生存分析 |
您所在的位置:网站首页 › 均匀分布的期望是 › 生存分析 |
生存分析
|
You can find the full article here 来看一个比较特殊的Survival分析建模的案例,利用的是半参模型:Poisson Regression 具体参考文章:Survival Analysis with LightGBM plus Poisson Regression 里面的建模思路非常有意思,不适合工业落地,不过咨询公司的data scientist看过来~ 1 Poisson Regression 1.1 松泊分布与泊松回归参考:什么是松泊分布?泊松回归可以用来做什么? 试想一下,你现在就站在一个人流密集的马路旁,打算收集闯红灯的人群情况(?)。 首先,利用秒表和计数器,一分钟过去了,有5个人闯红灯; 第二分钟有4个人;而下一分钟有4个人。 持续记录下去,你就可以得到一个模型,这便是“泊松分布”的原型。 除此以外,现实生活中还有很多情况是服从泊松分布的: 10分钟内从ATM中取钱的人数一天中发生车祸的次数每100万人中患癌症的人数单位面积土地内昆虫的数目Poisson模型(泊松回归模型)是用于描述单位时间、单位面积或者单位容积内某事件发现的频数分布情况, 通常用于描述稀有事件(即小概率)事件发生数的分布。 上述例子中都明显的一个特点: 低概率性,以及单位时间(或面积、体积)内的数量。 通常情况下,满足以下三个条件时,可认为数据满足Poisson分布: (1) 平稳性:发生频数的大小,只与单位大小有关系(比如1万为单位,或者100万为单位时患癌症人数不同);(2) 独立性:发生频数的大小,各个数之间没有影响关系,即频数数值彼此独立没有关联关系; 比如前1小时闯红灯的人多了,第2小时闯红灯人数并不会受影响;(3) 普通性:发生频数足够小,即低概率性。如果数据符合这类特征时,而又想研究X对于Y的影响(Y呈现出Poisson分布); 此时则需要使用Poisson回归,而不是使用常规的线性回归等。 1.2 LightGBM 实现泊松回归的案例参考来源:https://github.com/Microsoft/LightGBM/issues/807 import lightgbm as lgb import numpy as np import pandas as pd n=100000 lam = .01 X = np.floor(np.random.lognormal(size=(n,2))).astype(int) y = np.maximum(X[:,0],X[:,1])+np.random.poisson(lam=lam, size=n) train_inds = np.arange(int(n/3)) val_inds = np.arange(int(n/3), int(2*n/3)) test_inds = np.arange(int(2*n/3), int(n)) X_test, y_test = X[test_inds,:], y[test_inds] ds = lgb.Dataset(X,y, categorical_feature=[1]) ds_train = ds.subset(train_inds) ds_val = ds.subset(val_inds) params = {'objective':'poisson', 'metric':'rmse', 'learning_rate':.1 } gbm = lgb.train(params, ds_train, num_boost_round=300, early_stopping_rounds=20, valid_sets=[ds_val, ds_train], verbose_eval=100, categorical_feature=[1]) yhat = gbm.predict(X_test) print('neg obs:', len(yhat[yhat= datetime(year=2012, month=1, day=1))&(df.dteday < datetime(year=2012, month=5, day=1))].copy() X_val_surv['count_so_far'] = X_val_surv.apply(lambda x: np.arange(max_count), axis=1) X_val_surv['stop'] = X_val_surv.apply(lambda x:np.append(np.zeros(x.casual), np.ones(max_count-x.casual)), axis=1) X_val_surv = X_val_surv.apply(pd.Series.explode) X_val_surv['count_so_far'] = X_val_surv.count_so_far.astype(int) X_val_surv['stop'] = X_val_surv.stop.astype(int) y_val_surv = X_val_surv['stop'] X_val_surv = X_val_surv[columns+['count_so_far']] print(X_val_surv.shape)具体的已经在2.1 描述过了;这里要额外来看一下max_count,这个在train数据集中不会出现, 也就是今天有多少临时用户,就是多少X_train.apply(lambda x: np.arange(x.casual), axis=1) 但你会看到,X_val_surv是X_val_surv.apply(lambda x: np.arange(max_count), axis=1),这里就是临时用户的最大值设定为4000,这个值根据临时用户max值来取的,就是临时用户上线。 params = { 'objective':'poisson', 'num_leaves':30, 'learning_rate': 0.001, 'feature_fraction': 0.8, 'bagging_fraction': 0.9, 'bagging_seed': 33, 'poisson_max_delta_step': 0.8, 'metric': 'poisson' } ### FIT LGBM WITH POISSON LOSS ### trn_data = lgb.Dataset(X_train, label=y_train) val_data = lgb.Dataset(X_val, label=y_val) model = lgb.train(params, trn_data, num_boost_round=1000, valid_sets = [trn_data, val_data], verbose_eval=50, early_stopping_rounds=150)这里X_train的shape为:(247252, 13),那么可以知道训练集是非常大的; 需要重置数据,可到: ### PREDICT HAZARD FUNCTION ON VALIDATION DATA AND TRANSFORM TO SURVIVAL ### p_val_hz = model.predict(X_val_surv).reshape(-1,max_count) p_val = 1-np.exp(-np.cumsum(p_val_hz, axis=1)) X_val_surv.shape >>> (484000, 12) p_val.shape >>> (121, 4000)p_val就回归正常,代表着每一天,不同人群数量的概率,直接上图: 简单的模型检验: ### CRPS ON VALIDATION DATA ### crps(t_val, p_val) >>> 0.17425293919055515 ### CRPS ON VALIDATION DATA WITH BASELINE MODEL ### crps(t_val, np.repeat(cdf, len(t_val)).reshape(-1,max_count)) 3 同等lightGBM分类测试https://blog.csdn.net/wang263334857/article/details/81836578 来看一下同一份数据测试出来的结果如何,后续不贴太多,只贴一下我测试的代码,放在了之前的一个项目下面:Survival_Poisson_Regression |
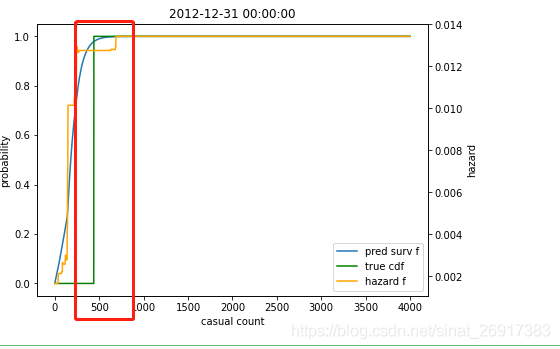 这天在500左右,达到峰值了,那么这天临时用户的预测值就在500左右了。
这天在500左右,达到峰值了,那么这天临时用户的预测值就在500左右了。【本文地址】
今日新闻 |
推荐新闻 |