情感计算综述 |
您所在的位置:网站首页 › 基于eeg的情绪识别 › 情感计算综述 |
情感计算综述
|
目录 一、背景介绍 基于物理信号 基于生理信号 物理-生理信号融合 二、情感模型 2.1 离散情感模型 2.2 维度情感模型 三、情感计算数据库 3.1 文本数据库 3.2 语音/音频数据库 3.3 视觉数据库 3.3.1 面部表情数据库 3.3.2 肢体动作情感数据库 3.4 生理数据库 3.5 多模态数据库 四、单模态情感识别 4.1 文本情感分析(TSA) 4.1.1 ML-based TSA 4.1.2 DL-based TSA 4.2 音频情感识别(SER) 4.2.1 ML-based SER 4.2.2 DL-based SER 4.3 视觉情感识别 4.3.1 面部表情识别 4.3.1.1 ML-based FER 4.3.2 身体姿态情感识别 4.3.2.1 ML-based EBGR 4.3.2.2 DL-based EBGR 4.4 基于生理的情感识别 4.4.1 EEG-based emotion recognition 4.4.1.1 ML-based EEG emotion recognition 4.4.1.2 DL-based EEG emotion recognition 4.4.2 ECG-based emotion recognition 4.4.2.1 ML-based ECG emotion recognition 4.4.2.2 DL-based ECG emotion recognition 五、 多模态情感分析 5.1 多物理模态融合进行情感分析 5.1.1 视音频情感识别 5.1.2 文本音频情感识别 5.1.3 视-听-文情感识别 5.2 多生理模态融合情感分析 5.3 物理-生理模态融合的情感分析 六、讨论 6.1 不同信号对单峰情感识别的影响 6.2 模态组合及融合策略对多模态情感分析的影响 6.3 基于ML和基于DL的模型对情感计算的影响 6.4 一些潜在因素对情感计算的影响 6.5情感计算在现实场景中的应用 七、未来研究展望 本篇综述主要参考下面这篇论文  论文链接如下A systematic review on affective computing: emotion models, databases, and recent advances - ScienceDirect 论文链接如下A systematic review on affective computing: emotion models, databases, and recent advances - ScienceDirect 一、背景介绍 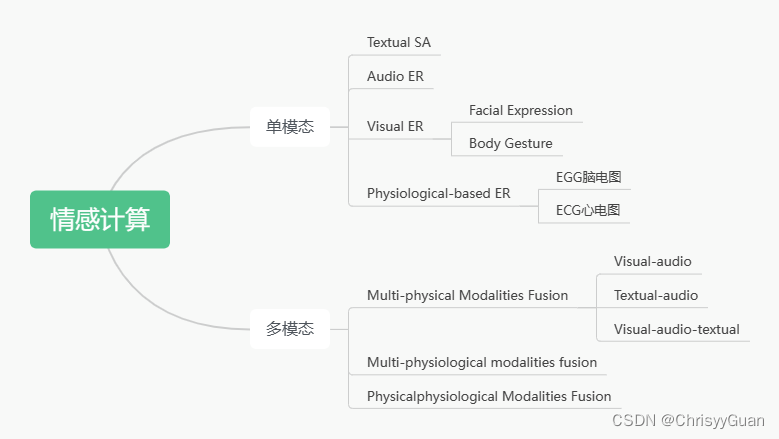
SA: Sentiment Analysis,ER: Emotion Recognition 情感计算主要分为单模态和多模态的研究,其中单模态包括文本SA, 音频ER,视觉ER和基于生理信号的ER;多模态包括多物理模态融合、多生理模态融合和物理-生理模态融合。 基于物理信号现有的基于物理的情感识别研究主要采用视觉、文本和音频三种方式。对于视觉形态,大多数研究采用了FER和FMEA,以及3D FER。此外,Noroozi等回顾了表征学习和从身体姿态开始的情绪识别,然后是基于语音或面部和身体姿态的多模态情绪识别。对于文本模态,可以根据会话中的内隐情绪来完成情感分析和情感识别。Han等人使用三种物理信号提出了基于深度学习的对抗性训练,旨在解决与情感AI系统相关的各种挑战。相比之下,Erik等人考虑了多模态融合,并提供了与单模态分析相比,不同融合类别下多模态情感识别潜在性能改进的关键分析。 基于生理信号利用嵌入式设备获取生理信号,使生理情感识别成为可能。基于生理信号的情感识别主要包括基于EEG(脑电图)和ECG(心电图)的机器学习和深度学习方法。 物理-生理信号融合在情感分析中同时使用生理和生理信号是一个明显的趋势。可以根据视听和生理信号来学习空间、时间和联合特征表示。 二、情感模型Emotion/Affect的定义对于建立情感的标准至关重要。十九世纪七十年代,Ekman第一次提出了emotions的基本概念。情感计算有两种通用的情感模型:离散情感模型和维度(连续)情感模型。 2.1 离散情感模型离散情感模型,也称为分类情感模型,将情感定义为有限的类别。两种被广泛使用的离散情绪模型分别是Ekman的六类基本情感和Plutchik的情感轮模型,分别如下图所示。
