|
文章目录
前言無監督學習的優點常用聚类算法的特點:KMeans算法算法的優缺點算法流程圖解
KMeans實戰
總結
前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习中無監督學習的基础内容。 无监督学习: 机器学习的一种方法,没有给定事先标记过的训练示例,自动对输入的数据进行分类或分群。
無監督學習的優點
算法不受监督信息(偏见)的约束,可能考虑到新的信息 这也就是上例所说的可以按不同方式分类,并没有一个明确的规定
不需要标签数据,极大程度扩大数据样本 无监督学习不需要标签数据,这样在面临成千上万个数据时可以让计算机自动去分类从而节省大量的人力成本。
常用聚类算法的特點:
KMeans聚类 根据数据与中心点距离划分类别 基于类别数据更新中心点 重复过程直到收敛 特点:实现简单、收敛快;需要指定类别数量(需要告诉计算机要分成几类) 均值漂移聚类(Meanshift) 在中心点一定区域检索数据点 更新中心 重复流程到中心点稳定 特点:自动发现类别数量,不需要人工选择;需要选择区域半径 DBSCAN算法(基于密度的空间聚类算法) 基于区域点密度筛选有效数据 基于有效数据向周边扩张,直到没有新点加入 特点:过滤噪音数据;不需要人为选择类别数量;数据密度不同时影响结果
KMeans算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法。
算法的優缺點
k-means聚类算法的优点有:
算法思想简单,收敛速度快; 聚类效果较优; 主要需要调参的参数仅仅是簇数K; 算法的可解释度比较强。
k-means聚类算法的缺点有:
采用迭代方法,聚类结果往往收敛于局部最优而得不到全局最优解; 对非凸形状的类簇识别效果差; 易受噪声、边缘点、孤立点影响; 可处理的数据类型有限,对于高维数据对象的聚类效果不佳; K值的选取不好把握。 K值就是劃分為幾類

算法流程
预将数据分为K组,则随机选取K个对象作为初始的聚类中心 然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。 聚类中心以及分配给它们的对象就代表一个聚类 每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算 这个过程将不断重复直到满足某个终止条件 终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
