|
首先按题目要求整理好关键数据

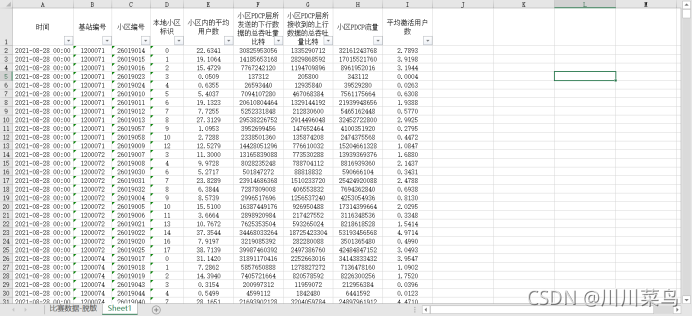 既然题目也讲到了三个关键指标,那么后文的异常检测一定要围绕这三个关键指标展开,这三个指标理论上是强相关性的,严谨来讲不能分开单独做异常检测 既然题目也讲到了三个关键指标,那么后文的异常检测一定要围绕这三个关键指标展开,这三个指标理论上是强相关性的,严谨来讲不能分开单独做异常检测
虽然题目只要求用到了几个指标,如果要考虑其余指标的话也可以用,用来描述设备的运行状态,如果要用其他设备指标数据,用要看第一问检测出的异常数据的变动情况,结合其余指标数据求相关性,如果有明显相关的,那么可以纳入后问分析,没有就不做
本题告诉了数据具有周期性,也谈到了异常,很明显时间序列解题方向是没错,用异常检测算法检测出异常数据,然后需要对异常数据进行修正。刚刚讲了三个关键指标强相关,那么这里的异常检测,应当从三者数据趋势角度去进行分析,如何个趋势分析这里说一下,第一种取指标数据中小到大排序后的第30%位和70%位两个值用最大最小法的公式标准化,第二种参考指标数据中的均值标准化处理,这样处理后可以保证三者数据在原有趋势下,具有相似的值,之后就是遍历求方差,方差大于多少位异常,这里可以自己设一个阈值,一定记得是每个小区单独分析。 
虽然这道题没说舆情,但是自己想一下用户的活跃,不就是上网嘛,肯定和娱乐圈、电影、新冠疫情、股市期货、猪肉价格等等事件相关,这也并不是说要人人都去爬取微博、知乎、东方财富等网站的评论然后做热词分析,量太大时间也来不及,这里推荐百度指数、微指数、谷歌趋势、360趋势。 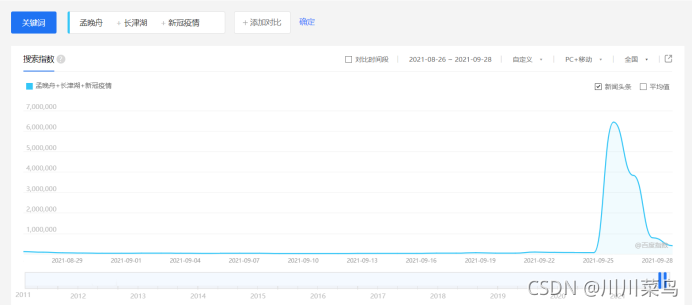 这是之前写了百度指数爬虫代码,分享给大家,按日采集搜索指数,也分了PC和移动端 这是之前写了百度指数爬虫代码,分享给大家,按日采集搜索指数,也分了PC和移动端
import requests
word_url = 'http://index.baidu.com/api/SearchApi/thumbnail?area=0&word={}'
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Cookie': '',#Cookie用自己的
'DNT': '1',
'Host': 'index.baidu.com',
'Pragma': 'no-cache',
'Proxy-Connection': 'keep-alive',
'Referer': 'http://index.baidu.com/v2/main/index.html',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
words = [[{"name": "猪肉", "wordType": 1}]]
keyword = str(words).replace("'", '"')
start='2010-12-27'
end='2021-10-10'
url = f'http://index.baidu.com/api/SearchApi/index?area=0&word={keyword}&area=0&startDate={start}&endDate={end}'#接口
resp = requests.get(url, headers=headers)
data = resp.json().get('data')#读取后发现数据被加密,需要解码
user_indexes = data.get('userIndexes')[0]
uniqid = data.get('uniqid')#读取uniqid参数
url = 'http://index.baidu.com/Interface/ptbk?uniqid={}'
resp = requests.get(url.format(uniqid), headers=headers)
ptbk = resp.json().get('data')#获取相应的json数据,也是解码
all_data = user_indexes.get('all').get('data')
pc_data = user_indexes.get('pc').get('data')
wise_data = user_indexes.get('wise').get('data')
#构建字典
n = list(ptbk)
a = {}
ln = int(len(n)/2)
start = n[ln:]