维度情感模型弥补了离散情感模型的局限性,其中一个最被认可的模型是Pleasure-Arousal-Dominance (PAD),如下图所示:
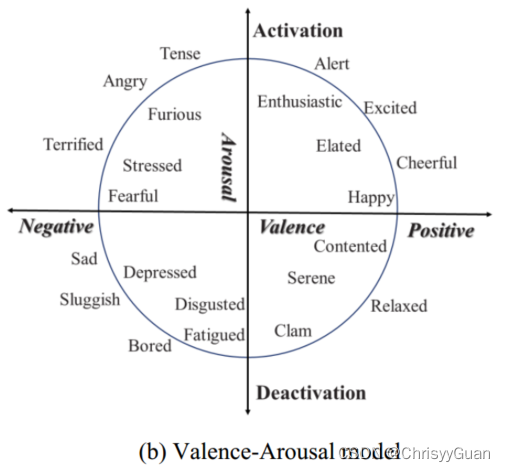
PAD模型具有三维空间: 1)Pleasure(Valence)维度,代表人类从极度痛苦到狂喜的快乐程度; 2)Arousal(Activation)维度,测量生理活动和心理警觉性水平; 3)Dominance(Attention)维度,表达影响周围环境和他人的感觉,或被周围环境和他人影响的感觉 由于PAD模型中的Pleasure和Arousal两个维度可以代表绝大多数不同的情绪,因此Russell提出了一个基于Valence-Arousal的circumplex模型来代表复杂的情绪。该模型定义了一个连续的二维情感空间模型,其轴为Valance(愉快或不愉快的程度)和Arousal(激活或失活的程度),如下图所示。圆周模型由四个象限组成。第一象限,积极效价的激活唤醒,显示了与快乐情绪相关的感受;第三象限,低唤醒和负效价,与悲伤情绪有关。第二象限显示愤怒情绪,具有高唤醒和负效价;第四象限为低唤醒、正效价的平静情绪。
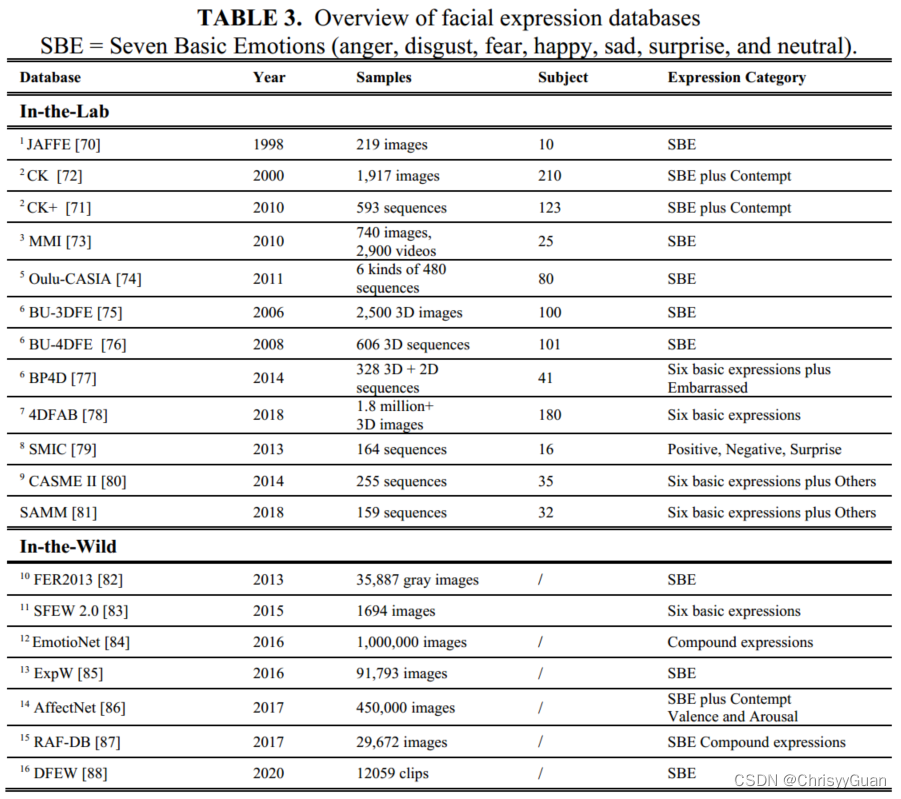
情感计算数据库根据数据模态可分为文本数据库、语音/音频数据库、视觉数据库、生理数据库和多模态数据库。 3.1 文本数据库TSA数据库主要有Multi-domain sentiment (MDS)和二元情感分类数据库IMDB。前者包含了从亚马逊网站获取的10万多句产品评论。这些句子被标记为两种情绪类别(积极和消极)和五种情绪类别(强积极,弱积极,中性,弱消极,强消极);后者提供25000条极具极性的电影评论用于训练,25000条用于测试。此外, Stanford sentiment treebank(SST)是由斯坦福大学标注的语义词汇数据库。它在11855个句子的解析树中包含215154个短语的细粒度情感标签,并且它是第一个具有完全标记的解析树的语料库。 3.2 语音/音频数据库语音数据库可以分为两种类型:自发和非自发(模拟和诱导) 非自发数据库Emo-DB包含了10位演员(5男5女)以happy, angry, anxious, fearful, bored and disgusting 的方式说出的约500句话。自发数据库Belfast是在英国北爱尔兰女王大学对40名受试者(年龄在18至69岁之间,20名男性和20名女性)进行记录的。每位受试者参加五项测试,每项测试都包含立体声短视频(长度为5到60秒),并与五种情绪倾向中的一种有关: anger, sadness, happiness, fear, and neutrality. 3.3 视觉数据库视觉数据库也可以分为两类:面部表情数据库和肢体动作情感数据库。 3.3.1 面部表情数据库
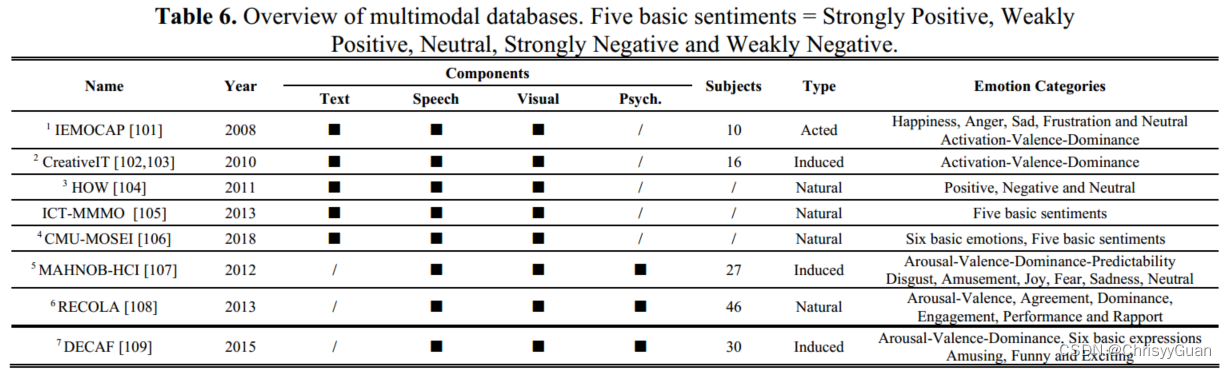
多模态数据库主要分为多物理数据库和物理生理数据库两种类型。
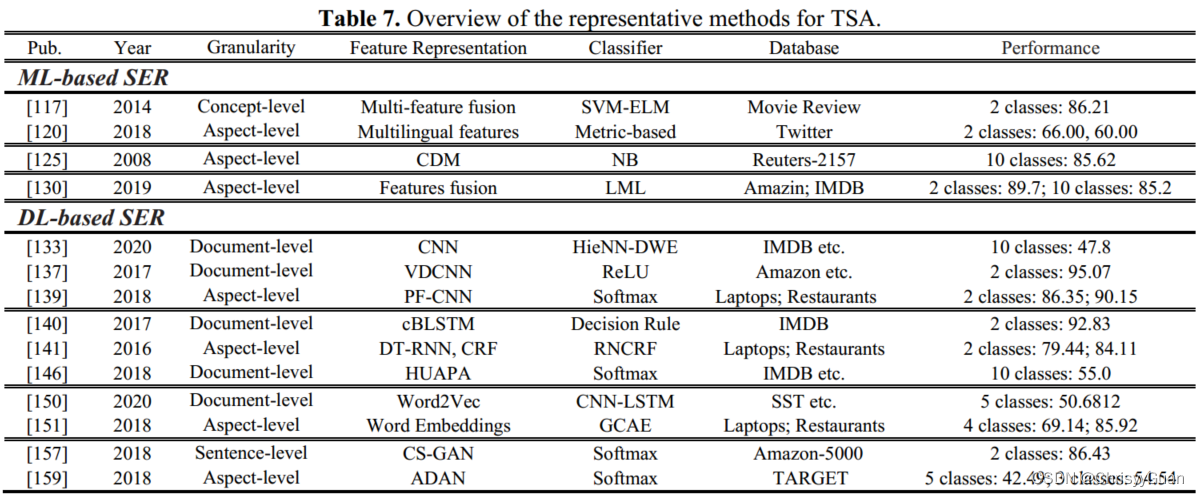
传统的TSA方法通常依赖于被称为“特征工程”的过程来寻找与情感相关的有用特征。基于dl的模型可以从文本数据中实现端到端的情感分析。 表格中的SER应该为TSA
基于传统ML方法的TSA主要依赖于基于知识的技术或统计方法。前者需要对大型情感词汇表进行同义词典建模,而后者则假设有大型数据库的可用性,并标注极性或情感标签。 ①Knowledge-based TSA通常基于词汇和语言规则。由于知识本身的局限性,基于知识的模型仅限于理解那些典型的和严格定义的概念。 ②Statistical-based TSA更多地依赖于带注释的数据集,通过使用先验统计或后验概率来训练基于ml的分类器。与基于词典的方法相比,基于统计的TSA方法更适于情感分析,因为后者可处理更多的数据。 ③Hybrid-based TSA将知识与统计模型相结合,充分利用两者的优势。 