一类强有效的一致预期衍生指标!【天风金工因子选股系列之十一】 |
您所在的位置:网站首页 › 四十十八除以三 › 一类强有效的一致预期衍生指标!【天风金工因子选股系列之十一】 |
一类强有效的一致预期衍生指标!【天风金工因子选股系列之十一】
|
缺失值填充 一致预期指标由于分析师覆盖度原因,存在一定缺失值。以往多因子模型一般以指标行业中位数或均值直接填充缺失值,但更合理的做法应是基于因子的投资逻辑为其量身定做一套缺失数据填补机制。 我们以预期净利润缺失企业前一年在行业内的利润增速分位点均值作为其当年在该行业增速分位点的估计值。通过估计增速分位点,我可以估计当年预期增速,最终得到一致预期净利润的填补值。该方法填充预期净利润缺失数据更符合逻辑,且最终绩效相对传统方法也略有提升。
正文 综合不同分析师对于上市公司未来经营情况的预期,我们可以得到分析师对于该公司的一致预期指标。一致预期代表了分析师对于一家公司未来经营情况的综合评价,其中暗含了企业未来的盈利信息,是选股时需要考虑的重要指标。朝阳永续作为股票预期数据供应商,其数据对A股有较为全面的覆盖,同时朝阳永续也提供了加工而得的一致预期数据,但考虑到算法的透明性,我们习惯于基于基础数据自己加工一致预期指标。本文以朝阳永续所收录的分析师预期数据为基础,提供了一致预期指标的加工新思路,并分析挖掘了其中蕴含的alpha信息。 1 分析师预期 煮一盘好菜最重要的是用好原材料,同理alpha模型的关键在于其特征工程,一个优秀的alpha模型中应有丰富而独立的alpha来源。传统上alpha模型的收益来源于价量类技术指标以及企业估值、盈利、成长等基本面指标,而分析师对于企业未来盈利的估计与这些指标一般有着相对较高的独立性。因此分析师预期指标应是已有模型中增量收益的重要来源之一。 一般数据供应商均会提供基于不同分析师预期综合而成的分析师一致预期指标,但其中存在算法透明性和拓展性问题。在我们不了解算法具体细节时,如果需要根据自身的需求对指标进行拓展可能存在不便之处。 因此,我们希望利用最原始的分析师预期数据加工分析师一致预期指标。本文利用朝阳永续所收集、录入的分析师预期数据,尝试不同的方法加工分析师一致预期指标,并分析各指标的选股效果。 2 朝阳永续数据 2.1 分析师报告数据 朝阳永续数据库中分析师报告相关数据主要报告两大类。其一是其收录的分析师报告数据,包含报告中分析师对于上市公司的预期营业收入、预期净利润等数据,相配套的还有报告对应的发布机构、分析师等数据。其二是其基于基础数据自己加工的分析师一致预期数据,包括股票以及指数一致预期净利润、一致预期PE,EPS等指标以及对应指标的滚动预测值。 朝阳永续中的分析师预期数据除了包含个股报告中的预期数据外,还包含行业、策略等报告中的股票预期数据。本文基于个股报告中的预期数据分析一致预期净利润及其相应的衍生指标。 在朝阳永续数据库中剔除简评文章以及港股报告后,主要还有以下关于股票预期的报告类别。其中部分数据如港股等报告,本文在数据预处理时剔除这部分报告。
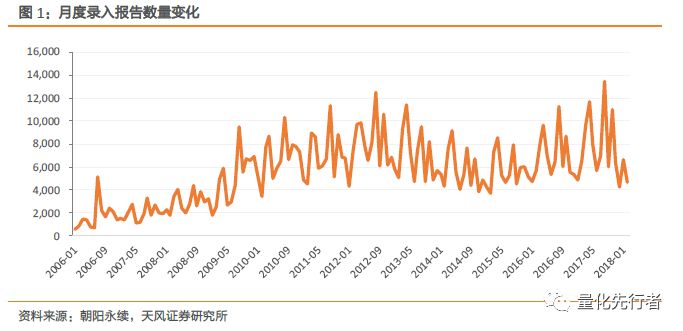
从2007年起朝阳永续数据库每月录入个股预期数据下图所示,可以发现其录入报告数量逐步上升,且数量随月份呈现出周期性变化。
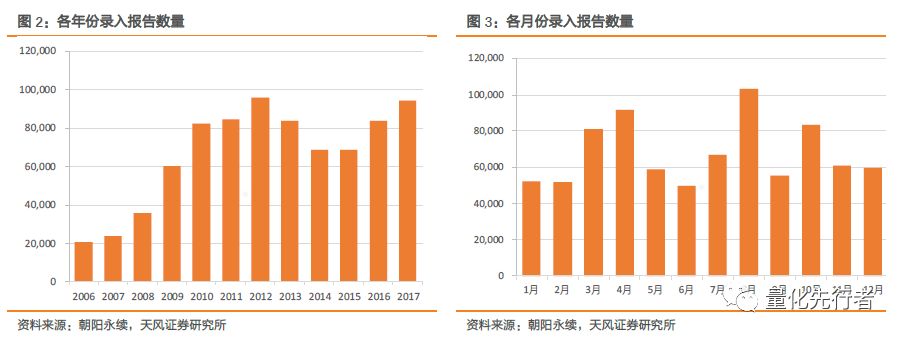
如图2,朝阳永续各年份收录报告数量上升明显,从2006年的2万多篇,到2017年达到将近10万篇。其年收录报告数量除了在13、14、15年出现下降外,其余时间均在缓步上升。 此外,图3是从2006年1月至2017年12月朝阳永续在各月份录入股票报告数量的总和展示图。在四个财报发布月份3月、4月、8月和10月,录入股票报告数量显著多于其他月份,可能的原因是分析师一般会在企业季度财务报告发布之后及时更新其对于企业的盈利预期。
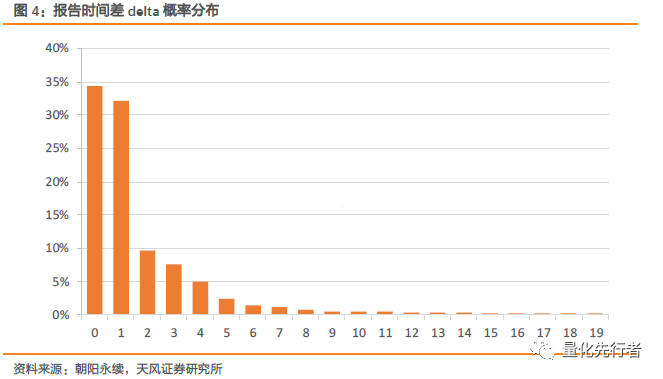
2.2 报告撰写、录入的时间差 报告撰写发布时间(CREATE_DATE)和数据商收录报告时间(INTO_DATE)一般存在着一个时间差(delta),由于我们需要通过数据商获取报告数据,因此我们获取信息的及时性取决于数据商收录报告的及时性。 delta = INTO_DATE - CREATE_DATE 2006年至今,朝阳永续数据库中报告撰写、录入时间时间差概率分布图如下所示,约有76%的报告在撰写完两天内被录入。但仍有少量的报告从撰写完成到录入进库之间有差较长的时间差,但我们发现整体上撰写、录入时间差随着时间在逐步缩小。
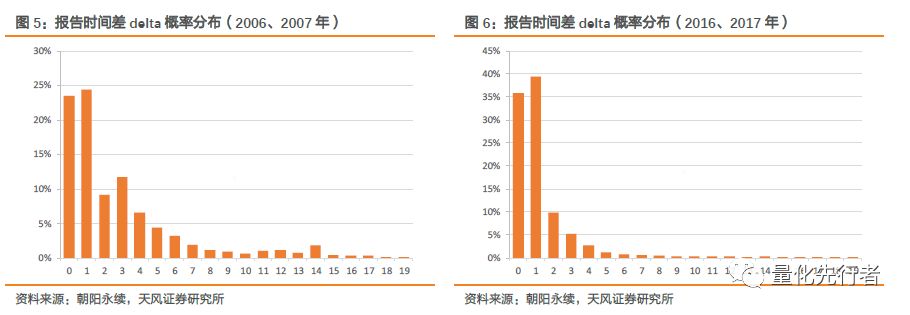
以下左图为2006年、2007年这早期两年数据商报告录入时间和报告实际撰写时间的时间差,在报告撰写发布两天内数据商录入报告的比例为56.9%。右图为2016、2017两年报告录入与撰写时间差,报告发布两天内录入比例为84.8%。可以看出,随着技术水平提高,信息获取效率在提高,数据商收录报告的及时性有显著提升。尽管数据收集的时效性在提高,但报告撰写与录入时间之间仍然存在着一个时间差,这是我们在数据处理时应该关注到的一个问题。
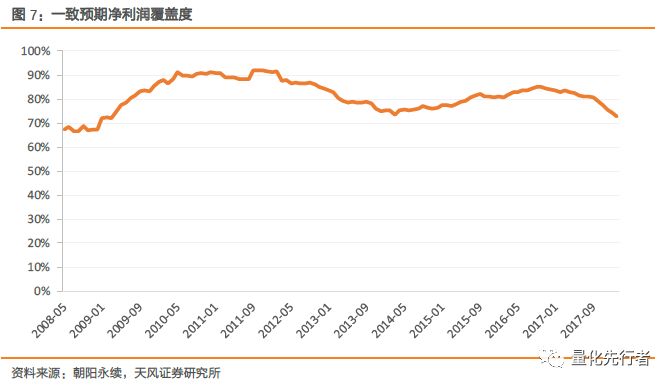
2.3 股票覆盖度 我们在全市场股票中剔除上市不满60个交易日、被ST处理与ST摘帽不满60个交易日的所有股票作为样本池,并计算样本池中分析师预测数据的覆盖度。在t月末,若t月以前6个月内存在分析师净利润预测数据,我们则记该股票为被覆盖。 朝阳永续数据库中净利润指标股票覆盖度从2008年至2010年出现明显提高,在2010年初达到峰值,但随后出现一定下滑,一致预期净利润指标覆盖在2014年达到低点,但仍有75%以上的覆盖度。从2008年初至2018年2月平均覆盖度达到80%以上,总体而言数据库对于分析师预测数据有着较全面的覆盖。
