一篇基于横断面研究数据统计分析论文的完全解析和统计方法解读 |
您所在的位置:网站首页 › 因果分断 › 一篇基于横断面研究数据统计分析论文的完全解析和统计方法解读 |
一篇基于横断面研究数据统计分析论文的完全解析和统计方法解读
|
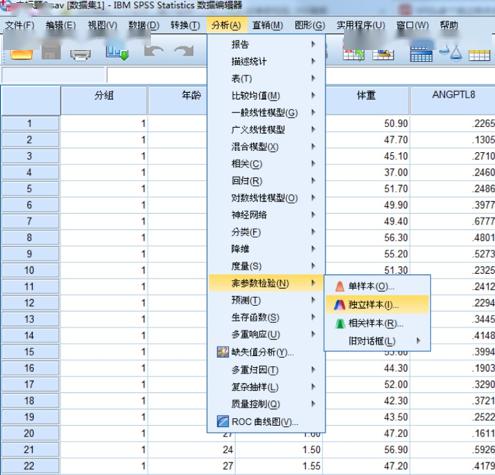
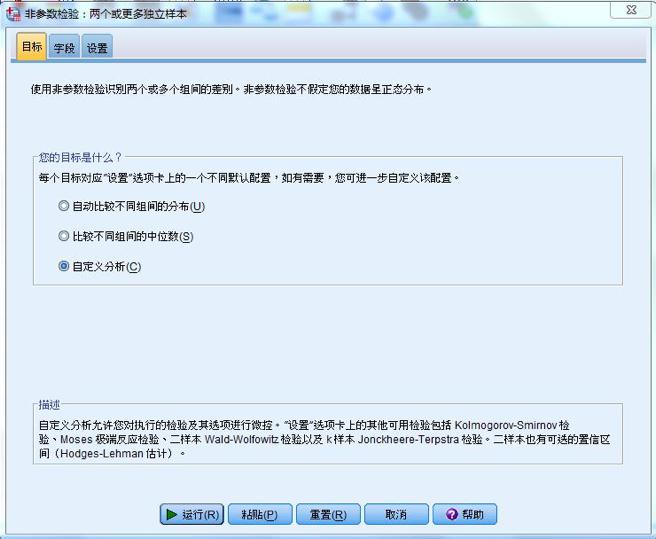
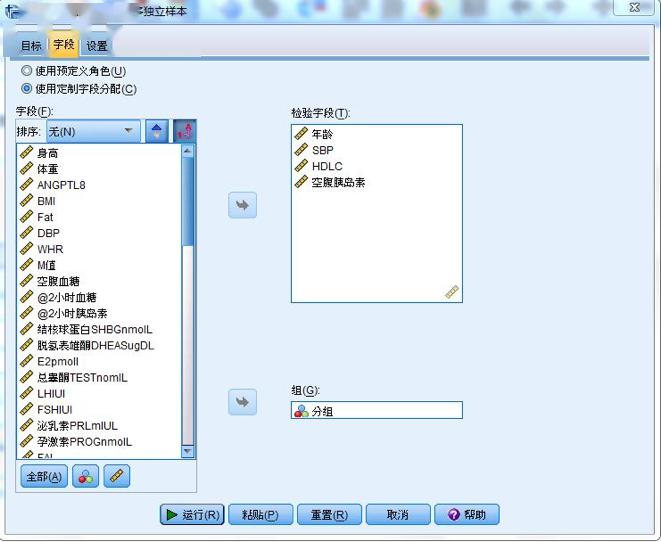
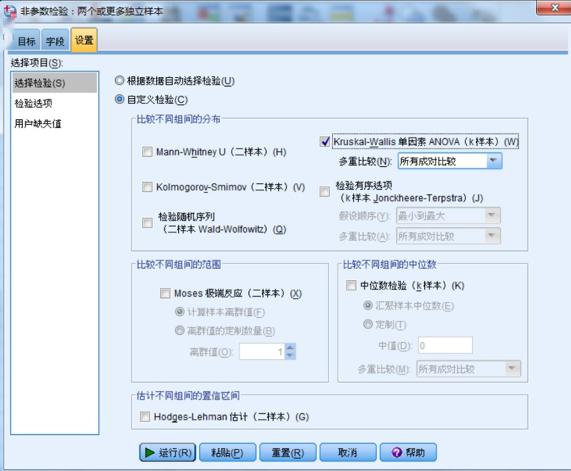
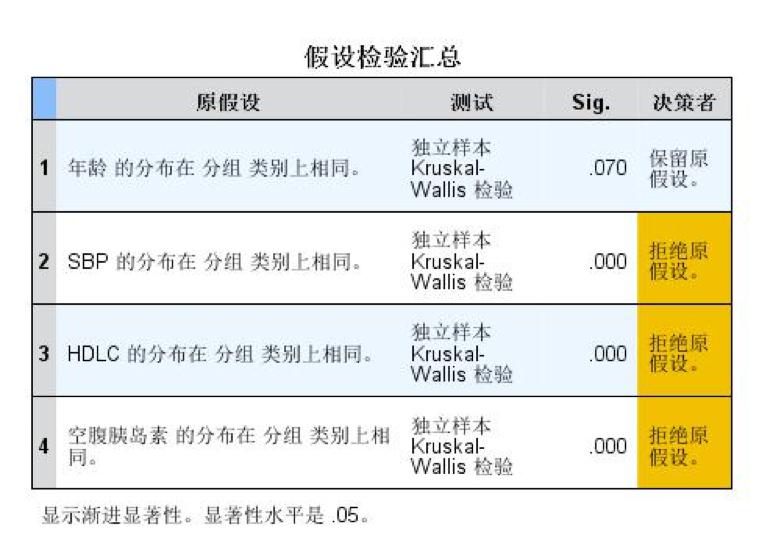
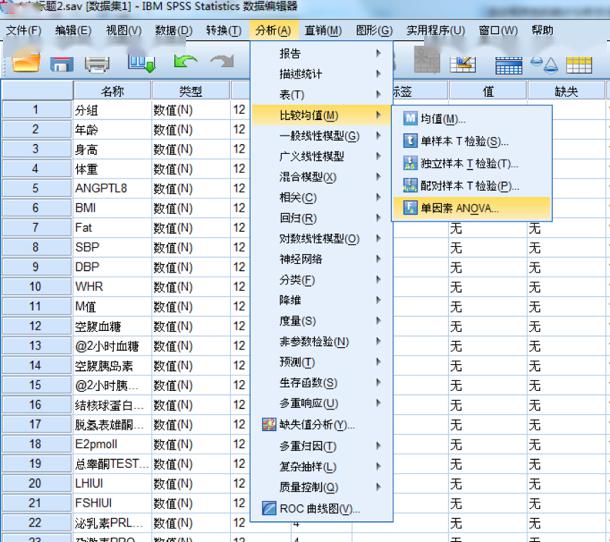
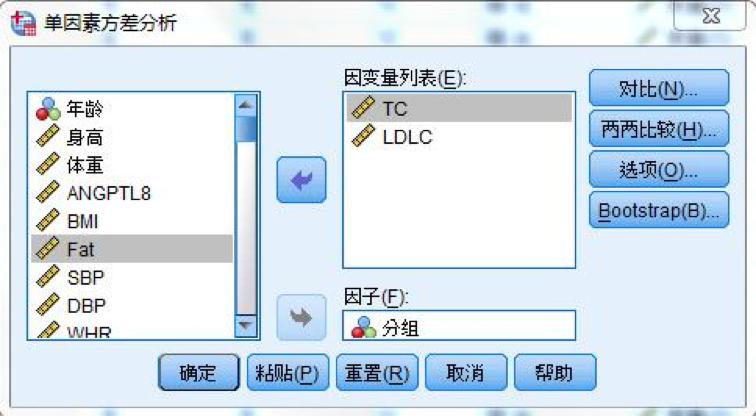
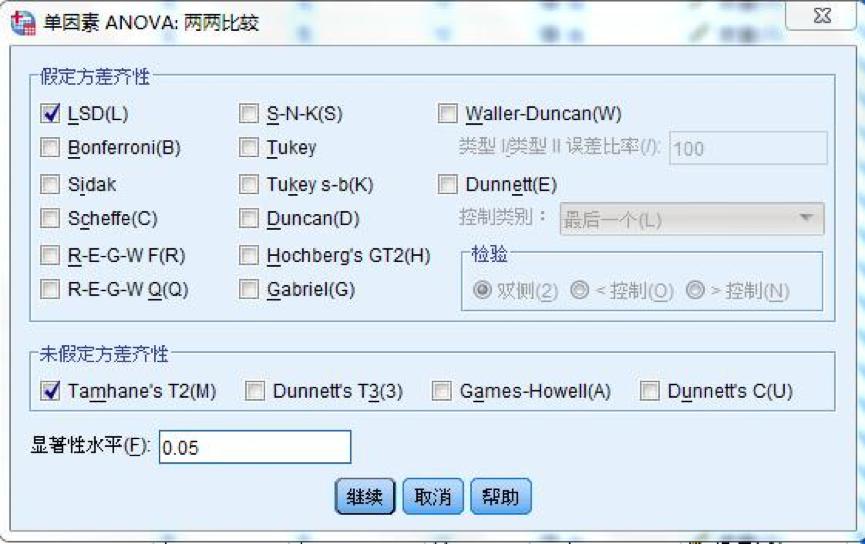
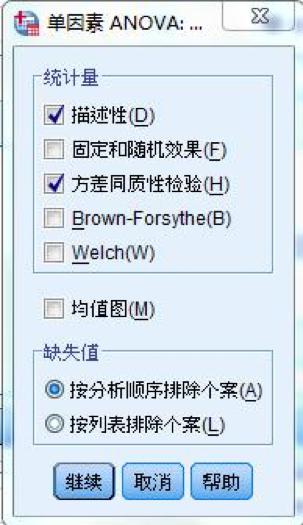
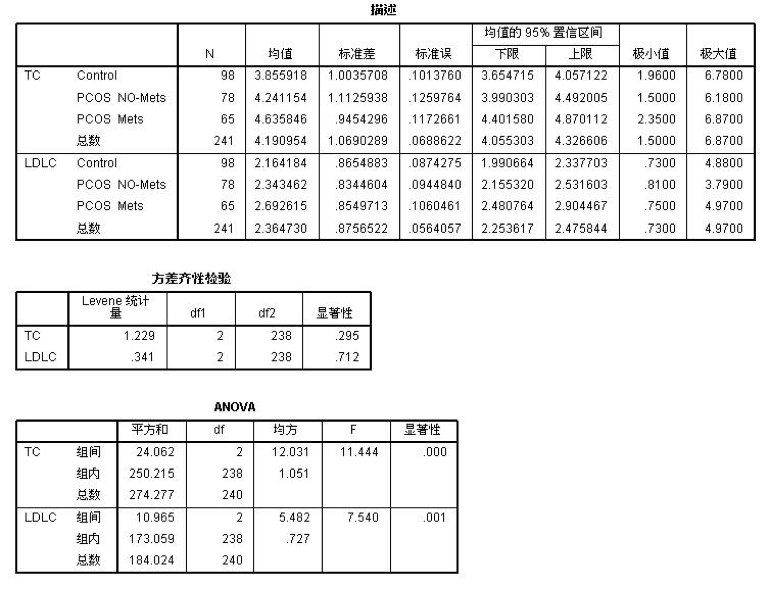
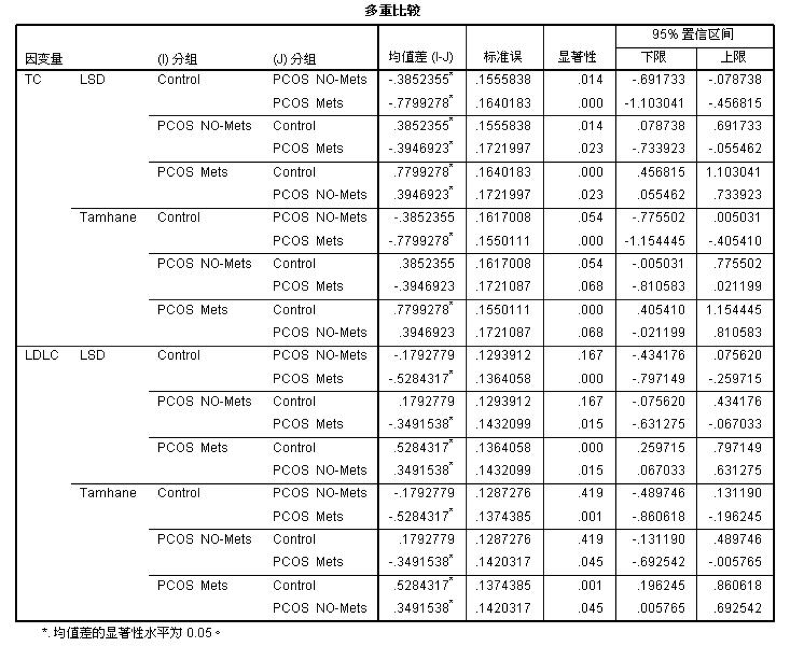
文章的设计 科学研究的基本框架大致分为选题、执行、总结三个部分,我们已经通过提出问题、查阅文献形成了初步的研究思路,明确了研究方向、研究人群以及可行的研究方法,下一步工作的方向便是执行和总结了。有了总的设计框架,具体执行还需要分步骤和细化才能推进和完成。 