狗狗图片识别分类的CNN(卷积网络)实现 |
您所在的位置:网站首页 › 图片识别如何实现 › 狗狗图片识别分类的CNN(卷积网络)实现 |
狗狗图片识别分类的CNN(卷积网络)实现
|
项目概述:
一种可用于移动应用或网络应用的算法。 代码将能够接受任何用户提供的图像作为输入。 如果从图像中检测出小狗,该算法将大致识别出小狗品种。 如果检测出人脸,该算法将大致识别出最相似的小狗品种。 项目学习步骤: 导入以及预处理数据集建立人脸检测模块:采用OpenVC检测人脸(https://docs.opencv.org/trunk/db/d28/tutorial_cascade_classifier.html)建立小狗识别模块:使用预训练的 ResNet-50 模型来检测图片中的狗狗从头开始创建预测小狗分类品种的 CNN:基于Keras添加CNN,此处使用categorical_crossentropy对于multiclassifier图片标签分类更有效(损失函数是用来估量模型中预测值y与真实值Y之间的差异,即不一致程度)使用迁移学习分类小狗品种的 CNN:基于预训练的模型获取瓶颈特征,在此基础上叠加CNN,以降低训练时间 VGG-16(Kaggle Compitition link if you are interested)Xception(Kaggle Compitition link if you are interested)编写算法:将图像的文件路径作为输入,并首先判断图像中是否包含人脸、小狗测试算法:测试图片获取分类 项目实施步骤与分析: 数据导入与预处理- 将准备完整的数据集,在本项目中为一系列狗狗图片,图片预存在服务器 - 项目数据集已分别存放在test, valid, train三个文件夹中 - 狗狗分类共133种,并以文件夹名与文件名形式预处理,例如:"train\001.Affenpinscher\Affenpinscher_00001.jpg" - 导入人脸文件数据文件,并做随机排序,不做分类训练 - 处理异常数据:项目数据集并无异常数据,但仍可以考虑添加对于文件类型filter图片类型文件,以及格式错误的文件 通过以下示例代码读取对数据进行预处理, # 函数获取test, train, valid数据,使用np array存储 def load_dataset(path): data = load_files(path) dog_files = np.array(data['filenames']) dog_targets = np_utils.to_categorical(np.array(data['target']), 133) return dog_files, dog_targets # 从文件夹中获取 train_files, train_targets = load_dataset('文件地址/train') valid_files, valid_targets = load_dataset('文件地址/data/dog_images/valid') test_files, test_targets = load_dataset('文件地址/data/dog_images/test') # 获取狗狗名称 dog_names = [item[20:-1] for item in sorted(glob("文件地址/train/*/"))] random.seed(8675309) # 获取人脸图片文件名 human_files = np.array(glob("../../../data/lfw/*/*")) random.shuffle(human_files)建立人脸检测模块 - 使用OpenCV 提供的预训练人脸检测器:可以将XML 文件的形式从github下载并使用。 - 本次测试代码使用Haar 特征级联分类器(Haar feature-based cascade classifiers来检测图片中的人脸 - 测试人脸检测模块的accuracy 通过以下示例代码建立人脸检测模块 # 读取xml face_cascade = cv2.CascadeClassifier('目标文件夹/haarcascade_frontalface_alt.xml') # 读取并将文件灰度化 img = cv2.imread(human_files[3]) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 调用探测人脸 faces = face_cascade.detectMultiScale(gray) #如定义检测函数,此处可以return len(faces) > 0 作为检测结果 # 加个框 for (x,y,w,h) in faces: cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2) # 将BGR通道转化为RGB cv_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 展示找到的人脸图片 plt.imshow(cv_rgb) plt.show()如找到人脸,示例代码输出:
