[数据结构 链表] 链表的定义与表示,删除,插入,初始化,循环链表,双向链表,链表的应用,多项式创建 |
您所在的位置:网站首页 › 在单链表双链表和单循环链表中 › [数据结构 链表] 链表的定义与表示,删除,插入,初始化,循环链表,双向链表,链表的应用,多项式创建 |
[数据结构 链表] 链表的定义与表示,删除,插入,初始化,循环链表,双向链表,链表的应用,多项式创建
|
单链表的定义和表示
n
线性表链式存储结构的特点
Ø
用一组
任意的
存储单元存储线性表的数据元素。
l
存储结点的地址
可以连续或不连续
l
即:逻辑上相邻的数据元素在物理上不一定相邻
Ø
为此,对线性表中的每一个数据元素,都需用两部分来存储:
l
一部分用于
存放数据元素
本身的信息,称为
数据域
(Data Field)
;
l
另一部分用于
存放直接前驱或直接后继的地址
(
指针
)
,称为
指针域
(Link Field)
。
n
与链式存储有关的术语
何谓首元结点、头结点和头指针? Ø 首元结点 l 是指链表中存储第一个数据元素 a 1 的结点 Ø 头结点 l 是在链表的首元结点之前附设的一个结点,其指针域指向首元结点 l 头结点不计入链表长度,其数据域通常不存储信息 Ø 头指针 l 指向链表中第一个结点 ( 为 头结点 或 首元结点 ) 的指针
如何表示空表? n 无头结点 Ø 空表: 头指针为 NULL 时 Ø 非空表
 Status ClearList(LinkList L)
{// 将L重置为空表
LinkList p,q;
p=L->next; //p指向首元结点
while(p) //没到表尾
{q=p->next; delete p; p=q;}
L->next=NULL; //头结点指针域为空
return OK;
}
n4. 求单链表的长度
Status ClearList(LinkList L)
{// 将L重置为空表
LinkList p,q;
p=L->next; //p指向首元结点
while(p) //没到表尾
{q=p->next; delete p; p=q;}
L->next=NULL; //头结点指针域为空
return OK;
}
n4. 求单链表的长度
 int ListLength(LinkList L)
{ //返回L中数据元素个数
LinkList *p=L->next; //p指向首元结点
int count=0;
while(p){//遍历单链表,统计结点数
++count;
p=p->next;
}
return count;
}
n5. 判断单链表是否为空
bool ListEmpty(LinkList L)
{//若L为空表,则返回true,否则返回false
return L->next==NULL;
}
n6.获取单链表中第i个数据元素的内容
Ø
算法步骤:
l
用指针
p
指向首元结点,用
j
做计数器初值赋为
1
l
从首元结点开始依次顺着链域
next