就我们这篇文章而言,除了刚刚谈到的选题,执行部分还包括实验设计、伦理审批、临床实验注册、从事实验、收集数据、整理和处理数据、设计分析等一系列工作,最后撰写论文、发表论文才算完成了研究。我们这篇文章涉及的横断面研究主要收集特定人群(PCOS女性与健康对照女性)的人体测量指标(身高、体重、腰臀围、血压等)、ANGPTL8浓度、代谢紊乱以及与生殖相关的实验室检测指标(包括空腹血糖、空腹胰岛素、血脂、性激素)等一系列数据。 为了更好了解ANGPTL8浓度与PCOS女性胰岛素抵抗的关系,我们还进行了口服糖耐量实验(Oral glucose tolerance test,OGTT)和高胰岛素正葡萄糖钳夹实验(Euglycemic-hyperinsulinemic clamp,EHC)。希望通过探索和寻找ANGPTL8浓度与相关指标的关系,找到新的突破点,找出有效的信息来指导临床诊治。在本文的统计分析中主要分为以下几个部分进行统计分析:①描述研究人群的主要临床特征;②探讨血清ANGPTL8浓度与研究人群中其他指标之间的关系;③利用EHC方法对研究人群中循环ANGPTL8浓度与胰岛素抵抗的关系进行评估;④推测循环ANGPTL8浓度在评估MetS和IR中的预测价值。 统计方法的选择及重现 1. 统计软件及统计方法的选择 数据最终呈现形式采用均数±标准差( )或中位数(上、下四分位数)表示。数据分布形态采用Shapiro-Wilk检验;非正态分布数据采取自然对数转换或平方根转换;两组间比较采用两独立样本t检验,多组间比较采用单因素ANOVA分析;正态分布数据采用皮尔森(pearson)相关分析和多元线性回归分析判定指标间的关系,非正态分布数据采用Spearman相关分析;统计分析由SPSS 19.0软件处理。