|
ms-tcn论文详解
这是一篇cvpr2019的论文,研究了一阵子,决定将论文主体思想写出来,给大家分享分享,也让自己巩固理解。
首先,看一下这篇论文的目的。
ms-tcn中,为时间动作分割任务引入了一个多阶段时间卷积网络。给定视频x1的帧:T =(x1,…,xT),我们的目的是推断每个帧c1的类标签:T=(c1,…,cT)(T是视频长度)。 论文大致分为:
Single-StageTCN ;Multi-StageTCN ;LossFunction ;Experiments ;Conclusion ;
Part 1 : Single-StageTCN
我们称Single-StageTCN为SS-TCN。第一层Single-StageTCN是一个1*1的卷积层,该层的作用是调整输入特征的尺寸来匹配在网络中的feature-map。下一层是一些1D的扩张卷积。(扩张卷积建议大家自己看一下,网上有不少介绍,大致作用与池化类似,但是增加了感受野。)受wavenet的结构影响(大家可以自行了解一下wavenet),我们在每一层中用加倍的dilation,1,2,4,……512。所有的这些层都有同样数量的卷积窗口。与wavenet中用到的因果卷积不同的是,我们用卷积核大小为3的非因果卷积。进一步,该文中也使用了残差连接来使得上一层的信息得以传到下一层中。每一层的操作可以描述如下: 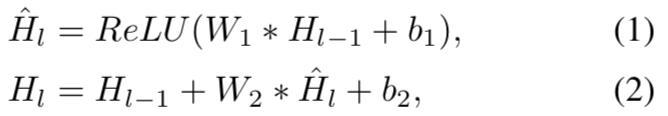  其中,有HL是第L层的输出,表示卷积操作,W1是核大小为3的扩张卷积的权重,D是卷积窗口的数量。W2是11卷积的权重。扩张卷积增加了感受野,无需通过增加层数或内核大小来增加参数数量。由于感受野随着层数呈指数增长,可以实现层数少但是感受野非常大,这有助于防止模型过度拟合训练数据。为了得到输出类的概率,在最后一个扩张卷积层的输出上应用1✖️1卷积,然后进行softmax激活。有: 其中,有HL是第L层的输出,表示卷积操作,W1是核大小为3的扩张卷积的权重,D是卷积窗口的数量。W2是11卷积的权重。扩张卷积增加了感受野,无需通过增加层数或内核大小来增加参数数量。由于感受野随着层数呈指数增长,可以实现层数少但是感受野非常大,这有助于防止模型过度拟合训练数据。为了得到输出类的概率,在最后一个扩张卷积层的输出上应用1✖️1卷积,然后进行softmax激活。有: 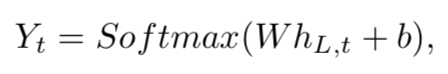 这里,Yt包含了在t时间时的类别,hL,t是t时间时的最后扩张卷积层的输出。 这里,Yt包含了在t时间时的类别,hL,t是t时间时的最后扩张卷积层的输出。
Part 2 Multi-Stage TCN
在这个多阶段模型中,每个阶段都从前一阶段进行初步预测,并在后一阶段进一步预测。第一阶段的输入是视频的逐帧特征,如下所示: 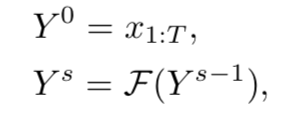 在这里,Ys是s阶段的输出,F是single-stage中的TCN。用这样的multi-stage框架帮助预测了每帧中的类的标签。下一阶段的输入只是没有任何附加特征的逐帧可能性。实验中展示如何在下一阶段的输入中添加特征,而这又会怎样影响预测。 在这里,Ys是s阶段的输出,F是single-stage中的TCN。用这样的multi-stage框架帮助预测了每帧中的类的标签。下一阶段的输入只是没有任何附加特征的逐帧可能性。实验中展示如何在下一阶段的输入中添加特征,而这又会怎样影响预测。
Part 3 Loss Function
在损失函数中,我们使用分类损失和平滑损失的组合。对于分类的loss,我们用一个交叉墒损失函数,有: 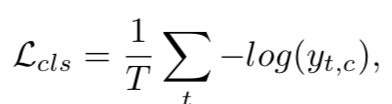 其中,有y是t时间时的对于预测概率值y。虽然这个交叉墒损失函数已经起到了很好的效果,但是我们发现对于一些视频来说,这个预测时有一些过分割的错误。为了进一步提升预测的质量,我们用一个额外的smoothing loss来减少这样 的过分割错误,在这种loss函数上,我们使用如下的loss函数作为平滑loss损失函数。有: 其中,有y是t时间时的对于预测概率值y。虽然这个交叉墒损失函数已经起到了很好的效果,但是我们发现对于一些视频来说,这个预测时有一些过分割的错误。为了进一步提升预测的质量,我们用一个额外的smoothing loss来减少这样 的过分割错误,在这种loss函数上,我们使用如下的loss函数作为平滑loss损失函数。有:  其中,有T是视频长度,C是类的数目,y(t,c)是在t时间对于类c的预测。这类似于相对熵损失函数。我们将在下面实验中比较KL损失函数与提出的损失函数。 最终的loss函数表达式为两者结合。 其中,有T是视频长度,C是类的数目,y(t,c)是在t时间对于类c的预测。这类似于相对熵损失函数。我们将在下面实验中比较KL损失函数与提出的损失函数。 最终的loss函数表达式为两者结合。 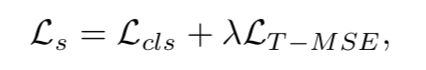