選擇聚類的個數k確定聚類中心根據點到聚類中心聚類確定各個點所屬類別根據各個類被數據更新聚類中心重複以上步驟直到收斂(中心點不再變化)
圖解
原始數據分佈
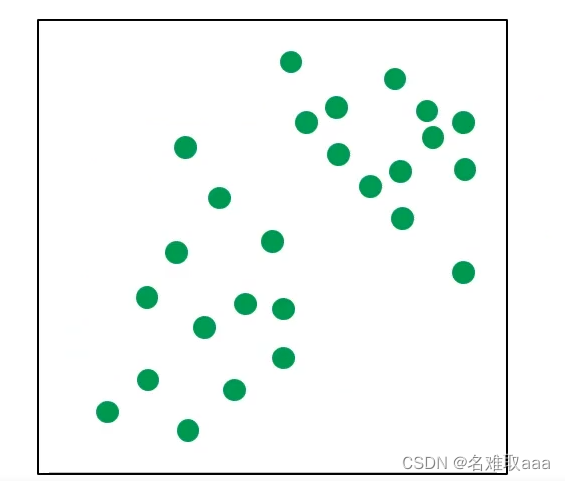 隨機選取聚類中心,也就是那兩個× 隨機選取聚類中心,也就是那兩個× 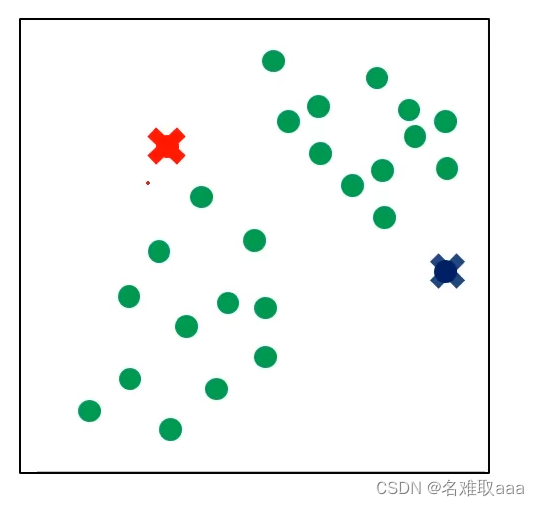 计算每个点到聚类中心的距离,然后将这些点进行分类 计算每个点到聚类中心的距离,然后将这些点进行分类
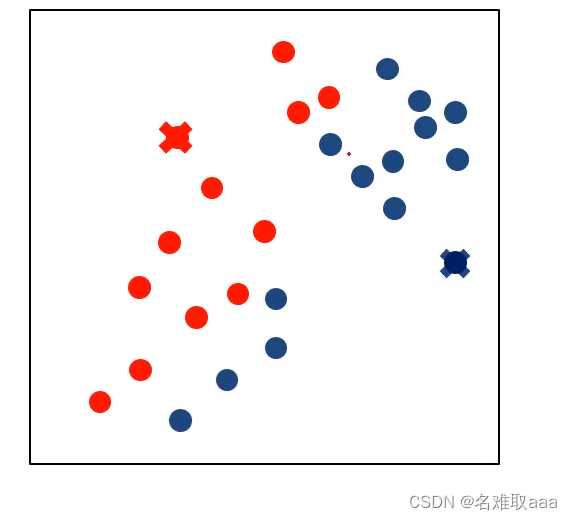
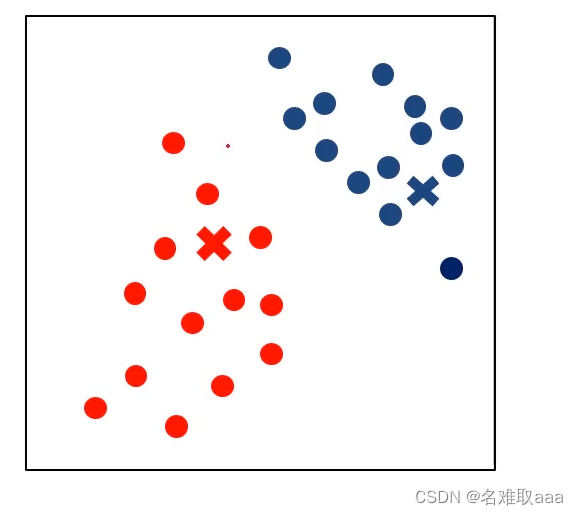
根據聚類更新聚類中心 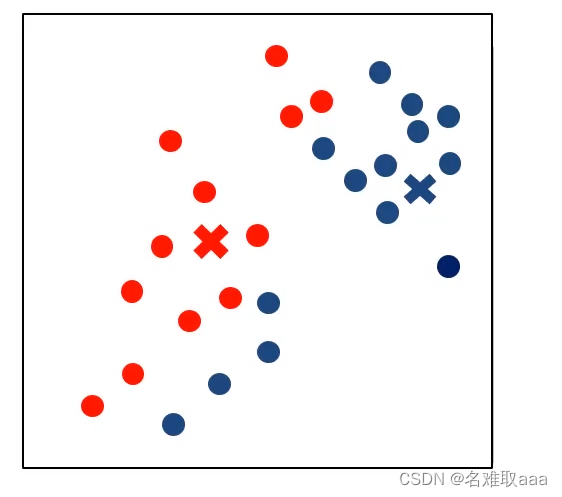
重新计算每个点到聚类中心的距离并根据新的距离重新分类
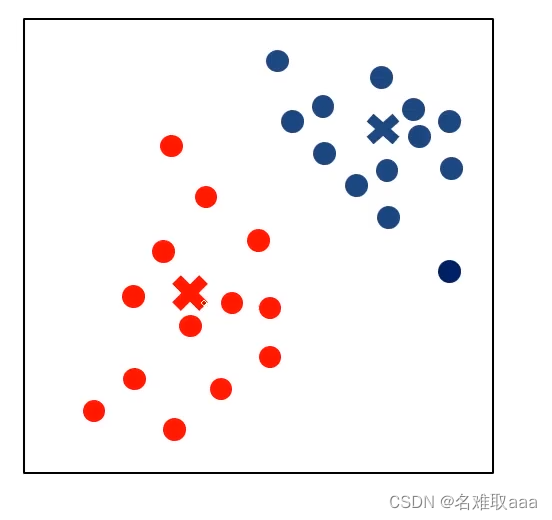
 中心收斂,不再變化就停止 中心收斂,不再變化就停止
KMeans實戰
任務:
采用Kmeans算法實現2D數據自動聚類,預測V1=80,V2=60數據類別計算預測準確率,完成結果矯正采用KNN、Meanshift算法,重複步驟1-2 數據:data.csv
# load the data
import pandas as pd
import numpy as np
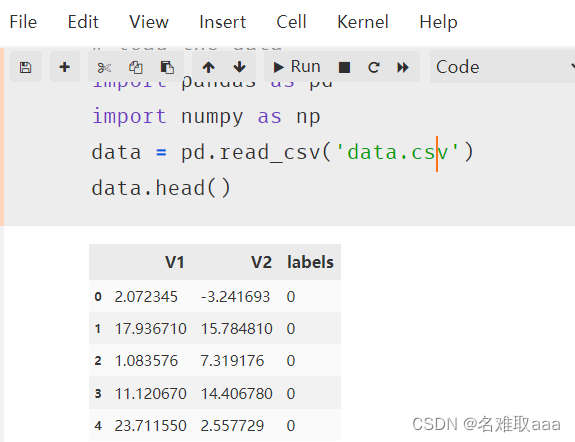
data = pd.read_csv('data.csv')
data.head()
#define X and y
X = data.drop(['labels'],axis=1)
y = data.loc[:,'labels']
X.head()
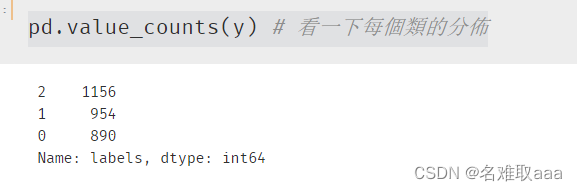
pd.value_counts(y) # 看一下每個類的分佈
from matplotlib import pyplot as plt
fig1 = plt.figure()
plt.scatter(X.loc[:,'V1'],X.loc[:,'V2'])
