阐述各类气象条件的特征。 问题3. 使用附件1、2中的数据,建立一个同时适用于A、B、C三个监测点(监测点两两间直线距离>100km,忽略相互影响)的二次预报数学模型,用来预测未来三天6种常规污染物单日浓度值,要求二次预报模型预测结果中AQI预报值的最大相对误差应尽量小,且首要污染物预测准确度尽量高。并使用该模型预测监测点A、B、C在2021年7月13日至7月15日6种常规污染物的单日浓度值,计算相应的AQI和首要污染物,将结果依照附录“污染物浓度及AQI预测结果表”的格式放在论文中。 问题4. 相邻区域的污染物浓度往往具有一定的相关性,区域协同预报可能会提升空气质量预报的准确度。如图 4,监测点A的临近区域内存在监测点A1、A2、A3,使用附件1、3中的数据,建立包含A、A1、A2、A3四个监测点的协同预报模型,【联合】要求二次模型预测结果中AQI预报值的最大相对误差应尽量小,且首要污染物预测准确度尽量高。使用该模型预测监测点A、A1、A2、A3在2021年7月13日至7月15日6种常规污染物的单日浓度值,计算相应的AQI和首要污染物,将结果依照附录“污染物浓度及AQI预测结果表”的格式放在论文中。并讨论:与问题3的模型相比,协同预报模型能否提升针对监测点A的污染物浓度预报准确度?说明原因。---------要提升才行 具体word题目链接见: 2021年B题空气质量预报二次建模.zip-机器学习文档类资源-CSDN下载 1.基于Stacking机器学习混合模型的空气质量预测摘 要: 大气污染系指由于人类活动或自然过程引起某些物质进入大气中,空气污染严重时,会对人体健康产生较大危害,空气质量指数(AQI)用来衡量空气质量状况,建立空气质量预报模型,预测可能发生的大气污染并采取相应控制措施,有利于减少大气污染对人体和环境等造成危害。 针对问题一、需要对原始数据进行简单的计算,原始数据来自于附件1中的监测点A从2020年8月25日到8月28日污染物浓度实测数据,这几天产生空气污染的首要污染物均为臭氧。 针对问题二、首先通过数据探索性分析对数据进行预处理,发现污染物分布符合无界约翰逊(Johnson SU)分布并做长尾截断处理,之后对数据进行归一化;其次通过相关性分析、顺序特征选择法(SFS)以及L1、L2正则化和弹性网络(ElaticNet)进行WRF-CMAQ预测气象特征进行筛选。随后对AQI进行动态分析,根据季节月份天数进行动态追踪分析,并采用聚类算法对气象分类进行验证,得到气象分类特征。 针对问题三、首先以A测试站点进行建模,根据筛选出来的气象特征和污染物变量特征;通过LGBM、Xgboots以及ElaticNet优化后的RNN和LSTM算法进行初次模型预测,同时采用贪心策略和贝叶斯网络对算法参数优化,衡量指标得到明显改善,其中分别以平平均绝对误差、均方根误差、MAPE 和R2作为模型评价指标,其次鉴于简单模型较难准确泛化各影响因素与空气质量之间的内在关系,文中进行Stacking方式将性能优秀的模型和WRF-CMAQ进行融合,并采用5折交叉验证的方法验证模型的预测能力。