python selenium 大众点评餐厅信息+用户评论 爬虫 |
您所在的位置:网站首页 › 大众点评店铺登录 › python selenium 大众点评餐厅信息+用户评论 爬虫 |
python selenium 大众点评餐厅信息+用户评论 爬虫
|
这次爬取的目标是大众点评里餐厅的信息以及用户的评论。 大众点评的反爬内容比较丰富,这里也只是记录了如何通过selenium模拟访问大众点评,以及大众点评的woff文件构建字典并对加密文字进行替换。 目标url='http://www.dianping.com/shop/G7RgscHLjDjXY9hg'进入目标网页,对我们想要的商店名进行分析,发现它在开发者工具与页面显示的并不一样, 同时发现这个字体的"font-family"属性为’PingFangSC-Regular-address’。 同时可以注意到:加密的字中都有一个相同的css地址,如上图箭头所指。 http://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/73c76f0d91f3b846605b9aa7a7cfc6e8.css转到链接所指向的网页地址,可以发现该文件是以这样的形式构成的: 这样的结构正好有6个,与上文分析的数目相同。 @font-face { font-family: "PingFangSC-Regular-xxxxxx"; src: url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/xxxx.eot"); src: url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/xxxxx.eot?#iefix") format("embedded-opentype"),url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/xxxxx.woff"); } .dishname { font-family: 'PingFangSC-Regular-xxxxx'; }其中的.woff文件就是我们要用来解密的字体文件,下载字体文件并通过 http://blog.luckly-mjw.cn/tool-show/iconfont-preview/index.html 网址在线预览一下:(这里以adders为例,每天的字体文件可能不同,仅做示范)
可以到网页中加密的文字的Unicode编码能与woff文件中的“吉”对应,因此只要利用woff文生成一个字典,就能通过字典替换得到真正的文字了。 因此 编写爬虫的基本思路为: 1.获取网页内容 2.获得带有woff文件地址的css文件 3.对css文件发起请求得到woff文件的地址 4.分别对woff文件的地址发起请求,得到所有的woff文件 5.利用woff文件生成字典 6.利用字典解密,并保存得到的数据 引用的库 import requests from lxml import etree from selenium import webdriver import time import numpy import re from fontTools.ttLib import TTFont # 解析字体文件的包 from PIL import Image, ImageDraw, ImageFont #绘制图片 from selenium.webdriver.chrome.options import Options from aip import AipOcr import os 获取网页内容 url='http://www.dianping.com/shop/G7RgscHLjDjXY9hg' options = Options() options.add_experimental_option("debuggerAddress", "127.0.0.1:9222") wb=webdriver.Chrome(options=options) wb.get(url) re_text=wb.page_source #数据读取并保存 dz=DZDP_HTML(re_text=re_text) dc=dz.dict_dict#传入总字典 tree=etree.HTML(re_text) data=get_datas_by_xpath(tree,dc) json_str = json.dumps(data,indent=4,ensure_ascii=False) with open('cs.json','w',encoding='utf-8') as f: f.write(json_str)由于直接使用selenium访问会被检测到,参考了https://www.cnblogs.com/triangle959/p/12015179.html 文章采用以上方式避免了被检测成功获取网页源代码 获取css地址,匹配woff地址 def get_fonts_css(re_text): # 传入selenium得到的网页内容 通过正则提取到各个字体对应的url链接 css_gz=re.compile(r'(s3plus.meituan.net.*?.\.css)',re.S) css_url="http://"+css_gz.search(re_text).group(1) req=requests.get(url=css_url).text # return req.text url_gz=re.compile(r',url\("\/\/(s3plus.meituan.net.*?\.woff)',re.S) font_gz=re.compile('font-family: "PingFangSC-Regular-(.*?)";',re.S) url_list=re.findall(url_gz,req) font_list=re.findall(font_gz,req) font_url_dict={} for x,y in zip(url_list,font_list): font_url_dict[y]=x return font_url_dict#得到类型名:网址 的字典 件 分别请求,得到各个woff文件 def down_fonts_url(font_url_dict): # 传入get_fonts_css得到的 字典 遍历后进行下载对应的woff文件 for key,url in font_url_dict.items(): url="http://"+url res=requests.get(url).content with open(key+".woff",'wb') as f: print(key+".woff文件下载完成!") f.write(res) 利用woff文件生成字典 class DZDP_HTML(object): def __init__(self,re_text): super().