paddlenlp:社交网络中多模态虚假媒体内容核查 |
您所在的位置:网站首页 › 大数据和社交媒体中的融合 › paddlenlp:社交网络中多模态虚假媒体内容核查 |
paddlenlp:社交网络中多模态虚假媒体内容核查
|
初赛之环境配置篇
一、背景二、任务三、数据集1、初赛阶段2、评分标准
四、环境操作五、写在最后
一、背景
随着新媒体时代信息媒介的多元化发展,各种内容大量活跃在媒体内中,与此同时各类虚假信息也充斥着社交媒体,影响着公众的判断和决策。如何在大量的文本、图像等多模态信息中,通过大数据与人工智能技术,纠正和消除虚假错误信息,对于网络舆情及社会治理有着重大意义。 二、任务本次赛题要求选手基于官方指定数据集,通过建模同一事实跨模态数据之间的关系 (主要是文本和图像),实现对任一模态信息能够进行虚假和真实性的检测。鼓励参赛选手通过大模型解决问题,进行技术探索。 三、数据集本次比赛提供从国内外主流社交媒体平台上爬取的含有不同领域声明的数据集。 1、初赛阶段训练集与验证集: 提供中文训练集5694条以及英文数据4893条,同时公开英文验证集611条与中文验证集711条供选手优化模型。 评测数据: 提供文娱、经济、健康领域的测试数据,这些领域的数据较容易区分。英文与中文数据集的测试集各600条。参赛队伍上传的结果文本的每一行就是对应的分类结果,该数据不公布,用于评测。 2、评分标准采用在三个不同类别上的macro F1的高低进行评分,兼顾了准确率与召回率,是谣言检测领域主流的自动评价指标。自动指标排名是计算两个测试集上的Macro F1平均值排序得到。专家会参考自动指标排名、技术方案和现场陈述进行最终的排名。 四、环境操作该模型运行在百度的飞桨平台,本文运行的是基于Ernie版的baseline。 1、点击【运行一下】 5、模型预测的文件需要改动一下,将这里的路径改为 best_model/model_best.pdparams 本次记录主要还是以学习为主,花了一个周末的时间,调试和跑通流程。探索了一个带大家最快上手的路径,降低大家的入门难度。下次再和大家分享对baseline的一些学习,以及可以做模型调整的地方。 看完觉得有用的话,记得点个赞,不做白嫖党~ |
