语音识别之MFCC特征提取 |
您所在的位置:网站首页 › 和弦基音 › 语音识别之MFCC特征提取 |
语音识别之MFCC特征提取
|
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 ** MFCC特征提取** 前言兜兜转转看了一些文献,总结出自己的一些理解,总结如下(若有错误之处,烦请指点一二): 一、为什么要做MFCC语音识别的第一步是特征提取,目的是可以给模型提供更加高质量的输入以此获得更好的识别效果。常用的特征提取包括线性预测倒谱系数(LPCC)和梅尔频率倒谱系数(MFCC)。 LPCC:是根据声管模型建立的特征参数,是对声道响应的特征表征MFCC:基于人类的听觉特征提取出来的特征参数,是对人耳听觉的特征的表征。MFCC比较常用,其步骤框图如下所示:
之所以进行预加重是因为,介质作为能量的载体,在声源尺寸一定的情况下,频率越高,介质对声能量的损耗越严重,而预加重可以在一定程度上弥补高频部分的损耗,保护了声道信息的完整性。 2.分帧语音信号在产生的过程中受到发声器官状态变化的影响,而状态变化速度较声音振动的速度要慢得多,因此可以认为是短时平稳的,进行分帧后对每一帧信号进行处理就相当于对特征固定的持续信号进行处理,可以以此减少非稳态时变的影响 3.加窗分帧后每一帧的起始段和末尾段会出现不连续的地方,从而导致与原始信号的误差越来越大。而加窗则可以使分帧后的信号变得相对连续,一般会选择使用汉明窗。 4.FFTFFT是指快速傅里叶变化。通过傅里叶变换,转化到频域。经过转化后可以得到语谱图。换句话说,前面的一些工作都是为了得到语谱图而做的一些准备。 语谱图的定义是语音经过短时傅里叶变换的幅度而画出的2D图,值得注意的是,不一定要非得是经过傅里叶变换而得到。根据定义可知,幅值是我们所需要的重要信息,因此在一些资料当中会进行一个幅值的平方。 语谱图分为两种,一种是窄带语谱图,一种是宽带语谱图: 窄带语谱图:带宽小,时宽大。因此在频率上就比较分的开,能够将语音在时间上的重复部分看得清楚,表现为“横条纹”,即频率分辨率高,容易分辨歌词谐波。 宽带语谱图:带宽大,时宽小。在时间上比较分得开,能将语音在时间上重复的部分看得清楚,表现为“竖条纹”,即时间分辨率高。 宽带语谱图:带宽大,时宽小。在时间上比较分得开,能将语音在时间上重复的部分看得清楚,表现为“竖条纹”,即时间分辨率高。 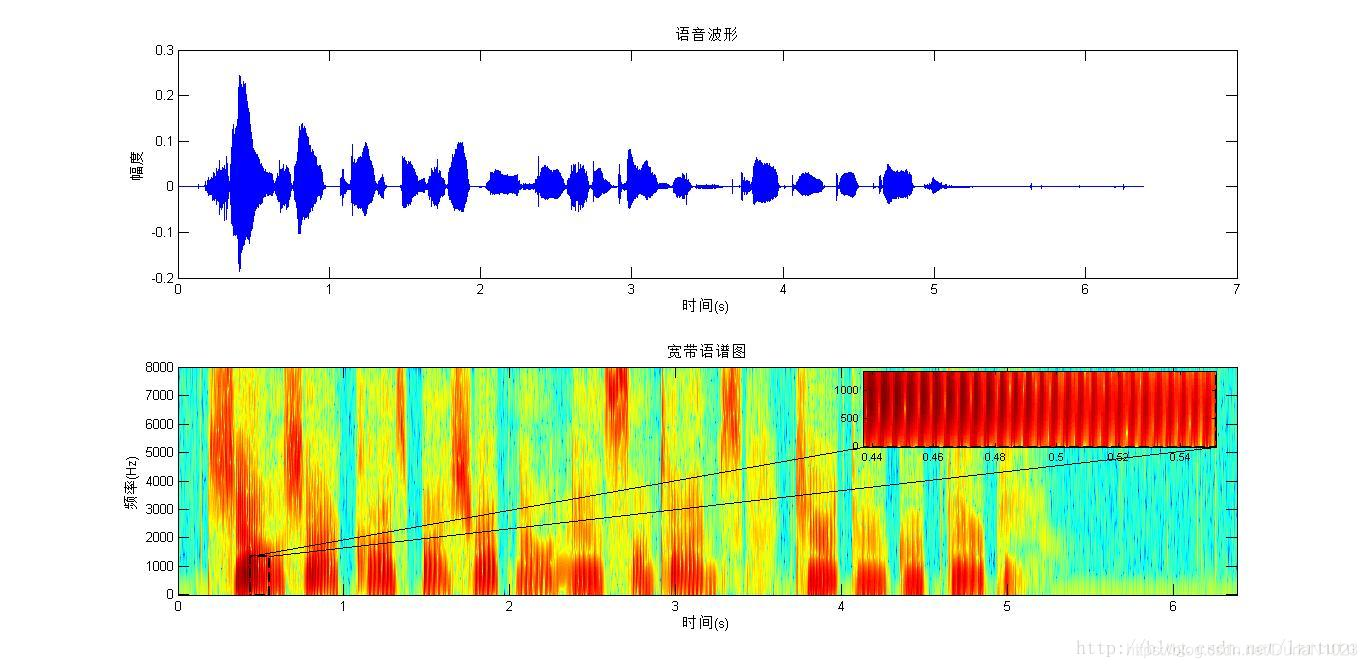