__init__() dict=self.__get_fonts_css(re_text) self.__down_fonts_url(dict) self.num_dict= self.__get_fonts_dict("num") self.dishname_dict= self.__get_fonts_dict("dishname") self.review_dict= self.__get_fonts_dict("review") self.hours_dict= self.__get_fonts_dict("hours") self.address_dict= self.__get_fonts_dict("address") self.shopdesc_dict= self.__get_fonts_dict("shopdesc") self.dict_dict={ "num":self.num_dict, "dishname":self.dishname_dict, "review":self.review_dict, "hours":self.hours_dict, "address":self.address_dict, "shopdesc":self.shopdesc_dict } def __get_fonts_ocr(self,filename): APP_ID = ' ' API_KEY = ' ' SECRET_KEY = ' ' aipOcr=AipOcr(APP_ID, API_KEY, SECRET_KEY) # 读取图片 filePath = filename+".jpg" def get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read() # 定义参数变量 optionss = { 'detect_direction': 'true', 'language_type': 'CHN_ENG', } # 网络图片文字文字识别接口 result = aipOcr.webImage(get_file_content(filePath),optionss) return result def __get_fonts_dict(self,fontpath): font = TTFont(fontpath+'.woff') # 打开文件 codeList = font.getGlyphOrder()[2:] im = Image.new("RGB", (1800, 1000), (255, 255, 255)) dr = ImageDraw.Draw(im) font = ImageFont.truetype(fontpath+'.woff', 40) count = 15 arrayList = numpy.array_split(codeList,count) #将列表切分成15份,以便于在图片上分行显示 for t in range(count): newList = [i.replace("uni", "\\u") for i in arrayList[t]] text = "".join(newList) text = text.encode('utf-8').decode('unicode_escape') dr.text((0, 50 * t), text, font=font, fill="#000000") im.save(fontpath+".jpg") dc={}#输出字典 result=self.__get_fonts_ocr(fontpath) words_list=result['words_result'] for array,word in zip(arrayList,words_list): for arra,wor in zip(array,word["words"]): # arra=str(arra) arra=arra.replace("uni", r"\u") dc[arra]=wor return dc字典的生成借用了 https://blog.csdn.net/weixin_44606217/article/details/103766197 文章的代码,利用百度识图的api进行文字识别,因此要输入自己的id和key 利用xpath提取信息,并利用字典进行解密. class_name_list=["shopdesc","address","hours","review","shopdesc","num"] def get_true_words(lists,dc): add="" for n in lists: class_num=0 class_name=n.xpath('.//@class') c=0 #去除不属于class_name_list 就可以实现跟加密文字的一一对应确定用哪个字典解密 while c} user_name=li.xpath('.//p[@class="user-info"]/a/text()') user_time=li.xpath('.//span[@class="time"]/text()') user_contont=li.xpath('.//p[@class="desc"]') add=get_true_words( user_contont,dc) data_user["user_name"]=user_name[0] data_user["user_time"]=user_time[0] data_user["user_contont"]=add data["user%s"%i]=data_user i+=1 return data输出: |
 继续分析其他加密字体,可以发现这样一个规律:
继续分析其他加密字体,可以发现这样一个规律: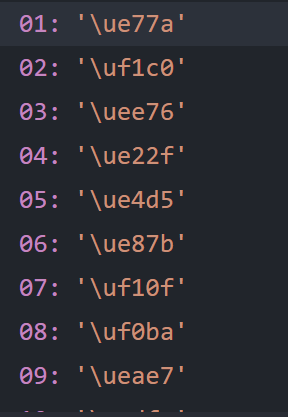


【本文地址】
今日新闻 |
推荐新闻 |