Part 4 Experiments
4.1 MS-TCN的作用 通过对比ms-tcn与ss-tcn模型,通过观察edit与F1我们发现,ss-tcn模型中出现了大量的过分割错误,这在很低的F1分数中可以观察到。通过实验,我们发现,四阶段的MS-TCN模型可以使得实验精度达到最佳值。  4.2 MS-TCN vs. Deeper SS-TCN 在这里,我们训练了一个48层的ss-tcn,这与四阶段的ms-tcn的层数相同,ms-tcn中有12层,其中包括10个卷积层,一个1*1的卷积层以及一个softmax层。在结果中所示,ms-tcn精度比ss-tcn提升了27%。该结果也说明了ms-tcn可以使得实验结果达到最精。 4.2 MS-TCN vs. Deeper SS-TCN 在这里,我们训练了一个48层的ss-tcn,这与四阶段的ms-tcn的层数相同,ms-tcn中有12层,其中包括10个卷积层,一个1*1的卷积层以及一个softmax层。在结果中所示,ms-tcn精度比ss-tcn提升了27%。该结果也说明了ms-tcn可以使得实验结果达到最精。  4.3 不同的损失函数的影响 在损失函数方面,我们使用了交叉墒损失函数与truncated mean squared loss的结合,尽管与一般的交叉墒损失函数相比,这样的loss在精度方面仅略微提升,但我们发现这样的loss有效减少了过分割错误。 同时,与KL-loss对比,我们也发现,我们提出的loss在各个方面性能更优。KL-loss损失函数结果不优是因为KL无法penalize预测与目标之间差异非常小的情况。 4.3 不同的损失函数的影响 在损失函数方面,我们使用了交叉墒损失函数与truncated mean squared loss的结合,尽管与一般的交叉墒损失函数相比,这样的loss在精度方面仅略微提升,但我们发现这样的loss有效减少了过分割错误。 同时,与KL-loss对比,我们也发现,我们提出的loss在各个方面性能更优。KL-loss损失函数结果不优是因为KL无法penalize预测与目标之间差异非常小的情况。  4.4 不同的超参数的影响 4.5 将特征输入更高阶段中 在这里,我们训练了两种multi-stage TCN,第一种是将这一阶段预测的逐帧概率输入到下一阶段中,第二种是我们将每一层中的空洞卷积层传到到下一阶段的输入中。 我们发现单纯的预测值的结果精度更好,是因为许多动作具有相似的外观和动作,通过在每一阶段这些类的特征,模型会混淆,造成结果精度问题。 4.4 不同的超参数的影响 4.5 将特征输入更高阶段中 在这里,我们训练了两种multi-stage TCN,第一种是将这一阶段预测的逐帧概率输入到下一阶段中,第二种是我们将每一层中的空洞卷积层传到到下一阶段的输入中。 我们发现单纯的预测值的结果精度更好,是因为许多动作具有相似的外观和动作,通过在每一阶段这些类的特征,模型会混淆,造成结果精度问题。  4.6 不同采样频率的影响 在这一部分中,文中提出了采样频率分别为1fps,与15fps时的训练结果的不同,虽然降低分辨率可以获得更好的f1,edit,但在精度上,高分辨率的结果更好。 4.6 不同采样频率的影响 在这一部分中,文中提出了采样频率分别为1fps,与15fps时的训练结果的不同,虽然降低分辨率可以获得更好的f1,edit,但在精度上,高分辨率的结果更好。  4.7 层数的影响 通过增加层数,可以有效改善实验结果,这是因为感受野的增大。当层数大于10时,精度不升反降,而f1,edit的结果会有更好的改善。 在这里,我们在gtea数据集上,实验分析了对于长短视频的不同结果。 4.7 层数的影响 通过增加层数,可以有效改善实验结果,这是因为感受野的增大。当层数大于10时,精度不升反降,而f1,edit的结果会有更好的改善。 在这里,我们在gtea数据集上,实验分析了对于长短视频的不同结果。  4.8 fine-tuning 特征的影响 实验也比较了特征微调的结果,微调确实改善了结果。 4.8 fine-tuning 特征的影响 实验也比较了特征微调的结果,微调确实改善了结果。  4.9 与现有的算法进行对比 4.9 与现有的算法进行对比 
Part 5 Conclusion
从该篇论文可以看出,其网络框架简单,思路清晰,激活函数也不复杂,但是该篇论文的精度很好,而且训练速度很快,这说明并不是越复杂层数越深的网络效果越好,往往简单而有效的网络不仅精度高,训练也很快。该篇论文实验部分做的很出色,方方面面考虑得都很细致,这也是能投中cvpr的一个重要因素。anyway,还有一些问题没有弄懂,等我弄懂了再多丰富一下。
下篇见。= =
|