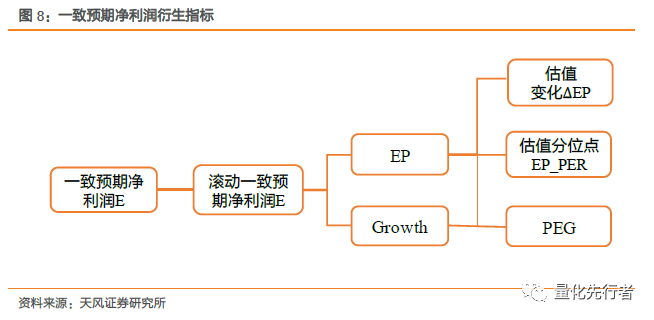
3 净利润预测偏离度及其影响因素 出于算法透明性、数据指标可靠性等考虑,我们希望能独立加工分析师一致预期指标。传统的分析师一致预期指标主要有一致预期估值EP、一致预期净利润增长率和一致预期PEG。其中的核心在于对企业净利润的估计,以一致预期净利润E除以市值可得到一致预期估值EP;以E与前期净利润求增长率可得到一致预期增速;以一致预期估值EP和一致预期增速G进而得到一致预期PEG。因此一致预期指标构建的成败主要取决于一致预期净利润的估计,本章将围绕一致预期净利润的估计展开。
一致预期指标的核心在于对企业净利润的估计,我们以分析师净利润预测值相对报告期净利润实际值的绝对偏差占绝对值的比例衡量预测数据的预测偏离度。
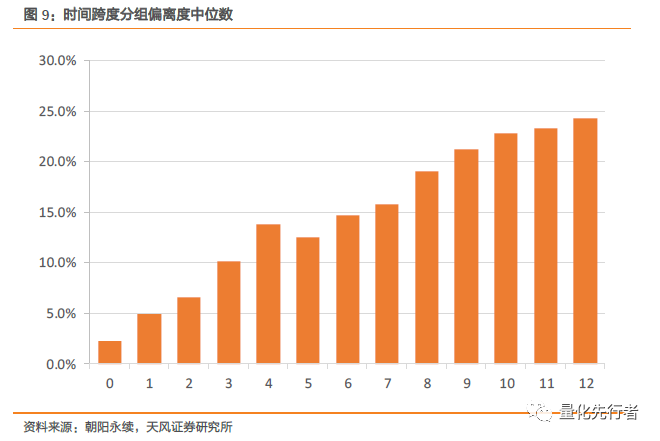
如上式,Profit_Forcast为分析师预测净利润值,Profit_Real为企业报告期实际净利润。我们以bias衡量预测数据的预测误差,但是偏离度bias受到预测时间跨度、预测企业规模大小及其企业所属行业等因素的影响。直观上,若分析师站在越远的时间做出预测,则预测的偏离度将越大;同时规模越大的企业,其营收与利润一般都相对较为稳定,因此分析师对于净利润的预测也相对更为准确;而不同行业由于其经营业务的差异,受到宏观经济周期的影响也不同,分析师预测的精确性上也存在着差异。以下我们以预测年份为2016年年报的所有预测数据为例,展示偏离度与这些因素的相关性。 3.1 时间跨度对于预测偏离度的影响 首先,对于偏离度影响最重要的因素应该是预测日期到年报实际公告日期之间的跨度。距离年报越近,分析师的预测准确性便越高。逻辑是显然的,若在企业已经公布其三季报之后再预测其年报净利润,相当于仅需要预测企业的第四季度净利润值,这比在年初便做出判断要有着更高的精确度。
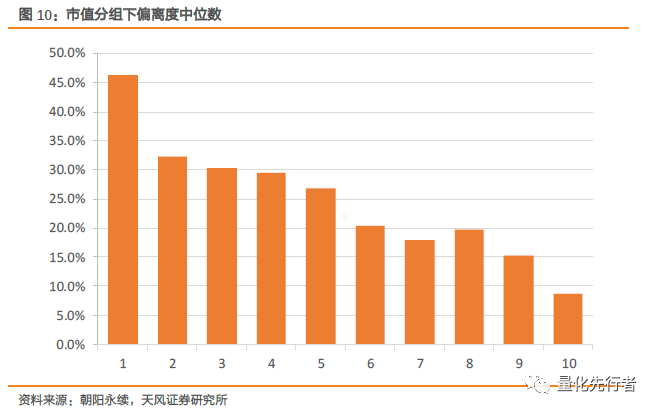
我们将预测数据按照其时间跨度δ分组并计算每组内偏离度的中位数,结果如上图所示,时间跨度δ是影响偏离度大小最重要的因素。预测时间跨度越大,平均预测误差就越大,且二者表现出显著的单调性。其原因是由于分析师会根据市场上信息以及调研数据等不断更新修正其预测,越临近年报时发布的预测数据准确度便越高。因此,一致预期计算中,报告发布时间上的差异是需要考虑的至关重要因素,通常越新的报告所涵盖的信息便越精确。 3.2 企业规模对于预测偏离度的影响 其次,预测企业的规模差异也是影响预测偏离度的重要因素。我们将预测数据按预测企业的市值大小分组,计算每组预测净利润与实际净利润之间偏离度的中位数,最终结果如下图所示。
企业规模与预测偏离度大小表现出明显的单调性。预测企业市值越大,分析师对于其预测的偏离度倾向于减小。而规模较小的企业由于其营收、利润等波动较大,分析师一般很难精确地预测其净利润的大小。 3.3 企业所属行业对于预测偏离度的影响 此外,预测偏离度在行业之间也表现出明显的差异。我们将预测数据按照其所属企业的中信一级行业类别分组,计算每组偏离度的中位数。如下图所示,偏离度在行业之间呈现出显著的差异,不同行业由于其所受关注度以及经营业务上的差异,分析师对于其预测结果的精确度也呈现出高低起伏的波动。钢铁、煤炭、有色等周期性行业由于受到宏观经济的影响,其不可预测性也更大,因此呈现出较大的预测偏离度;而银行、食品饮料等营收较为稳定的行业,分析师更容易做出较为精确的判断。
4 一致预期净利润加权 前面我们讨论了影响预测偏离度的相关因素,基于基础数据加权一致预期净利润时,我们希望预测值能越精确,也即预测偏离度能尽量小。在本章,我们将讨论如何基于基础数据进行一致预期净利润的加权。 4.1 有效报告 由于分析师预测数据的时效性考虑,计算一致预期净利润Profit_FY1时,我们定义最近3个月内撰写且录入的报告为有效报告,只使用这部分报告的预测数据计算一致预期;当最近3个月都不存在有效报告时,我们定义最近6个月撰写录入的报告为有效报告,使用相应的预测数据计算一致预期。相应的,计算Profit_FY2时,我们按照相同方法筛选有效报告,并根据报告对相应预测年度计算一致预期。此外,若6个月内均没有分析师覆盖,由于更早的数据可信度的太低,我们将一致预期净利润作缺失值处理。
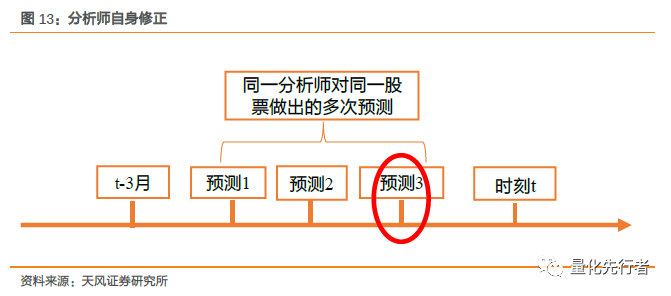
按照以上方法定义有效报告的原因有二:首先,报告撰写时间离预测日过远时,报告时效性太低,参考意义不大;其次,考虑报告录入的时效性,如果录入时间在预测日之后,那么在实际使用中将无法获取这部分报告。因此我们按照这种方法定义有效报告,兼顾报告预测数据的质量和数据的可获取性,它们是回测时有效且可获取的信息 4.2 分析师对自身预测的修正 同一个分析师可能会不断修正其对于同一只股票的预测值,因此在有效报告中可能出现同一个分析师的多次预测,对于此种情况在加权时我们仅保留该分析师最新的预测数据。
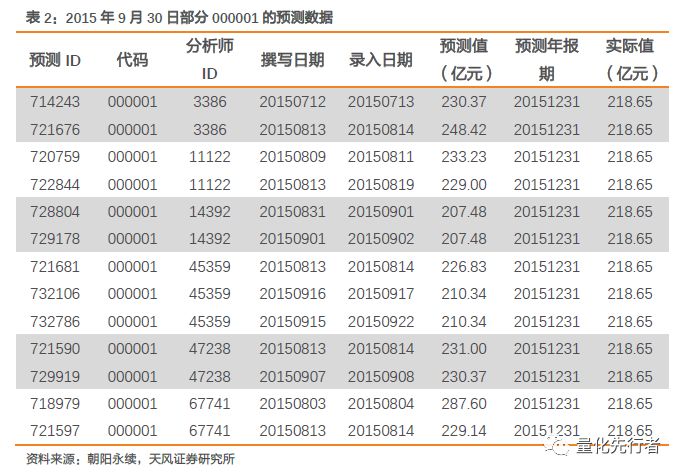
我们以2015年9月30日000001.SZ往前3个月的有效预测数据为例,其中有多个分析师不止一次对于该企业净利润做出预测,而同一分析师最新的净利润预测值是分析师对于自身预测的修正,其可信度更高。因此存在同个分析师的多次预测时,我们仅保留其最新的预测数据。
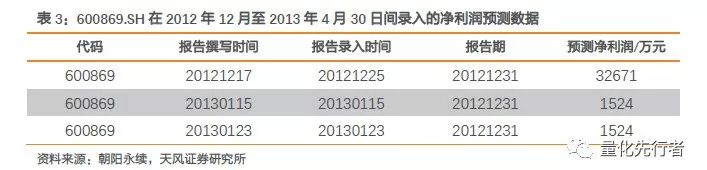
