|
在卷积网络中通道注意力经常用到SENet模块,来增强网络模型在通道权重的选择能力,进而提点。关于SENet的原理和具体细节,我们在上一篇已经详细的介绍了:经典神经网络论文超详细解读(七)——SENet(注意力机制)学习笔记(翻译+精读+代码复现)
接下来我们来复现一下代码。
因为SENet不是一个全新的网络模型,而是相当于提出了一个即插即用的高性能小插件,所以代码实现也是比较简单的。本文是在ResNet基础上加入SEblock模块进行实现ResNet_SE50。
一、SENet结构组成介绍
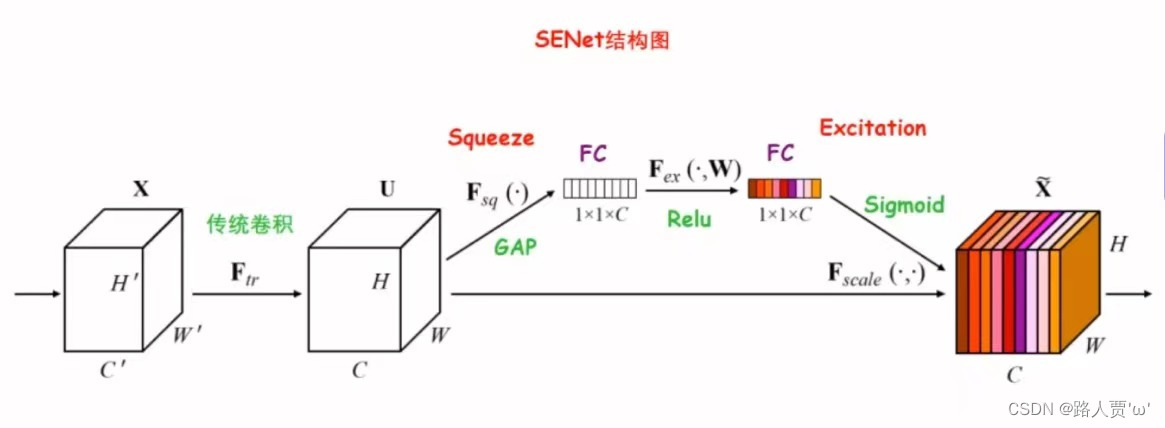
上图为一个SEblock,由SEblock块构成的网络叫做SENet;可以基于原生网络,添加SEblock块构成SE-NameNet,如基于AlexNet等添加SE结构,称作SE-AlexNet、SE-ResNet等
SE块与先进的架构Inception、ResNet的结合效果
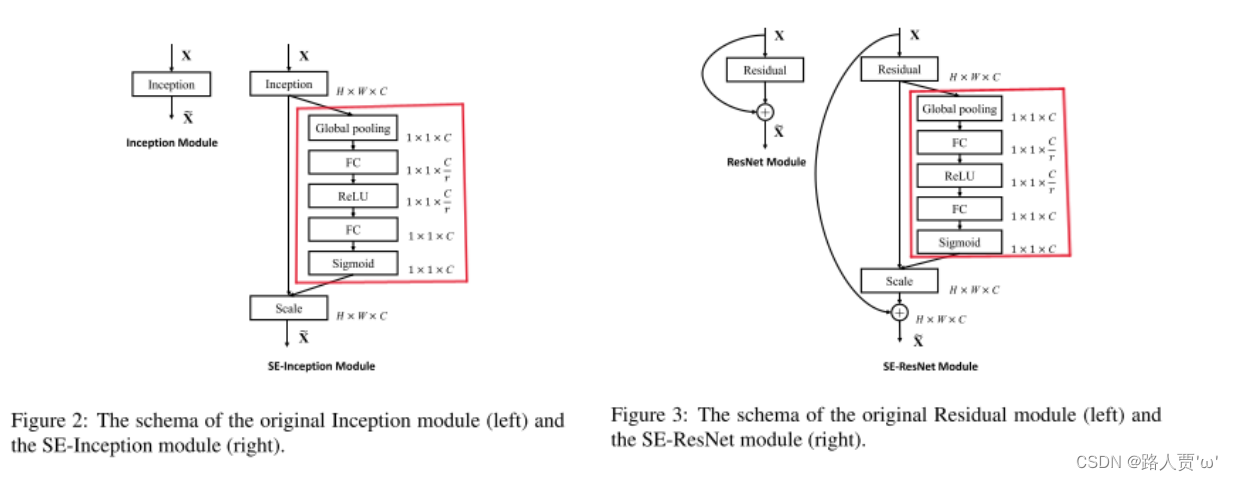
原理:通过一个全局平均池化层加两个全连接层以及全连接层对应激活【ReLU和sigmoid】组成的结构输出和输入特征同样数目的权重值,也就是每个特征通道的权重系数,学习一个通道的注意力出来,用于决定哪些通道应该重点提取特征,哪些部分放弃。
SE块详细过程
1.首先由 Inception结构 或 ResNet结构处理后的C×W×H特征图开始,通过Squeeze操作对特征图进行全局平均池化(GAP),得到1×1×C 的特征向量
2.紧接着两个 FC 层组成一个 Bottleneck 结构去建模通道间的相关性:
(1)经过第一个FC层,将C个通道变成 C/ r ,减少参数量,然后通过ReLU的非线性激活,到达第二个FC层
(2)经过第二个FC层,再将特征通道数恢复到C个,得到带有注意力机制的权重参数
3.最后经过Sigmoid激活函数,最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特征上。
二、SEblock的具体介绍
Sequeeze:Fsq操作就是使用通道的全局平均池化,将包含全局信息的W×H×C 的特征图直接压缩成一个1×1×C的特征向量,即将每个二维通道变成一个具有全局感受野的数值,此时1个像素表示1个通道,屏蔽掉空间上的分布信息,更好的利用通道间的相关性。具体操作:对原特征图50×512×7×7进行全局平均池化,然后得到了一个50×512×1×1大小的特征图,这个特征图具有全局感受野。
Excitation :基于特征通道间的相关性,每个特征通道生成一个权重,用来代表特征通道的重要程度。由原本全为白色的C个通道的特征,得到带有不同深浅程度的颜色的特征向量,也就是不同的重要程度。
具体操作:输出的50×512×1×1特征图,经过两个全连接层,最后用一 个类似于循环神经网络中门控机制,通过参数来为每个特征通道生成权重,参数被学习用来显式地建模特征通道间的相关性(论文中使用的是sigmoid)。50×512×1×1变成50×512 / 16×1×1,最后再还原回来:50×512×1×1
Reweight:将Excitation输出的权重看做每个特征通道的重要性,也就是对于U每个位置上的所有H×W上的值都乘上对应通道的权值,完成对原始特征的重校准。
具体操作:50×512×1×1通过expand_as得到50×512×7×7, 完成在通道维度上对原始特征的重标定,并作为下一级的输入数据。
三、PyTorch代码实现
(1)SEblock搭建
全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
'''-------------一、SE模块-----------------------------'''
#全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
class SE_Block(nn.Module):
def __init__(self, inchannel, ratio=16):
super(SE_Block, self).__init__()
# 全局平均池化(Fsq操作)
self.gap = nn.AdaptiveAvgPool2d((1, 1))
# 两个全连接层(Fex操作)
self.fc = nn.Sequential(
nn.Linear(inchannel, inchannel // ratio, bias=False), # 从 c -> c/r
nn.ReLU(),
nn.Linear(inchannel // ratio, inchannel, bias=False), # 从 c/r -> c
nn.Sigmoid()
)
def forward(self, x):
# 读取批数据图片数量及通道数
b, c, h, w = x.size()
# Fsq操作:经池化后输出b*c的矩阵
y = self.gap(x).view(b, c)
# Fex操作:经全连接层输出(b,c,1,1)矩阵
y = self.fc(y).view(b, c, 1, 1)
# Fscale操作:将得到的权重乘以原来的特征图x
return x * y.expand_as(x)
(2)将SEblock嵌入残差模块
SEblock可以灵活的加入到resnet等相关完整模型中,通常加在残差之前。【因为激活是sigmoid原因,存在梯度弥散问题,所以尽量不放到主信号通道去,即使本个残差模块有弥散问题,以不至于影响整个网络模型】
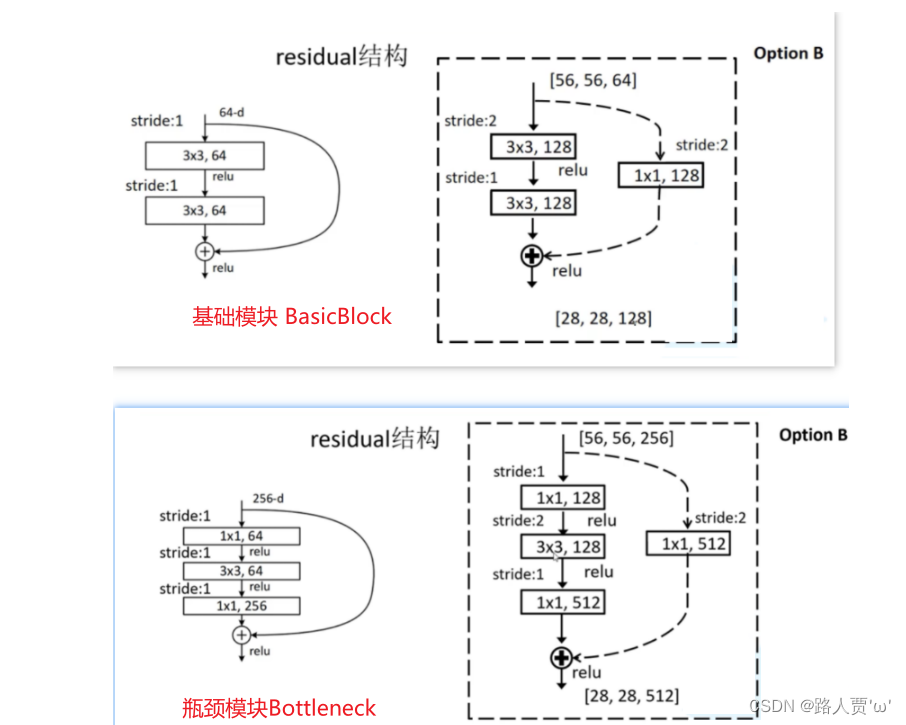
这里我们将SE模块分别嵌入ResNet的BasicBlock和Bottleneck中,得到 SEBasicBlock和SEBottleneck(具体解释可以看我之前写的ResNet代码复现+超详细注释(PyTorch))