通过测试预先load的人脸与狗狗文件,做一个准确性测试,示例代码如下: ## 检测 print("Human detected: ",np.mean([face_detector(f) for f human_files[:100]])) print("Dog detected: ",np.mean([face_detector(d) for d train_files[:100]])) 示例代码输出: Human detected: 1.0 Dog detected: 0.11结论与分析:对于'human_files",人脸检测100%(1.0)。对于‘dog_files',人脸检测为11%(0.11) 。此模型对于11%狗狗识别为人脸,但是对于人脸图片100%成功,未来可以通过组合其他CNN的方法,比如FaceNet等不同的算法和模型交叉测试降低错误率。 建立小狗识别模块 - 预处理Keras CNN要求输入的数组类型:一个 4D 的 numpy 数组(我们也称之为 4 维张量),其形状为(nb_samples,rows,columns,channels), 其中 nb_samples表示图片 (或样本) 的数量, rows、 columns和 channels表示每个图片 各自的行数、列数和通道数。 - 使用Keras预训练的 ResNet-50 模型来检测图片 - 使用在 ImageNet 预训练后的权重信息 - 通过对预测概率向量取 argmax,我们得到一个整数,该整数表示该图片所属的类别的序号,我们可以使用这个字典找到类别名称。 通过以下示例代码建立小狗识别模块 #初始化基于ImageNet权重的ResNet50模型 ResNet50_model = ResNet50(weights='imagenet') # 处理图片成为4维向量 # 读取RGB图片 as PIL.Image.Image type img = image.load_img(img_path, target_size=(224, 224)) # 转置生成向量 x = image.img_to_array(img) # 将3维向量升为4维向量 img_tensor = np.expand_dims(x, axis=0) #使用keras.applications.resnet50的预处理函数,对进行归一化、转化BGR img = preprocess_input(img_tensor) #测试输入的图片,获取预测结果的类别键值 prediction = np.argmax(ResNet50_model.predict(img)) #根据字典的分类151~268之间为狗狗 result = ((prediction = 151))通过测试预先load的人脸与狗狗文件,做一个准确性测试,示例代码如下: # 使用前述代码定义dog_detector, 返回true如果找到 print("human detected: ", np.mean([dog_detector(h) for h in human_files[:100])) print("dog dtected: ", np.mean([dog_detector(d) for d in dog_files[0:100]))示例代码输出: 0.0 - 0%人脸图片被识别 1.0 - 100%狗狗图片被识别 结论与分析:对于'dog_files",基于ResNet50的狗狗识别预测100%准确。对于‘human_files',没有错误识别为狗狗。基于事先训练的预测模型,对于同样的数据集,表现出比述程序更高的准确率和更低的错误率。下一步可以使用不同的数据集(模糊的,人狗混合的)图片进一步训练预设模型,是否会出现不同的表现。 从头开始创建预测小狗分类品种的 CNN- 预处理数据:缩放图像 - 添加卷积层:尝试cov2d, maxPooling2D, globalAveragePooling2D, Dense的组合 - 训练做到在 CPU 上训练相对较快并且训练至少5个周期(epoch),准确率 >1% - 分析和测试模型效果 预处理数据的代码示例 #将像素除以255来进行缩放 train_tensors = paths_to_tensor(train_files).astype('float32')/255 valid_tensors = paths_to_tensor(valid_files).astype('float32')/255 test_tensors = paths_to_tensor(test_files).astype('float32')/255添加如下CNN组合
示例代码如下 model = Sequential() # 第一层卷积层与第一层最大池化层 model.add(Conv2D(filters=16, kernel_size=2, padding='valid', activation='relu',input_shape=(224,224,3))) model.add(MaxPooling2D(pool_size=2)) # 第二层卷积层与最大池化层 model.add(Conv2D(filters=32, kernel_size=2, padding='valid', activation='relu')) model.add(MaxPooling2D(pool_size=2)) # 第三层卷积层与最大池化层 model.add(Conv2D(filters=64, kernel_size=2, padding='valid', activation='relu')) model.add(MaxPooling2D(pool_size=2)) # 添加Global Average Pool model.add(GlobalAveragePooling2D(data_format='channels_last')) # 添加Dense model.add(Dense(133, activation='softmax'))结论与分析:按上图提示搭建卷积网络,该网络能取得很好表现的原因: 一方面,卷积层对特征选取并局部感知,这样可以在更高层次对局部做综合操作,最终获取全局信息;此外,池化层对特征降维,减小过拟合,通过MaxPooling保留最强的特征,再通过平均池化,形成一个特征点;最后使用Dense对特征向量进行softmax计算。 