4.3 业绩预告及快报对一致预期的修正 企业可以通过业绩预告以及业绩快报两种方式预披露业绩。由于预告以及快报都是早于年报发布的,且业绩报告(快报或预报)中的数据直接来自于企业本身,其可信度应高于分析师的预期,因此,在存在业绩预告或者业绩快报信息时,优先使用企业的报告信息。 分析师反馈业绩报告信息需要时间(报告撰写、推送、录入等),且我们使用更早一段时间内的分析师预期以计算一致预期,因此分析师一致预期往往很难及时反馈企业业绩报告中的信息。在存在企业业绩报告,且在当前时点能获取这部分报告信息时,我们优先使用企业业绩报告能增加预测精确。其中,业绩快报中会给出企业报告期经营情况的具体数据;而业绩预告一般会给出年报净利润预期上下限,此时我们取预测上下限均值作为净利润的一致预期。 举例而言,600869.SH在2013年1月30日公布2012年年度业绩预告,预计2012年度归属上市公司股东净利润在-10000万元至-12000万元之间,因此我们在2013年2月28日以及之后取均值-11000万元作为2012年度净利润真实值的预测值。而若采用分析师预期数据,我们在2013年2月28日取最近三个月的分析师预期数据,如下表所示,简单平均值计算为11900万元。而其在2013年4月26公布的2012年度报告显示,其在2012年间净利润值为-14212万元。该结果与预告信息基本吻合,而和分析师预期值却相去甚远。显然,由于分析师预期的滞后效应,分析师一致预期对于公司业绩报告反应不够及时,在存在业绩报告时我们优先使用业绩报告作为企业净利润的预测更为合理。
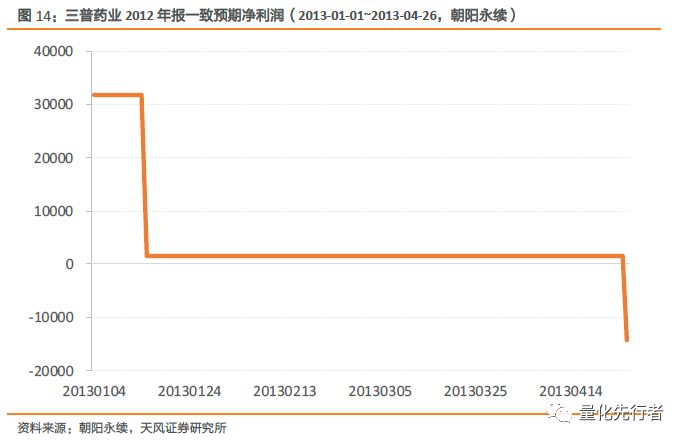
业绩报告修改的样本点有限,因此从整体上我们很难看出添加企业业绩报告增量信息能带来预测精确度上显著地提升。但观察通过业绩报告修正的点前后预测偏差的变化,我们可以发现业绩报告在局部上对于净利润一致预期精度的提高是明显的。而对比朝阳永续数据库中加工的一致预期,我们发现其在2013年1月15日沿用了最近一篇报告所使用的预测数据(1524万元)作为一致预期,但其与真实值却相差甚远,直到2013年4月26日,三普药业公布其实际年报净利润亏损额度时,朝阳永续才将它的一致预期更正为年报净利润值-14212万元。
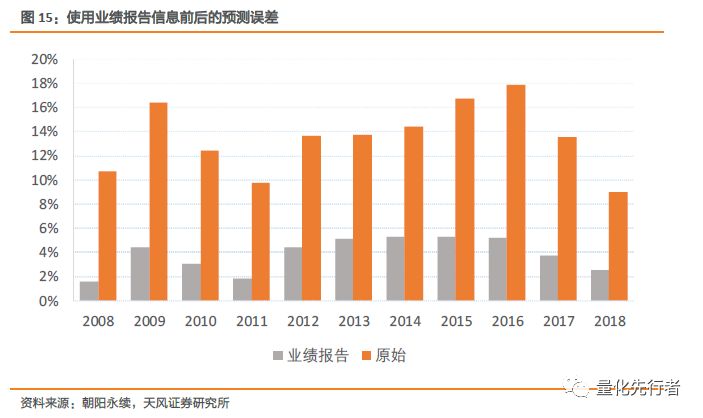
由上分析,存在业绩报告时我们优先使用业绩报告数据作为一致预期值,可以提高我们的预测精度。但由于业绩报告数量有限,这部分修正值约占所有一致预期值总数的15%左右。我们仅对比这部分一致预期值在修改前后的偏差表现。如下图所示,我们给出了使用业绩报告作为预测值和使用分析师预测简单平均作为预测值在这部分样本点上的偏离度变化。分别计算两者中位数作为其平均误差度量,我们发现相较于完全使用分析师预期,使用业绩报告时预测精确度在这部分修正一致预期样本点上有显著提高。
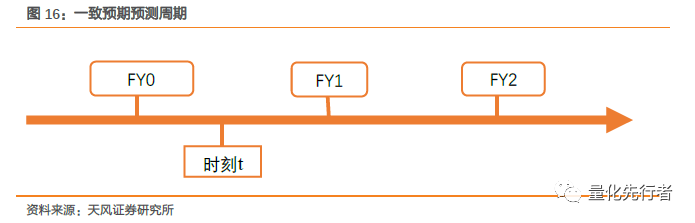
4.4 一致预期净利润在时间维度的加权 由前文预测偏离度与预测时间跨度分析可知,预测数据的时间跨度越小,其预测便越精确。直观上也是显然的,随着年报公告日的时间越近,企业季度财务报告的公布以及市场相关信息释放,分析师对于企业净利润的预期值就应该越精确。因此,计算分析师一致预期时应考虑报告录入时间的差异,给予新报告以更高的权重。同时,在当前时点t,相对时刻t过早前发布的报告由于信息的更新,其可信度已经非常低。为此计算一致预期时,我们不使用撰写、录入时间过早的分析师预测数据,我们按照前文所筛选出的有效报告作为基础数据集。 关于净利润的一致预期,我们主要预测的是年报的净利润,由于不同企业年报公告时间的差异,这使得我们在计算一致预期时需要先确定预测年度。有些人采用4月30作为年度的切换时间点,这种方法虽然简化了计算过程,但其中存在不合理之处,很多企业可能在4月份之前就已经公告其年报,因此对于该年度净利润的一致预期已经没有意义。
因此,我们在计算一致预期时,我们以企业的年报实际公告日期为准,记企业最近公布的年报为FY0,则随后的年报分别为FY1,FY2。我们将FY1年份净利润的一致预期值记为Profit_FY1,FY2年份净利润的一致预期值记为Profit_FY2。 此外,传统的一致预期净利润时间加权的做法一般简单地按报告加权平均,对于近期的报告给予更大的权重而对于时间更早的报告给予小权重,但该做法忽略了不同时间点上报告数量差异的影响。假设我们现在用1月、2月、3月的报告来计算一致预期,其中1月份有10篇报告,而3月份只有2篇报告,我们希望对3月份的预测结果赋予更大的权重,因此3月份的报告赋予权重3,而1月份报告赋予权重1,但由于一月份报告数量明显多于3月份,因此加权时1月份的权重仍然是大于3月份的(10*1 > 3*2)。该方法存在不合理之处,所以我们需要适当修正。
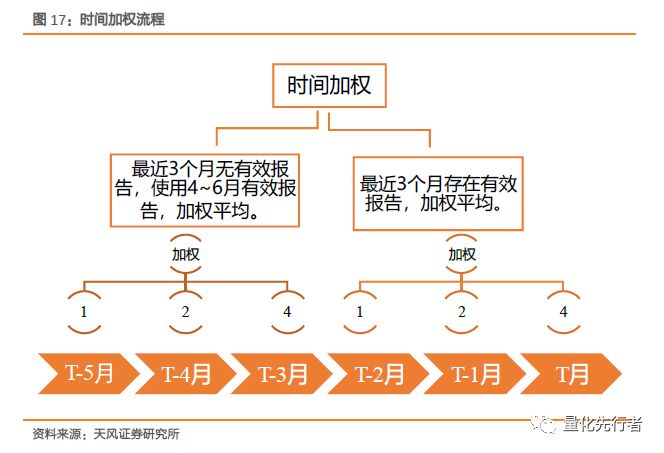
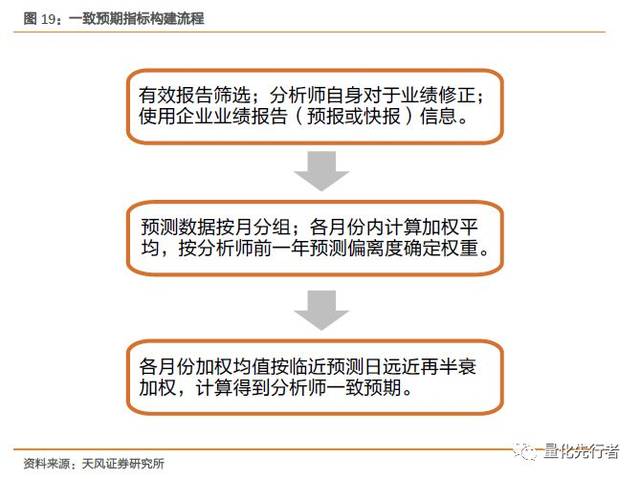
我们如图所示流程计算一致预期净利润值。首先,我们使用过去3个月的有效报告,将报告按撰写月份分组,对每组内预测数据计算简单平均得到各组的净利润预测值;然后,我们将3个不同月份的净利润预测值加权平均得到一致预期净利润指标,各预测值权重按照时间半衰,由远至近分别赋予各月份预测值权重1,2,4。若3个月内无有效报告,我们用6个月内的有效报告,方法同上。 4.5 一致预期净利润在分析师维度的加权 除了时间因素外,分析师因素也是影响预测精度的重要因素。分析师根据其所属机构的不同、研究年限长短以及自身研究能力等差异,其对于企业净利润的预测精确性也存在差异。 我们从分析师的预测精度入手,对于历史上预测更准确的分析师我们在计算一致预期时给予更大的权重。我们在前文定义预测偏离度bias衡量一个分析师预测的误差大小,但实际上该值的大小与该分析师撰写报告的时间跨度(报告撰写日到实际年报公告日的时间跨度),预测企业的市值大小以及所属行业均相关。当报告时间跨度越大时,预测便越困难;而预测企业市值越小时,其净利润的波动便越大,因此预测偏差就倾向于更大。因此偏离度指标需要做适当调整才能更好的衡量分析师的预测准确性。