BasicBlock模块
'''-------------二、BasicBlock模块-----------------------------'''
# 左侧的 residual block 结构(18-layer、34-layer)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inchannel, outchannel, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inchannel, outchannel, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(outchannel)
self.conv2 = nn.Conv2d(outchannel, outchannel, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(outchannel)
# SE_Block放在BN之后,shortcut之前
self.SE = SE_Block(outchannel)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != self.expansion*outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, self.expansion*outchannel,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*outchannel)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
SE_out = self.SE(out)
out = out * SE_out
out += self.shortcut(x)
out = F.relu(out)
return out
Bottleneck模块
'''-------------三、Bottleneck模块-----------------------------'''
# 右侧的 residual block 结构(50-layer、101-layer、152-layer)
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inchannel, outchannel, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inchannel, outchannel, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(outchannel)
self.conv2 = nn.Conv2d(outchannel, outchannel, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(outchannel)
self.conv3 = nn.Conv2d(outchannel, self.expansion*outchannel,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*outchannel)
# SE_Block放在BN之后,shortcut之前
self.SE = SE_Block(self.expansion*outchannel)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != self.expansion*outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, self.expansion*outchannel,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*outchannel)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
SE_out = self.SE(out)
out = out * SE_out
out += self.shortcut(x)
out = F.relu(out)
return out
(3)搭建SE_ResNet结构
'''-------------四、搭建SE_ResNet结构-----------------------------'''
class SE_ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(SE_ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1, bias=False) # conv1
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) # conv2_x
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2) # conv3_x
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2) # conv4_x
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2) # conv5_x
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.linear = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
out = self.linear(x)