训练做到在 CPU 上训练相对较快并且训练至少5个周期(epoch),准确率 >1% epochs = 150 #尝试150个周期,分析下结果 checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.from_scratch.hdf5', verbose=1, save_best_only=True) history = model.fit(train_tensors, train_targets, validation_data=(valid_tensors, valid_targets), epochs=epochs, batch_size=20, callbacks=[checkpointer], verbose=1)
输出的测试结果: Test accuracy: 13.1579%结论与分析:按5次Epoch结果看,Accuracy = 2.03%,该模型已符合基本大于1%的要求。继续进行直至150次Accuracy = 21%, 每个epoch的val_loss improve已经不再显著,当然可以再尝试更多轮学习周期直到val_loss上升。也可以使用 keras.callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)来自动识别val_loss上升的epoch。 使用迁移学习分类小狗品种的 CNN- 使用预训练的 VGG-16 模型和Xception 模型作为固定的特征提取器(fixed feature extractor),也就是说,特征提取器的最后一层卷积层的输出会作为我们模型的输入。我们仅仅加入了一层全局平均池化层(global average pooling layer)和一个全连接层(fully connected layer),后者包含一个节点,该节点和所有狗狗品种的节点相连,并使用 softmax 激活函数
- 测试并分析两个模型的预测效果 以迁移学习VGG-16模型代码示例: # 获取瓶颈特征 bottleneck_features = np.load('bottleneck_features/DogVGG16Data.npz') train_VGG16 = bottleneck_features['train'] valid_VGG16 = bottleneck_features['valid'] test_VGG16 = bottleneck_features['test'] # 加入了一层全局平均池化层(global average pooling layer)和一个全连接层(fully connected layer),后者包含一个节点,该节点和所有狗狗品种的节点相连,并使用 softmax 激活函数 VGG16_model = Sequential() VGG16_model.add(GlobalAveragePooling2D(input_shape=train_VGG16.shape[1:])) VGG16_model.add(Dense(133, activation='softmax')) # 编译模型 VGG16_model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy']) # 训练模型 Epochs = 150 checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.VGG16.hdf5', verbose=1, save_best_only=True) history = VGG16_model.fit(train_VGG16, train_targets, validation_data=(valid_VGG16, valid_targets), epochs=150, batch_size=20, callbacks=[checkpointer], verbose=1) # 加载验证损失最低的模型 VGG16_model.load_weights('saved_models/weights.best.VGG16.hdf5') # 测试模型 VGG16_predictions = [np.argmax(VGG16_model.predict(np.expand_dims(feature, axis=0))) for feature in test_VGG16] # 输出准确率 test_accuracy = 100*np.sum(np.array(VGG16_predictions)==np.argmax(test_targets, axis=1))/len(VGG16_predictions) print('Test accuracy: %.4f%%' % test_accuracy)
代码输出:Test accuracy: 53.2297% 同理模式可获得Xception瓶颈特征的Test accuracy: 84.3301% 结论与分析:根据以下的图表分析 图 - VGG16 (左)vs Xception(右)
