深度学习笔记(二) |
您所在的位置:网站首页 › 多层感知机模型 › 深度学习笔记(二) |
深度学习笔记(二)
|
一、人工神经网络定义
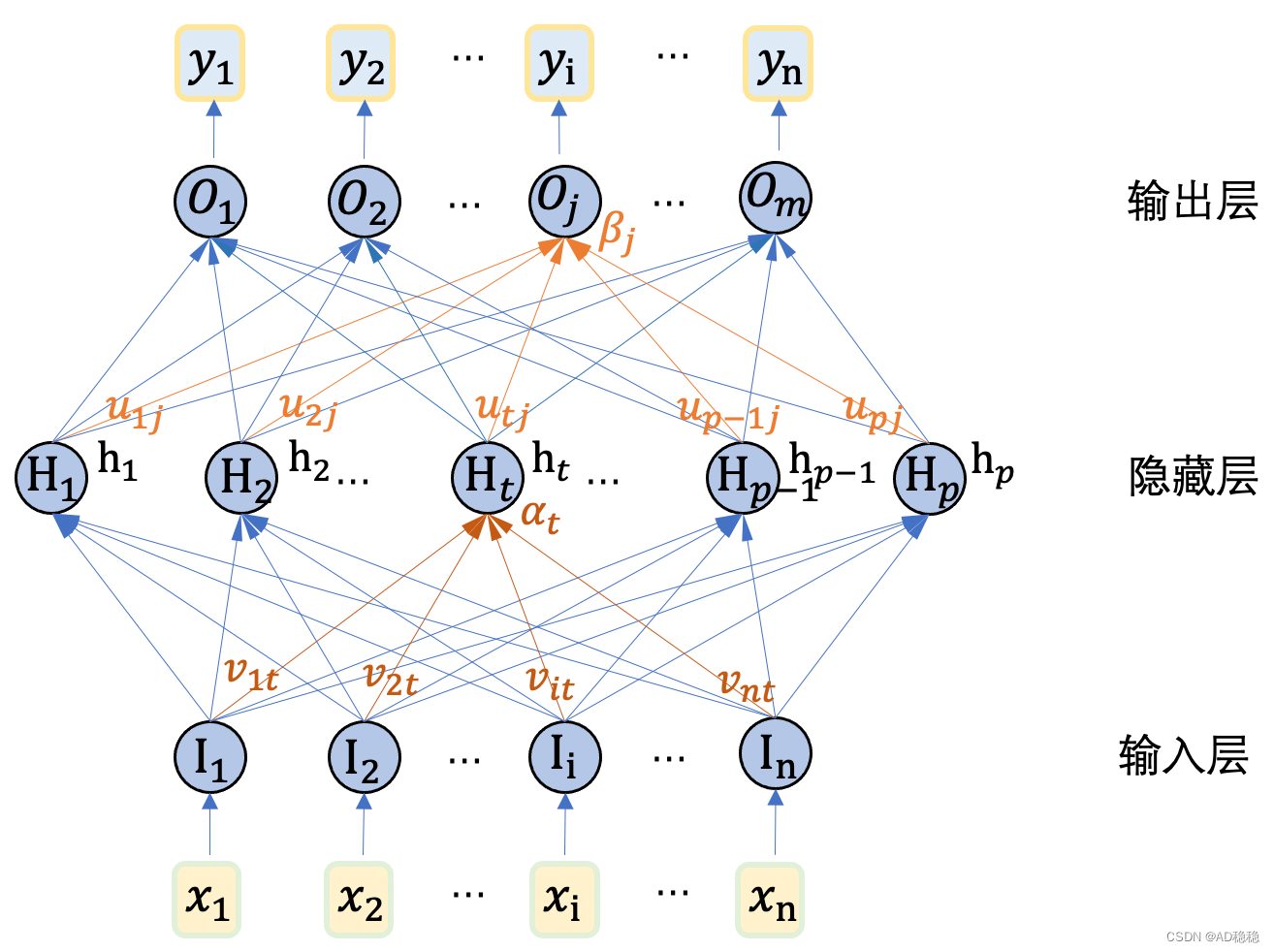
广义上来说,由神经元模型构成的模型就可以称之为人工神经网络模型。神经元模型已经在上一篇感知机的笔记中进行介绍。上一篇也提到,两层神经元模型即可组成最简单的感知机模型,其中第一层称为输入层,第二层称为输出层。由于单层感知机的学习能力限制,科研人员又提出将多个感知机组合到一起,构成了多层感知机(Multilayer Perceptron)模型。本文主要来介绍最基础的人工神经网络模型——多层感知机模型。 二、多层感知机模型在神经网络模型中,将信号逐层向前传播的神经网络称为前馈网络,感知机模型就是典型的前馈网络。而多个感知机模型排列而成的多层感知机模型也是前馈网络,也可以具体称为多层前馈网络(Multi-Layer FeedForward Neural Networks)。在多层感知机中,每一层的各个神经元的输出都会传到下一层的各个神经元中,因此多层感知机也称为全连接网络。 由于多层感知机模型由多个感知机模型连接形成,因此,相邻两个感知机模型中,第一个感知机模型的输入即为第二个感知机模型的输入,因此第二个感知机模型的输入层可以省略掉不进行表示。在多层感知机中,除了整体模型的输入层和输出层之外,中间的各层都称为隐藏层(Hidden Layer)。下图是一个包含两层感知机的双层感知机模型,由于该模型包含一个隐藏层,也称为单隐藏层MLP。
在该图中,n表示输入数据的维度,m表示输出数据的维度,p表示隐藏层的维度;在这个双层MLP中,输入变量为向量 由于MLP是由多个感知机模型组合构成的,整体模型的待学习参数即为每层感知机的参数量之和。每个单层感知机模型中待学习的参数为输出层与输入层的所有连接权重,及每个输出层神经元的阈值,其中阈值数量为输入层神经元数X输出层神经元数,阈值数等于输出层神经元数。同样,在多层感知机中,需要计算的包括所有相邻两层的连接权重,及所有隐藏层及输出层的阈值。 计算上图中表示的双层感知机,需要学习的参数量即为: 本节来学习前馈网络中最常用也是最经典的BP算法,来研究多层感知机的参数学习算法。以前面提到的双层MLP模型为例。首先,定义模型的训练数据集中的某一个数据元组为
在双层感知机模型中,共有 一下以隐藏层神经元 其中,公式(1)为误差对参数计算的偏导数,考虑到从误差 根据公式(3)可得, 将(5)式代入公式(1),可以得到权重的更新值为: 这样,我们就得到了第二次MLP中的权重参数更新值。模型中剩余待确定的参数为第二层阈值、第一次权重、第一次阈值。类似地我们可以推导出第二层的阈值参数更新: 采用和第二层权重更新同样的方法,来推导第一层权重: 同理可以得到第一层阈值参数更新为 为了方便进一步计算,我们定义梯度项: 综上,我们可以得到双层感知机中所有模型参数的更新值如下: 由此,我们可以得出双层感知机模型的参数更新算法: ''' 伪代码 输入:训练集D={(Xk,Yk)} 1 |
【本文地址】
今日新闻 |
推荐新闻 |