return out
(4)网络模型的创建和测试
网络模型创建打印 SE_ResNet50
# test()
if __name__ == '__main__':
model = SE_ResNet50()
print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
打印模型如下
SE_ResNet(
(conv1): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=256, out_features=16, bias=False)
(1): ReLU()
(2): Linear(in_features=16, out_features=256, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=256, out_features=16, bias=False)
(1): ReLU()
(2): Linear(in_features=16, out_features=256, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential()
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=256, out_features=16, bias=False)
(1): ReLU()
(2): Linear(in_features=16, out_features=256, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential()
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=512, out_features=32, bias=False)
(1): ReLU()
(2): Linear(in_features=32, out_features=512, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=512, out_features=32, bias=False)
(1): ReLU()
(2): Linear(in_features=32, out_features=512, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential()
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=512, out_features=32, bias=False)
(1): ReLU()
(2): Linear(in_features=32, out_features=512, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential()
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=512, out_features=32, bias=False)
(1): ReLU()
(2): Linear(in_features=32, out_features=512, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential()
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=1024, out_features=64, bias=False)
(1): ReLU()
(2): Linear(in_features=64, out_features=1024, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=1024, out_features=64, bias=False)
(1): ReLU()
(2): Linear(in_features=64, out_features=1024, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential()
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=1024, out_features=64, bias=False)
(1): ReLU()
(2): Linear(in_features=64, out_features=1024, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential()
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=1024, out_features=64, bias=False)
(1): ReLU()
(2): Linear(in_features=64, out_features=1024, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential()
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=1024, out_features=64, bias=False)
(1): ReLU()
(2): Linear(in_features=64, out_features=1024, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential()