end = n[:ln]
for j,k in zip(start, end):
a.update({k: j})
#总指数=pc端搜索指数+移动端搜索指数
result1 = []
for j in all_data:
result1.append(a.get(j))#解码后为单个字符
result1 = ''.join(result1)#组合
result1 = result1.split(',')#以逗号切分
print('总指数')
print(result1)
#pc端搜索指数
result2 = []
for j in pc_data:
result2.append(a.get(j))#解码后为单个字符
result2 = ''.join(result2)#组合
result2 = result2.split(',')#以逗号切分
print('pc端搜索指数')
print(result2)
#移动端搜索指数
result3 = []
for j in wise_data:
result3.append(a.get(j))#解码后为单个字符
result3 = ''.join(result3)#组合
result3 = result3.split(',')#以逗号切分
print('移动端搜索指数')
print(result3)
疫情数据国内外都可以 ①
https://www.arcgis.com/apps/dashboards/index.html#/bda7594740fd40299423467b48e9ecf6
②
https://ourworldindata.org/coronavirus#growth-of-cases-how-long-did-it-take-for-the-number-of-confirmed-cases-to-double
③
http://www.hoonew.cn/newPneu_china/
以及股市大盘的走向或者重大事件 ①
http://quote.eastmoney.com/sz300059.html?from=Sougou
②
https://datacenter.jin10.com/
或者比较关心的猪肉价格、蔬菜价格走势
https://d.qianzhan.com/
等等,后面要做数据预测,时间序列并不能预测出未来用户活跃的数据趋势,但如果再结合舆情,可能更真实。包括对异常数据的修正,比如说通过上面找到的舆情指标分别构建本题三个关键指标的指标体系,然后用这些指标数据作为训练输入,关键指标数据作为输出,分别通过机器学习方法去修正检测到的数据,如何给自己增加亮点自己考虑,随便套用算法谁都会  来看看第一问,一定是针对每个小区来做分析,前面也给大家分析了怎么去做异常检测,并不是直接扔个LOF算法单独对每个指标数据中的异常值进行识别,记住题目强调的三个指标,且三个指标具有强相关关系,所以应当从三个指标共同的趋势层面去考虑。为了获得刚高的准确率,可以对数据进行稍微地平滑处理,虽然说平滑后会导致数据失真,那肯定不能平滑的太厉害,平滑后至少要把异常数据段凸显出来,具体的参数需要自己探索。这里的异常检测如果结合实际生活来看大家觉得还有什么,不说0点到7点了,就看看1点到6点之间肯定是用户不怎么活跃的时间,如果这个时间段数据值较高,那么肯定设备出问题了,因此这方面还需单独进行分析。千万别把学到的异常检测算法直接网上套,记得先看清问题背景,最后再说下表1,异常检测后识别出来的异常点,这里你们可以给一个时间长度判断是否是异常孤立点, 异常周期就是你设置的这个时间长度内,如果有其他异常点,那么与其余异常点中,近邻的一个异常点可构成一个异常周期,当然也需要判断一下异常数据的大小,如下图中的一样,基本位于同一高度。 来看看第一问,一定是针对每个小区来做分析,前面也给大家分析了怎么去做异常检测,并不是直接扔个LOF算法单独对每个指标数据中的异常值进行识别,记住题目强调的三个指标,且三个指标具有强相关关系,所以应当从三个指标共同的趋势层面去考虑。为了获得刚高的准确率,可以对数据进行稍微地平滑处理,虽然说平滑后会导致数据失真,那肯定不能平滑的太厉害,平滑后至少要把异常数据段凸显出来,具体的参数需要自己探索。这里的异常检测如果结合实际生活来看大家觉得还有什么,不说0点到7点了,就看看1点到6点之间肯定是用户不怎么活跃的时间,如果这个时间段数据值较高,那么肯定设备出问题了,因此这方面还需单独进行分析。