plt.title('un-labled data')
plt.xlabel('V1')
plt.ylabel('V2')
plt.show()
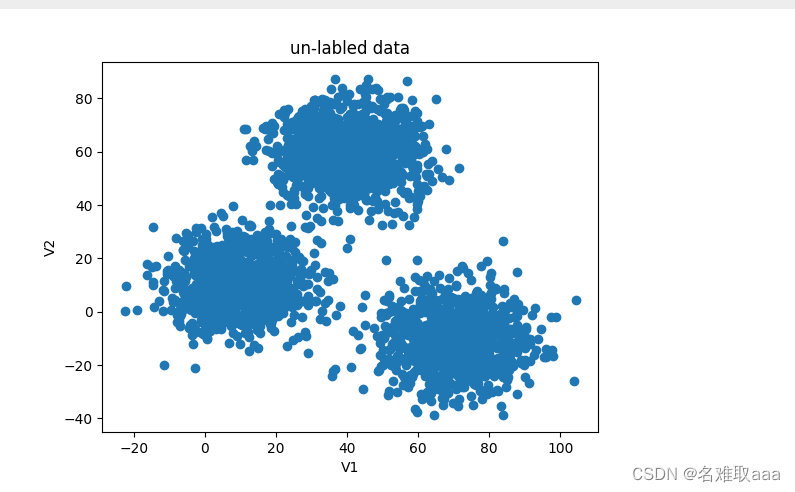
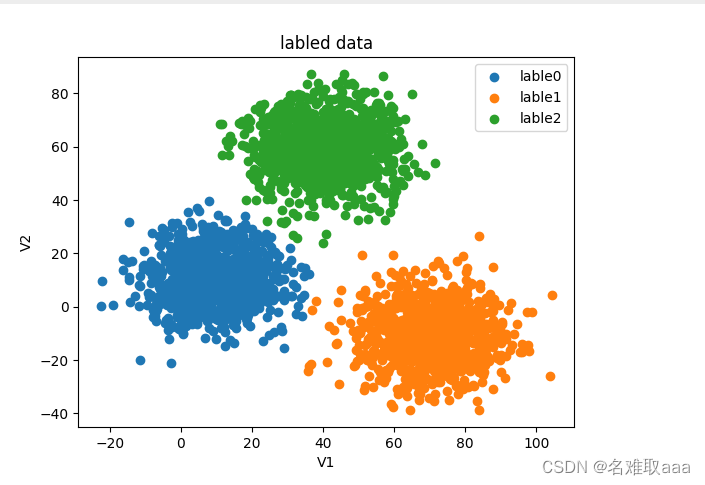
fig2 = plt.figure()
lable0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:,'V2'][y==0])
lable1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:,'V2'][y==1])
lable2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:,'V2'][y==2])
plt.title('labled data')
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((lable0,lable1,lable2),('lable0','lable1','lable2'))
plt.show()
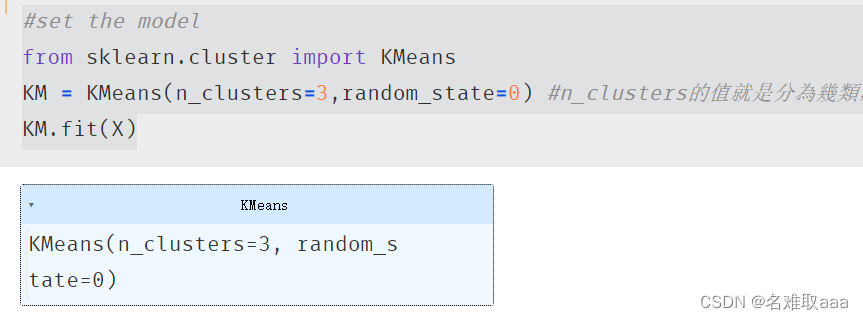
print(X.shape,y.shape)#看一下維度

#set the model
from sklearn.cluster import KMeans
KM = KMeans(n_clusters=3,random_state=0) #n_clusters的值就是分為幾類,也就是K值
KM.fit(X)
centers = KM.cluster_centers_ #看一下中心點在哪
print(centers)
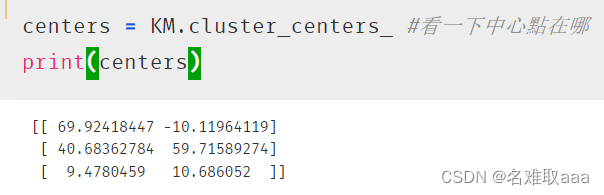
fig3 = plt.figure()
lable0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:,'V2'][y==0])
lable1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:,'V2'][y==1])