为了更准确的衡量分析师预测的精确度,我们取预测年度上一年的所有分析师的预测数据汇总成截面数据,计算每个预测数据的偏离度bias。为了剔除预测偏离度受到其他因素的影响,我们将偏离度值bias对预测时间跨度δ、预测企业在报告撰写日截面上的对数市值标准化z-score值Size、以及企业所属行业哑变量Industry回归;剔除相关因素影响后,我们以残差值ε作为预测数据的修正后偏离度bias,衡量该预测的预测误差。
最后我们用每个分析师预测数据的平均调整后偏离度作为该分析师在当前年份的预测误差。此外,若分析师在上一年份预测数量小于5个,考虑数据稳定性我们将其预测偏离度作缺失值处理。 以预测期为2016年报的所有预测数据进行截面回归为例,回归结果如下式所示,
时间跨度δ系数为正,意味着预测时间跨度越长的预测数据,其预测误差便越大;而市值暴露Size系数为负,代表着市值越大的上市公司,分析师对其预测误差便越小,预测准确性越高。两变量检验t值绝对值均远超过阈值2,具有非常高的显著性。因此,预测偏离度的回归调整结果符合前文的结论,它使得我们对于跨度太长以及预测目标市值太小的预测数据有更大宽容度。 基于以上讨论,我们可以根据分析师在t-1年的修正后偏离度作为其预测精确性的度量标准,在计算t年净利润加权时以分析师在t-1年的预测表现对于预测数据赋予适当的权重。我们按照如下做法,我们将t-1年修正后偏离度最大的分析师权重设为1,将t-1年修正后偏离度最小的分析师权重设为5,剩余的分析师根据其在t-1年修正偏离度的大小线性插值到区间[1,5]之间,其权重如下式所示。同时,对于在t-1年无报告或者预测数小于5的分析师,我们将其权重设为1。由此,我们得到t年份各分析师的权重,如此滚动向前我们对于每个预测数据都能根据其所属分析师赋予合理的权重。
例如,若t-1年有四个分析师,且其中一个分析师在当年预测次数小于5,则将其偏离度值当作缺失值处理。调整后的各分析师平均预测偏离度分别为(-0.1,-0.9,1,nan),那么将各分析师权重插值到区间[1,5]中,则在t年各分析师对应的权重则为(3.316,5,1,1)。 4.6 一致预期净利润指标构建 由上文分析可知,一致预期净利润加权时,时间和分析师因素是加权时最为重要的两个维度;同时,有效报告筛选,分析师自身的预测修正,引入企业业绩报告(预报或快报)信息,都有助于我们对于净利润有着更精确的一致预期。以上各维度都是我们对于净利润简单平均算法所做修正,其中相对于报告撰写分析师而言,报告预测时间跨度显然占据更大的重要性,一个预测再精准的分析师也难以在很长的时间跨度下对企业净利润做出精确的判断;而企业报告无疑是最为精确的净利润预期数据。因此,综合各维度的重要性,最终的净利润一致预期加权算法如下图所示。
综合以上各维度,一致预期净利润加权方法如下: 1. 仅采用有效报告作为预测数据,其中有效报告定义为预测日前3个月内撰写并录入的报告。 2.存在业绩报告(预报或快报)信息时使用业绩报告中数据作为净利润一致预期。 3.计算t月底一致预期净利润时使用前3个月撰写并录入的有效报告数据。将报告按撰写月份分为3组:t-2月撰写、t-1月撰写和t月撰写。在每组内根据报告所属分析师权重加权,方法如前文4.5节所述。若前3个月,不存在有效报告时,使用前6个月的有效报告,加权方法相同。 4.在筛选出的有效报告内,若存在一个分析师对同一股票的多次预测,仅保留该分析师最新的预测数据。 5. 将每组均值按分组权重再加权平均,其中权重按由近至远分别赋予t月、t-1月,t-2月(或t-3月,t-4月,t-5月)半衰权重4,2,1。 根据以上加权方法,我们得到分析师对于净利润的一致预期,同前文我们定义一致预期的偏离度如下式所示,并以该值度量一致预期净利润的预测误差。
其中Profit_FY是一致预期净利润,Profit_Real是报告期实际净利润。 我们发现本文的一致预期加权方式相比于简单平均有着更高的精确度。为对比本文加权方式与普通平均的做法在偏离度上的差异,我们定义偏离度差异指标如下, diff=bias_simple-bias_tf 其中bias_simple是简单平均的偏离度值,而bias_tf为本文一致预期加权方式的偏离度值。 我们将所有预测期为2016年年报的截面数据按照预测时间跨度δ分组,以每组内偏离度中位数作为该组别的平均预测误差。其中时间跨度δ定义同上文:δ=M_report-M_t,其中M_report为报告实际公告日所在月份,M_t为一致预期预测日所在月份。 最终的偏离度变化如下图所示,在各时间跨度下本文的一致预期净利润加权方式相比于简单平均都有着更小的预测偏离度,同时这种效应在预测时间跨度越小时便越明显。当预测跨度较大时,预测精度的提升效果出现一定下降,主要原因是在预测时间跨度较大时,基础的预测信息可信度均不高,此时加权方式对于结果的提升有限。
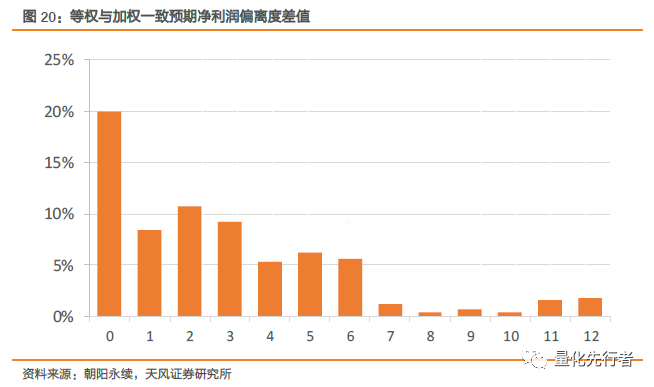
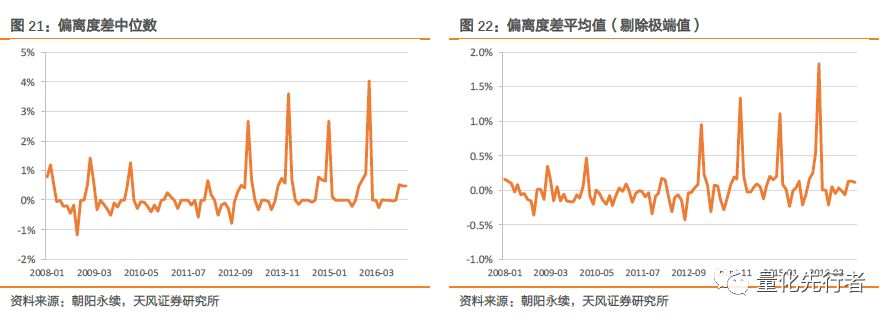