4.1.2 DL-based TSA基于dl的技术具有从数据本身自动学习和发现判别特征表示的强大能力。TSA的各种基于dl的方法包括深度卷积神经网络(ConvNet)学习,深度RNN学习,深度ConvNet-RNN学习和深度对抗性学习。 ①Deep ConvNet learning for TSA. 基于cnn的方法已经应用于不同层次的TSA,包括文档级、句子级和词级,通过使用不同的过滤器从输入数据中学习局部特征。 ②Deep RNN learning for TSA. 基于rnn的TSA能够处理长序列数据。注意机制有助于根据加权表示对给定输入序列的相关部分进行优先排序,且计算成本低。在TSA的基于注意的LSTM范式中,LSTM帮助构建文档表示,然后基于注意的深度记忆层计算每个文档的评级。 ③Deep ConvNet-RNN learning for TSA将将ConvNets和rnn结合起来,通过获得每个模型提供的优势来提高TSA的性能。 ④Deep adversarial learning for TSA具有正则化监督学习算法能力。 4.2 音频情感识别(SER)音频情感识别通过处理和理解语音信号来检测嵌入的情感。各种基于ml和基于dl的SER系统已经在这些提取的特征基础上进行了更好的分析。传统的基于ml的SER集中于声学特征的提取和分类器的选择。然而,基于深度学习的SER构建了一个端到端的CNN架构来预测最终的情绪,而不考虑特征工程和选择。
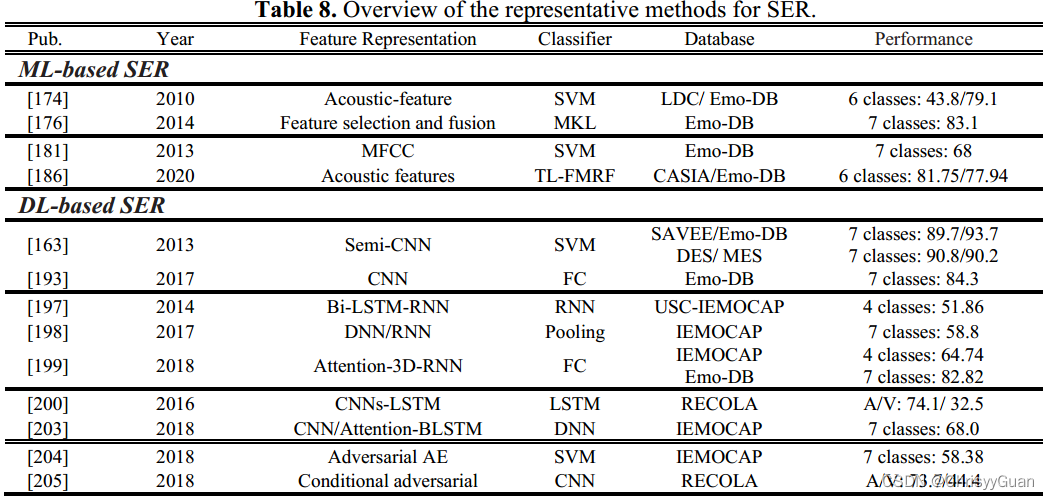
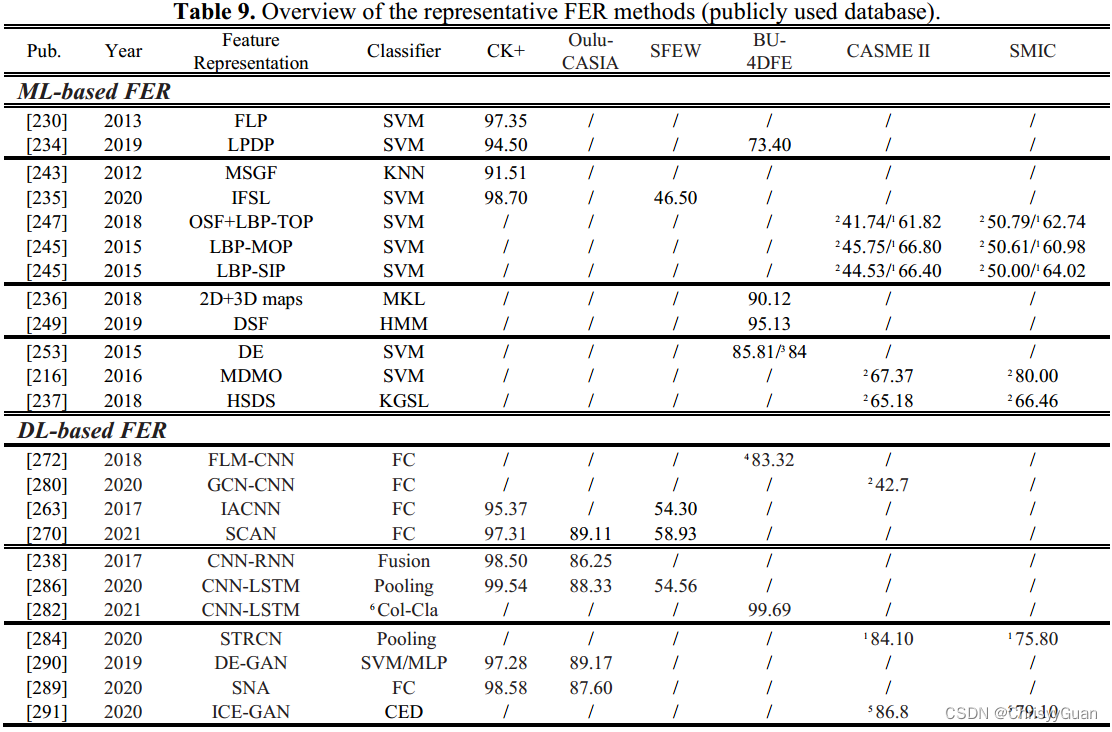
基于ML的SER系统包括两个关键步骤:情绪性语音的强特征表示学习和最终情绪预测的适当分类。 基于声学特征的SER。韵律特征(如语调和节奏)已被发现能够传达SER情感内容最独特的特性。韵律特征包括基本频率(节奏和音调特征)、能量(音量或强度)和持续时间(构建元音、单词和类似结构的总时间)。语音质量是由声道的物理特性决定的,如抖动、闪烁和谐波噪声比。 与韵律特征或话语级谱特征相比,细粒度谱特征可以得到精度更高的结果。此外,这些特征与韵律特征的结合也提高了准确性。 基于ML的SER分类器。由于语音信号的产生机制,隐马尔可夫分类器被广泛采用。GMM及其变体可以看作是一种特殊的连续HMM,适用于基于全局特征的SER。 与HMM和GMM不同的是,SVM通过核函数将情感向量映射到高维空间,并在高维空间中建立最大区间超平面进行最优分类。与单一分类器相比,集成学习已被证明具有更好的性能。 4.2.2 DL-based SER基于DL的SER系统可以理解和检测情感语音的上下文和特征,而无需设计定制的特征提取器。带有自编码器的CNN被认为是基于DL的SER的常用技术。RNN及其变体(例如Bi-LSTM)被广泛用于捕获时间信息。SER的混合深度学习包括ConvNets和RNN,以及注意机制。针对数据量有限和数据库质量不高的问题,可以通过增强训练数据和消除扰动,将对抗性学习用于基于DL的SER。 ConvNet learning for SER. RNN learning for SER. RNN可以处理语音输入序列,并在处理下一个输入序列时保持其状态。他们学习短时间帧级的声学特征,并随着时间的推移将这些特征适当地聚合成一个话语级的表征。考虑到长话语中可能存在不同的情绪状态,RNN及其变体(如LSTM和Bi-LSTM)可以解决情绪标签的不确定性。注意模型的目的是忽略不相关的情绪框架和话语的其他部分。注意力模型旨在忽略话语中不相关的情绪框架。 ConvNet-RNN learning for SER. 由于卷积神经网络和RNN都有各自的优点和局限性,CNN和RNN的结合使得SER系统同时获得频率依赖性和时间依赖性 Adversarial learning for SER. 在SER系统中,分类器经常暴露于与测试数据具有不同分布的训练数据。训练数据和测试数据分布的差异导致了严重的误分类。GAN及其变体已被证明,生成模型生成的合成数据可以增强SER的分类性能 4.3 视觉情感识别视觉情感识别主要分为面部表情识别(FER)和身体姿态情感识别(也称为情感身体姿态识别,EBGR)。 4.3.1 面部表情识别FER是使用包含面部情感线索的图像或视频来实现的。根据使用静态图像还是动态视频来表示面部表情,FER系统可以分为基于静态的FER和基于动态的FER。在面部表情持续时间和强度方面,FER又可分为宏观FER和微观FER(或FMER)。根据面部图像的维度,宏观FER可以进一步分为2D FER和3D/4D FER。请注意,由于面部图像或视频受到各种背景,照明和头部姿势的影响,因此使用预处理技术(例如如人脸对齐、人脸归一化和姿态归一化等),对人脸区域的语义信息进行对齐和归一化。下表概述了代表性的FER方法。