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=1024, out_features=64, bias=False)
(1): ReLU()
(2): Linear(in_features=64, out_features=1024, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential()
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=2048, out_features=128, bias=False)
(1): ReLU()
(2): Linear(in_features=128, out_features=2048, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=2048, out_features=128, bias=False)
(1): ReLU()
(2): Linear(in_features=128, out_features=2048, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential()
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(SE): SE_Block(
(gap): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=2048, out_features=128, bias=False)
(1): ReLU()
(2): Linear(in_features=128, out_features=2048, bias=False)
(3): Sigmoid()
)
)
(shortcut): Sequential()
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(linear): Linear(in_features=2048, out_features=10, bias=True)
)
torch.Size([1, 10])
使用torchsummary打印每个网络模型的详细信息
if __name__ == '__main__':
net = SE_ResNet50().cuda()
summary(net, (3, 224, 224))
打印模型如下
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,728
BatchNorm2d-2 [-1, 64, 224, 224] 128
Conv2d-3 [-1, 64, 224, 224] 4,096
BatchNorm2d-4 [-1, 64, 224, 224] 128
Conv2d-5 [-1, 64, 224, 224] 36,864
BatchNorm2d-6 [-1, 64, 224, 224] 128
Conv2d-7 [-1, 256, 224, 224] 16,384
BatchNorm2d-8 [-1, 256, 224, 224] 512
AdaptiveAvgPool2d-9 [-1, 256, 1, 1] 0
Linear-10 [-1, 16] 4,096
ReLU-11 [-1, 16] 0
Linear-12 [-1, 256] 4,096
Sigmoid-13 [-1, 256] 0
SE_Block-14 [-1, 256, 224, 224] 0
Conv2d-15 [-1, 256, 224, 224] 16,384
BatchNorm2d-16 [-1, 256, 224, 224] 512
Bottleneck-17 [-1, 256, 224, 224] 0
Conv2d-18 [-1, 64, 224, 224] 16,384
BatchNorm2d-19 [-1, 64, 224, 224] 128
Conv2d-20 [-1, 64, 224, 224] 36,864
BatchNorm2d-21 [-1, 64, 224, 224] 128
Conv2d-22 [-1, 256, 224, 224] 16,384
BatchNorm2d-23 [-1, 256, 224, 224] 512
AdaptiveAvgPool2d-24 [-1, 256, 1, 1] 0
Linear-25 [-1, 16] 4,096
ReLU-26 [-1, 16] 0
Linear-27 [-1, 256] 4,096
Sigmoid-28 [-1, 256] 0
SE_Block-29 [-1, 256, 224, 224] 0
Bottleneck-30 [-1, 256, 224, 224] 0
Conv2d-31 [-1, 64, 224, 224] 16,384
BatchNorm2d-32 [-1, 64, 224, 224] 128
Conv2d-33 [-1, 64, 224, 224] 36,864
BatchNorm2d-34 [-1, 64, 224, 224] 128
Conv2d-35 [-1, 256, 224, 224] 16,384
BatchNorm2d-36 [-1, 256, 224, 224] 512
AdaptiveAvgPool2d-37 [-1, 256, 1, 1] 0
Linear-38 [-1, 16] 4,096
ReLU-39 [-1, 16] 0
Linear-40 [-1, 256] 4,096
Sigmoid-41 [-1, 256] 0
SE_Block-42 [-1, 256, 224, 224] 0
Bottleneck-43 [-1, 256, 224, 224] 0
Conv2d-44 [-1, 128, 224, 224] 32,768
