基于热门旅游景点数据的爬取 |
您所在的位置:网站首页 › 四川旅游景点名称 › 基于热门旅游景点数据的爬取 |
基于热门旅游景点数据的爬取
|
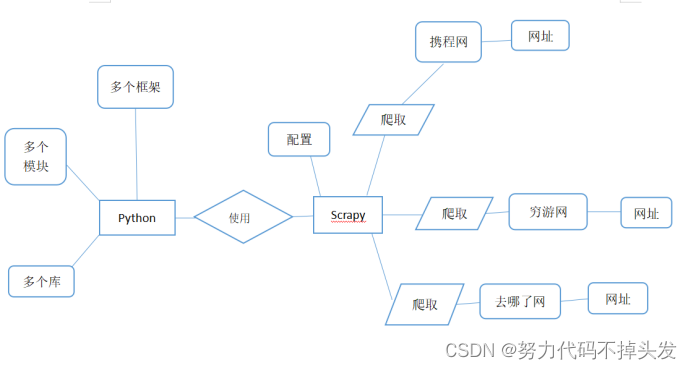
一、需求分析 1.至少 3 个及以上的旅游网站数据; 我找的网站是: (1)www.qyer.com (穷游网站) (2)hotels.ctrip.com (携程网站) (3)www.qunar.com (去哪了网站) 2.爬取数据应包括字段:景点名称、景点星级、景点热度、景点地址、景点价格、景点简介、景点详情、用户评论(用户名称,评论,时间)等。 3.每个网站采集数据 2000 条以上(一个景点为一条数据);每个网站基本含有200千以上的旅游景点。 4.对脏数据进行清洗和并实现数据库存储。 数据的清洗与整理:(1)统一数据格式;(2)缺失值处理;(3)数据的合并与去重;(5)处理异常值。 将清洗的后的数据实现数据库储存。 5.确定热门旅游景点分析目标,完成 3 个以上可视化图表: 所有数据弄完之后,按需求分析数据,做出可视化图表。 二、爬虫设计与实现 我采用了Scrapy框架对热门旅游景点进行爬取,我选择这个爬虫框架的原因是它有以下优点: 1.采用可读性更强的xpath代替正则表达式,速度更快。 2.Scrapy是异步的,可以灵活调节并发量。 3.写 middleware,方便写一些统一的过滤器。 4.可以同时在不同的url上爬行。 5.支持shell方式,方便独立调试。 6.通过管道的方式存入数据库,灵活,可保存为多种形式。 有利就有弊,它的弊端就是: 1.自身去重效果差,消耗内存,且不能持久化 2.对于需要执行js才能获取数据的网页,爱莫能助 3.兼容了下载图片与视频,但是可用性比较差 4.无法用它完成分布式爬取 5.基于 twisted 框架,运行中的 exception 是不会干掉 reactor(反应器),并且异步框架出错后 是不会停掉其他任务的,数据出错后难以察觉,预警系统简单的使用邮件,很不友好。 所以我们可以根据Scrapy的功能来绘制E-R图,如下:
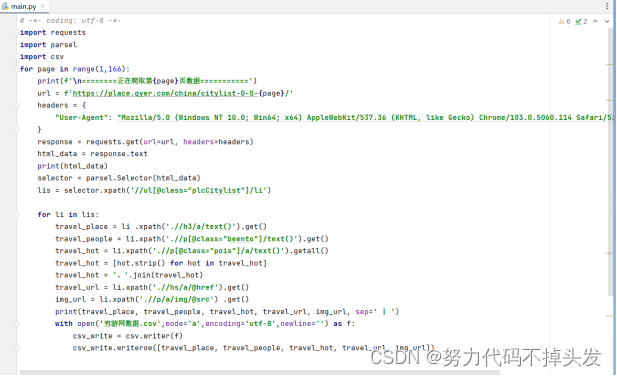
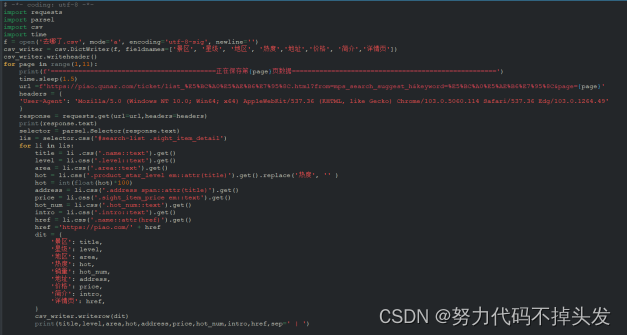
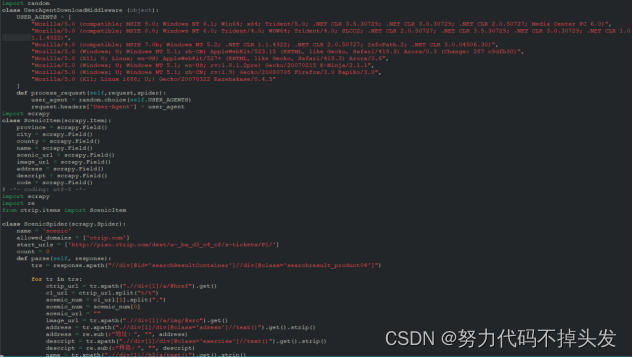
除了scarpy框架,我还运用了parsel第三方库。它是由scrapy团队开发,是将scrapy中的parsel独立抽取出来的,可以轻松解析html,xml内容,获取需要的数据。相比于BeautifulSoup,xpath,parsel效率更高,使用更简单。 Python网络爬虫领域两个最新的比较火的工具莫过于httpx和parsel了。httpx号称下一代的新一代的网络请求库,不仅支持requests库的所有操作,还能发送异步请求,为编写异步爬虫提供了便利。parsel最初集成在著名Python爬虫框架Scrapy中,后独立出来成立一个单独的模块,支持XPath选择器, CSS选择器和正则表达式等多种解析提取方式, 据说相比于BeautifulSoup,parsel的解析效率更高。