结果表明模型预测值和真实值一致性较强,且预测准确度很高,同时模型泛化能力很好适用于B、C检测站点。 针对问题四、考虑到A1、A2、A3、A4协同预报模型,在问题三构建的模型上着重考虑风速和风向特征因素带来的影响,以及考虑不同站点因为距离不同对A站点预测结果产生影响程度不同,进行权重配比构建基于Stacking融合的预测模型,结果表明风力因素对模型预测以及多站点协同预报对QAI以及污染物等预报更准确。 城市空气质量进行短期预测分析,最终实现对AQI指数具体值以及主要污染物成分的有效短期预测,克服当前监测系统后效性的缺陷,提供有效预警,,竭力为我市居民打造一个健康、可持续的居住环境具有更强的推广性。 关键词: 空气质量预测,Stacking,Elastic Net-LSTM,LGBM,Xgboost 2.问题重述2.1 问题背景大气污染系指由于人类活动或自然过程引起某些物质进入大气中,呈现足够的浓度,达到了足够的时间,并因此危害了人体的舒适、健康和福利或危害了生态环境。污染防治实践表明,建立空气质量预报模型,提前获知可能发生的大气污染过程并采取相应控制措施,是减少大气污染对人体健康和环境等造成的危害,提高环境空气质量的有效方法之一。 目前常用WRF-CMAQ模拟体系(以下简称WRF-CMAQ模型)对空气质量进行预报。WRF-CMAQ模型主要包括WRF和CMAQ两部分:WRF是一种中尺度数值天气预报系统,用于为CMAQ提供所需的气象场数据;CMAQ是一种三维欧拉大气化学与传输模拟系统,其根据来自WRF的气象信息及场域内的污染排放清单,基于物理和化学反应原理模拟污染物等的变化过程,继而得到具体时间点或时间段的预报结果。WRF和CMAQ的结构如错误!未找到引用源。-1、错误!未找到引用源。所示,详细介绍可以在附录提供的官网中进行查询。 图1- 1中尺度数值天气预报系统WRF结构 但受制于模拟的气象场以及排放清单的不确定性,以及对包括臭氧在内的污染物生成机理的不完全明晰,WRF-CMAQ预报模型的结果并不理想。故题目提出二次建模概念:即指在WRF-CMAQ等一次预报模型模拟结果的基础上,结合更多的数据源进行再建模,以提高预报的准确性。其中,由于实际气象条件对空气质量影响很大(例如湿度降低有利于臭氧的生成),且污染物浓度实测数据的变化情况对空气质量预报具有一定参考价值,故目前会参考空气质量监测点获得的气象与污染物数据进行二次建模,以优化预报模型。 图1- 2空气质量预测与评估系统CMAQ结构 二次模型与WRF-CMAQ模型关系如错误!未找到引用源。所示。为便于理解,下文将WRF-CMAQ模型运行产生的数据简称为“一次预报数据”,将空气质量监测站点实际监测得到的数据简称为“实测数据”。一般来说,一次预报数据与实测数据相关性不高,但预报过程中常会使用实测数据对一次预报数据进行修正以达到更好的效果。 