向后访问,只要指向当前结点的指针
p
不为空,并且没有到达序号为
i
的结点,则循环执行以下操作:
ü
p
指向下一结点,同时计数器
j
加
1
l
当循环执行完成时,如果指针
p
为空,或者计数器
j
大于
i
,说明指定的序号
i
值不合法,取值失败返回
ERROR
;否则取值成功,此时有
j =
i
,
p
所指的结点就是要找的第
i
个结点。
Status GetElem(LinkList L,int i,ElemType &e){
//当第i个元素存在时,其值赋给e并返回OK,否则返回ERROR
p=L->next; j=1; //初始化
while(p && jnext; ++j;
}
if(!p || j>i) return ERROR; //第i个元素不存在
e=p->data; //取第i个元素
return OK;
}
int ListLength(LinkList L)
{ //返回L中数据元素个数
LinkList *p=L->next; //p指向首元结点
int count=0;
while(p){//遍历单链表,统计结点数
++count;
p=p->next;
}
return count;
}
n5. 判断单链表是否为空
bool ListEmpty(LinkList L)
{//若L为空表,则返回true,否则返回false
return L->next==NULL;
}
n6.获取单链表中第i个数据元素的内容
Ø
算法步骤:
l
用指针
p
指向首元结点,用
j
做计数器初值赋为
1
l
从首元结点开始依次顺着链域
next
向后访问,只要指向当前结点的指针
p
不为空,并且没有到达序号为
i
的结点,则循环执行以下操作:
ü
p
指向下一结点,同时计数器
j
加
1
l
当循环执行完成时,如果指针
p
为空,或者计数器
j
大于
i
,说明指定的序号
i
值不合法,取值失败返回
ERROR
;否则取值成功,此时有
j =
i
,
p
所指的结点就是要找的第
i
个结点。
Status GetElem(LinkList L,int i,ElemType &e){
//当第i个元素存在时,其值赋给e并返回OK,否则返回ERROR
p=L->next; j=1; //初始化
while(p && jnext; ++j;
}
if(!p || j>i) return ERROR; //第i个元素不存在
e=p->data; //取第i个元素
return OK;
}
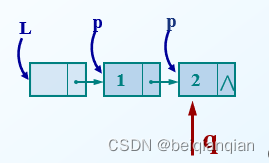
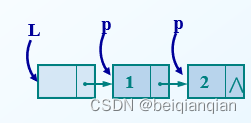