BatchNorm2d-45 [-1, 128, 224, 224] 256
Conv2d-46 [-1, 128, 112, 112] 147,456
BatchNorm2d-47 [-1, 128, 112, 112] 256
Conv2d-48 [-1, 512, 112, 112] 65,536
BatchNorm2d-49 [-1, 512, 112, 112] 1,024
AdaptiveAvgPool2d-50 [-1, 512, 1, 1] 0
Linear-51 [-1, 32] 16,384
ReLU-52 [-1, 32] 0
Linear-53 [-1, 512] 16,384
Sigmoid-54 [-1, 512] 0
SE_Block-55 [-1, 512, 112, 112] 0
Conv2d-56 [-1, 512, 112, 112] 131,072
BatchNorm2d-57 [-1, 512, 112, 112] 1,024
Bottleneck-58 [-1, 512, 112, 112] 0
Conv2d-59 [-1, 128, 112, 112] 65,536
BatchNorm2d-60 [-1, 128, 112, 112] 256
Conv2d-61 [-1, 128, 112, 112] 147,456
BatchNorm2d-62 [-1, 128, 112, 112] 256
Conv2d-63 [-1, 512, 112, 112] 65,536
BatchNorm2d-64 [-1, 512, 112, 112] 1,024
AdaptiveAvgPool2d-65 [-1, 512, 1, 1] 0
Linear-66 [-1, 32] 16,384
ReLU-67 [-1, 32] 0
Linear-68 [-1, 512] 16,384
Sigmoid-69 [-1, 512] 0
SE_Block-70 [-1, 512, 112, 112] 0
Bottleneck-71 [-1, 512, 112, 112] 0
Conv2d-72 [-1, 128, 112, 112] 65,536
BatchNorm2d-73 [-1, 128, 112, 112] 256
Conv2d-74 [-1, 128, 112, 112] 147,456
BatchNorm2d-75 [-1, 128, 112, 112] 256
Conv2d-76 [-1, 512, 112, 112] 65,536
BatchNorm2d-77 [-1, 512, 112, 112] 1,024
AdaptiveAvgPool2d-78 [-1, 512, 1, 1] 0
Linear-79 [-1, 32] 16,384
ReLU-80 [-1, 32] 0
Linear-81 [-1, 512] 16,384
Sigmoid-82 [-1, 512] 0
SE_Block-83 [-1, 512, 112, 112] 0
Bottleneck-84 [-1, 512, 112, 112] 0
Conv2d-85 [-1, 128, 112, 112] 65,536
BatchNorm2d-86 [-1, 128, 112, 112] 256
Conv2d-87 [-1, 128, 112, 112] 147,456
BatchNorm2d-88 [-1, 128, 112, 112] 256
Conv2d-89 [-1, 512, 112, 112] 65,536
BatchNorm2d-90 [-1, 512, 112, 112] 1,024
AdaptiveAvgPool2d-91 [-1, 512, 1, 1] 0
Linear-92 [-1, 32] 16,384
ReLU-93 [-1, 32] 0
Linear-94 [-1, 512] 16,384
Sigmoid-95 [-1, 512] 0
SE_Block-96 [-1, 512, 112, 112] 0
Bottleneck-97 [-1, 512, 112, 112] 0
Conv2d-98 [-1, 256, 112, 112] 131,072
BatchNorm2d-99 [-1, 256, 112, 112] 512
Conv2d-100 [-1, 256, 56, 56] 589,824
BatchNorm2d-101 [-1, 256, 56, 56] 512
Conv2d-102 [-1, 1024, 56, 56] 262,144
BatchNorm2d-103 [-1, 1024, 56, 56] 2,048
AdaptiveAvgPool2d-104 [-1, 1024, 1, 1] 0
Linear-105 [-1, 64] 65,536
ReLU-106 [-1, 64] 0
Linear-107 [-1, 1024] 65,536
Sigmoid-108 [-1, 1024] 0
SE_Block-109 [-1, 1024, 56, 56] 0
Conv2d-110 [-1, 1024, 56, 56] 524,288
BatchNorm2d-111 [-1, 1024, 56, 56] 2,048
Bottleneck-112 [-1, 1024, 56, 56] 0
Conv2d-113 [-1, 256, 56, 56] 262,144
BatchNorm2d-114 [-1, 256, 56, 56] 512
Conv2d-115 [-1, 256, 56, 56] 589,824
BatchNorm2d-116 [-1, 256, 56, 56] 512
Conv2d-117 [-1, 1024, 56, 56] 262,144
BatchNorm2d-118 [-1, 1024, 56, 56] 2,048