图1- 3 二次模型优化的WRF-CMAQ空气质量预报过程 根据《环境空气质量标准》(GB3095-2012),用于衡量空气质量的常规大气污染物共有六种,分别为二氧化硫(SO2)、二氧化氮(NO2)、粒径小于10μm的颗粒物(PM10)、粒径小于2.5μm的颗粒物(PM2.5)、臭氧(O3)、一氧化碳(CO)。其中,臭氧污染在全国多地区频发,对臭氧污染的预警与防治是环保部门的工作重点。臭氧浓度预报也是六项污染物预报中较难的一项,其原因在于:作为六项污染物中唯一的二次污染物,臭氧并非来自污染源的直接排放,而是在大气中经过一系列化学及光化学反应生成的(可参考附录 一种近地面臭氧污染形成机制 部分),这导致用WRF-CMAQ模型精确预测臭氧浓度变化的难度很高;同时,国内外已有的研究工作尚未得出臭氧生成机理的一般结论。 2.2 问题描述需要通过建立数学模型,解决以下几个问题: 问题一: 计算AQI和首要污染物 根据附录中提供的计算方法,再利用附件1中的监测点A从2020年8月25日到8月28日每日实测数据来计算每日的实测AQI和首要污染物,并将计算得出的数据填入附录所给的“AQI计算结果表”中,再放到正文里。 问题二: 对气象条件进行合理分类 使用附件1中的数据,包括一次预报数据和实测数据,再根据对污染物浓度的影响程度,对气象条件进行合理分类,并阐述各类气象条件的特征 问题三: 建立二次预报数学模型 使用附件1、2中的数据,建立一个同时适用于A、B、C三个监测点的二次预报数学模型,用来预测未来三天6种常规污染物单日浓度值,要求二次预报模型预测结果中AQI预报值的最大相对误差应尽量小,且首要污染物预测准确度尽量高。并使用该模型预测监测点A、B、C在2021年7月13日至7月15日6种常规污染物的单日浓度值,计算相应的AQI和首要污染物,将结果依照附录“污染物浓度及AQI预测结果表”的格式放在论文中。 问题四: 建立区域协同预报模型 使用附件1、3中的数据,建立包含A、A1、A2、A3四个监测点的协同预报模型,要求二次模型预测结果中AQI预报值的最大相对误差应尽量小,且首要污染物预测准确度尽量高。使用该模型预测监测点A、A1、A2、A3在2021年7月13日至7月15日6种常规污染物的单日浓度值,计算相应的AQI和首要污染物,将结果依照附录“污染物浓度及AQI预测结果表”的格式放在论文中。并与问题3的模型相对比监测点A的污染物浓度预报准确度。 2.3模型假设问题假设在问题求解过程中,考虑实际情况与简化计算的需求,提出了以下相关的假设:(1) 由于样本中数据缺失较多,假设在数据填充时,不会影响模型性能。 (2) 在变量筛选时,其他变量对模型预测性能无影响。 (3) 在有效信息提取和无用信息摒弃过程中对模型性能无影响。 (4) 所有样本数据都为实际场景的真实数据。 3、问题一模型的建立与求解3.1 解题思路概述问题1需要对原始数据进行简单的计算,原始数据来自于附件1中的监测点A从2020年8月25日到8月28日污染物浓度实测数据,由于原始数据只有四天的数据量,且没有数据缺失或异常,所以无需进行数据预处理。 