python网络爬虫 |
您所在的位置:网站首页 › 哔哩哔哩动漫播放量排行 › python网络爬虫 |
python网络爬虫
|
(一)、选题的背景 因为我是个动漫爱好者,所以很喜欢看动漫剧,又叫做番剧,所以我都特别关注哔哩哔哩的动漫番剧排行榜的各番剧排名,评分,观看次数等等。 但是我不知道这几个数量值有什么关联。 所以我选择爬取bilibili的番剧综合排行榜的排名,番剧名,番剧链接,播放量,收藏量,评分,介绍。 并分析其中的排名,播放量,收藏量,评分几个数量之间是否有明显的联系。 (二)、主题式网络爬虫设计方案 1.主题式网络爬虫名称 python爬取哔哩哔哩网站的番剧排行榜和其中各番剧详情页信息 2.主题式网络爬虫爬取的内容与数据特征分析 番剧综合排行榜的排名,番剧名,番剧链接,介绍为文本类型。 播放量,收藏量,评分为数值类型。 3.主题式网络爬虫设计方案概述 先设计好爬取代码,然后处理好数据后将其记录在表格和数据表中,保存并进行数据分析。 (三)、主题页面的结构特征分析 1.主题页面的结构与特征分析 我的目的是要爬取bilibili的番剧综合排行榜的排名,番剧名,番剧链接,播放量,收藏量,评分,介绍。 而排行榜网页中只包含:排名,番剧名,番剧链接,播放量,收藏量。
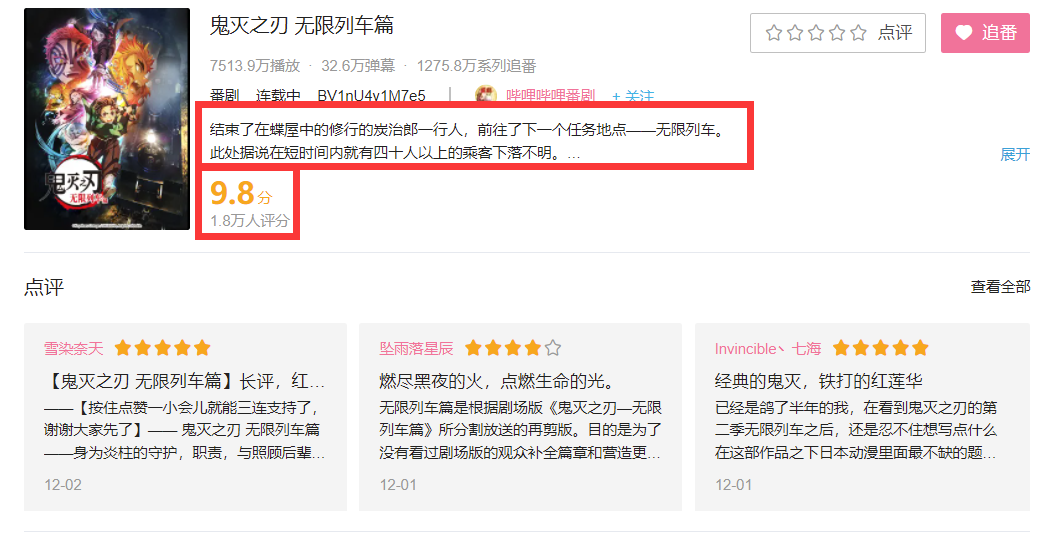
若想要知道它们的评分与番剧介绍需要进入详情页面查找。
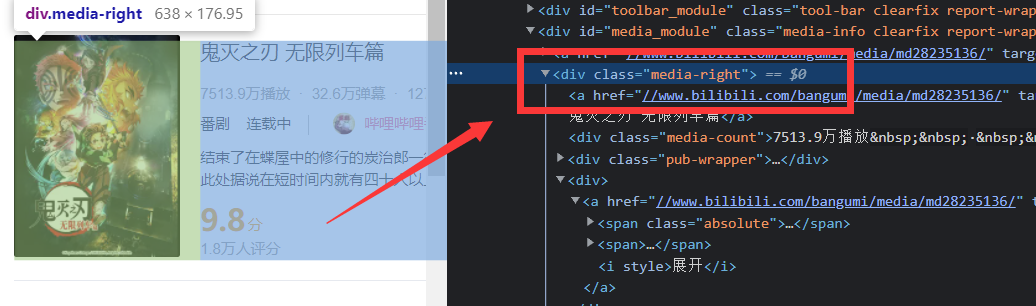
2.Htmls 页面解析 排行榜里的各条信息都包含在这个li标签中
详情页面中的评分和介绍都包含在这个div标签中
3.节点(标签)查找方法与遍历方法 经过分析,我打算先从第一个页面(排行榜页面)查找出每条符合条件的li标签,再逐个分析,从中提取想要的信息,比如说番剧名称,播放量,收藏数,番剧链接。 再通过爬取上一步提取的每条番剧链接,从第二个页面查找出每条符合条件的div标签,再逐个分析,从中提取想要的信息。 (四)、网络爬虫程序设计 数据爬取与 首先开始编写获取网页信息的函数(因为我们需要用到该代码两次,所以写为函数比较方便): 1 def get(url):#获取网页信息函数 2 head = { 3 "User-Agent": "Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome / 96.0.4664.110 Safari / 537.36" 4 } 5 #模拟浏览器头部信息 6 request = urllib.request.Request(url, headers=head) 7 #携带着这个包含着我的设备型号的头部信息去访问这个网址 8 html = "" 9 #用字符串对它进行存储 10 time.sleep(0.1) 11 #添加延时,防止错误 12 13 try: 14 #处理可能会发生的错误,比如说网络问题等,并输出错误代码,如404 15 response = urllib.request.urlopen(request) 16 html = response.read().decode("utf-8") 17 18 except urllib.error.URLError as e: 19 20 if hasattr(e, "code"): 21 print(e.code) 22 23 if hasattr(e, "reason"): 24 print(e.reason) 25 26 soup = BeautifulSoup(html,"html.parser") 27 #解析数据 28 return soup测试输出获取的信息,分析信息内容得知该网页可以用这种方式爬取我们想要的数据。
通过网页检查工具得知,排名里的番剧信息都分别包含于一个class="rank-item"的标签li之中,所以 1 for item1 in soup.find_all('li',class_="rank-item"): 2 # 查找符合条件的li标签,逐一分析即遍历(在输出的标签li列表中,逐一进行查找标签li中我们需要的信息,并保存于新的列表datalist中)测试输出了一条符合条件的li标签,分析其中的内容:得到想要的信息位置特征。
比如说包含番剧链接信息的文本的前面有“ 9.5: 9 pf[0] = pf[0] + 1 10 if df.评分[i] > 9.0 and df.评分[i] 8.5 and df.评分[i] 8.0 and df.评分[i] 7.5 and df.评分[i] 7.0 and df.评分[i] 9.5: 429 pf[0] = pf[0] + 1 430 if df.评分[i] > 9.0 and df.评分[i] 8.5 and df.评分[i] 8.0 and df.评分[i] 7.5 and df.评分[i] 7.0 and df.评分[i] |


【本文地址】
今日新闻 |
推荐新闻 |