lable2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:,'V2'][y==2])
plt.title('labled data')
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((lable0,lable1,lable2),('lable0','lable1','lable2'))
plt.scatter(centers[:,0],centers[:,1])
plt.show()
從可視化這裏也可以看出聚類是對的差不多就是類別不對 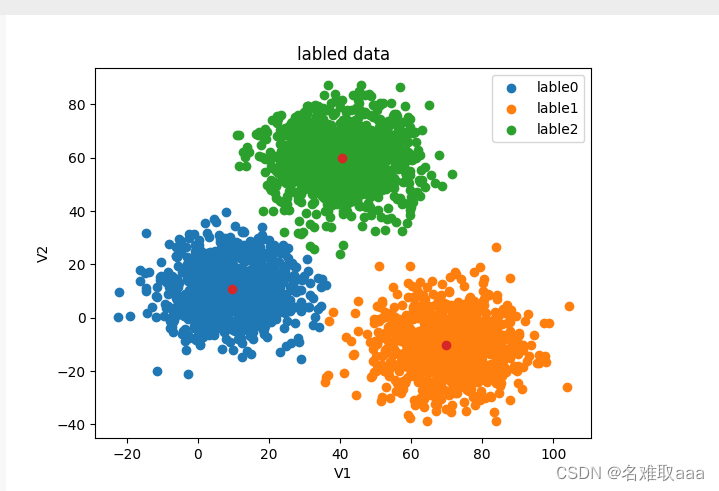
#test data:V1=80,V2=60
y_predict_test = KM.predict([[80,60]])
print(y_predict_test)
#predict based on training data
y_predict = KM.predict(X)
print(pd.value_counts(y_predict),pd.value_counts(y)) #看一下預測數據和原始數據的分佈區別
這裏可以看出 類別2 變成 類別1 了 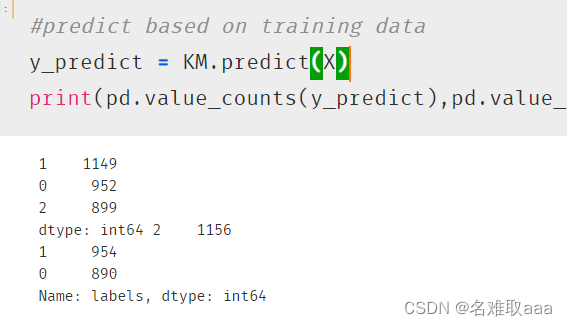
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
accuracy_score也驗證了預測效果很差 
#visualize the data and results
fig4 = plt.subplot(121)
lable0 = plt.scatter(X.loc[:,'V1'][y_predict==0],X.loc[:,'V2'][y_predict==0])
lable1 = plt.scatter(X.loc[:,'V1'][y_predict==1],X.loc[:,'V2'][y_predict==1])
lable2 = plt.scatter(X.loc[:,'V1'][y_predict==2],X.loc[:,'V2'][y_predict==2])
plt.title('predict data')