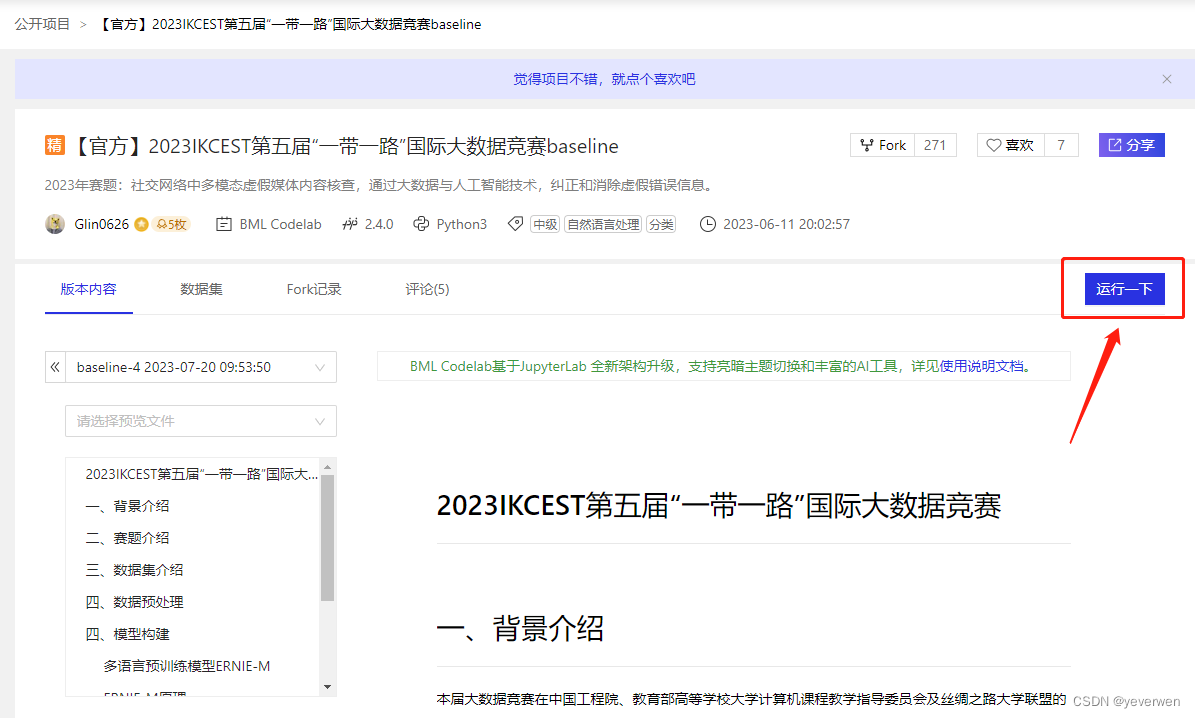 2、选择运行的环境,我们选择【V100 32GB】,这里算力卡基本就是依据你图片的入模容量决定。算力卡余额是有限的,所以尽量用【基础版】环境进行代码编写,编写完后再用【V100 32GB】来进行训练。
2、选择运行的环境,我们选择【V100 32GB】,这里算力卡基本就是依据你图片的入模容量决定。算力卡余额是有限的,所以尽量用【基础版】环境进行代码编写,编写完后再用【V100 32GB】来进行训练。 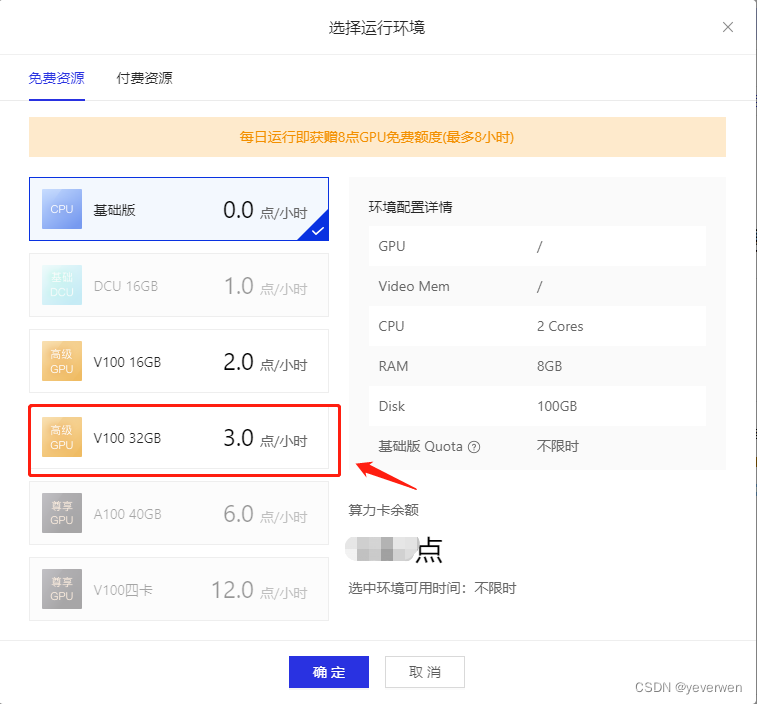 3、将/home/aistudio/data/data229919/data.zip 文件拷贝(单击右键进行复制)到根目录,在根目录进行解压(单机右键进行解压),会生成一个 queries_dataset_merge 的文件夹
3、将/home/aistudio/data/data229919/data.zip 文件拷贝(单击右键进行复制)到根目录,在根目录进行解压(单机右键进行解压),会生成一个 queries_dataset_merge 的文件夹  4、后续的操作就是右图中的代码运行了,此操作和notebook基本一致,点运行即可,最后等待大约两个小时四十分钟,就能得到训练模型的结果了。
4、后续的操作就是右图中的代码运行了,此操作和notebook基本一致,点运行即可,最后等待大约两个小时四十分钟,就能得到训练模型的结果了。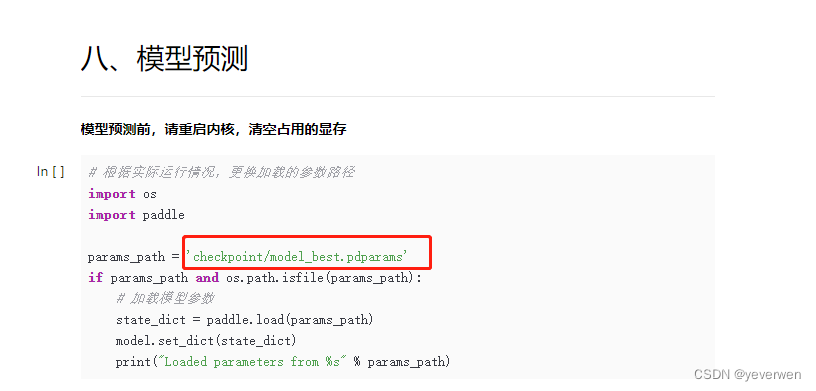 6、最后再把预测结果打包成zip
6、最后再把预测结果打包成zip【本文地址】
今日新闻 |
推荐新闻 |