当双侧显著性水平P 0.05,表示这个数据符合正态分布。对于不符合正态分布的数据可以采用取自然对数转换或平方根转换为正态分布数据。 3. 一般资料的统计分析 收集2016-2017年就诊的241名青少年女性, 其中98名健康对照者和143名PCOS受试者,将PCOS患者按照是否合并MetS再分成PCOS合并MetS组及PCOS合并非MetS组,对这些患者的一般资料进行统计分析。对于具有方差同性的正态分布数据,可使用单因素方差分析进行三组间比较,而非正态分布数据则需采用非参数检验。本文中正态分布数据采用单因素方差分析,而非正态分布数据则采用非参数检验(图4)。 首先,我们展示使用SPSS 19.0进行非参数检验分析变量。导入三组样本,对样本数据进行正态性及方差齐性检验,非正态数据进行正态性转换。基础数据处理好之后,选择分析→非参数检验→独立样本(图5)。在SPSS的对话框中有三个小标签,目标(Objective)中选择自动比较不同组间的分布(Automatically compare distributions across groups),见图6。在字段(Fields)中选择“使用定制字段分配”(Use custom field assignments),将需分析的变量放入“检验字段”(Test Fields)框中,将需检测的分组变量“分组”放入组(Groups)中(图7)。在设置(Settings)中选择“自定义检验”(Customize tests),选择Kruskal-Wallis 1-way ANOVA(k samples)即Kruskal-Wallis单因素ANOVA(k样本),多重比较中可以选择“所有成对比较”(All pairwise),最后点击“运行”(Run)按钮(图8)。