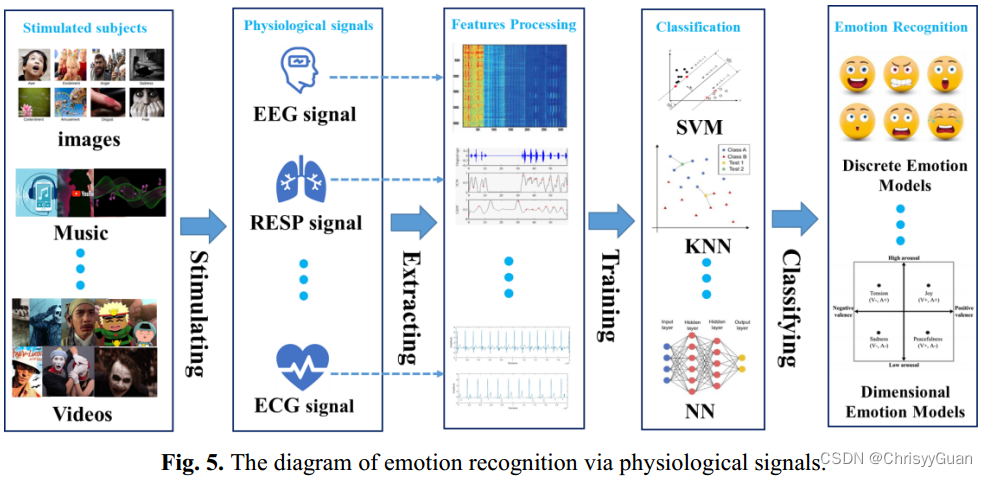
①Geometry-based FER. 基于面部动作编码系统(FACS)的先验知识,利用AAM中关键特征的变化和模糊逻辑模型来识别面部表情。由于不同局部结构的几何变形具有不稳定的形状表示,提出了局部突出定向模式描述子(local prominent directional pattern descriptor, LPDP),利用像素邻域的统计信息编码更有意义和可靠的信息。 ②Appearance-based FER. 通常从整个或特定的面部区域提取和分析空间信息或时空信息 ③Feature fusion for FER. 已经证明融合不同类型的基于几何的特征和基于外观的特征来增强FER的鲁棒性。 ④Feature selection for FER. 虽然更多的3D/4D特征或动态特征对FER有不同的影响,但过多的特征可能会破坏预测模型。特征选择是在识别和删除冗余属性的同时,从给定的特征集中选择一个相关且有用的子集。 4.3.1.2 DL-based FER 基于DL的FER骨干网大多来源于知名的预训练卷积神经网络,如VGG、VGG-face、ResNet和GoogLeNet。因此,考虑到网络架构的差异,我们将基于DL的FER分为针对FER的ConvNet学习、针对FER的ConvNet- RNN学习和针对FER的对抗性学习。 ①ConvNet learning for FER. 当使用相对较小的面部表情数据库时,基于convnet的FER经常设计转换学习或损失函数来克服过拟合。为了突出面部图像中最有用的信息,提出了各种注意机制来区分不同的特征。除了具有注意力网络或损失函数的高效网络架构外,还有一种基于多尺度编码策略的快速轻量级流形卷积神经网络(FLM-CNN)或深度融合卷积神经网络。由于面部表情数据库的偏差,源数据库和目标数据库之间的条件概率分布往往不同。为了实现跨数据库的FER, 提出了一种新的深度情感条件自适应网络来学习域不变和判别特征表示。3D ConvNet(或C3D)通过学习和表示视频或序列的时空特征,已被普遍用于基于动态的FER。 ②ConvNet-RNN learning for FER. 对于动态的面部序列或视频,连续帧的时间相关性应被视为重要的线索。RNN及其变体(LSTM)可以鲁棒地导出空间特征表示的时间特征。相比之下,代表性表达状态帧的空间特征可以通过CNN学习。基于ConvNet-RNN网络的架构,许多研究提出了级联融合或集成策略来捕获FER的空间和时间信息。使用级联融合的基于ConvNet-RNN的FER的标准流程是将卷积神经网络的输出级联到RNN中以提取时间动态。采用集成策略的基于ConvNet-RNN的FER的标准流程是融合两个流的输出。 ③Adversarial learning for FER. 由于GAN可以生成不同姿态和视角下的合成面部表情图像,因此基于gan的模型被用于姿态/视角不变的FER或身份不变的FER。 4.3.2 身体姿态情感识别由于视觉情感识别在识别人类情感方面的突出优势,大多数视觉情感识别研究都集中在视觉情感识别上。然而,在某些环境下,当专用传感器无法捕获面部图像或仅捕获低分辨率的面部图像时,FER将不适用。EBGR旨在从全身视觉信息(如身体姿势)和身体骨架运动或上半身视觉信息(如手势、头部定位和眼球运动)中揭示一个人隐藏的情绪状态。EBGR的一般流程包括人体检测(视为预处理)、特征表示和情感识别。从特征提取和情感识别过程是否端到端进行的角度出发,EBGR系统分为基于ML的EBGR和基于DL的EBGR。 4.3.2.1 ML-based EBGR在现有的基于ML的EBGR系统中,输入是通过整体身体部位或运动学模型对人体手势(或其动力学)的抽象;通过基于机器学习的方法或统计度量来区分输出的情绪,将输入映射到情绪特征空间,在情感特征空间中,情绪状态可以被基于机器学习的分类器识别。 ①Statistic-based or movement-based EBGR. 特征提取的方法可以分为基于统计的分析和基于运动的分析。 ②Feature fusion for EBGR. 融合多身体姿态特征可以增强EBGR的泛化能力和鲁棒性 ③Classifier-based EBGR. 基于ML的EBGR常用分类器包括决策树、集成决策树、KNN、SVM等。 ④Non-acted EBGR. 虽然上述工作在表演数据上显示出良好的结果,但由于夸大了情绪身体动作,它们无法解决更困难的非表演场景。 4.3.2.2 DL-based EBGR尽管基于DL的EBGR系统不需要设计定制的特征提取器,但它们通常基于常用的姿态估计模型或低级特征提取器对输入数据进行预处理。通过基于CNN的网络、基于LSTM的网络或基于CNN-LSTM的网络,可以在空间、时间或时空维度上学习高级特征。最近,许多研究已经证明了将不同的基于DL的模型与注意机制有效结合在一起的优势,可以提高EBGR的性能。 ①ConvNet-RNN learning for EBGR. ②Zero-shot based EBGR. 由于人类通过肢体语言表达情感的复杂性和多样性,很难列举出所有的情感肢体语言,并为每个类别收集足够的样本。因此,现有的方法无法确定一个新的身体姿态属于哪种情绪状态。为了从看到的身体姿态中识别未知的情绪或未见过的身体姿态中了解情绪,引入了广义零机会学习框架,包括基于CNN的特征提取、基于自编码器的表示学习和情绪分类器。 4.4 基于生理的情感识别一个人的面部表情、文字、声音和肢体动作都可以很容易地收集到。由于身体信息的可靠性在很大程度上取决于社会环境和文化背景,以及测试者的性格,他们的情绪很容易被伪造。而生理信号的变化直接反映了人类情绪的变化,可以帮助人类识别、解读和模拟情绪状态。因此,通过生理信号来学习人类情绪是非常客观的。
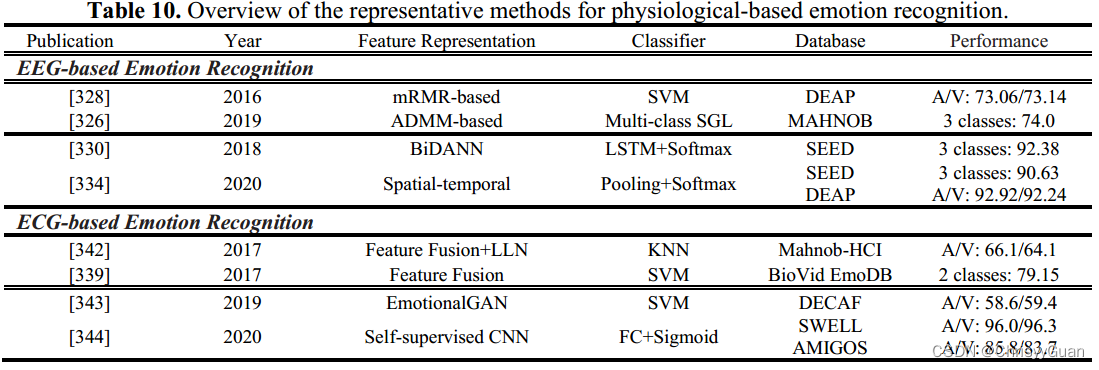
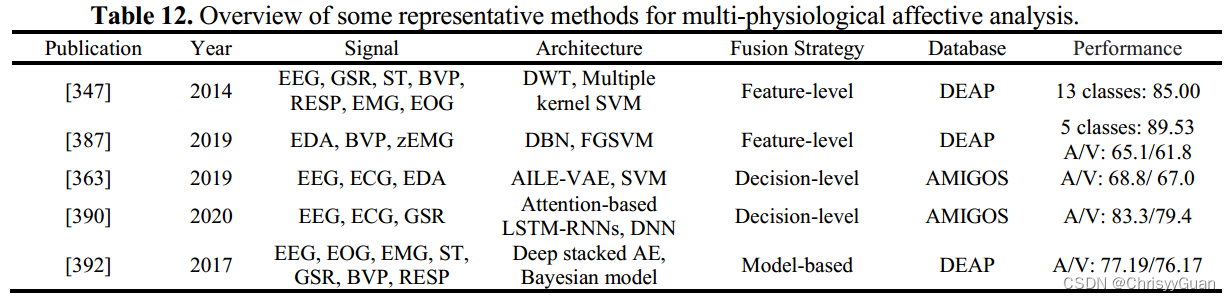
在上述生理情绪信号中,EEG或ECG可为识别情绪提供简单、客观、可靠的数据,是最常用于情绪分析和情绪识别的信号。
与其他外周神经生理信号相比,EEG可以直接测量大脑活动的变化,提供情绪状态的内在特征。此外,脑电图具有较高的时间分辨率,可以实时监测人的情绪状态。因此,最近出现了各种基于脑电图的情感识别技术。 4.4.1.1 ML-based EEG emotion recognition基于ML的脑电图情感识别的性能取决于如何正确设计特征提取、特征降维(或特征选择)和分类方法。特征提取的核心目标是提取重要的脑电信号特征,包括时域特征、频域特征和时频域特征。快速傅里叶变换(FFT)分析常用于将EEG转换为功率谱。由于脑电图的冗余性,特征降维是基于脑电图的情感识别的重要步骤。基于EEG的情感识别常用的基于ML的分类器是SVM或其变体。 4.4.1.2 DL-based EEG emotion recognition与基于ML的EEG情感识别流程不同,基于DL的EEG情感识别同时学习特征并对基于脑电图的情绪进行分类。 4.4.2 ECG-based emotion recognition心电图通过自主神经系统的活动,记录人的心脏在不同情况下的生理变化。随着人的情绪或情绪状态的变化,心电会检测到相应的波形变换,可以为情绪识别提供足够的信息。 4.4.2.1 ML-based ECG emotion recognition基于心电的情绪自动识别的九个阶段框架,包括:1)信号预处理;2) R波检测;3)开窗心电记录;4)噪声时代抑制;5)基于时域、频域和非线性分析的特征提取;6)特征归一化;7)基于序列前向浮动选择核的类可分离性特征选择;8)基于广义判别分析的特征约简;9)基于LS-SVM的分类器构建。注意,并非所有基于ml的心电情绪识别方法都遵循上述步骤,但特征提取、特征选择和分类器的步骤是必不可少的。 4.4.2.2 DL-based ECG emotion recognition提出了EmotionalGAN和自监督的方法来进行基于DL的ECG情感识别。 五、 多模态情感分析多模态情感分析框架融合不同模态,旨在获得比单模态情感识别更准确的结果和更全面的理解。 1. 特征级融合将从多模态输入中提取的特征组合成一个通用特征向量,然后将其发送到分类器中。 (a)、(b)和(c)分别显示了基于特征级融合的视音频模式、文本音频模式和视音频文本模式的示例。
