应用统计学与R语言实现学习笔记(四) |
您所在的位置:网站首页 › 基于正态总体的抽样分布定理 › 应用统计学与R语言实现学习笔记(四) |
应用统计学与R语言实现学习笔记(四)
|
Chapter 4 Sampling And Sample Distribution
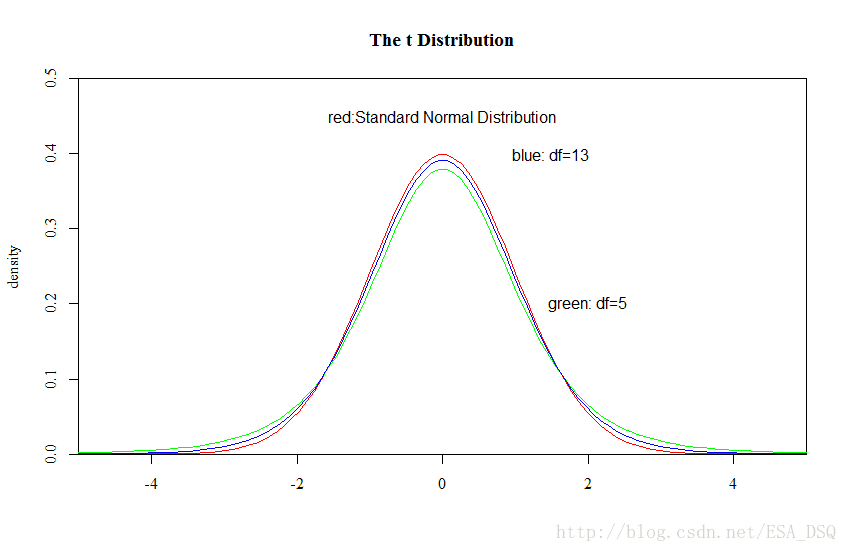
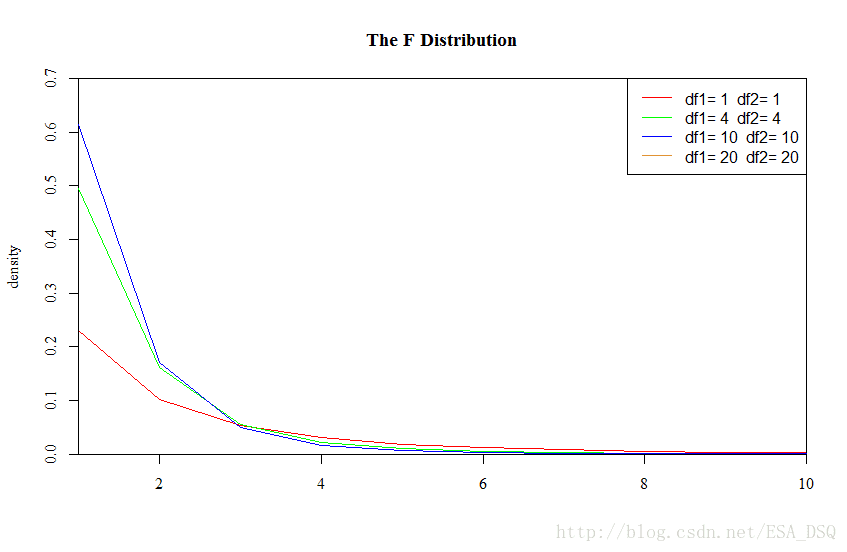
本篇是第四章,内容主要是抽样方法与抽样分布。这一章内容比较多(从抽样方法一直到许多分布函数,尤其是介绍了四个重要分布——正态分布、卡方分布、t分布、F分布,以及部分统计推断的内容)。 Chapter 4 Sampling And Sample Distribution 抽样方法正态分布三种不同性质的分布一个总体样本统计量的抽样分布两个总体样本统计量的抽样分布附录 1.抽样方法抽样调查的概念前面已经有所涉及到,这里就不详述了。大部分情况下,普查是不太可能的,所以抽样调查是科学研究中应用最为广泛的收集数据的方法。但是正如前面在谈论precision和accuracy问题的时候说的,我们希望数据的质量是Low Bias and Low Variance,抽样调查的样本既能很好地代表总体(非抽样误差小),同时多次抽样的话,也希望抽样的样本大致都接近,降低抽样误差。所以从统计学诞生至今,已经提出了很多的抽样方法。可以说并没有任何一种方法能完全避免这些误差,这些方法需要根据具体情境具体使用。 总的来说,抽样方法可以分为两大类:概率抽样与非概率抽样。 概率抽样包括了: 简单随机抽样 系统抽样分层抽样整群抽样多阶段抽样概率抽样是根据一个已知的概率来抽取样本单位(也称为随机抽样),概率抽样要求按照一定的概率随机抽取样本,也就是说每个样本都有一定的机会被抽中,同时每个样本被抽中的概率是可以已知或计算出来的,而当运用概率抽样的样本进行参数估计的时候必须考虑样本被抽中的概率(某种程度来说感觉类似贝叶斯,先验概率和后验概率的问题)。 简单随机抽样——从总体N个单位里抽出n个单位作为样本(可以重复抽样,也可以不重复抽样),最常用的抽样方式,参数估计和假设检验主要依据的就是简单随机样本。 系统抽样——将总体中的所有单位(抽样单位)按一定顺序排列, 在规定的范围内随机地抽取一个单位作为初始单位, 然后按事先规定好的规则确定其他样本单位(先从数字1到k之间随机抽取一个数字r作为初始单位,以后依次取r+k, r+2k…等单位)。 分层抽样——将总体单位按某种特征或某种规则划分为不同的层(Strata), 然后从不同的层中独立、 随机地抽取样本。 整群抽样——将总体中若干个单位合并为组(群), 抽样时直接抽取群, 然后对中选群中的所有单位全部实施调查。 多阶段抽样——先抽取群, 但并不是调查群内的所有单位, 而是再进行一步抽样,从选中的群中抽取出若干个单位进行调查(群是初级抽样单位,第二阶段抽取的是最终抽样单位。将该方法推广, 使抽样的段数增多, 就称为多阶段抽样) 非概率抽样包括了: 方便抽样判断抽样自愿样本滚雪球抽样配额抽样非概率抽样则不是按照随机的原则选取样本,而是根据研究的具体需求选取调查样本。 方便抽样——研究员依据方便的原则选取对应的样本。 判断抽样——研究员根据自己的判断选择样本。 自愿样本——被调查者自愿参加调查提供信息。