用最小二乘法OLS做回归,并解读结果 |
您所在的位置:网站首页 › 回归方程中常数项的含义 › 用最小二乘法OLS做回归,并解读结果 |
用最小二乘法OLS做回归,并解读结果
|
使用OLS做回归
#使用OLS做多元线性回归拟合
from sklearn import linear_model,cross_validation, feature_selection,preprocessing
import statsmodels.formula.api as sm
from statsmodels.tools.eval_measures import mse
from statsmodels.tools.tools import add_constant
from sklearn.metrics import mean_squared_error
X = b_data.values.copy()
X_train, X_valid, y_train, y_valid =
cross_validation.train_test_split( X[:, :-1], X[:, -1],train_size=0.80)
result = sm.OLS( y_train, add_constant(X_train) ).fit()
result.summary()
https://www.datarobot.com/blog/ordinary-least-squares-in-python/ 解读summary结果
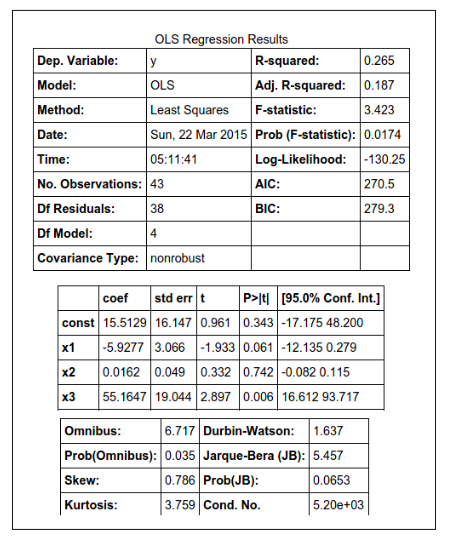
summary结果中提供了很多关于拟合的信息,下面是这些描述信息的含义: 第一个表左边部分是关于拟合的基本信息: ElementDescription中文描述(个人翻译,如有错误请留言指出)Dep. VariableWhich variable is the response in the model响应变量/独立变量 y ModelWhat model you are using in the fit用来做拟合的模型MethodHow the parameters of the model were calculated模型参数的计算方法No. ObservationsThe number of observations (examples)观察样本个数DF ResidualsDegrees of freedom of the residuals. Number of observations – number of parameters残差自由度 = 样本数-模型参数个数DF ModelNumber of parameters in the model (not including the constant term if present)模型自由度 = 模型参数个数(不包括常数项)第一个表的右边部分显示的是拟合的好坏情况: ElementDescription中文描述(个人翻译,如有错误请留言指出)R-squaredThe coefficient of determination. A statistical measure of how well the regression line approximates the real data pointsR决定系数,描述回归曲线对真实数据点拟合程度的统计量,取值[0,1]之间,越接近于1 越好Adj. R-squaredThe above value adjusted based on the number of observations and the degrees-of-freedom of the residuals调整R决定系数,是R决定系数加上了残差自由度后的重新计算的结果,通过比R小。 计算公式: F统计值是对总体线性的显著性假设检验值,衡量拟合的重要性。 计算公式: 第二个表显示的是拟合系数信息: ElementDescription中文描述(个人翻译,如有错误请留言指出)coefThe estimated value of the coefficient模型系数估计值std errThe basic standard error of the estimate of the coefficient. More sophisticated errors are also available.系数的标准差tThe t-statistic value. This is a measure of how statistically significant the coefficient is.t统计量,衡量系数的统计显著性P > |t|P-value that the null-hypothesis that the coefficient = 0 is true. If it is less than the confidence level, often 0.05, it indicates that there is a statistically significant relationship between the term and the response.P值,显示统计量和响应变量间是否具有显著线性相关性。[95.0% Conf. Interval]The lower and upper values of the 95% confidence interval 95%置信区间的上下边界值 最后一个表显示的是对残差分布的统计检验评估: ElementDescription中文描述(个人翻译,如有错误请留言指出)SkewnessA measure of the symmetry of the data about the mean. Normally-distributed errors should be symmetrically distributed about the mean (equal amounts above and below the line).偏度系数,描述数据关于均值的对称情况。KurtosisA measure of the shape of the distribution. Compares the amount of data close to the mean with those far away from the mean (in the tails).峰度系数,通过比较接近平均值的数据量 和远离平均值的数据量来 描述数据分布形状的度量值。OmnibusD’Angostino’s test. It provides a combined statistical test for the presence of skewness and kurtosis.对偏度和峰度进行组合统计检验的一个概括值 Prob(Omnibus)The above statistic turned into a probability把上面的统计值变成概率值Jarque-BeraA different test of the skewness and kurtosis另一个检验偏度和峰度的统计测试Prob (JB)The above statistic turned into a probability把上面的统计值变成概率值Durbin-WatsonA test for the presence of autocorrelation (that the errors are not independent.) Often important in time-series analysis对自相关性的假设检验。通常在时间序列分析中很重要。Cond. NoA test for multicollinearity (if in a fit with multiple parameters, the parameters are related with each other).多重共线性的假设检验 |
【本文地址】
今日新闻 |
推荐新闻 |