AdaptiveAvgPool2d-119 [-1, 1024, 1, 1] 0
Linear-120 [-1, 64] 65,536
ReLU-121 [-1, 64] 0
Linear-122 [-1, 1024] 65,536
Sigmoid-123 [-1, 1024] 0
SE_Block-124 [-1, 1024, 56, 56] 0
Bottleneck-125 [-1, 1024, 56, 56] 0
Conv2d-126 [-1, 256, 56, 56] 262,144
BatchNorm2d-127 [-1, 256, 56, 56] 512
Conv2d-128 [-1, 256, 56, 56] 589,824
BatchNorm2d-129 [-1, 256, 56, 56] 512
Conv2d-130 [-1, 1024, 56, 56] 262,144
BatchNorm2d-131 [-1, 1024, 56, 56] 2,048
AdaptiveAvgPool2d-132 [-1, 1024, 1, 1] 0
Linear-133 [-1, 64] 65,536
ReLU-134 [-1, 64] 0
Linear-135 [-1, 1024] 65,536
Sigmoid-136 [-1, 1024] 0
SE_Block-137 [-1, 1024, 56, 56] 0
Bottleneck-138 [-1, 1024, 56, 56] 0
Conv2d-139 [-1, 256, 56, 56] 262,144
BatchNorm2d-140 [-1, 256, 56, 56] 512
Conv2d-141 [-1, 256, 56, 56] 589,824
BatchNorm2d-142 [-1, 256, 56, 56] 512
Conv2d-143 [-1, 1024, 56, 56] 262,144
BatchNorm2d-144 [-1, 1024, 56, 56] 2,048
AdaptiveAvgPool2d-145 [-1, 1024, 1, 1] 0
Linear-146 [-1, 64] 65,536
ReLU-147 [-1, 64] 0
Linear-148 [-1, 1024] 65,536
Sigmoid-149 [-1, 1024] 0
SE_Block-150 [-1, 1024, 56, 56] 0
Bottleneck-151 [-1, 1024, 56, 56] 0
Conv2d-152 [-1, 256, 56, 56] 262,144
BatchNorm2d-153 [-1, 256, 56, 56] 512
Conv2d-154 [-1, 256, 56, 56] 589,824
BatchNorm2d-155 [-1, 256, 56, 56] 512
Conv2d-156 [-1, 1024, 56, 56] 262,144
BatchNorm2d-157 [-1, 1024, 56, 56] 2,048
AdaptiveAvgPool2d-158 [-1, 1024, 1, 1] 0
Linear-159 [-1, 64] 65,536
ReLU-160 [-1, 64] 0
Linear-161 [-1, 1024] 65,536
Sigmoid-162 [-1, 1024] 0
SE_Block-163 [-1, 1024, 56, 56] 0
Bottleneck-164 [-1, 1024, 56, 56] 0
Conv2d-165 [-1, 256, 56, 56] 262,144
BatchNorm2d-166 [-1, 256, 56, 56] 512
Conv2d-167 [-1, 256, 56, 56] 589,824
BatchNorm2d-168 [-1, 256, 56, 56] 512
Conv2d-169 [-1, 1024, 56, 56] 262,144
BatchNorm2d-170 [-1, 1024, 56, 56] 2,048
AdaptiveAvgPool2d-171 [-1, 1024, 1, 1] 0
Linear-172 [-1, 64] 65,536
ReLU-173 [-1, 64] 0
Linear-174 [-1, 1024] 65,536
Sigmoid-175 [-1, 1024] 0
SE_Block-176 [-1, 1024, 56, 56] 0
Bottleneck-177 [-1, 1024, 56, 56] 0
Conv2d-178 [-1, 512, 56, 56] 524,288
BatchNorm2d-179 [-1, 512, 56, 56] 1,024
Conv2d-180 [-1, 512, 28, 28] 2,359,296
BatchNorm2d-181 [-1, 512, 28, 28] 1,024
Conv2d-182 [-1, 2048, 28, 28] 1,048,576
BatchNorm2d-183 [-1, 2048, 28, 28] 4,096
AdaptiveAvgPool2d-184 [-1, 2048, 1, 1] 0
Linear-185 [-1, 128] 262,144
ReLU-186 [-1, 128] 0
Linear-187 [-1, 2048] 262,144
Sigmoid-188 [-1, 2048] 0
SE_Block-189 [-1, 2048, 28, 28] 0
Conv2d-190 [-1, 2048, 28, 28] 2,097,152
BatchNorm2d-191 [-1, 2048, 28, 28] 4,096
Bottleneck-192 [-1, 2048, 28, 28] 0