首先计算监测点A从2020年8月25日到8月28日的六项污染物的空气质量分指数(IAQI),取六个IAQI中的最大值得到空气质量指数(AQI),若AQI大于50,则IAQI最大的污染物为首要污染物。 确定问题一的总体思路如图3-1所示。 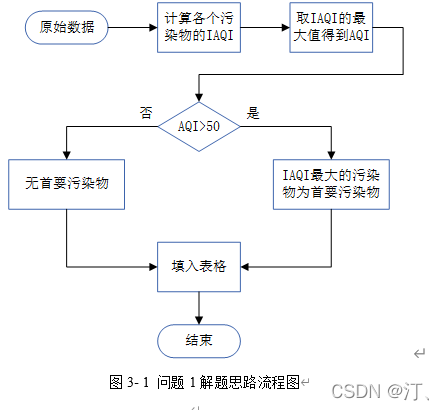 3.2 AQI的求解3.2.1 计算各项污染物的IAQI 3.2 AQI的求解3.2.1 计算各项污染物的IAQI首先需得到各项污染物的空气质量分指数(IAQI),其计算公式如下: 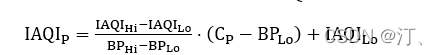 式中各符号含义如下:  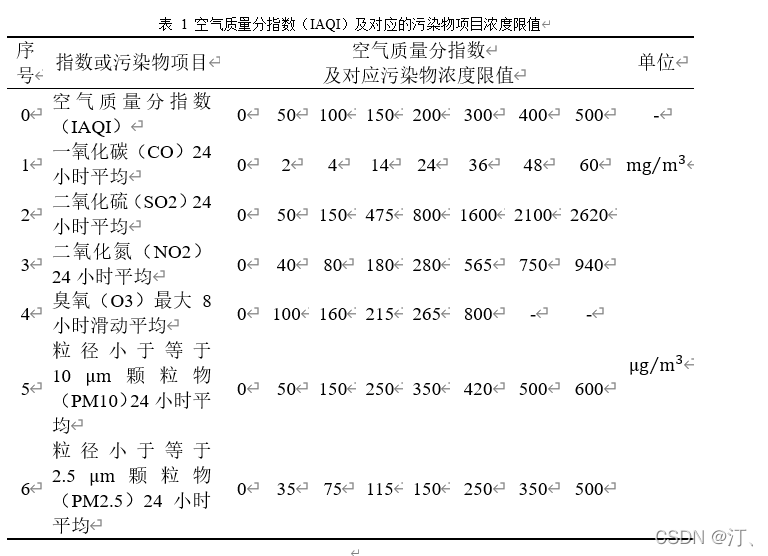 注:(1) 臭氧(O3)最大8小时滑动平均浓度值高于800 μg∕m^3 的,不再进行其空气质量分指数计算。 (2) 其余污染物浓度高于IAQI=500对应限值时,不再进行其空气质量分指数计算。 由于监测点A从2020年8月25日到8月28日污染物浓度实测数据均未到达限值,所以都进行空气质量分指数计算。 3.2.2 计算AQI计算首要污染物在此模型中,对于AQI的计算仅涉及表 1提供的六种污染物,因此计算公式如下: 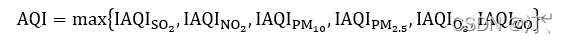 空气质量等级范围根据AQI数值划分,等级对应的AQI范围见表 2。  当AQI小于或等于50(即空气质量评价为“优”)时,称当天无首要污染物; 当AQI大于50时,IAQI最大的污染物为首要污染物。若IAQI最大的污染物为两项或两项以上时,并列为首要污染物。 IAQI大于100的污染物为超标污染物。 2020年8月25日到8月28日的AQI以及首要污染物的计算结果如表3所示: 表3 AQI计算结果表  4、数据预处理 4、数据预处理由于数据表较多,且监测点A,B,C的预测和实测数据类型都相同,所以数据处理时论文只展现监测点A的预处理结果,对于其他的数据表,也采用相同的方法进行处理,便于问题2,3的模型建立。 4.1 缺失数据填充与处理为了提高模型的能,一般会对数据进行预处理,因为数据预处理就是特征工程。通常,由于种种原因,在现实世界中,数据集有时会丢失缺失,例如传感器临时故障和其他人为错误。这些缺失的数据会降低模型的准确度,甚至有些缺失值的数据会让模型无法进行正确的预测。因此,应在建立模型之前填充数据。同时,数据中包含一些与预测特征无关的特征。为了提高模型的预测精度和建模效率,需要对模型的特征进行筛选。另外,不同数据特征的维度也是不同的,这就需要对数据进行标准化以提高模型的性能。 4.1.1 缺失数据分析由于监测站点设备调试、维护等原因,监测站点的数据在连续时间内存在部分或全部缺失的情况,因此我们需要先对监测站点的数据进行分析,再确定对缺失数据的处理办法。如图所示的柱形图,可以直观的看到逐小时和逐日的缺失值,这样便于确定缺失的变量和它的值。 