parsel最大的特点就是支持三大功能:css()、xpath()、re.()。这次我们同样采用requests获取目标网页内容,使用parsel库(事先需通过pip安装)来解析。Parsel库的用法和BeautifulSoup相似,都是先创建实例,然后使用各种选择器提取DOM元素和数据,但语法上稍有不同。Beautiful有自己的语法规则,而Parsel库支持标准的css选择器和xpath选择器, 通过get方法或getall方法获取文本或属性值,使用起来更方便。 代码如下: 1.爬取穷游网站的代码:
2.爬取去哪了网站的代码: 3.爬取携程网站的代码:
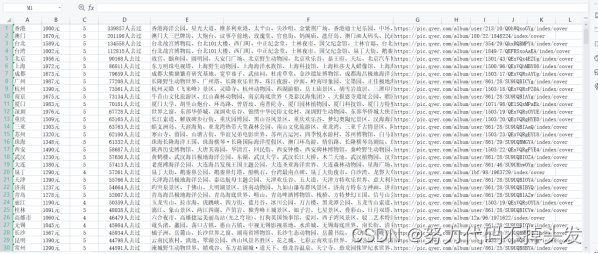
每个代码都能爬取3000条左右的数据。 三、数据预处理 最基础的预处理方法有: #1、加载csv数据 import pandas as pd df_csv=pd.read_csv('C:\Users\DELL\Desktop\淘宝.csv') df_csv.head() #2、察看空值 判断是否有缺失值 data.isnull().any(axis=0) data.isnull().any(axis=1) #处理空值 data3=data.dropna() data3 #定义缺失值为0 data_null_0=data.fillna(0,inplace=False) data_null_0 #对缺失值进行填充 data_null_value=data.fillan(value={'Hoesepower':data['Hoesepower'.mode()[0]], Miles_per_Gallon':data[Miles_per_Gallon],mean()}, inplace_False) data_null_value #3、处理重复值 #判断是否存在重复值 data_du.duplicated().any #删除重复值 data_du.drop_duplicates() #4、数据标准化 X=data['Horsepower'] import numpy as np我的思路: 得到三个不同网站爬到的数据,首先是把它们合并到一起。 在观察爬到的数据,发现有许多的空值而且数据量较大,所以我用到了最简单的直接删除法: df1 = df.dropna()删除后,重置索引: df.index = range(df.shape[0])然后再删除重复值: df[df.duplicated()] np.sum(df.duplicated()) df.drop_duplicates() df.drop_duplicates(subset=['appname','size'],inplace=True)删除后的数据如下:
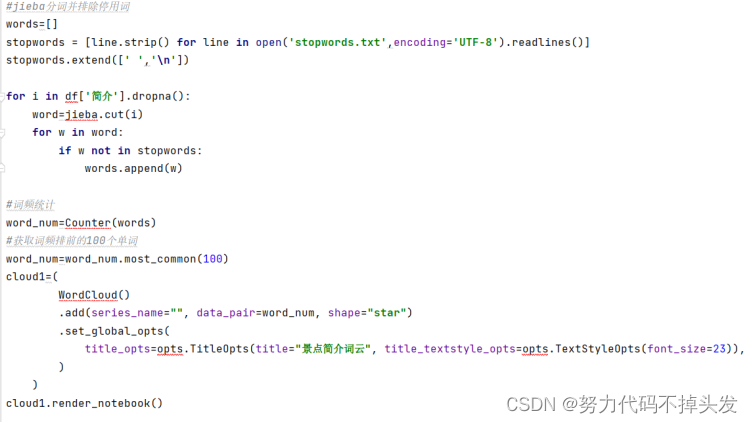
四、数据可视化 数据可视化是指借助于图形化手段,清晰有效地传达与沟通信息,使用户能够快速地识别模式,交互式可视化能够让决策者对细节有更深层的了解。数据可视化与信息图形、信息可视化、科学可视化和统计图形密切相关,数据可视化实现了成熟的科学可视化领域和信息可视化领域的统一。 景点简介词云:
五、总结 ......... (有求必应) |
【本文地址】