Conv2d-193 [-1, 512, 28, 28] 1,048,576
BatchNorm2d-194 [-1, 512, 28, 28] 1,024
Conv2d-195 [-1, 512, 28, 28] 2,359,296
BatchNorm2d-196 [-1, 512, 28, 28] 1,024
Conv2d-197 [-1, 2048, 28, 28] 1,048,576
BatchNorm2d-198 [-1, 2048, 28, 28] 4,096
AdaptiveAvgPool2d-199 [-1, 2048, 1, 1] 0
Linear-200 [-1, 128] 262,144
ReLU-201 [-1, 128] 0
Linear-202 [-1, 2048] 262,144
Sigmoid-203 [-1, 2048] 0
SE_Block-204 [-1, 2048, 28, 28] 0
Bottleneck-205 [-1, 2048, 28, 28] 0
Conv2d-206 [-1, 512, 28, 28] 1,048,576
BatchNorm2d-207 [-1, 512, 28, 28] 1,024
Conv2d-208 [-1, 512, 28, 28] 2,359,296
BatchNorm2d-209 [-1, 512, 28, 28] 1,024
Conv2d-210 [-1, 2048, 28, 28] 1,048,576
BatchNorm2d-211 [-1, 2048, 28, 28] 4,096
AdaptiveAvgPool2d-212 [-1, 2048, 1, 1] 0
Linear-213 [-1, 128] 262,144
ReLU-214 [-1, 128] 0
Linear-215 [-1, 2048] 262,144
Sigmoid-216 [-1, 2048] 0
SE_Block-217 [-1, 2048, 28, 28] 0
Bottleneck-218 [-1, 2048, 28, 28] 0
AdaptiveAvgPool2d-219 [-1, 2048, 1, 1] 0
Linear-220 [-1, 10] 20,490
================================================================
Total params: 26,035,786
Trainable params: 26,035,786
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 3914.25
Params size (MB): 99.32
Estimated Total Size (MB): 4014.14
----------------------------------------------------------------
Process finished with exit code 0
(5)完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
'''-------------一、SE模块-----------------------------'''
#全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
class SE_Block(nn.Module):
def __init__(self, inchannel, ratio=16):
super(SE_Block, self).__init__()
# 全局平均池化(Fsq操作)
self.gap = nn.AdaptiveAvgPool2d((1, 1))
# 两个全连接层(Fex操作)
self.fc = nn.Sequential(
nn.Linear(inchannel, inchannel // ratio, bias=False), # 从 c -> c/r
nn.ReLU(),
nn.Linear(inchannel // ratio, inchannel, bias=False), # 从 c/r -> c
nn.Sigmoid()
)
def forward(self, x):
# 读取批数据图片数量及通道数
b, c, h, w = x.size()
# Fsq操作:经池化后输出b*c的矩阵
y = self.gap(x).view(b, c)
# Fex操作:经全连接层输出(b,c,1,1)矩阵
y = self.fc(y).view(b, c, 1, 1)
# Fscale操作:将得到的权重乘以原来的特征图x
return x * y.expand_as(x)
'''-------------二、BasicBlock模块-----------------------------'''
# 左侧的 residual block 结构(18-layer、34-layer)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inchannel, outchannel, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inchannel, outchannel, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(outchannel)
self.conv2 = nn.Conv2d(outchannel, outchannel, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(outchannel)