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((lable0,lable1,lable2),('lable0','lable1','lable2'))
plt.scatter(centers[:,0],centers[:,1])
fig5 = plt.subplot(122)
lable0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:,'V2'][y==0])
lable1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:,'V2'][y==1])
lable2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:,'V2'][y==2])
plt.title('labled data')
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((lable0,lable1,lable2),('lable0','lable1','lable2'))
plt.scatter(centers[:,0],centers[:,1])
plt.show()
可視化對比一下預測數據分佈和原始數據分佈的區別,可以看出類比不對
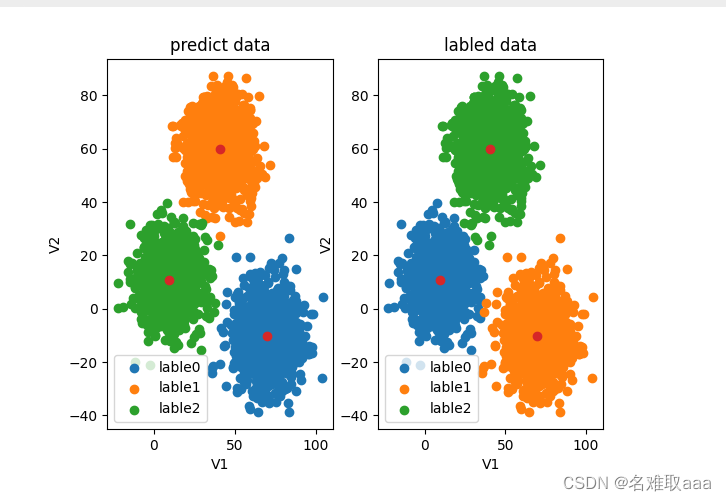
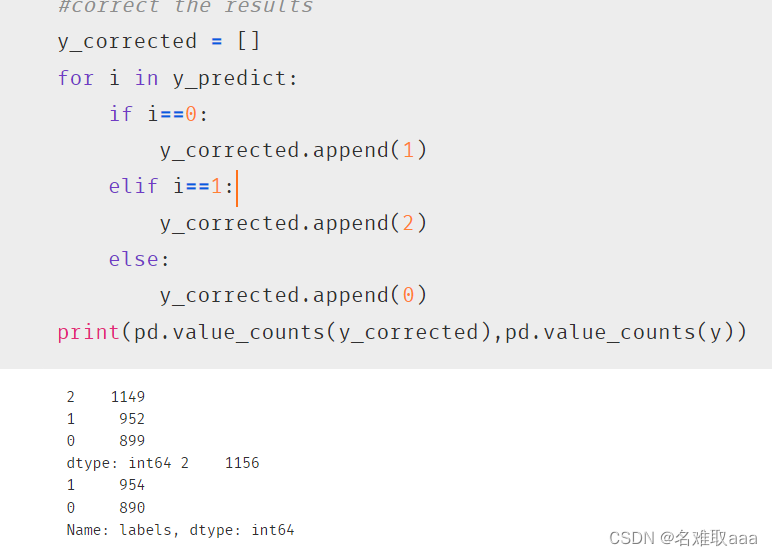
#correct the results
y_corrected = []
for i in y_predict:
if i==0:
y_corrected.append(1)
elif i==1:
y_corrected.append(2)
else:
y_corrected.append(0)
print(pd.value_counts(y_corrected),pd.value_counts(y))
矯正一下類比
print(accuracy_score(y,y_corrected))
再看一下accuracy_score分數,可以看出還是比較理想

y_corrected = np.array(y_corrected) #轉換為數組不然後面[y_corrected==0]會報錯
print(type(y_corrected))
