深度学习(8) |
您所在的位置:网站首页 › 和飞鸿对应的词是什么 › 深度学习(8) |
深度学习(8)
|
看了这一节内容,结合之前CV相关知识,认为NLP也是将词表达为数字化,然后进行一系列预测判断等的过程,词嵌入得到学习矩阵E类似于图片解析为数字矩阵。 上一篇:深度学习(7)-RNN(网络模式,典型应用场景,梯度修剪,GRU,LSTM,双向RNN,深度RNN)https://blog.csdn.net/qq_36187544/article/details/93052465 下一篇:深度学习(9)-序列模型(seq2seq,机器翻译,集束搜索,注意力模型,语音检测与CTC)https://blog.csdn.net/qq_36187544/article/details/93715297 目录 词汇表征(词嵌入) 词嵌入的特性 嵌入矩阵(学习矩阵E) 词向量 情绪分类应用举例 词嵌入的偏见问题 词汇表征(词嵌入)one-hot表示:比如词典里有10000个单词,man是第1234个,表示为[0,0...0,1,0...0](第1234位为1,也表示为O1234)。这种表示法最大缺陷是每个词都相互独立,没有关联。 特征向量:利用各个特征将词更加细分化,比如特征1为是否为食物,香蕉最终300个特征得到[0.97,0.1,0.5...]等,这样就得到了300维特征,相较于one-hot表示更加强调关联性。但是一般来讲,机器不是通过人为规定的特征来记录这次词汇的,是通过某些可能我们也不清楚的特征来学习的,但是这些特征可以进行词嵌入实现低维化。 词嵌入:把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。比如下图为词嵌入二维空间表示,采用t-SNE算法进行可视化展示,可以看到词之间的关联程度关系:
词嵌入的特性:在多维空间内,找到向量对应关系。比如man->woman,那么king->?,可以求平行向量来找到最匹配的词语。注意:不要使用t-SNE算法转到二维可视化看这个关系,因为算法采用的是非线性映射,得到的结果不是可视的结果
计算方法可以通过计算余弦相似度:
嵌入矩阵即将词的特征(图为300维特征,10000个词库词语)组成矩阵,这个矩阵与独热编码的词语相乘能得到独立的特征词向量。比如,orange为第6257个向量,学习矩阵E×O6257得到orange的词向量。 意义:实现了矩阵与独热编码、词向量之间的相互转化,实现了词语转为数字向量,以便进行神经网络迭代更新矩阵E。 注意:由于独热编码的特性,一般不采用E×O的方式进行计算,将消耗大量计算资源,直接采用取特定的某一列的方式。
词向量意味着该词语的特征,常用的有word2Vec(包含CBOW和Skip-gram结构,前者通过上下文预测中间词,后者通过某词预测上下文某词)和GloVe词向量算法。 意义:将词语转化为词向量,之后可以通过这样进行下游工程应用。可以简单理解为这些算法就是简单神经网络将词语输出为序列 word2Vec迭代计算是比较慢的,所以也有将softmax层转化为分类树的softmax等方法加快速度。 情绪分类应用举例将词语转为词向量后,将其放入RNN网络,输出Y(情绪可分为5分好评,1分差评),应用场景比如分析顾客对某店的评价等:
通过词嵌入得到的结果往往具有偏见性,比如利用词嵌入分析男人->医生,女人->?,算法结果很可能得到护士的结果(性别歧视了,为啥不是医生),因为训练的语料库是人类本身的语言,所以得到的结果受人类认知的影响。词嵌入可能包含很多偏见,性别歧视、种族歧视等。 SVD(奇值分解)可以用来处理偏见问题,类似于PCA主成分分析算法,减少偏见。 因为机器学习逐渐被提上辅助分析社会重大决策的议程,所以消除这些偏见是很重要的。 |


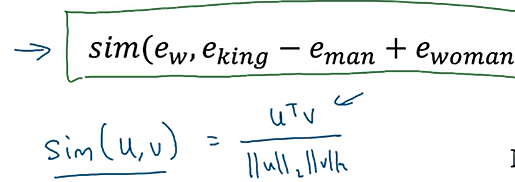


【本文地址】
今日新闻 |
推荐新闻 |