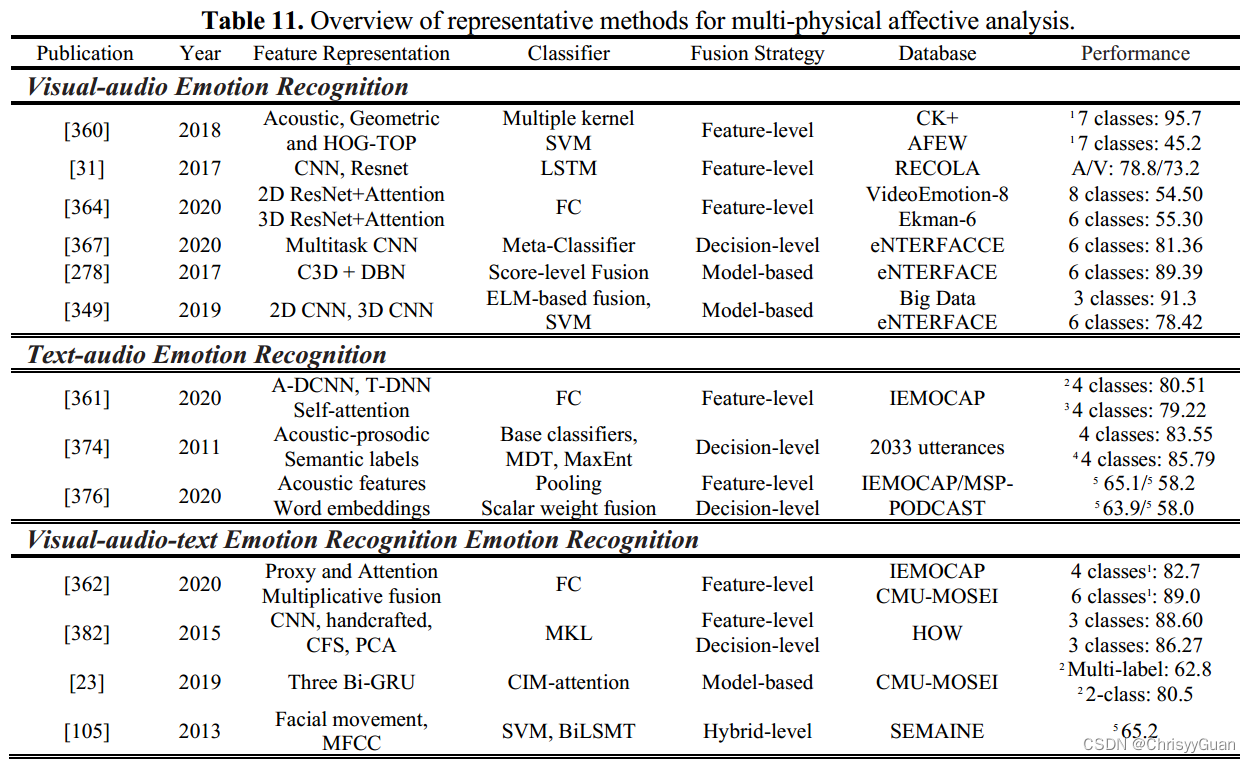
根据模态组合的常见方式,我们将情感分析的多物理模态融合分为视音频情感识别、文本音频情感识别和视音频文本情感识别。
视觉和听觉信号是人们日常交流中最自然、最有效的情感表达方式。许多研究工作表明,视觉-音频情感识别优于视觉或音频情感识别。 ①特征级融合 ②决策级融合 ③模型级融合 需要基于ML的模型(如HMM、卡尔曼滤波器和DBN)来构建不同模态之间的关系来做出决策。 5.1.2 文本音频情感识别尽管SER和TSA已经取得了重大进展,但单独执行这两项任务很难获得令人信服的结果。文本音频情感识别方法使用语言内容和语音线索来增强单模态情感识别系统的性能。 ①特征级融合 ②决策级融合 ③特征级融合与决策级融合 为了验证特征级融合和决策级融合在文本音频情感识别中哪个更有效,探讨了特征级融合和决策级融合三种不同的融合方式,比较了它们的性能。 5.1.3 视-听-文情感识别声音调节、面部表情和基于上下文的文本为更好地识别意见持有者的真实情感状态提供了重要线索。例如,当一位女士被求婚,然后她流着泪说“我愿意”时,基于文本、基于音频或基于视觉的情感识别模型都无法预测自信的结果。而视觉-音频-文本情感识别则会带来更好的解决方案。 ①特征级融合 与三种单模态和三种双模态模型相比,多模态(文本-音频-视觉)模型比单独使用一种模态或融合任何两种模态都能显著提高模型性能。 ②特征级融合与决策级融合 实验结果表明,文本情感识别在三种单模态情感识别方法中表现最好,在特征级融合方面,视听文本情感识别优于其他单模态和双模态情感识别。特征级融合的精度明显高于决策级融合,但以牺牲计算速度为代价。 ③模型级融合 ④混合级融合 5.2 多生理模态融合情感分析随着可穿戴技术的增强和完善,基于多生理模式的自动情感分析受到越来越多的关注。然而,由于情绪的复杂性和生理反应的显著个体差异,无论是基于脑电图还是基于脑电图的情绪识别,都难以达到令人满意的预测效果。
①特征级融合 ②决策级融合 ③模型级融合 5.3 物理-生理模态融合的情感分析由于人类情绪的变化是一种复杂的心理生理活动,情感分析的研究涉及到许多线索(如行为信号、生理信号和心理信号)。研究人员通过挖掘物理数据的强烈外部表达和生理信号不可掩饰的内部变化,将物理-生理模态融合用于情感分析。
①特征级融合 ②特征级融合与决策级融合 Huang等提出了基于视频脑电的多模态情感分析方法,该方法将外部面部表情的时空局部单基因二元模式与内部脑电的特征级和决策级判别谱功率相融合。根据他们的实验,多模态情感分析比单模态情感识别取得了更好的性能;在MAHNOB-HCI的效价和唤醒识别方面,决策级融合优于特征级融合。 ③模型级融合 六、讨论 6.1 不同信号对单峰情感识别的影响根据基于文本、音频、视觉、EEG或ECG的单模态情感识别,我们可以发现,使用最广泛的是视觉信号,主要由面部表情和肢体动作组成。基于视觉的情绪识别系统的数量与基于其他模态的系统的数量相当,因为视觉信号比其他信号更容易捕获,并且视觉信号中的情绪信息比其他信号更有助于识别人类的情绪状态。基于视觉的情感识别比基于音频的情感识别更有效,因为音频信号容易受到噪声的影响。 然而,一项研究表明,基于文本的情感分析在情感识别和情感分析中准确率最高。虽然可穿戴传感器收集的生理信号比物理信号更难获得,但由于其结果客观可靠,许多基于脑电图或基于心电图的情绪识别方法已经被研究和提出。 6.2 模态组合及融合策略对多模态情感分析的影响不同模态的结合和融合策略是多模态情感分析的两个关键方面。多模态组合分为多物理模态、多生理模态和物理-生理模态。融合策略包括特征级融合、决策级融合、混合级融合和模型级融合。 在多物理模态中,有三种不同模态的组合,包括视觉-音频、文本-音频和视觉-音频-文本。整合视觉和音频信息可以提高单模情感识别的性能。在其他多物理模态组合中也有类似的结果,其中文本模态在多模态情感分析中起着最重要的作用。在情感分析的多生理模态融合研究中,除EEG和ECG外,还联合其他类型的生理信号(如ECG、EOG、BVP、GSR和EMG)来解释情绪状态。