STATA回归分析结果解读 |
您所在的位置:网站首页 › 回归系数读法 › STATA回归分析结果解读 |
STATA回归分析结果解读
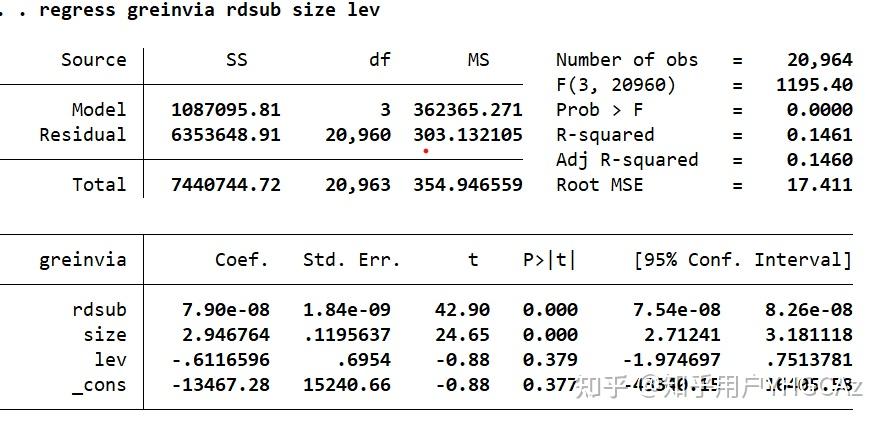 上图为基本线性回归的结果图,具体解释如下: 1.方差分析 Number of obs 为样本观测值数量,共20964条数据观测值, F(3,20960)=MSR/MSE,显示的为F检验-方差检验结果,为整个模型的全局检验,来表明拟合方程是否有意义,其中,3是回归自由度,20960是残差自由度 Prob>F 表示的是F检验的显著性 R-squared=SSR/SST 为相关系数R的平方,值在0-1之间,表示模型的拟合优度,越大说明模型预测越准确 Adj R-squared 表示的为调整后的拟合优度,因为R2会随着变量的变化而变化,但拟合优度不会随其改变,所以需要进行调整来正确衡量模型的拟合优度。 Root MSE指的是残差标准差=根号下MSE  SS指的是误差平方和 其中,model行对应的是模型可以解释的偏差,又称回归平方和SSR,为预测值对平均值的总偏差,回归自由度dfr=3,为解释变量数目,MS对应的为均方差MSR,即平方和除以其自由度 Resuidual行指的是模型不可以解释的偏差,即残差平方和SSE,为实际值对预测值的总偏差,残差自由度dfe=20964-3-1=样本数目-自变量数目-1,MSE为SSE/dfe TOTAL行对应的是总偏差,即SST离差平方和 2.系数分析 下方表格中左列指的是变量名,greniva为被解释变量-绿色发明专利申请量,rdsub为核心解释变量-政府研发补助,size-企业规模与lev-资产负债率为控制变量,_cons为常数项 Coef指的是模型预测的各对应变量的系数值,Std.Err.指的是标准误,t值=Coef. / Std. Err.,P值:指比t值更极端结果发生的概率,如果P值过小,小于0.1,即小于小概率事件发生的概率,则拒绝原假设,选择备择假设。[95% Conf,Interval]指的是预测系数的95%置信区间=预测系数+-1.96*标准误 3.标准误、t值、p值及置信区间之间的关系? 对于估计系数的正确性,需要进行有关考量。假设检验,原假设一般是假定系数值为0,或某一常数,在假设成立的情况下,如果有小概率事件发生,则说明原假设不成立,拒绝原假设,备择假设成立,即与原假设相反的假设 对于检验统计量的选取,有以下两个原则:1.该检验统计量可由样本观测值计算出 2.其概率分布已知,从而可以便于分辨抽样结果为小概率事件还是大概率事件 根据已有研究对扰动项的分析,可以得出如果把扰动项看作为遗漏变量与测量误差之和,由中心极限定理得其近似服从正态分布,对其近似标准化处理可得t值,且第k个变量的t值近似服从t分布,且其值可由观测值得到,初步预定其越小,越符合原假设,越大,越倾向于拒绝原假设 t检验: 1.计算t值 2.计算显著性水平为a的临界值-其中显著性水平是指当原假设为正确时人们却把它拒绝了的概率或风险--弃真概率。它是公认的小概率事件的概率值,必须在每一次统计检验之前确定,通常取α=0.05或α=0.01。根据已知t分布及小概率事件的概率值算出t值的临界值 3.判定tk落于拒绝域还是接受域。