用python构建线性回归和决策树模型实现房价预测 |
您所在的位置:网站首页 › 基于python对销量的预测 › 用python构建线性回归和决策树模型实现房价预测 |
用python构建线性回归和决策树模型实现房价预测
|
国家整体经济水平的不断提高和人们生活质量的提升,刺激着房屋价格也在不断的上涨,具体可查看国家统计局发布的数据。房价是由多个因素决定的,比如国家的宏观调控、居民人均可支配收入、房地产开发投资、住宅销售面积等,这些因素都影响着房价的走势。   Step1:数据基本统计分析
Step1:数据基本统计分析
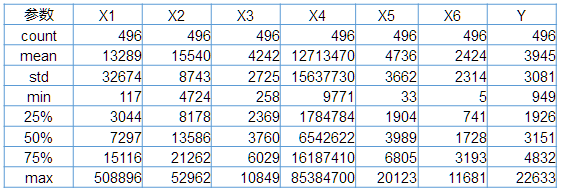
首先,查看数据基本分布情况。 #-*- coding: utf-8 -*- import pandas as pd import numpy as np ##读取数据,查看数据基本分布 house=pd.read_csv('datasets/housing_2.csv',index_col=0,encoding='gb2312') print (house.shape) print (house.describe()) #index=house.index #print (index)
运用sklearn.model_selection的train_test_split进行数据集划分,也可以用k折交叉验证(KFold)。 ##划分训练集和测试集 from sklearn.model_selection import train_test_split #划分数据集 house_train,house_test=train_test_split(house,test_size=0.3, random_state=0) print ('训练集描述性统计:') print (house_train.describe().round(2)) print ('验证集描述性统计:') print (house_test.describe().round(2)) #['X2','X3','X5','X6'] features=['X1','X2','X3','X4','X5','X6'] X_train=house_train.ix[:,features] y_train=house_train.ix[:,'Y'] X_test=house_test.ix[:,features] y_test=house_test.ix[:,'Y']
为了更全面的评估模型效果,分别运用sklearn.linear_model和statsmodels.api.sm构建线性回归模型,综合两个模型的结果更好的解释模型。其中 sklearn(https://scikit-learn.org/stable/index.html)是机器学习中一个常用的python第三方模块,里面对一些常用的机器学习方法进行了封装,比如SVM、KNN、贝叶斯、线性回归、逻辑回归、决策树、随机森林、xgboost、GBDT、boosting、神经网络NN;statsmodels(http://www.statsmodels.org)用于拟合多种统计模型,比如方差分析、ARIMA、线性回归等,执行统计测试以及数据探索和可视化。 #线性回归模型训练、评估,为了更全面的评估模型的效果,此处使用了sklearn.linear_model和statsmodels.api.sm建模,综合两个模型的结果更好的解释模型 from sklearn import linear_model from sklearn.metrics import mean_squared_error,explained_variance_score,mean_absolute_error,r2_score reg = linear_model.LinearRegression() reg.fit (X_train,y_train) print ('coef:',reg.coef_) #print (reg.predict(X_test)) print ("线性回归评估--训练集:") print ('训练r^2:',reg.score(X_train,y_train)) print ('均方差',mean_squared_error(y_train,reg.predict(X_train))) print ('绝对差',mean_absolute_error(y_train,reg.predict(X_train))) print ('解释度',explained_variance_score(y_train,reg.predict(X_train))) print ("线性回归评估--验证集:") print ('验证r^2:',reg.score(X_test,y_test)) print ('均方差',mean_squared_error(y_test,reg.predict(X_test))) print ('绝对差',mean_absolute_error(y_test,reg.predict(X_test))) print ('解释度',explained_variance_score(y_test,reg.predict(X_test))) import statsmodels.api as sm X_train=sm.add_constant(X_train) est=sm.OLS(y_train,X_train).fit() print (est.summary()) #print (reg.predict(house.ix[:,0:6]))
|

 查看各变量间的相关系数。
查看各变量间的相关系数。
 根据相关系数表和散点图矩阵,X2城镇居民家庭人均可支配收入与Y商品房平均销售价格的线性相关性最大,相关系数超过了0.8,其次是X4房地产开发投资额,相关系数超过了0.5。但是,X3总人口数与X5住宅房屋竣工面积、X4房地产开发投资额与X6商品房销售面积的相关系数超过了0.8,即各因素间存在多重共线性,不满足相互独立的条件,不太适合直接进行线性回归。但是为了对比模型效果,后面还是构建了线性回归模型。
根据相关系数表和散点图矩阵,X2城镇居民家庭人均可支配收入与Y商品房平均销售价格的线性相关性最大,相关系数超过了0.8,其次是X4房地产开发投资额,相关系数超过了0.5。但是,X3总人口数与X5住宅房屋竣工面积、X4房地产开发投资额与X6商品房销售面积的相关系数超过了0.8,即各因素间存在多重共线性,不满足相互独立的条件,不太适合直接进行线性回归。但是为了对比模型效果,后面还是构建了线性回归模型。
 用6个影响因素建立线性回归模型,发现虽然模型的拟合优度
R
2
R^2
R2和调整的
R
2
R^2
R2超过了0.8,即拟合效果很好,但是X1和X4没通过显著性检验((P>|t|)
用6个影响因素建立线性回归模型,发现虽然模型的拟合优度
R
2
R^2
R2和调整的
R
2
R^2
R2超过了0.8,即拟合效果很好,但是X1和X4没通过显著性检验((P>|t|)【本文地址】
今日新闻 |
推荐新闻 |