可以通过语谱图来分析基因频率和共振峰 5.Mel滤波器组Mel滤波器组种的每个滤波器都具有三角滤波特性,这些滤波器都是等带宽的。在高频部分分辨率较低,低频部分分辨率较高,只让某些频率的信号通过,对高频信息的幅度进行一个衰减。 人类的发声系统是由基因信息和声道信息卷积而成的,经过语谱图FFT变换之后卷积变成了乘法,此时取对数运算就能使其变成加法。也就是取FFT和对数运算是为了把卷积信号变成加性信号。 7.DCT
|

 语谱图(又称声谱图)横坐标是时间,纵坐标是频率,坐标点是语音数据能量。它虽然是2D图,但是可以表达三维的信息,能量的大小是通过颜色来进行区分的,颜色深则表示该点的语音能量强。
语谱图(又称声谱图)横坐标是时间,纵坐标是频率,坐标点是语音数据能量。它虽然是2D图,但是可以表达三维的信息,能量的大小是通过颜色来进行区分的,颜色深则表示该点的语音能量强。
 原始的频谱由两部分组成,即包络和频谱的细节。我们要提取的不仅仅是共振峰的位置,还得提取它们转变的过程。所以我们提取的是频谱的包络(Spectral Envelope)。
原始的频谱由两部分组成,即包络和频谱的细节。我们要提取的不仅仅是共振峰的位置,还得提取它们转变的过程。所以我们提取的是频谱的包络(Spectral Envelope)。  中间的图就是我们所需要提取出来的部分。那怎么把他们分离开呢?也就是,怎么在给定log X[k]的基础上,求得log H[k] 和 log E[k]以满足log X[k] = log H[k] + log E[k]呢?那就是利用DCT。 DCT(离散余弦变换)将基音信息和声道信息进行分离。基音信息在频域内是快速变化的,声道信息在频域内是缓慢变化的,因此再做一次DCT可以将其分离,这称之为倒谱域。 倒谱域的低频部分刻画了声道信息,高频部分刻画了基音信息。 得到的H[k]就是梅尔频率倒谱系数 对DCT变换后的输出进行一个降维就可以得到最后的MFCC特征。
中间的图就是我们所需要提取出来的部分。那怎么把他们分离开呢?也就是,怎么在给定log X[k]的基础上,求得log H[k] 和 log E[k]以满足log X[k] = log H[k] + log E[k]呢?那就是利用DCT。 DCT(离散余弦变换)将基音信息和声道信息进行分离。基音信息在频域内是快速变化的,声道信息在频域内是缓慢变化的,因此再做一次DCT可以将其分离,这称之为倒谱域。 倒谱域的低频部分刻画了声道信息,高频部分刻画了基音信息。 得到的H[k]就是梅尔频率倒谱系数 对DCT变换后的输出进行一个降维就可以得到最后的MFCC特征。 
【本文地址】