视觉模态(面部表情、声音、手势、姿势等)也可以与多模态生理信号相结合,用于视觉-生理情感分析。 多模态情感分析的两种基本融合策略是特征级融合和决策级融合。特征向量的拼接或因式双线性池化通常用于特征级融合。多数/平均投票通常用于决策级融合。线性加权计算可以用于特征级和决策级融合,通过使用和/乘积算子来融合不同模态的特征或分类决策。 根据多模态情感分析,我们发现特征级融合比决策级融合更为常见。基于特征级融合的情感分类器的性能受到来自不同模态特征的时间尺度和度量水平的显著影响。 另一方面,在决策级融合中,对来自每个模态的输入进行独立建模,最后将这些单模态的情感识别结果结合起来。与特征级融合相比,决策级融合更容易进行,但忽略了不同模态特征之间的相关性。混合级融合旨在充分利用基于特征的融合和基于决策的融合策略的优点,同时克服两者的缺点。与上述三种融合策略不同,模型级融合使用HMM或贝叶斯网络来建立不同模态特征与一种松弛融合模式之间的相关性。HMM或贝叶斯的选择和建立对模型级融合的结果有致命的影响,而模型级融合往往是为一个特定的任务而设计的。 6.3 基于ML和基于DL的模型对情感计算的影响大多数关于情感计算的早期工作都采用了基于ML的技术。基于ML的管道由原始信号的预处理,手工制作的特征提取器和精心设计的分类器组成。尽管已经为不同的模式设计了各种类型的手工特征,但是基于ML的情感分析技术很难在类似的问题中重用,因为它们具有特定于任务和特定于领域的特征描述符。常用的基于ML的分类器有SVM、HMM、GMM、RF、KNN和ANN,其中SVM分类器是最有效的分类器,确实用于基于ML的情感计算的大多数任务中。当基于DL的模型仅用于单模态特征提取或多模态特征分析时,这些基于ML的分类器也用于最终分类。 目前,基于DL的模型由于具有较强的特征表示学习能力,在情感计算的大部分领域已经成为热点,并超过了基于ML的模型。对于静态信息(例如,面部和光谱图图像),CNN及其变体被设计用于提取重要的和判别性的特征。对于序列信息(如生理信号和视频),RNN及其变体被设计用于捕获时间动态。CNN-LSTM模型可以进行深度时空特征提取。对抗学习被广泛用于通过增强数据和跨领域学习来提高模型的鲁棒性。此外,将不同的注意力机制和自动编码器与基于DL的技术集成在一起,以提高整体性能。似乎基于DL的方法在自动学习最具判别性的特征方面具有优势。然而,与基于ML的模型相比,基于DL的方法尚未对生理情绪识别产生巨大影响。 6.4 一些潜在因素对情感计算的影响在整个回顾中,我们一致发现情感计算的进步是由各种数据库基准驱动的。例如,由于物理生理情感数据库的限制,视频生理情感识别方法很少。相比之下,FER的快速发展与各种基线数据库是分不开的,这些数据库是公开的,可以免费下载。此外,还可以使用BU-4DFE、BP4D等大型视觉数据库对目标模型进行预训练,以识别面部表情或微表情。然而,不同的数据库在大小、质量和收集条件方面存在显著差异。例如,大多数身体姿态情感数据库只包含几百个样本,姿态类别有限。更糟糕的是,样本通常是在实验室环境中收集的,这往往远离现实世界的条件。此外,数据库的大小和质量对基于DL的情感识别的影响比基于ML的情感识别更明显。许多研究已经得出结论,减少可用数据库的大小是追求高性能情感分析的关键因素。为了解决这个问题,可以将预先训练好的基于DL的模型转换为专门用于情感分析的基于任务的模型。 尽管对自然情感状态的表征尚无共识,但大多数情感分析都是基于两种类型的情感模型进行训练和评估的:离散模型和维度模型。在建立情感数据库时,通常选择离散或维度标签来拟合原始信号。例如,情感图像或序列通常与离散的情感状态(基本情感或极性)相匹配。情感识别可以分为分类(情感、维度或极性)和连续维度回归(愉悦、唤醒、优势期望或强度)。分类或成分情绪分类通常采用正确率、精密度和召回率三个指标。当数据库不平衡时,通过10折交叉验证和LOSO, F-Measure(或F1-Score)似乎是现有情绪分类评估指标中的最佳选择。加权平均recall/F1-score (WAR/WF1)和非加权平均recall/F1-score (UAR/UF1)最适合于视觉、音频或多模态情感分析的分类性能。另一方面,MSE和RMSE通常用于评估连续维度的情绪预测。