算法的平均时间复杂度为O(n) n7. 查找值为e的数据元素 Ø 算法步骤 l 用指针 p 指向首元结点 l 从首元结点开始依次顺着链域 next 向后访问,只要指向当前结点的指针 p 不为空,并且 p 所指结点的数据域不等于 e ,则循环执行以下操作: ü p 指向下一结点 l 循环执行完成后 返回 p 。若查找成功, p 此时即为目标结点的地址值;若查找失败, p 的值为 NULL 。 LNode * LocateElem (LinkList L,ElemType e) { p=L->next; while(p && p->data!=e) p=p->next; return p; //返回L中值为e的数据元素的位置,查找失败返回NULL }算法的平均时间复杂度为O(n) n8.在单链表的第i个位置插入一个数据元素 Ø 目标: 将值为 e 的新结点插入到表的第 i 个结点的位置上,即插入到 a i-1 与 a i 之间 Ø 算法步骤 l 找到 a i-1 存储位置 p l 生成一个新结点* s l 将新结点* s 的数据域置为 e l 新结点* s 的指针域指向结点 a i l 令结点* p 的指针域指向新结点* s
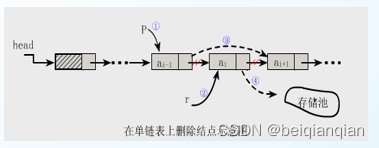
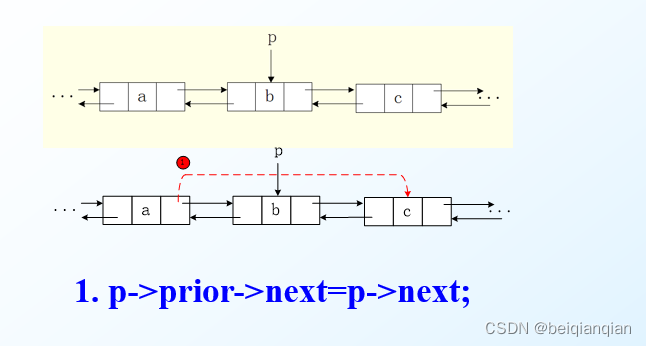
算法的平均时间复杂度为O(n) n9. 删除线性表中第i个数据元素 Ø 目标:将表的第 i 个结点删除,结果放在 e 中 Ø 算法步骤 l 查找结点 a i-1 , 令指针 p 指向该结点 l 临时保存待删除结点 a i 的地址在 r 中,以备释放 l 将结点 *p 的指针域指向 a i 的直接后继结点 l 将 a i 的值保留在 e 中,释放结点 a i 的空间
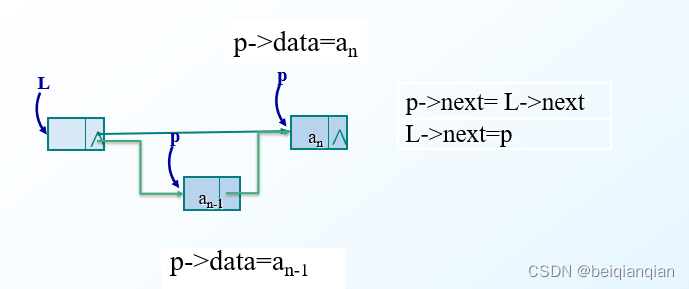
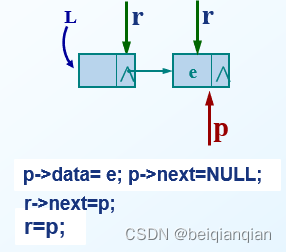
算法的平均时间复杂度为O(n) n 10 创建单链表 Ø 注意,初始化操作创建的是只有一个头结点的空链表。而前述的算法都假定链表中有多个结点。 Ø 那么如何创建包含多个结点的单链表呢? Ø 根据结点插入位置的不同,创建链表的方法: l 前插法 l 后插法 前插法: n 前插法是通过将新结点逐个插入链表的头结点之后来创建单链表。 n 每次首先申请一个新结点,然后将读入的数据存放到新结点的数据域中,最后将新结点插入到头结点之后。 n 算法步骤 Ø 创建一个只有头结点的空链表 Ø 根据待创建链表包含的元素个数 n ,循环 n 次执行以下操作 l 生成一个新结点 *p l 将读入的数据存放到新结点 *p 的数据域中 l 将新结点 *p 插入到头结点之后
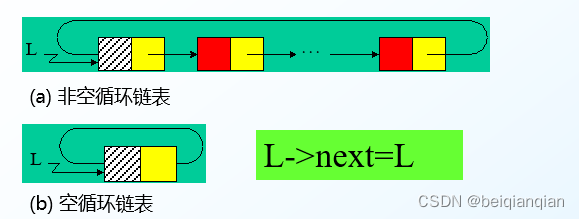
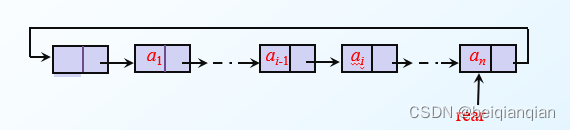
存取效率不高,必须采用顺序存取,即存取数据元素时,只能按链表的顺序进行访问 n循环链表
n循环链表的合并
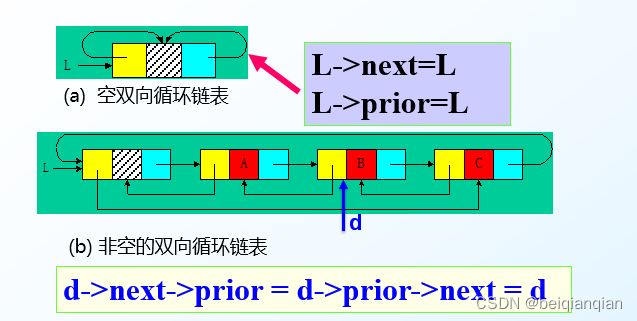
n双向链表
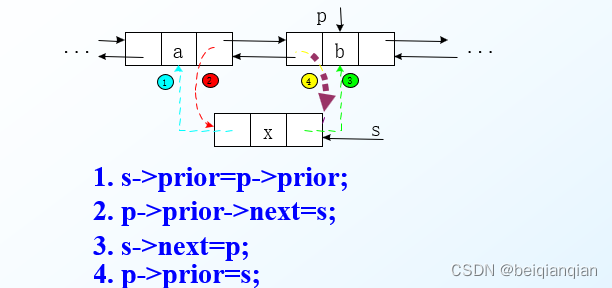