如果tk观测值落于临界值区间-也称接受域内,说明接受原假设,若落于临界值外-拒绝域,则拒绝原假设,说明假设成立情况下,抽样所得结论落在了小概率事件上,原假设不成立,备择假设成立---通常是通过利用小概率原理反证法即拒绝原假设来验证某一假设--备择假设的正确性。 P值检验: P值是指当原假设为真时,比所得到的样本观察结果更极端的结果出现的概率。如果P值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设,P值越小,我们拒绝原假设的理由越充分 P18 陈强高级计量经济学 以下引用自【214】回归模型的总体显著性检验:t检验 - 知乎 (zhihu.com)该文具体目录:1.t检验的原理 2.t检验的具体步骤 3.t检验与F检验的异同4. t 检验与 F 检验间的关系在一元情形下, F 检验与 t 检验是一致的在一元线性回归模型中,由于解释变量只有一个,不存在解释变量联合影响的整体检验问题,也就不需要进行 F 检验。事实上,在一元情形下, F 检验与 t 检验是一致的,它们之间存在如下关系: \begin{aligned} F&=\frac{SSE/1}{SSR/(n-2)}=\frac{\sum(\hat y_{t}-\bar{y})^{2}}{\sum e_{t}^{2}/(n-2)}=\frac{\sum[(\hat b_{0}+\hat b_{1}x_{t})-(\hat b_{0}+\hat b_{1}\bar{x})]^{2}}{\sum e_{t}^{2}/(n-2)}\\ &=\frac{\sum \hat b_{1}^{2}(x_{t}-\bar{x})^{2}}{\sum e_{t}^{2}/(n-2)}=\frac{\hat b_{1}^{2}\sum (x_{t}-\bar{x})^{2}}{\sum e_{t}^{2}/(n-2)}=\frac{\hat b_{1}^{2}\sum (x_{t}-\bar{x})^{2}}{\hat \sigma^{2}}=\left[\frac{\hat b_{j}}{s(\hat b_{j})}\right]^{2}=t^{2} \end{aligned} F=t^{2}\ (3.2.15) 即 F 统计量等于 t 统计量的平方。给定显著性水平 \alpha ,查 F_{\alpha}(1,n-2) 与 t_{\alpha/2}(n-2) ,临界值之间也存在这种平方关系。也就是说,在一元情况下,对参数 b_1 的显著性检验( t 检验)与对回归模型总体显著性检验( F 检验)是等价的。 在多元线性回归模型中, F 检验与 t 检验是不同的。(1)检验对象不同: t 检验为 H_{0}:b_{j}=0,\ H_{1}:b_{j}\neq 0(j=1,2,\cdots,k) ; F 检验为 H_{0}:b_{1}=b_{2}=\cdots=b_{k}=0,\ H_{1}:b_{j}(j=1,2,\cdots,k)不全为零 。 (2)当对参数 b_{1},b_{2},\cdots,b_{k} 检验显著时, F 检验一定是显著的。F检验显著即P值小于0.1,H1假设成立 (3)但当 F 检验显著时,并不意味着对每一个回归系数的 t 检验一定都是显著的。 【提示】倘若某个解释变量对因变量的影响不显著,则应在模型中剔除该解释变量,重新建立多元线性回归模型。 |
【本文地址】