为了描述重合程度,建议通过整合PCC和MSR,采用系数一致性相关系数来评估基线绩效评估。 6.5情感计算在现实场景中的应用近年来,越来越多的研究团队将重点转向情感计算在现实场景中的应用。NTU的Erik Cambria领导的SenticNet为了从文本信息中检测情绪和情感,将情感计算和情感分析的研究成果应用到日常生活的许多方面,包括HCI、金融和社交媒体监测和预测。TSA通常用于推荐系统,通过整合各种反馈信息或微博文本。视觉情感识别的应用包括课程教学、智能决策辅助、HCI、游戏玩家动态质量适应、抑郁症识别以及帮助自闭症谱系障碍儿童医学康复。特别是,由于音频/语音情感信号的可靠性和稳定性以及可穿戴设备的生理信号的可及性,音频和生理信号经常被用于检测临床抑郁和压力。由于多模态情感分析可以增强单模态情感识别的鲁棒性和性能,越来越多的研究开始将其转化为各种现实应用,使其成为一个有前景的研究途径。 七、未来研究展望1)发展新的和更广泛的基线数据库,特别是由不同模式(文本、音频、视觉和生理)组成的多模态情感数据库将会是有帮助的。条件应该包括自发和非自发的场景,并在离散和维度情感模型中提供注释数据。 2)情感分析中存在一些具有挑战性的问题需要解决,包括部分遮挡或虚假情绪表达下的FER,基于各种复杂信号的生理情绪识别,以及针对离散情绪识别和维度情绪预测的基线模型。 3)融合策略有很大的改进空间,特别是基于规则或基于统计的知识,以实现不同模式的相互融合,可以考虑每种模式在情感识别中的作用和重要性。 4)零/小样本或无监督学习方法(如自监督学习)需要进一步探索,特别是由于它们有可能增强有限或有偏差数据库下情感分析的鲁棒性和稳定性。 5)情感分析的一个突出应用是机器人技术。 |
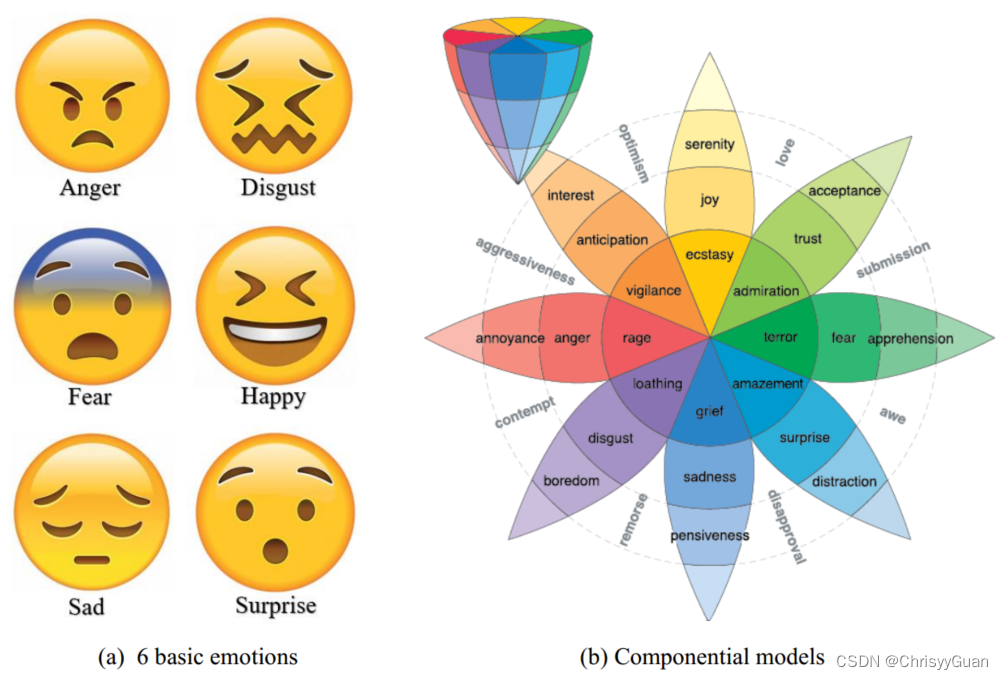 六种基本情绪包括愤怒、厌恶、恐惧、快乐、悲伤和惊讶。 Plutchik的轮子模型涉及八种基本情绪(即喜悦、信任、恐惧、惊讶、悲伤、期待、愤怒和厌恶)以及这些情绪之间的相互关系。例如,快乐和悲伤是对立的,期待很容易发展成警惕。轮子模型也被称为成分模型,其中较强的情绪占据中心,而较弱的情绪占据极端,这取决于它们的相对强度水平。这些离散的情绪通常可以分为三种极性(积极,消极和中性),通常用于情感分析。为了描述细粒度的情感,提出了矛盾情感处理来分析多层次的情感,提高二值分类的性能。
六种基本情绪包括愤怒、厌恶、恐惧、快乐、悲伤和惊讶。 Plutchik的轮子模型涉及八种基本情绪(即喜悦、信任、恐惧、惊讶、悲伤、期待、愤怒和厌恶)以及这些情绪之间的相互关系。例如,快乐和悲伤是对立的,期待很容易发展成警惕。轮子模型也被称为成分模型,其中较强的情绪占据中心,而较弱的情绪占据极端,这取决于它们的相对强度水平。这些离散的情绪通常可以分为三种极性(积极,消极和中性),通常用于情感分析。为了描述细粒度的情感,提出了矛盾情感处理来分析多层次的情感,提高二值分类的性能。


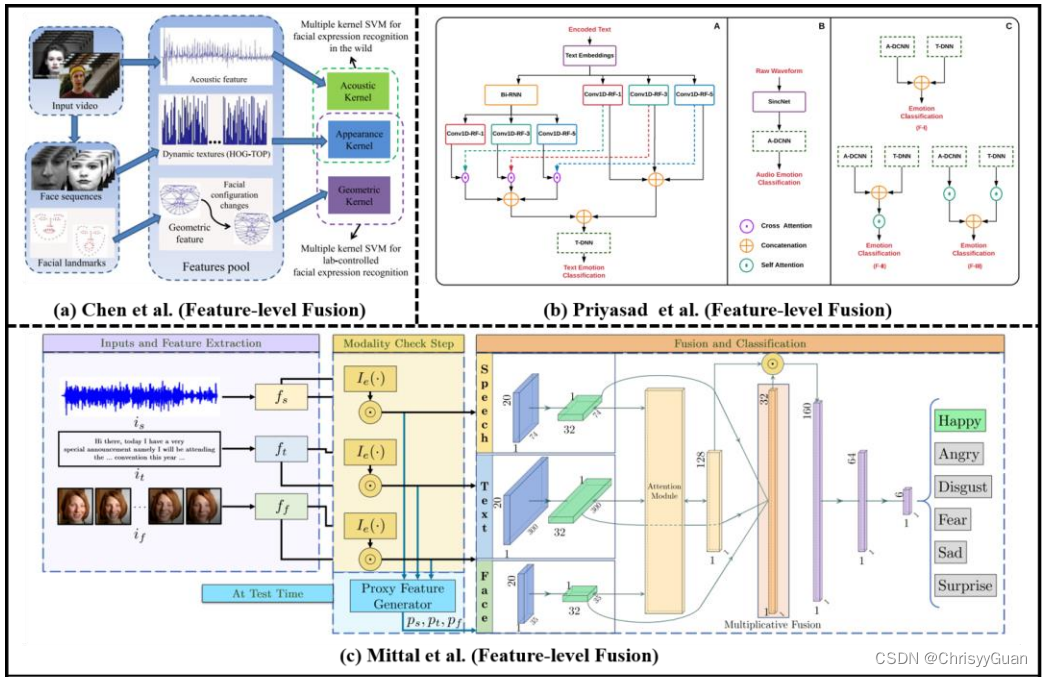 2. 决策级融合将每个模态独立生成的所有决策向量连接成一个特征向量。(d)显示了基于决策级融合的EGG、ECG和EDA多生理模式的一个示例。 3.模型级融合发现从不同模态中提取的特征之间的相关性,并使用或设计具有松弛和平滑类型(如HMM和两阶段ELM)的融合模型。 (e)和(f)分别是基于物理生理模式和视觉-音频-文本模式的模型级融合的两个示例。
2. 决策级融合将每个模态独立生成的所有决策向量连接成一个特征向量。(d)显示了基于决策级融合的EGG、ECG和EDA多生理模式的一个示例。 3.模型级融合发现从不同模态中提取的特征之间的相关性,并使用或设计具有松弛和平滑类型(如HMM和两阶段ELM)的融合模型。 (e)和(f)分别是基于物理生理模式和视觉-音频-文本模式的模型级融合的两个示例。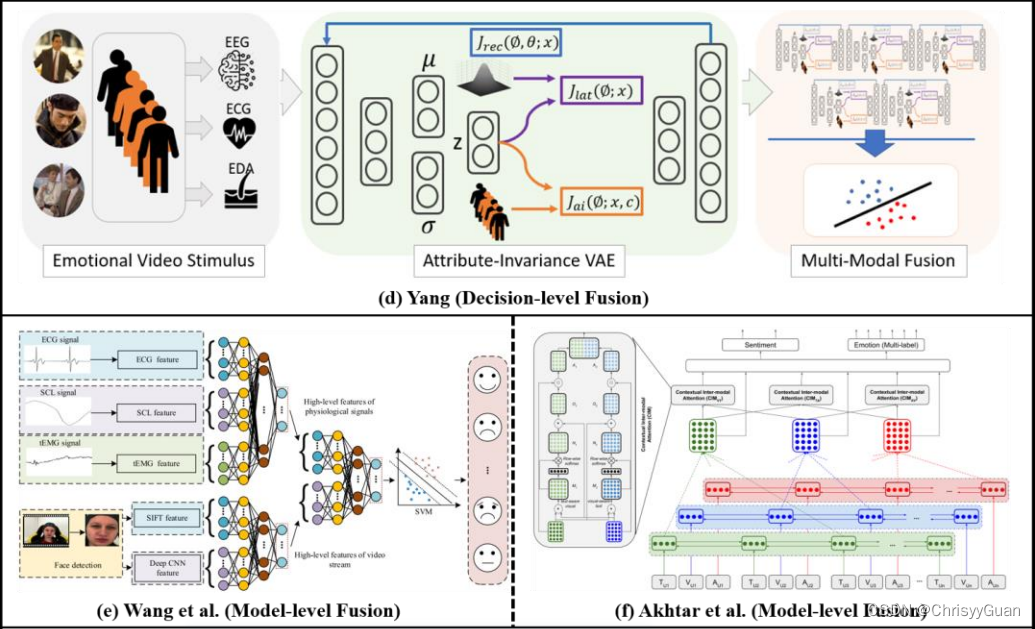 4. 混合融合是特征级融合和决策级融合的结合。(g)显示了一个基于视觉-音频-文本模式混合融合的示例。
4. 混合融合是特征级融合和决策级融合的结合。(g)显示了一个基于视觉-音频-文本模式混合融合的示例。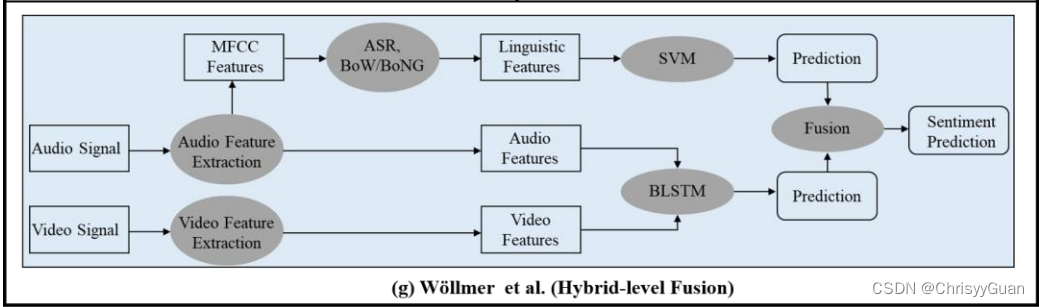

【本文地址】
今日新闻 |
推荐新闻 |