朝阳永续的数据库中有其对于企业净利润的一致预期加权结果。我们对比本文一致预期净利润值与朝阳永续数据库中表CON_FORECAST_STK的一致预期净利润值。在每个月我们分别计算各个股票朝阳永续一致预期净利润的预测偏离度与本文一致预期净利润的预测偏离度差值diff,我们以截面上该差值的中位数衡量两种方法预测精确度差异。此外,由于存在大量股票只有一个预测数据,因此本文所得的一致预期净利润值与朝阳永续的相等,此时偏离度差为0,无法对比两种方法的差异,因此在比较时我们剔除偏离度差为0的数据。 diff=bias_go-bias_tf 最终结果如下图所示,偏离度差呈现出明显的周期性变化。在每年一月份前后,由于本文使用了业绩报告(预报与快报)信息,因此相对于朝阳永续而言该加权方式有着更小的预测偏离度;而在其他时段,本文所加权的一致预期净利润预测偏离度与朝阳永续所加工指标表现相当,偏离度差值均非常接近于0。
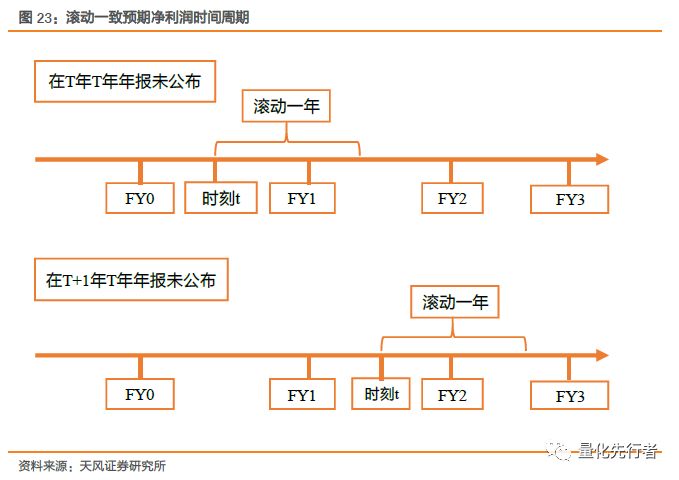
5 滚动一致预期净利润 类似于滚动净利润TTM指标,一致预期净利润也可以衍生出滚动一致预期净利润Profit_rolling指标。在实际使用中滚动净利润Profit_rolling相比于Profit_FY1更具合理性。若当前时点是3月份且企业年报还未发布,此时上一财务年份已经结束且前3季度报告已公布,此时对于该年报的预测意义已经不大。因此,一致预期的滚动净利润在当前的时点往后看一年,在实际使用中更具实际意义。
该算法以实际预测日所处年度为基础,在实际计算中需要用到Profit_FY3信息。如果在S1年企业上一年份的年报尚未公布,则Profit_S1即为Profit_FY2,Profit_S2即为Profit_FY3;若企业在当年度已公布上一年度的财务年报,此时Profit_S1即为Profit_FY1,而Profit_S2即为Profit_FY2。该算法以预测日所处的实际财务年度为准,在逻辑上更为合理,因此本文以该方法计算滚动一致预期净利润。
此外,滚动一致预期净利润还可以根据企业财务报表的公告情况来计算,其实际计算逻辑与Profit_TTM类似,方向上为在当前时点往未来滚动四个季度财报。假设当前预测年度已公布最新季报的累计净利润值为Profit_Rep,则滚动未来四季度净利润值为以下两者的和: 1. 当年一致预期净利润Profit_FY1与Profit_Rep的差值,即当年度尚未公布季报的季度净利润值的一致预期。 2. 下一年一致预期净利润Profit_FY2在当年已公布季报的季度净利润占比大小,我们以Profit_FY2乘以Profit_Rep/Profit_FY1作为该季度一致预期净利润的估计。
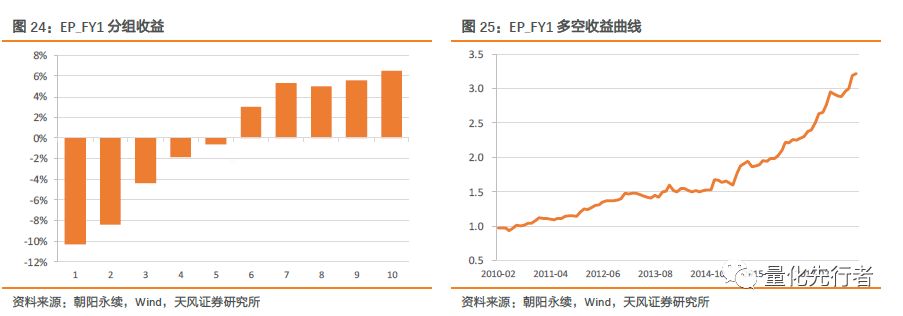
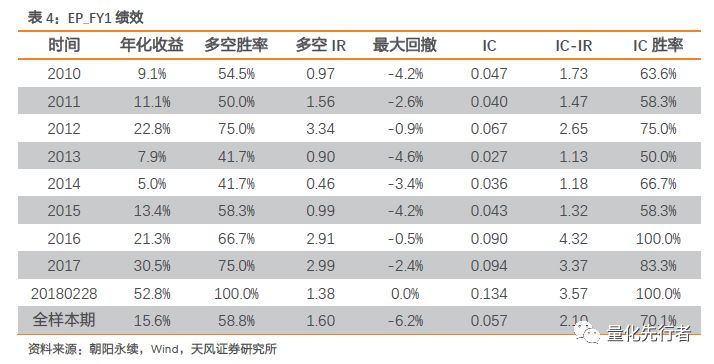
6 一致预期衍生指标构建与回测 根据一致预期净利润,我们可以衍生出诸如一致预期估值、一致预期净利润增速、一致预期PEG、一致预期估值变化、一致预期估值分位点等一系列指标等。以下我们分别分析这些指标的alpha能力,回溯其在历史绩效表现。 因子绩效回溯时,主要参数如下: 样本空间为上市满60个交易日全部A股 剔除ST股票及ST摘帽后不满60个交易日股票 回溯区间为2010年1月至2018年2月,月度调仓 不说明情况下因子值均默认做去极值、标准化以及行业市值中性化处理6.1 一致预期估值EP_FY 以一致预期净利润占企业总市值比得到企业未来EP的一致预期。 EP_FY=一致预期净利润 / 总市值 EP_FY衡量分析师对于企业未来估值水平的估计。当分子为下个未公告年度净利润一致预期值时,有 EP_FY1=Proft_FY1 / TOT_MV EP_FY1因子行业、市值中性化后历史绩效表现优秀,从2010年以来该因子有着稳定的收益,IC均值0.057,IC胜率达到70%,IC-IR达到2.1。
此外,EP_FY1因子分组单调性明显,多头组合收益虽略低于空头组合,但仍有年化约6%的收益。多空净值曲线在回溯区间内未出现明显回撤,多空净值曲线持续向上,多空组合收益表现出较强的稳定性。
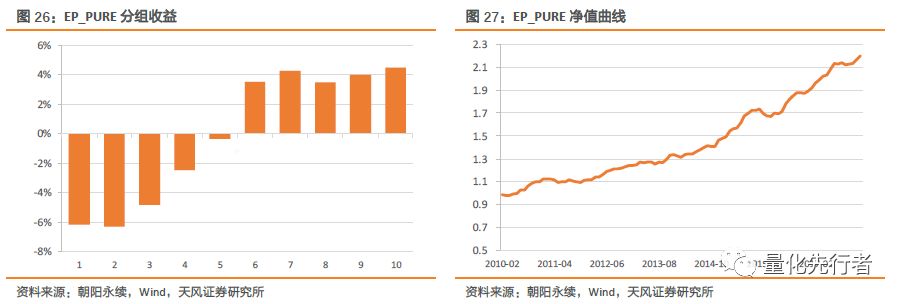
我们发现,一致预期估值EP_FY1与当前估值水平EP_TTM在截面上表现出较高的相关性,为此我们分析EP_FY1剔除EP_TTM因子后的表现。对EP_FY1行业、市值中性化时,我们同时加入EP_TTM,将EP_FY1原始值对行业、市值和EP_TTM作回归,得到同时与EP_TTM正交的因子EP_PURE。
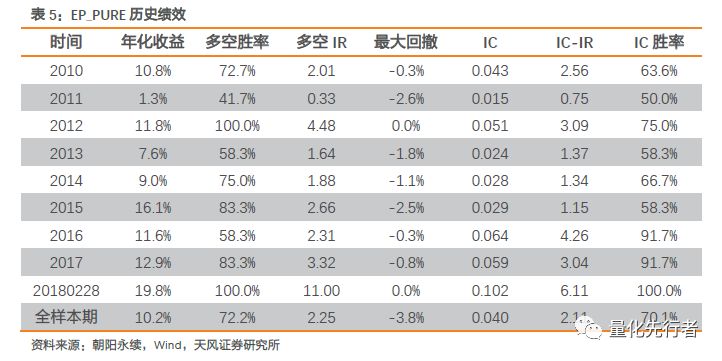
在相同的回溯区间内,剔除当前估值信息后一致预期估值绩效出现一定下降,但从多空组合收益与IC均值看,EP_PURE仍然表现出优秀的选股能力。
EP_FY1剔除EP_TTM后,因子有效性出现一定程度下降,IC均值从0.057下降到0.038,同时多空组合年化收益也从16%下降到10%。但因子稳定性有明显提升,多空组合IR从1.6提升到2.25,多空胜率58%提升到72%。
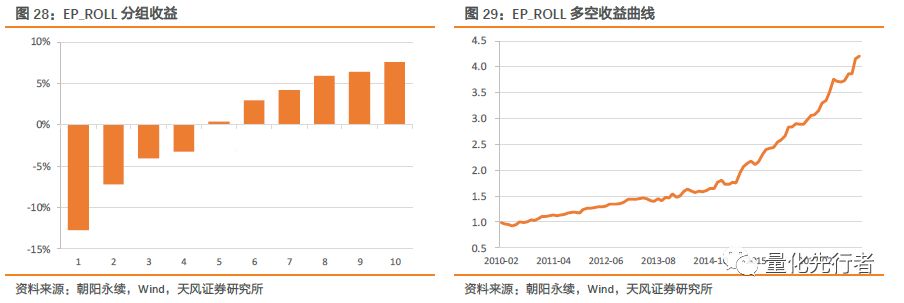
6.2 滚动一致预期估值EP_ROLL 我们将滚动一年净利润一致预期除以当前市值作为滚动一致预期估值EP_ROLL。 EP_ROLL=Profit_ROLL / TOT_MV EP_ROLL与EP_FY1表现出高度的相关性,本质上EP_ROLL是EP_FY1、EP_FY2和EP_FY3之间加权平均,而分析师对于Profit_FY1、Profit_FY2和Profit_FY3的盈利估计呈现出一致性,因此EP_ROLL与EP_FY1具有高度相关性。 但是如前文所分析,EP_ROLL在使用中更为合理,尤其在于每年的前四个月当企业年报尚未公布时,此时距离年报公布时间已经非常近同时上一个财务年度实际上已经结束,故此时EP_ROLL相较于EP_FY1更具有实际意义。