非参数检验的结果如图9所示,独立样本Kruskal-Wallis检验的显著性水平大于或等于0.05则组间比较无差异性,显著性水平小于0.05则组间比较有统计学差异。 然后,我们再展示使用SPSS 19.0进行单因素方差分析变量。“选择分析→比较均值→单因素ANOVA”即单因素方差分析(图10)。将需分析的变量放入“因变量列表”(Test Fields)框中(图11),点击“两两比较”选择项,在“假定方差齐性”选项中选择“LSD”法即最小显著差法(Least Significance Difference Method),在“未假定方差齐性”选项中选择“Tamhane’s T2”,再点击“继续”按钮(图12)。接下来点击“选项”按钮,在“统计量”选项中选择“描述性”、“方差同质性检验”,在“缺失值”选项中选择“按分析顺序排除个案”,点击“继续”按钮(图13)。单因素方差分析的结果如图14所示,在“描述”结果框中我们可以看到不同组别中各变量的均值、标准差,在“方差齐性检验”结果框中,我们可以看到方差齐性检验的结果,在“ANOVA”结果框中,我们可以看到方差检验的F值以及显著性水平值,显著性水平大于或等于0.05则组间比较无差异性,显著性水平小于0.05则组间比较有统计学差异。在“多重比较”结果框中,我们可以看到组间两两比较的结果(图15),显著性水平大于或等于0.05则组内两组比较无差异性,显著性水平小于0.05则组内两组比较有统计学差异。
图4. 患者的一般资料比较
图5. 患者一般资料的非参数检验
图6. 非参数检验的“目标”选项
图7. 非参数检验的“字段”选项