# SE_Block放在BN之后,shortcut之前
self.SE = SE_Block(outchannel)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != self.expansion*outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, self.expansion*outchannel,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*outchannel)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
SE_out = self.SE(out)
out = out * SE_out
out += self.shortcut(x)
out = F.relu(out)
return out
'''-------------三、Bottleneck模块-----------------------------'''
# 右侧的 residual block 结构(50-layer、101-layer、152-layer)
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inchannel, outchannel, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inchannel, outchannel, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(outchannel)
self.conv2 = nn.Conv2d(outchannel, outchannel, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(outchannel)
self.conv3 = nn.Conv2d(outchannel, self.expansion*outchannel,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*outchannel)
# SE_Block放在BN之后,shortcut之前
self.SE = SE_Block(self.expansion*outchannel)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != self.expansion*outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, self.expansion*outchannel,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*outchannel)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
SE_out = self.SE(out)
out = out * SE_out
out += self.shortcut(x)
out = F.relu(out)
return out
'''-------------四、搭建SE_ResNet结构-----------------------------'''
class SE_ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(SE_ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1, bias=False) # conv1
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) # conv2_x
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2) # conv3_x
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2) # conv4_x
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2) # conv5_x
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.linear = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
out = self.linear(x)
return out
def SE_ResNet18():
return SE_ResNet(BasicBlock, [2, 2, 2, 2])
def SE_ResNet34():
return SE_ResNet(BasicBlock, [3, 4, 6, 3])
def SE_ResNet50():
return SE_ResNet(Bottleneck, [3, 4, 6, 3])
def SE_ResNet101():
return SE_ResNet(Bottleneck, [3, 4, 23, 3])
def SE_ResNet152():
return SE_ResNet(Bottleneck, [3, 8, 36, 3])
'''
if __name__ == '__main__':
model = SE_ResNet50()
print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
# test()
'''
if __name__ == '__main__':
net = SE_ResNet50().cuda()
summary(net, (3, 224, 224))
本篇就结束了,欢迎大家留言讨论呀!
|