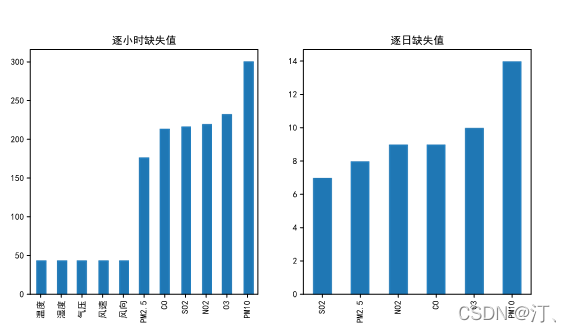 图4- 1 缺失值图 同时,再使用missingno可视化库对数据进行处理,得到缺失值无效矩阵图,无效矩阵是一个数据密集的显示,它可以快速直观地看出数据完整度。由图4-2和图4-3可知,空白越多说明缺失越严重,右侧的迷你图概述了数据完整性的一般形状,并指出了数据集中具有最大和最小无效值的行数。  图4- 2 逐小时监测数据缺失值无效矩阵图  图4- 3 逐日监测数据缺失值无效矩阵图 4.1.2 缺失数据处理处理数据集中缺失值的方法主要有两种,一种是删除缺失值所在的行,另一种是填充缺失值。如果数据集中有很多缺失值的行,删除数据就会导致忽略一半以上的观察值,尤其是数据集较小时,会导致模型无法学习关键的数据分布,同时还会限值模型的性能。另外,当数据集是时间序列时,删除缺失值会导致模型无法学习相邻时间数据之间的关系。 本文使用多重插补的方法来填充缺失值,多重插补(Multiple Imputation)是一种基于重复模拟的处理缺失值的方法。它从一个包含缺失值的数据集中生成一组完整的数据集。 和单一插补不同的是,多重插补并没有试图去通过模拟值去估计每个缺失值, 而是提出缺失数据值的一个随机样本, 这种程序的实施恰当地反映了由于缺失值引起的不确定性, 使得统计推断有效。附件1的数据为气象数据,若简单的采用缺失值前后的数据进行填补,容易受到极端数值的影响,且缺失数据之间并不一定连续,如果使用多重填补在整体上进行一个缺失数据填充,能够让填充的数据更加的准确,更服从气象变化的规律。 多重插补推断包括了3个不同步骤: (1)对缺失数据填补m次, 产生m个完整的数据集 (2)使用标准程序去分析这m个完整数据集 (3)综合这个完整数据集的结果, 用于推断 对于附件1中监测点A的逐小时和逐日的实测数据进行填充处理,采用多重插补的办法进行填充,最后得到无缺失值的数据集,如图4-4和图4-5所示,下面的缺失值无效矩阵图无空白处,右侧迷你图也没有突出的线,表明处理后的数据无缺失值。 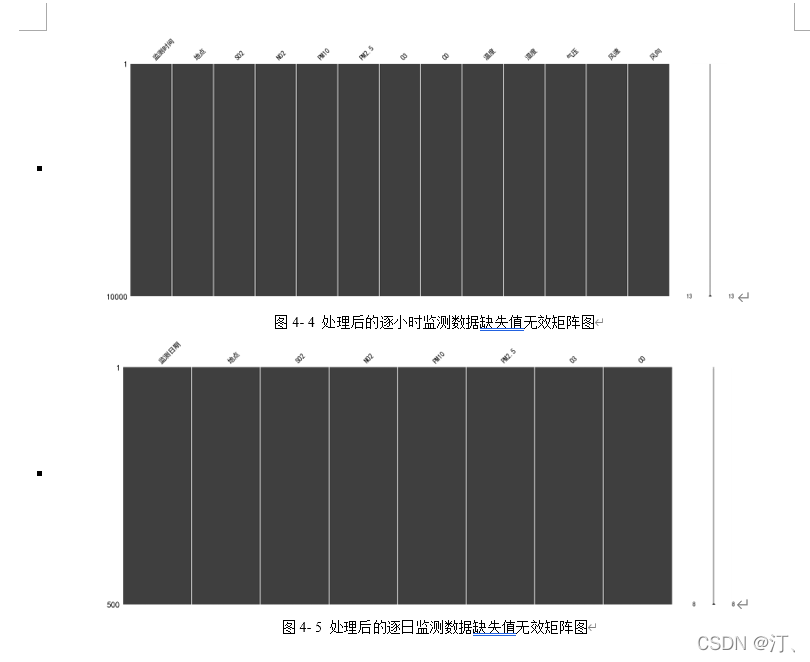 4.2 异常值分析 4.2 异常值分析受监测站点及其附近某些偶然因素的影响,实测数据在某个小时或某天的数值偏离正常分布,这些偏离正常分布的值就为异常值,而这些异常值会影响模型的预测精度和准确度。异常值的定义是离其他数据点很远的点,对于很多统计算法来说,异常值会导致算法做出错误决策,严重干扰预测结果。但是,目前没有严格的统计规则来确定异常值,异常值检测只能依赖于学科领域的知识和对数据收集过程的理解。 异常值的监测方法有很多,例如箱形图、3-Sigma、长尾截断等。本文采用的异常值检测方法就是箱形图法。箱形图是用于显示一组数据分布信息的统计图表。以盒状形状得名。 主要用于反映原始数据分布的特征,也可以比较多个数据集的分布特征。箱线图提供了识别异常值的标准。