图8. 非参数检验的“设置”选项
图9. 非参数检验的结果解读
图10. 患者一般资料的单因素方差分析
图11. 单因素方差分析的变量选择
图12. 单因素方差分析的“两两比较”
图13. 单因素方差分析的“选项”
图14. 单因素方差分析的结果解读
图15. 单因素方差分析的“多重比较”结果解读 4. 血清ANGPTL8浓度与其他指标之间的相关分析 本文中的相关分析主要描述PCOS人群中血清ANGPTL8浓度与其他指标是否存在相关关系。两个变量之间的相关性可以采用Pearson或Spearman相关分析方法进行分析。Pearson相关分析主要用来分析正态分布、非等间距测度的连续变量,而Spearman可用来分析不服从双变量正态分布或总体分布型未知以及原始数据是等级资料的数据。本文中因部分数据无法转换成正态分布数据,故选择使用Spearman相关分析方法对血清ANGPTL8浓度与其他指标之间的关系进行分析(图16)。 下面我们展示使用SPSS 19.0进行Spearman相关分析的实现过程。首先,使用PCOS人群数据作为分析数据集,导入SPSS软件,数据整理完成后选择“分析→相关→双变量”(图17)。在SPSS弹出对话框中,将需要进行相关性分析的变量拖入到“变量”列表框中,勾选相关系数为“Spearman”,显著性检验“双侧检验”和“标记显著性相关”,最后点击“确定”按钮(图18)。Spearman相关分析的结果如图19所示,相关系数则是两变量之间的相关系数,该值为正数表示成正相关,反之则为负相关。显著性水平≥0.05则表示两变量之间的相关性无统计学差异性,显著性水平 |

【本文地址】
今日新闻 |
推荐新闻 |