基于Python的豆瓣网站数据爬取与分析 |
您所在的位置:网站首页 › 基于python爬取豆瓣图书信息 › 基于Python的豆瓣网站数据爬取与分析 |
基于Python的豆瓣网站数据爬取与分析
|
基于Python的豆瓣网站数据爬取与分析
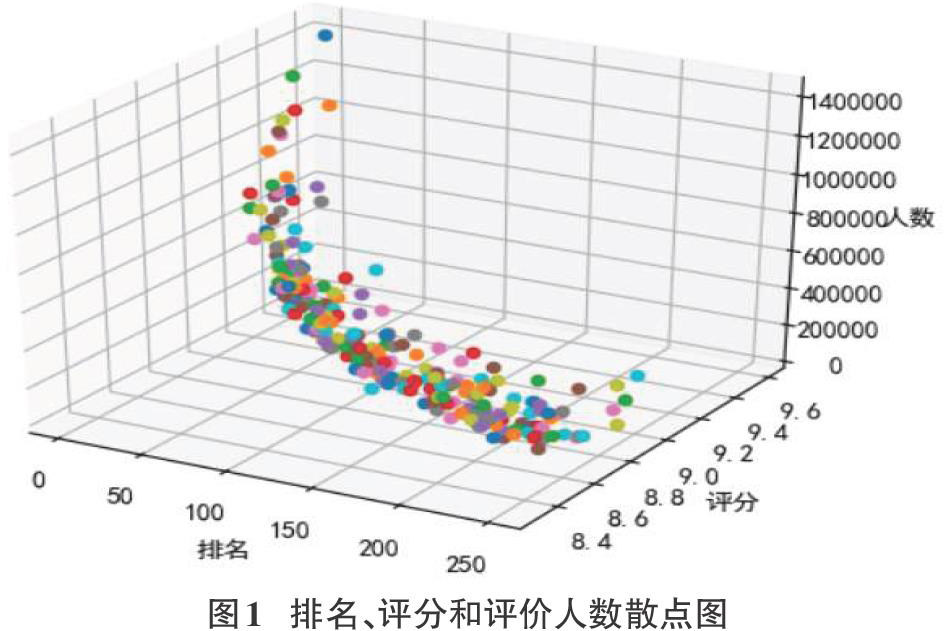
摘要:大数据时代,随着社交网络的发展,社会媒体数据量呈现指数级增长。通过基于Python的网络爬虫程序爬取豆瓣网站的有关数据,使用非关系型数据库MongoDB存储数据,并利用Matplotlib和PyEcharts对爬取结果进行了可视化分析。对豆瓣电影和图书Top250排行榜的数据进行可视化分析,可以了解作品排名、评分、年份、地区和导演及作家的分布情况,从而分析得出数据之间的相关性和文化产业的发展趋势。(剩余5562字) ~~试读结束~~ 购买全文4.00元 打印文章 网站仅支持在线阅读(不支持PDF下载),如需保存文章,可以选择【打印】保存。 下一篇 大数据背景下高校图书馆馆藏地方特色文献的有效利用 |
 打开文本图片集
打开文本图片集
【本文地址】
今日新闻 |
推荐新闻 |