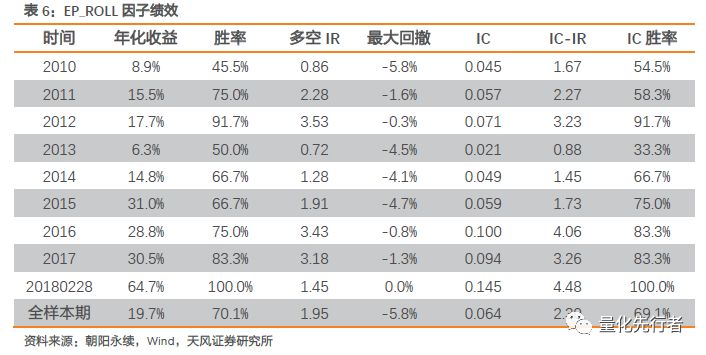
EP_ROLL在逻辑上更为合理,其绩效表现也优于EP_FY1指标。滚动估值EP_ROLL因子IC达到0.064,IC-IR达到2.30。同时多空组合年化收益达到19.7%,月度胜率提升至70%,相比于EP_FY1具有明显的提升。
6.3 一致预期成长Growth_FY 一致预期成长是分析师对企业未来成长水平的评价,由于希望在预测精度得到保证同时拥有较长的时间长度,因此实际使用中一般以一致预期的两年复合增长率作为分析师对于企业的成长水平评估。 假设最新公告的年报净利润为Profit_FY0,随后年度的净利润一致预期值分别为Profit_FY1和Profit_FY2,以往一般使用简单年化复合增长率
作为企业的成长水平的预期。但该算法忽略了企业盈利路径的变化,只关注Profit_FY2相对于Profit_FY0的增长,忽略了Profit_FY1存在极端值的情形,有欠妥当。 本文通过回归法计算企业的两年复合增长率。以最小二乘法拟合点列(1,Profit_FY0),(2,Profit_FY1),(3,Profit_FY2) 的线性方程 同时我们添加约束条件使得回归方程通过点(1,Profit_FY0)。系数b的拟合值b ̂即为企业每年的净利润增长额度,将b ̂除以三年净利润Profit_FY0,Profit_FY1,Profit_FY2平均值即得到企业的预期复合增长率。
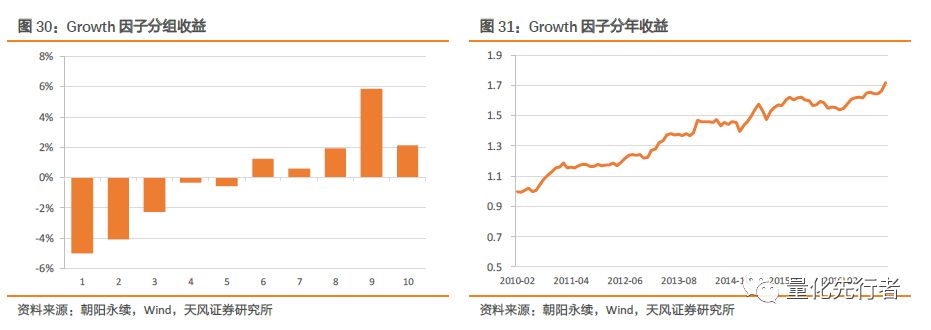
一致预期成长Growth历史绩效如下图所示,该因子分组上呈现出一定程度的单调性,但是第10组收益出现下降,且多空收益并不明显。同时其IC均值只有1.6%,多空收益只有6%,整体上该因子收益不明显,同时波动也较大,其alpha能力较弱。
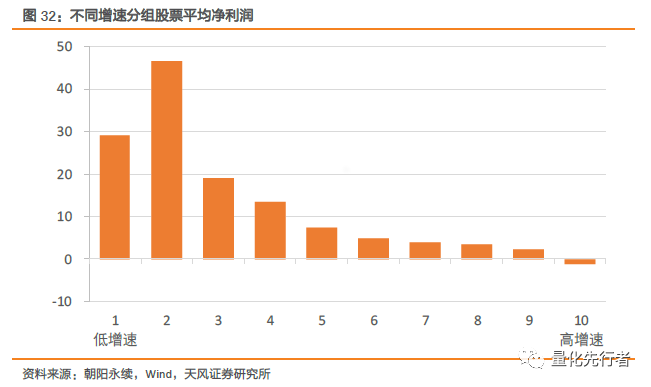
从分组收益可以看出,预期增速因子多头组合收益较低,其原因应是高预期增速组合中存在着大量的微利股,而这些微利润股往往表现出虚假的高预期增速水平。 事实上,一致预期增速因子构建逻辑中存在同样的问题。我们以预期净利润相对于前期净利润的增长率衡量企业的预期增速,然而高预期增速可能来自于两个原因:其一是企业未来有着高预期盈利水平;其二是企业前期业绩很差,盈利很低。而根据盈余惯性(PEAD),前期盈利较差的企业,其股价未来一段时间也将相应走低。
我们将所有股票按预期增速分成10组,各组内股票的平均净利润如上图所示表现出明显的递减趋势,增速越高的组合其平均净利润便越低。因此对于预期增速因子时,剔除历史净利润因素的影响是挖掘其alpha的关键。
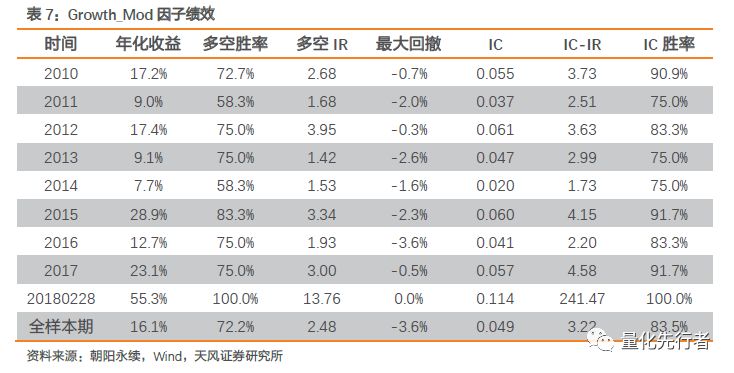
我们剔除上一年份净利润为负的样本,将预期增速对行业、市值及上期净利润做回归,如上式,取残差项作为修正后的增速Growth_Mod。通过上述回归方法,剔除净利润效应后,调整后预期增速因子Growth_Mod绩效如下。
预期增速指标剔除净利润因素之后,不同历史净利润基准下的预期增速变得更可比,调整后的增速因子表现出优秀的选股能力。分组收益单调性明显,因子IC均值达到0.049,IC-IR有3.22,年化多空收益16.1%,多空胜率以及IC胜率均在70%以上。
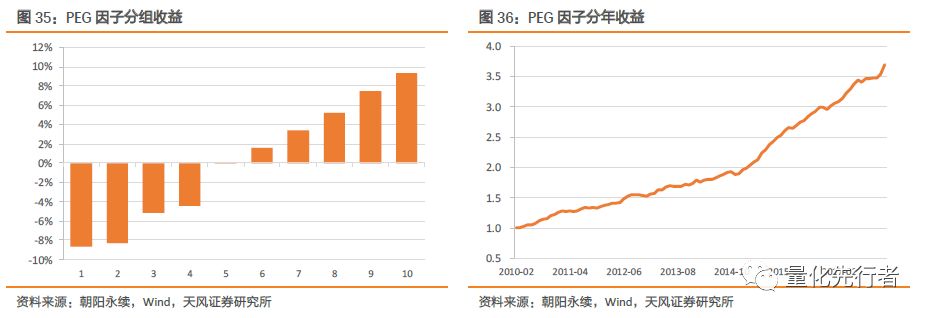
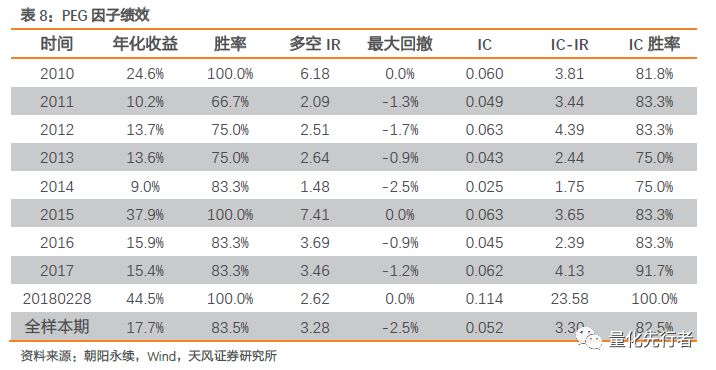
6.4 一致预期估值增速比PEG PEG(市盈率相对盈利增长比率)指标为企业市盈率与其盈利增长倍数的比值,相对于市盈率指标(PE)而言,其在选股的时候除了考虑企业估值水平外,还权衡了企业的成长性。我们以企业一致预期PE除以一致预期两年净利润复合增速得到其PEG指标。 PEG=PE_ROLL/Growth_FY=1/(EP_ROLL*Growth) 考虑到市盈率PE指标可能为负,而EP指标比PE指标保序性更好,因此我们以EP_ROLL*Growth_FY作为PEG代理变量。在相同回溯区间内,PEG因子历史绩效如下。
PEG因子表现出优秀的选股能力,其年化多空收益达到17.7%,IC均值达到0.052;同时PEG表现出极强的稳定性,多空收益率IR达到3.29,ICIR达到3.30,多空胜率以及IC胜率均超过80%。
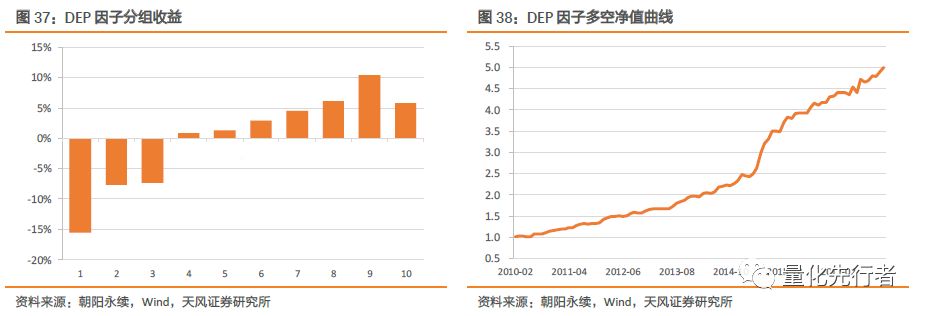
6.5 一致预期估值变化DEP 一致预期随着分析师对于企业预期的调整而变化。因此,股票在不同月份有着不同的预期估值水平。我们用一致预期估值EP_FY在不同月份的环比变化衡量分析师对于股票预期状况的调整。
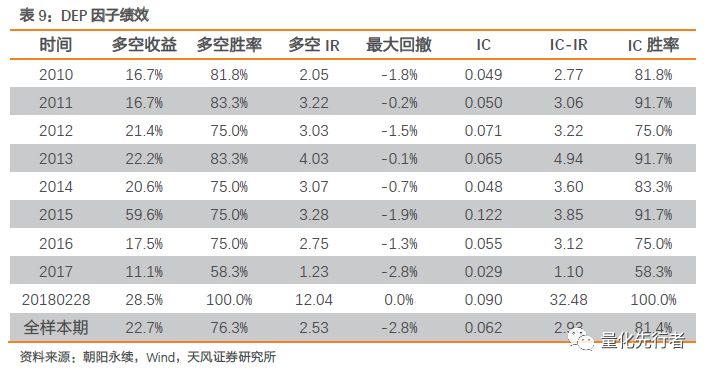
DEP因子在回溯区间内表现出优秀的alpha能力,其IC达到0.062,IC-IR达到2.93,年化多空收益达到22.7%,多空胜率以及IC胜率均在75%以上。
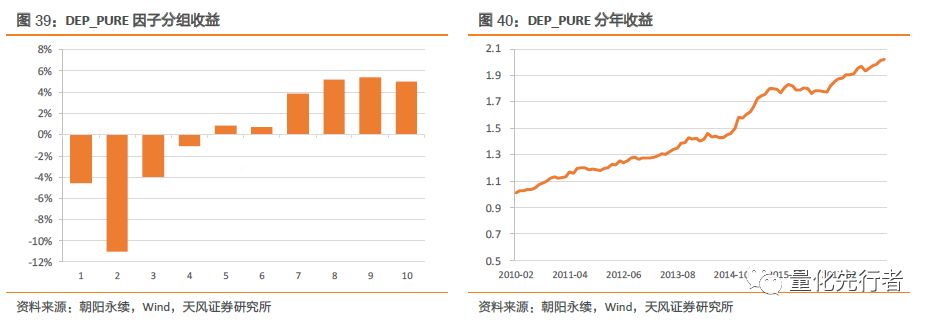
DEP指标构建过程中我们用到了价格信息以及预期估值信息,实际上由于一致预期净利润的变化不大,因此该因子的变化很大一部分来自于价格的变化,因此该因子与反转因子之间存在较高的相关性。我们按如下方式剔除反转因子效应: 在对DEP做行业、市值中性化同时剔除反转因子,最终在得到修正后因子DEP_PURE,该指标在测试区间绩效如下。
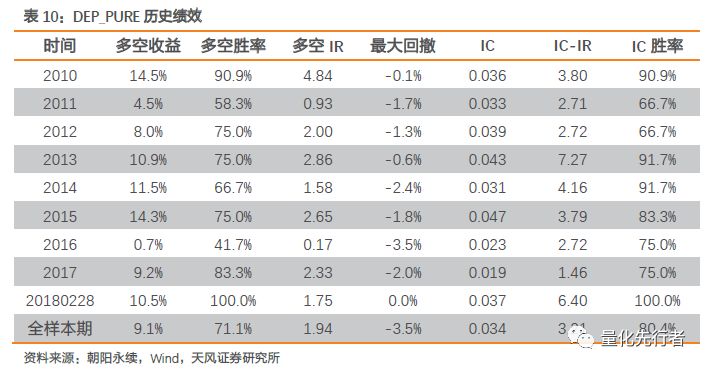
在剔除相关性较高的因子后,DEP_PURE仍表现出显著的选股收益,IC均值达到0.033,IC-IR有3.21,多空组合年化收益9.1%。因此剔除反转效应后DEP_PURE因子中蕴含着较为丰富的增量alpha信息,实际使用中可考虑直接使用剔除反转效应后的提纯因子。