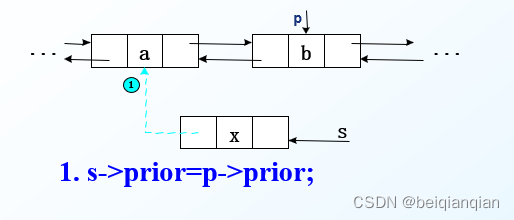
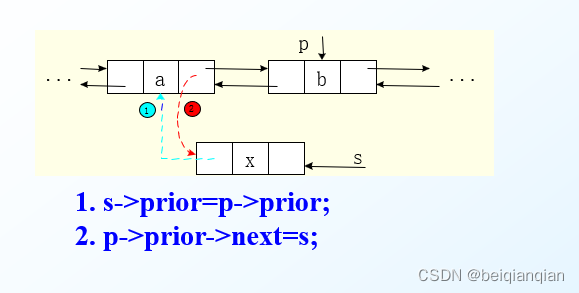
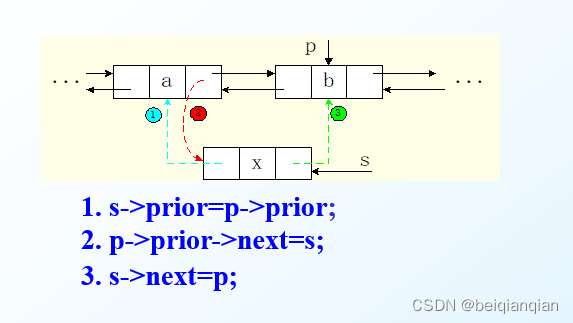
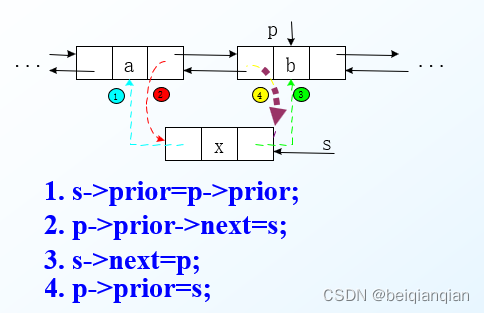
n双向链表的插入
顺序表和链表的比较
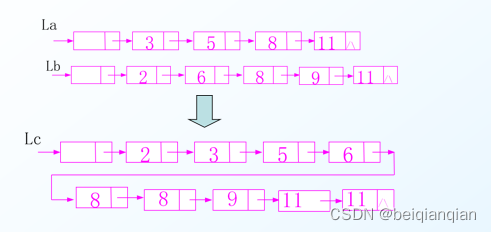
n有序表的合并 已知线性表A和B中的数据元素按值非递减有序排列,现要求将A和B归并为一个新的线性表C,且C中的数据元素仍按值非递减有序排序。 示例:A=(3,5,8,11),B=(2,6,8,9,11) 合并后: C =( 2 , 3 , 5 , 6 , 8 , 8 , 9 , 11,11 ) Ø假定线性表 A和B分别由单链表 La 和 Lb 存储
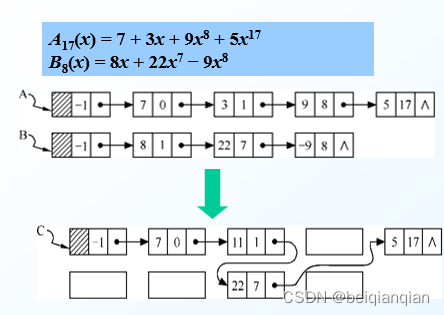
一元多项式相加: 依次比较Pa和Pb所指结点中的指数项,依次比较Pa->expn =、Pb->expn等情况,再决定是将两系数域的数值相加(并判其和是否为0),还是将较低指数项的结点插入到新表c中。
一、判断题 1. 线性表的逻辑顺序与物理顺序总是一致的。F 2. 线性表的顺序存储表示优于链式存储表示。F 3. 线性表若采用链式存储表示时 , 所有结点的地址可连续可不连续。T 4. 每种数据结构都应具备三种基本运算:插入、删除和搜索。T 5. 线性表的特点是每个元素都有一个前驱和一个后继。F 6. 顺序存储方式插入和删除时效率太低,因此它不如链式存储方式好。 F二、填空题 1. 线性表( a 1 ,a 2 , … ,a n )有两种存储结构: ( A )和( B )。( A )存储密度较大,( B )存储利用率较高,( A )可随机存取,( B )不可随机存取,( B )插入和删除操作比较方便。 ●A顺序存储结构 ●B链式存储结构 (链表对内存的利用率比较高,无需连续的内存空间,即使有内存碎片,也不影响链表的创建) 2. 在单链表中,删除指针 p 所指结点的后继结点的语句是:( p->next=p->next->next ) 3. 带头结点的单循环链表 Head 的判空条件是( Head->next=Head )。 4. 画出下列数据结构的图示:①顺序表 ②单链表 ③双链表 ④循环链表 5. 在一个长度为 n 的顺序表中第 i 个元素( 1next==L ) 8. 在单链表 L 中,指针 p 所指结点有后继结点的条件是: (p->next!=null ) 9. 当线性表的元素总数基本稳定,且很少进行插入和删除操作,但要求以最快的速度存取线性表中的元素时,应采用( 顺序 )存储结构。 |




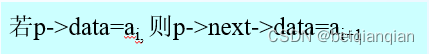







【本文地址】
今日新闻 |
推荐新闻 |