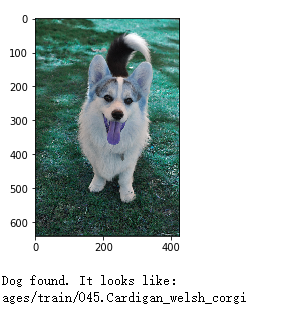
Xception的瓶颈特征,有着更好的学习效率以及预测准确度,对于狗狗分类识别的图片数据集而言,在此选择Xception的瓶颈特征作为最终狗狗分类识别的瓶颈特征是正确的选择。接下去也可以尝试其他特征集合,比如 VGG-19 瓶颈特征ResNet-50 瓶颈特征Inception 瓶颈特征进行对比,可能会有更合适预测模型。 编写算法:将图像的文件路径作为输入,并首先判断图像中是否包含人脸、小狗首先判断图像中是否包含人脸、小狗,或二者都不含。然后, 如果在图像中检测到了小狗,则返回预测的品种。如果在图像中检测到了人脸,则返回相似的小狗品种。如果二者都没检测到,则输出错误消息。示例代码如下 # 预测并输出结果和图片 def predict_dog(img_path): img = cv2.imread(img_path) plt.imshow(img) plt.show() if dog_detector(img_path): print('Dog found. It looks like: ') print(Xception_predict_breed(img_path)) # display the image, along with bounding box elif face_detector(img_path): print('Human found. It looks like: ') print(Xception_predict_breed(img_path)) else: print('ERROR!NOT FOUND!') 测试算法:测试图片获取分类输入图片测试结果
通过项目的学习,我们可以将预训练的特征,权重,和不同的CNN算法组合起来,对数据添加卷积层,比如cov2d, maxPooling2D, globalAveragePooling2D, Dense的组合以获得更高的accuracy。同时,观测val_loss的变化,避免过度拟合现象的出现,通过学习周期的控制(keras callback)选取合适的学习周期获得预测模型。 关于项目指标的讨论:模型使用了根据accuracy作为度量评估的方式对于测试集进行度量,因为狗的品种数据集内品种相对平衡,简单的accuracy足够了,否则可能F1等指标更合适。根据项目的目标:任务类型多类别分类,选用 categorical_crossentropy评估我们的模型。最终实验分别在100张人和狗的图像上进行了validation,共有6680张狗狗训练图片和835张验证图片、836张测试图片参与模型训练。人脸探测器是基于OpenCV的HAARCascade特征分类,在13223人的脸上训练的,而狗探测器使用了预训练的ResNet50模型,来确定图像是否为狗。
模型评估和预测: 使用OpenVC人脸探测器对于11%狗狗识别为人脸,但是对于人脸图片100%成功;使用ResNet50的狗脸探测器可以确认100%的狗狗为狗,并正确的识别出0%的人是狗。犬类别模型的分类器,通过绘制学习曲线的方法检查模型是否过拟合:
训练精度达到96%以上,而验证精度低于86%,最后的测试精度在84%,说明该模型与训练集过度拟合。 当然由于此项目训练集相对大(相对于CNN架构),可以通过增加更多池化层用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的容错性,通过增加MaxPooling能够保留最强的特征。 测试过程中,GPU的使用大大缓解了项目对于计算速度慢的限制,使得测试者在模型的训练时,可以在更多的学习周期中选择合适的,在不同的CNN组合中发现合适的组合。 项目过程中有趣或者困难的点:比较不同的CNN预学习模型学习速率的差异,发现CNN本身是一个类似人类学习的过程,一手拿着正确答案,一手拿着待训练的模型,期待能诞生一组合适的weight与网络激活组合。 进一步探索: 1)尝试一些新的人脸识别算法,比如基于深度学习的一些算法FaceNet等 2)对于照片中同时出现多个dog或者human,考虑目标识别算法RCNN等 3)通过增加数据量或者采用交叉验证对实验数据做不同的处理提高模型准确率 参考:VGG-16架构 https://zhuanlan.zhihu.com/p/48760794 对于xception非常好的理解 https://www.jianshu.com/p/4708a09c4352 FaceNet: A Unified Embedding for Face Recognition and Clustering https://arxiv.org/abs/1503.03832 Cascade Classifier https://docs.opencv.org/trunk/db/d28/tutorial_cascade_classifier.html ResNet https://ethereon.github.io/netscope/#/gist/db945b393d40bfa26006 Keras Plot https://machinelearningmastery.com/display-deep-learning-model-training-history-in-keras/ OpenCV 中的 Haar 级联检测 https://blog.csdn.net/tingyuxinhappy/article/details/88793406 |




 分析和测试模型效果:
分析和测试模型效果:










【本文地址】
今日新闻 |
推荐新闻 |