千万别把学到的异常检测算法直接网上套,记得先看清问题背景,最后再说下表1,异常检测后识别出来的异常点,这里你们可以给一个时间长度判断是否是异常孤立点, 异常周期就是你设置的这个时间长度内,如果有其他异常点,那么与其余异常点中,近邻的一个异常点可构成一个异常周期,当然也需要判断一下异常数据的大小,如下图中的一样,基本位于同一高度。 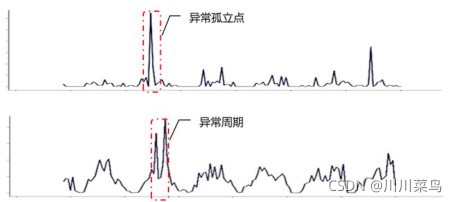  时间周期推荐两个方法,一个是傅里叶变化的平均时间周期,第二个是混沌理论中的时延(常见的有自相关法、互信息法、平均位移法等,在matlab混沌时间序列工具箱中都有) 时间周期推荐两个方法,一个是傅里叶变化的平均时间周期,第二个是混沌理论中的时延(常见的有自相关法、互信息法、平均位移法等,在matlab混沌时间序列工具箱中都有)
function T_mean=period_mean_fft(data)
%该函数使用快速傅里叶变换FFT计算序列平均周期
%data:时间序列
%T_mean:返回快速傅里叶变换FFT计算出的序列平均周期
Y = fft(data); %快速FFT变换
N = length(Y); %FFT变换后数据长度
Y(1) = []; %去掉Y的第一个数据,它是data所有数据的和
power = abs(Y(1:N/2)).^2; %求功率谱
nyquist = 1/2;
freq = (1:N/2)/(N/2)*nyquist; %求频率
figure
plot(freq,power); grid on %绘制功率谱图
xlabel('频率')
ylabel('功率')
title('功率谱图')
period = 1./freq; %计算周期
figure
plot(period,power); grid on %绘制周期-功率谱曲线
ylabel('功率')
xlabel('周期')
title('周期—功率谱图')
[mp,index] = max(power); %求最高谱线所对应的下标
T_mean=period(index); %由下标求出平均周期
第一问也差不多就是确定周期参数和一场数据检测和处理,来看第二问
注意是每个小区单独分析,如果有异常就有异常,没异常就别故意增加异常
如果按前面说的找舆情数据,那这个问就比较好做,为什么前面要说如果能用上设备状态的数据就用,设备的运行,主要有天气和负载导致的,既然举办方也说不用考虑地区,那就不考虑天气了。可分析设备参数与三个关键指标的相关性,如果有发现相关性较高的设备状态指标可以在本问中考虑,这里也可以考虑基站的负荷情况,比如同一基站服务范围内所有用户的活跃数据(三个关键指标)来反映。第二问是异常预测,在历史数据中,三个关键指标以及一些舆情指标、小区所属基站的整体三个关键指标值作为输入,异常点输出1,正常输出0,建立一个二分类的模型,为什么还要结合基站来分析,一个基站服务多个小区,就算一个小区看着数据正常,但是也不能保证会因为其他小区导致高过载引起的异常,就例如平时的网络波动,大家在做题目的时候一定是要结合生活实际去分析,在使用算法算出比较好的结果的同时,也应当具有完善的逻辑
对模型检验采用F检验
精确率= 将正类预测为正类 / 所有预测为正类 TP/(TP+FP) 召回率 = 将正类预测为正类 / 所有正真的正类 TP/(TP+FN) F值 = 精确率 * 召回率 * 2 / ( 精确率 + 召回率) (F 值即为精确率和召回率的调和平均值)
第三问是预测,就是接着异常处理后的三个关键指标数据进行预测,一定是每个小区做分析,第一问的周期是需要用上的,在混沌时间序列中,时延和周期是其中算法的输入参数,也就刚好接上了第一问,这个问可以先用混沌时间序列方法进行预测(RBF神经网络一步预测、RBF神经网络多步预测、Volterra级数一步预测、Volterra级数多步预测等),预测出的只能是个时间序列,然后通过9月26-28日的舆情指标,借鉴第二问做法,对该时间段进行一个预测,这里为什么做两个预测呢,第一个主要是预测出数据周期,而第二个预测的是这三天内实际的用户活跃情况,接下来就需要将两者结果结合起来,最简单的方式就是取两者平均,但是严谨一点就是数据复制一份,两者都做平滑处理,这里平滑可以狠一点,主要的出两条趋势,然后用后者减去前者平滑后的数据,会得到一个舆情相对这个周期性数据的变化量,变化量加在时间序列数据上就行。如果不考虑舆情,直接时间序列/混沌时间序列得出好的结果也可以。 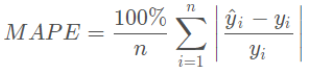
欢迎关注个人公众号:川川菜鸟 后期我会整理好建模资料发给大家。代码现在好像跑不通了,白天我再更新,大家可以先进群。
|