#visualize the data and results
fig4 = plt.subplot(121)
lable0 = plt.scatter(X.loc[:,'V1'][y_corrected==0],X.loc[:,'V2'][y_corrected==0])
lable1 = plt.scatter(X.loc[:,'V1'][y_corrected==1],X.loc[:,'V2'][y_corrected==1])
lable2 = plt.scatter(X.loc[:,'V1'][y_corrected==2],X.loc[:,'V2'][y_corrected==2])
plt.title('corrected data')
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((lable0,lable1,lable2),('lable0','lable1','lable2'))
plt.scatter(centers[:,0],centers[:,1])
fig5 = plt.subplot(122)
lable0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:,'V2'][y==0])
lable1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:,'V2'][y==1])
lable2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:,'V2'][y==2])
plt.title('labled data')
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((lable0,lable1,lable2),('lable0','lable1','lable2'))
plt.scatter(centers[:,0],centers[:,1])
plt.show()
可以看出基本一致了 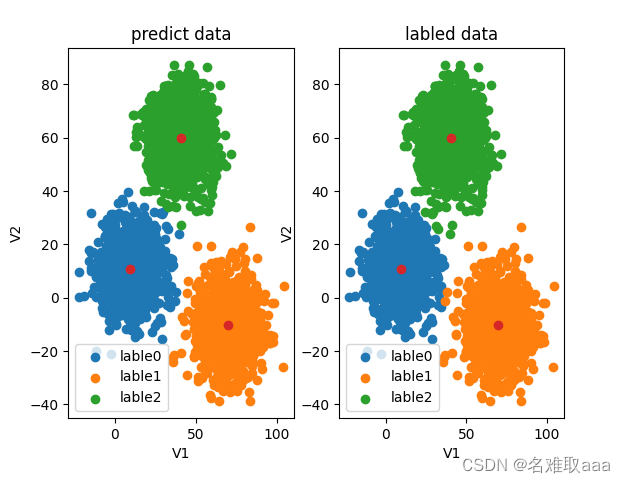
總結
附上實戰的數據集和源碼 鏈接:https://github.com/fbozhang/python/tree/master/jupyter
|