6.6 一致预期估值分位点EP_PER A股市场存在明显的低估值溢价,一般我们对于估值溢价收益的获取主要利用截面上个股估值差异的比较。但实际上,估值溢价也存在于个股估值水平在时间序列上的差异。随着利润以及股价的波动,个股的估值水平随着而变化,在时间序列上表现出相对的高估值水平或者低估值水平。截面上的估值水平差异并不完全等同于时间序列上的估值差异,有些股票可能在截面上表现出高估值,但是在自身时间序列上可能呈现出低相对估值水平。 我们以个股一致预期估值EP_ROLL(滚动一致预期估值)在该股票过去12个月的滚动一致预期估值时间序列上的分位点代表其相对估值水平的高低。通过如下线性插值方式,我们确定当前一致预期估值水平在历史上的分位点。
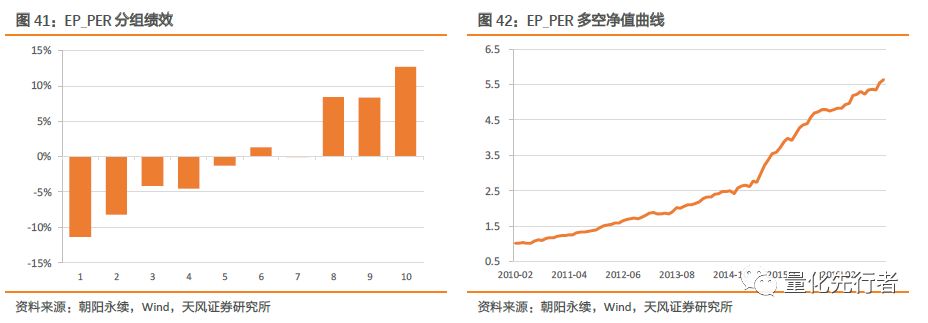
按照如上定义,剔除前期12个月内存在一致预期估值缺失的股票后,每个股票都存在一个介于0到1之间的相对一致预期估值分位点,最终行业、市值中性化后一致预期估值分位点EP_PER指标绩效如下。
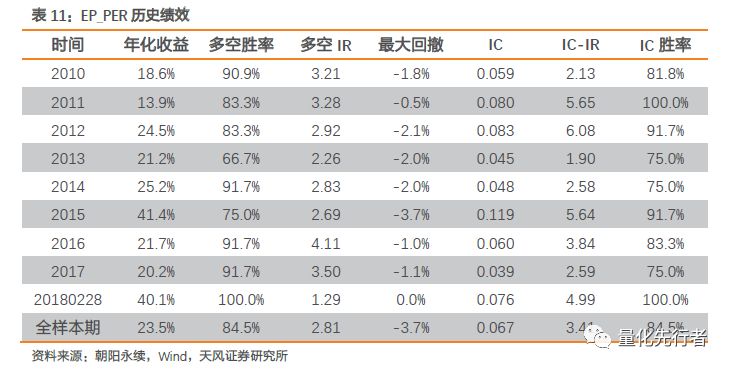
估值历史分位点EP_PER在回测区间内表现出极强的选股能力。其平均IC达到0.067,多空年化收益达到23.8%;同时因子表现出极强的稳定性,多空IC胜率以及IC胜率都在80%以上,IC-IR达到3.42。一致预期估值的历史分位点是一致预期衍生指标中因子收益及稳定性都极强的指标之一。
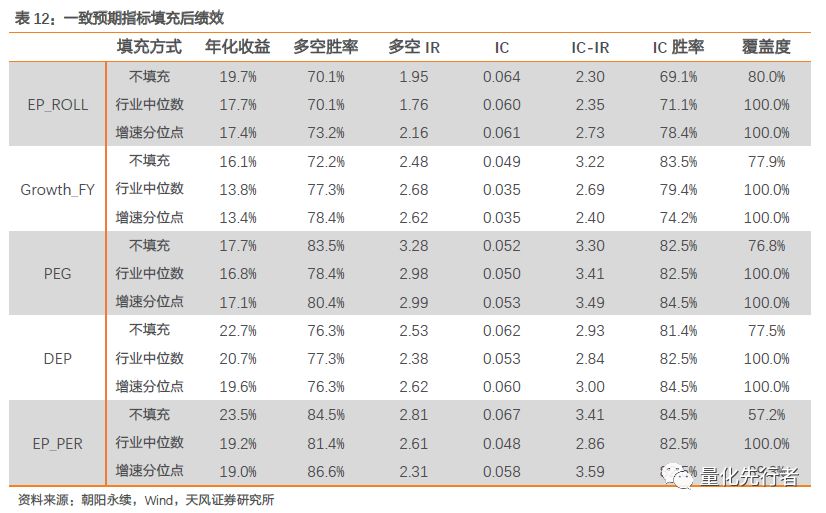
7 缺失值填充 由于分析师预期数据覆盖度有限,因此存在着部分数据的缺失。实际上,缺失值填补是我们在做多因子模型时经常遇到的问题。传统上,对于因子缺失值通常的做法是用该因子的行业均值或者中位数作为该缺失值的填充值。但对于一个足够精细化的模型而言,更为合理的做法应该是根据因子的投资逻辑,在因子构建阶段就对缺失值给予恰当的填充。 7.1 指标行业中位数填充 传统缺失值填充时,一般直接利用指标在行业内均值或中位数来填充同行业中的缺失数据。我们以中信一级行业作为行业划分,利用指标在各行业的中位数填补原始值缺失的数据,再将填充后的指标行业、市值中性化。利用行业均值或中位数填充缺失数据是实际操作中较为稳妥的方法,最终各指标填充后表现可见后文。 7.2 增速分位点填充 由于一致预期衍生指标的核心在于一致预期净利润的估计,各指标均通过一致预期净利润衍生而来,因此一致预期指标更合理的填充方式应优先填充一致预期净利润,再通过一致预期净利润的填充值计算缺失的衍生指标。 相对于直接用中位数等方式填充一致预期净利润,我们认为通过估计企业的增速,再计算一致预期净利润显得更加合理。以行业作为划分,对于预期净利润缺失的企业,我们以同行业内缺失企业在该行业内上年度增速分位点的平均值作为该行业内预期净利润缺失企业的增速估计值。 point_forecast=Mean(point_last) 如上式,point_last为预期净利润缺失企业上一年在行业内增速的分位点。通过增速分位点的估计,同时结合分析师给同行业其他企业的盈利增速预测,我们可以计算出预期净利润数据缺失企业在当年的预期增速水平。利用预期增速的估计以及企业前期的净利润,我们能得到当前一致预期净利润的估计值。由于相关指标都是由净利润衍生而得,最终各指标也都能得到填充。
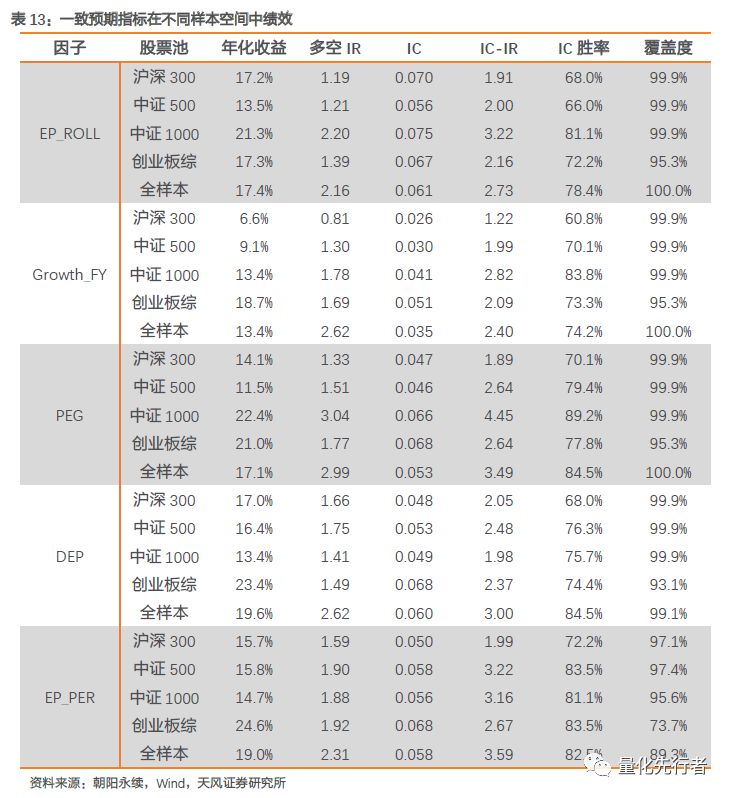
通过增速分位点途径填充一致预期指标,该方法通过先填充预期净利润再填充指标,其在逻辑上更加合理。从填充效果来看,直接利用行业中位数填充因子在多空收益上略好于增速分位点填充,其原因在于指标值行业内中位数填充将缺失数据填充到行业平均水平,对于多空组合的影响较小;但从因子的综合选股能力评价来看,增速分位点填充后因子有着相对更高的IC以及IC-IR,指标的综合选股能力提升更明显。两种方法效果相当,一致预期因子在填充后绩效并未出现明显下降,因子稳定性较高,填充后因子仍有着优秀的选股能力。 8 不同样本空间下表现 为了验证一致预期指标在不同样本空间下表现的稳定性,我们分别在沪深300,中证500,中证1000以及创业板综指中重新测试一致预期指标表现,并比较各指标在不同样本空间内的表现差异。 各指标默认做行业、市值中性化,其中增速指标同时剔除净利润因素,最终结果罗列在下表中。一致预期指标对于样本空间并不敏感,各一致预期指标在不同样本空间中均表现出优秀的选股能力。 此外,我们发现分析师一致预期估值指标EP_ROLL表现稳定,在各股票池表现均有着优秀的绩效水平,尤其在沪深300以及中证1000中IC均值达到0.07;分析师预期盈利增速指标与PEG指标在小票中有着更好的表现,对于小票投资者一般更关注其成长水平;而分析师一致预期估值变化DEP与一致预期估值分位点EP_PER两指标在各样本池中均有着表现出优秀的选股能力,其IC均值基本都在0.05以上,在全样本空间中IC-IR均超过3。
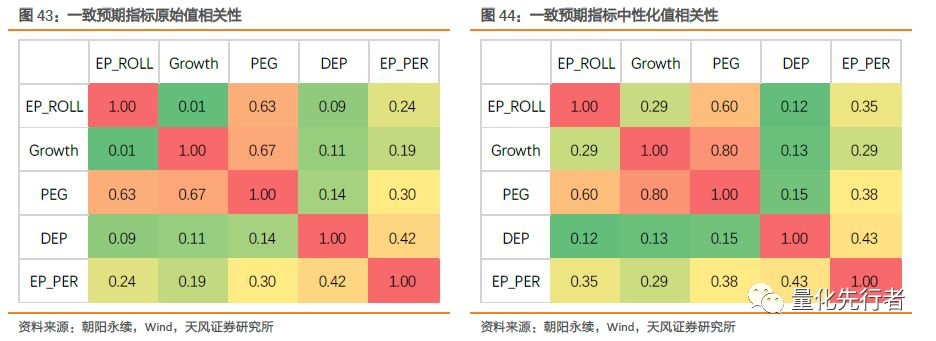