异常值通常定义为小于 QL-k * QR或大于QU+k * QR的值。其中,QL为下四分位数,即所有观测值有四分之一比QL小,QU为上四分位数,所有观测值有四分之一比QU小。QR是四分位距,即上四分位数QU和下四分位数QL之间的差值。本文的k值使用默认的k值3。图4-6的左图是逐日的〖SO〗_2监测浓度的原数据的箱形图,右图是使用箱形图剔除异常值后的箱形图,其中黑色的点是异常值,由图可以看出,清除异常值的效果非常显著,左图的大量异常值清除到只剩右图的一个异常值,仅剩的一个异常值对于模型预测的准确度影响不大,可以不再进行删除处理。 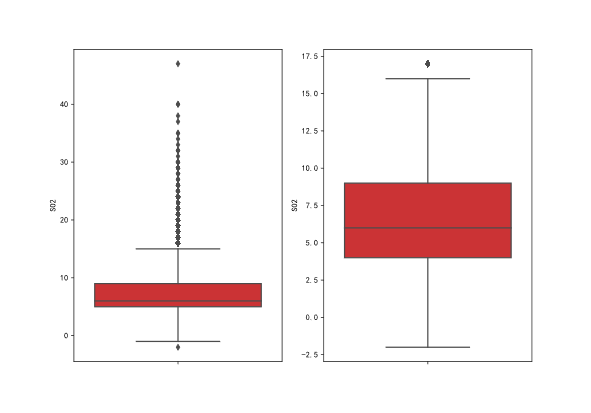 图4- 6 处理前后的SO2箱形图 使用箱形图对所有数据进行异常值删除处理,得到图-,由图4-7可知,部分污染物仍然存在少量的异常值,少量的异常值对于预测模型的影响不大,若将其删除,可能也会对后续的预测造成较大的影响,所以不再进行删除处理。 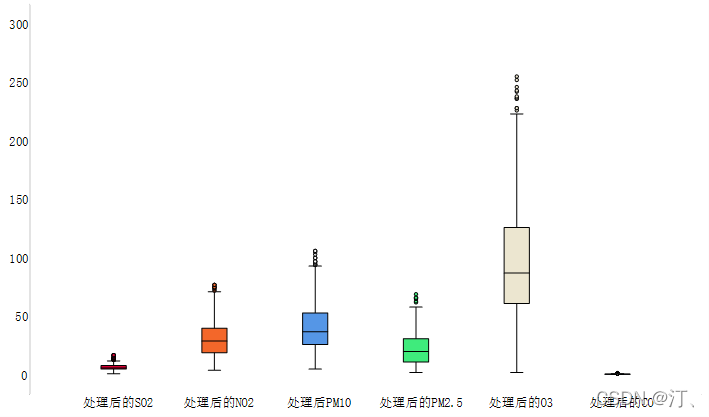 图4- 7 各种污染物处理后的浓度的箱形图 4.3 描述性统计分析描述性统计分析是将一系列复杂的数据减少到几个能起到描述作用的关键数字,是对已有数据集的一个整体情况描述,主要体现数据的集中趋势和离散趋势。描述性统计分析包含平均值、标准差、最小值、下四分位数、中位数、上四分位数、最大值、偏度、峰度等关键数值,通过平均值和上下四分位数,可以比较好的描述数据的整体分布情况,通过标准差、中位数、偏度、峰度,可以反映出数据波动的程度和识别出可能的异常值。描述性统计分析如表4所示 表 4 描述性统计分析表 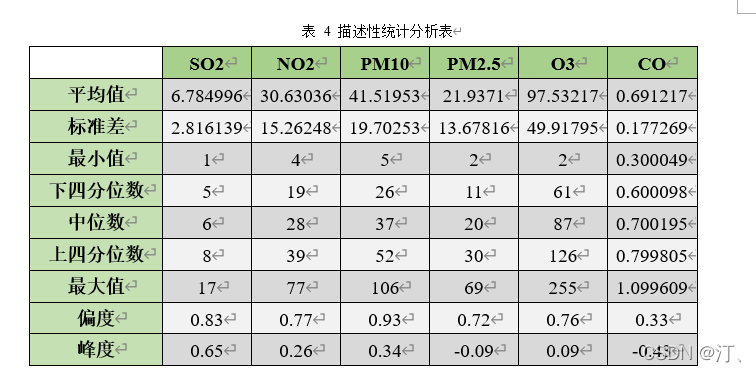 偏度(Skewness)可以用来度量随机变量概率分布的不对称性。公式为: 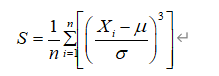 其中μ是均值,δ是标准差。偏度的取值范围为(-∞,+∞)。当偏度0时,概率分布图右偏。 峰度可以用来度量随机变量概率分布的陡峭程度。公式为: 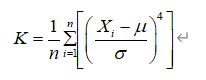 其中μ是均值,δ是标准差。完全服从正态分布的数据的峰度值为 0,峰度值越大,概率分布图越高尖,峰度值越小,越矮胖。 通过表可以看出,全部数据的偏度都大于0,所以全部数据均右偏,PM2.5和O_3的峰度比较靠近0,所以分布比较接近正态分布,其余偏离正态分布的程度都较大,特别是〖SO〗_2,因此需要在下文中对数据进行数据分布分析,把偏离正态分布的数据进行变换使其符合正态分布。 4.4 数据分布分析对数据进行数据分布分析可以得到对应数据的分布特征和分布类型,分析完成得到数据的分布后,可以根据数据的不同分布对数据进行不同的预处理。例如,若数据服从正态分布:根据正态分布的定义可知,距离平均值3δ之外的概率为 P(x-μ>3δ) |
【本文地址】
今日新闻 |
推荐新闻 |