举个跟地学相关的例子——志愿地理信息(Volunteer Geographcial Information,VGI),是指利用工具创建、组装和传播个人资源提供的地理数据,像社交媒体中的签到。 滚雪球抽样——首先选择一组进行调查,让调查者提供另外一些属于调查总体的调查对象,然后持续下去。 配额抽样——先将体中的所有单位按一定的标志(变量) 分为若干类, 然后在每个类中采用方便抽样或判断抽样的方式选取样本单位。 总的来说,各种抽样方式各有各有的优缺点,根据研究具体情况进行选择。而实际研究中简单随机抽样的应用更多些,这边提供R语言中做简单随机抽样的代码示例。 #N表示总体的数据,n为抽样单位,replace=FALSE代表不重复抽样,replace=TRUE代表重复抽样。 n30时, t 分布可用标准正态分布近似)t分布的性质可以根据这张图来看。 t分布的应用是在求样本均值与样本标准差之比上 样本均值与样本标准差之比的分布为: t=x¯−μs/n√∼t(n−1) 自由度为(n-1)的t 分布 5.两个总体样本统计量的抽样分布其实从前面第4点内容可以看出,其实实际应用中,均值、比例、方差的估计是比较多的,因此这三个总体样本统计量的抽样分布特别提出来了。而第4点讨论的是一个总体的,两个总体的也可以类比,道理是一样的。 两个样本均值之差的抽样分布: 两个总体均为正态分布,即 X1∼N(μ1,σ21),X2∼N(μ2,σ22) 两个样本均值之差的抽样分布服从正态分布,其分布的数学期望为两个总体均值之差: E(x¯1−x¯2)=μ1−μ2 方差为各自的方差之和: σ2x¯1−x¯2=σ21n1+σ22n2两个样本比例之差的抽样分布: 两个总体都服从二项分布。分别从两个总体中抽取容量为 n1 和 n2 的独立样本,当两个样本都为大样本时,两个样本比例之差的抽样分布可用正态分布来近似。分布的数学期望为: E(p¯1−p¯2)=p1−p2 方差为各自方差之和: σ2p¯1−p¯2=p1(1−p1)n1+p2(1−p2)n2最后的最后,我们来介绍本片的最后一个重要的分布——F分布。 F分布: 设若U为服从自由度为n1的χ2分布,即U∼χ2(n1), V为服从自由度为n2的χ2分布,即V∼χ2(n2),且U与V相互独立, F=U/n1V/n2,F服从自由度n1和n2的F分布, 记为F∼F(n1,n2) 不同自由度下的F分布两个样本方差比的抽样分布: 两个总体都为正态分布,即 X1∼N(μ1,σ21),X2∼N(μ2,σ22) 从两个总体中分别抽取容量为 n1 和 n2 的独立样本。两个样本方差比的抽样分布, 服从分子自由度 (n1−1) , 分母自由度为 (n2−1) 的F分布, 即 s21/σ21s22/σ22∼F(n1−1,n2−1) 附录常用统计量公式 样本均值: X¯=1n∑i=1nXi 样本方差: S2=1n−1∑i=1n(Xi−X¯)2 样本标准差: S=1n−1∑i=1n(Xi−X¯)2−−−−−−−−−−−−−−−−√ 样本k阶原点矩: Ak=1n∑i=1nXki(k=1,2,⋯) 样本k阶中心矩: Bk=1n∑i=1n(Xi−X¯)k(k=1,2,⋯) 各统计量的观察值: x¯=1n∑i=1nxi s2=1n−1∑i=1n(xi−x¯)2 ak=1n∑i=1nxki(k=1,2,⋯) bk=1n∑i=1n(xi−x¯)k(k=1,2,⋯) |
【本文地址】
今日新闻 |
推荐新闻 |