总而言之,一致预期指标在不同样本空间均有着稳定而优秀的绩效表现。实际投资中,不同投资者关注的着眼点可能存在差异,很多人更关心指标在大盘股中的选股表现,因此指标在不同样本空间中的稳定表现非常重要。由上表,一致预期相关指标在不同的股票池中均有着稳定的alpha能力,一些指标常面临的在大市值中选股能力迅速衰退的现象并未出现在一致预期指标上。因此,对于不同风格偏向的选股模型,一致预期指标都能贡献出显著的增量收益。 9 因子相关性 以上我们通过一致预期净利润衍生出一系列一致预期指标,然而实际使用中我们同样关注各指标间独立性,相对独立的指标才能为模型带来增量的alpha收益。 按照前文通过增速分位点方式填充各指标后,从2010年至2018年2月各一致预期指标间的平均截面相关性如下图所示。 EP_ROLL与增速指标间相关性非常低;由于PEG由EP_ROLL和Growth衍生而来,因此PEG与二者均存在较强的相关性;DEP与EP_PER指标均是衡量自身预期估值的相对变化,因此二者之间存在较强相关性,同时EP_PER与其他指标相关性更强。总体上,各指标间平均截面相关性并非特别的高,指标间的独立性尚可。
总结 Alpha模型的绩效提升关键在于增量alpha来源的贡献。分析师预期是与传统指标相对独立的指标。本文基于分析师预测数据构建了一系列分析师一致预期指标,其独立的alpha信息能为多因子模型带来增量收益。 追寻一个表现长期稳定的alpha因子,其核心不应在于历史数据拟合,而应该关注因子背后逻辑推演的合理性;相较于漂亮的历史回溯绩效,我们更关注于挖掘因子背后的深层含义。同样的,合理的一致预期指标的构建,目的不应在于追求其历史绩效多高,而应该关注于逻辑链的完整性、合理性。 一致预期指标的构建核心在于企业净利润的估计。本文以预测偏离度衡量预测净利润相对于实际净利润的预测误差。我们发现,分析师的预测偏离度与预测时间跨度、预测企业市值大小、预测企业所属行业等因素均相关。 时间因素是影响预测偏离度最显著的因素。一致预期计算时,我们基于时间加权,赋予新近报告以更大权重。此外,不同分析师预测误差也存在显著差异。我们将分析师预测偏离度经时间跨度、市值、行业因素调整,得到更加合理的分析师预测准确性评判准则。依据上一年份各分析师调整后预测偏离度均值,我们赋予预测误差越小的分析师以更大的权重,使得一致预期值有更强的精确性。 企业在年报发布之前可能会发布业绩快报与业绩预告,业绩报告(快报或预报)是企业经营状况的提前披露,其涵盖企业最真实的盈利信息。相较于分析师预测数据,业绩报告具有更高的可信度和准确性。因此存在业绩报告时,我们使用业绩报告数据作为净利润的一致预期值 基于时间、分析师两个维度,同时考虑业绩报告信息,本文构建了一致预期净利润指标。基于净利润估计,我们衍生出五大类一致预期指标:一致预期估值EP_FY,一致预期净利润增速,一致预期PEG,一致预期估值变化DEP,一致预期估值分位点EP_PER。各指标均表现出优秀的选股能力。 一致预期指标中存在缺失值,本文以预期利润缺失企业上一年度在行业中增速分位点的平均值作为其在当期行业中增速分位点的预测,从而推导出企业一致预期净利润的合理估计值。相较于以往方法更符合逻辑且因子综合绩效更优秀。 感谢实习生缪铃凯对本文的贡献。 市场系统性风险,模型失效风险,有效因子变动风险。 相关报告 《多因子模型的业绩归因评价体系》2018-04-10 《风险预算与组合优化》2018-03-05 《哪些行业应该单独选股?——基于动态因子筛选的行业内选股实证研究》2018-02-23 《协方差矩阵的常用估计和评价方法》2017-11-16 《因子正交全攻略——理论、框架与实践》2017-10-30 《基于动态风险控制的组合优化模型》2017-09-21 《MHKQ因子择时模型在A股中的应用》2017-08-15 《利用组合优化构建投资组合》2017-08-14 《半衰IC加权在多因子选股中的应用》2017-07-22 《反转现象的选择性交易策略》2017-05-31天风金工专题报告一览 《》2018-04-10 《》2018-03-22 《》2018-03-05 《》2018-02-09 《》 2018-02-08 《》2018-02-05 《金融工程:》 2018-01-22 《》2017-12-12 《》2017-11-28 《》2017-11-17 《》2017-10-30 《》2017-10-24 《金融工程:基于动态风险控制的组合优化模型》2017-09-21 《》 2017-09-18 2017-09-04 《金融工程:MHKQ因子择时模型在A股中的应用》 2017-08-15 2017-07-17 2017-07-11 《》2017-06-12 2017-06-01 2017-05-25 2017-05-14 2017-04-16 2017-03-22 2017-03-10 《金融工程:专题报告-基于自适应破发回复的定增选股策略》 2017-03-09 《金融工程:专题报告-定增节点收益全解析》 2017-03-06 2017-03-06 2017-02-14 2017-02-13关注我们
风险提示:市场环境变动风险,模型失效风险,有效因子变动风险。 《天风证券-金工专题报告-基于基础数据的分析师一致预期指标构建 2018-04-10》 2018年04月10日 张欣慰 SAC 执业证书编号: S1110517010003
|


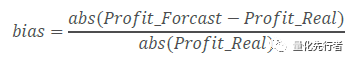



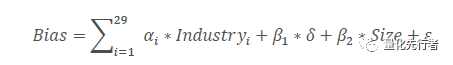
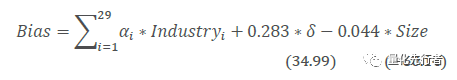
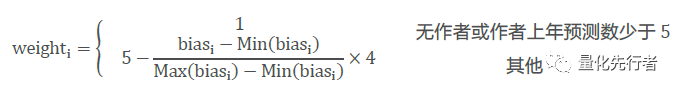
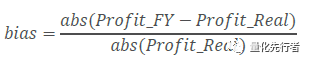


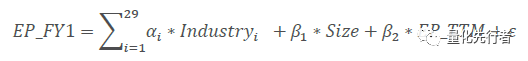
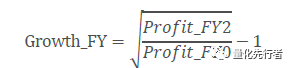

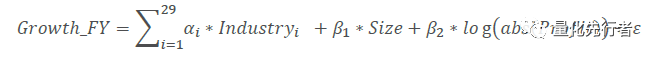





 返回搜狐,查看更多
返回搜狐,查看更多【本文地址】
今日新闻 |
推荐新闻 |