综述 词向量与分布式表示 |
您所在的位置:网站首页 › 向量矩阵表示法 › 综述 词向量与分布式表示 |
综述 词向量与分布式表示
|
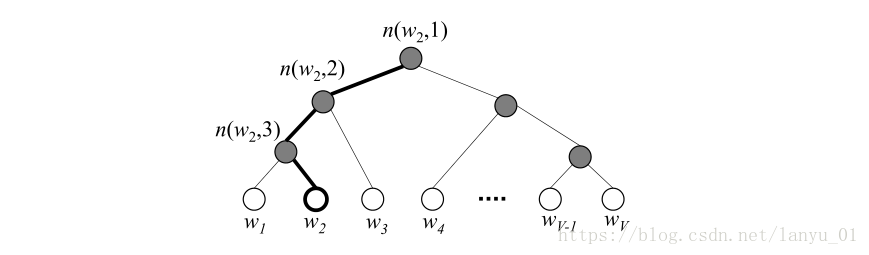
从古老的one-hot表示法,到大热的Word2vec系列的分布式表示方法,再到现在惊艳的预训练模型ELMo、BERT等,技术迭代迅速,这其中包含许多内容需要我们学习,例如语言模型LM、Transformer、CBOW、SkipGram等等。 接下来本文归纳梳理,逐一介绍。 目录 1、词的表示 2、词向量学习方法 2.1 matrix factorization 2.2 神经网络语言模型 (NNLM) 2.3 Word2Vec 2.4 Glove 2.5 fasttext 2.6 ELMo 2.7 BERT 2.8 XLNet 2.9 ALBERT 1、词的表示1.1 离散表示(one-hot representation) 把每个词表示为一个长向量。这个向量的维度是词表大小,向量中只有一个维度的值为1,其余维度为0,这个维度就代表了当前的词。 面临着数据稀疏性和维度灾难的问题。但也有一个好处,就是在高维空间中,很多应用任务线性可分。 1.2 分布式表示(distribution representation) 将词转化成一种分布式表示,又称词向量(Word embedding)。将词表示成一个定长的连续的稠密向量。 分布式表示优点:(1) 词之间存在相似关系,存在“距离”概念,这对很多自然语言处理的任务非常有帮助。(2) 词向量能够包含更多信息,并且每一维都有特定的含义。 2、词向量学习方法 2.1 matrix factorization例如,基于奇异值分解(SVD)的LSA算法 2.2 神经网络语言模型 (NNLM)2003年 Bengio 提出神经网络语言模型( neural network language model, NNLM),由此产生“词向量”,使用具有一定维度的实数向量进行单词的分布式表示,解决了维度爆炸的问题,同时通过词向量可获取词之间的相似性。 NNLM的任务是根据窗口大小内的上文来预测下一个词(从另一个角度看,它就是一个使用神经网络编码的n-gram模型)。如下图所示, 此网络由四层构成,输入层、嵌入层、隐藏层、输出层。输入层输入的是单词的index序列。例如,利用上文词 缺点:(1)计算量大,通过前馈神经网络来训练语言模型,其中的参数过多计算量较大,同时softmax那部分计算量也过大。(2)直观上看就是使用神经网络编码的 n-gram 模型,也无法解决长期依赖的问题。 2.3 Word2Vec相关论文 Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013. Word2Vec是用一个一层的神经网络把one-hot形式的稀疏词向量映射称为一个K维的稠密向量的过程。为了加快模型训练速度,论文中利用了一些技巧,包括Hierarchical softmax,negative sampling, Huffman Tree等。 Word2Vec里面有两个重要的模型CBOW模型(Continuous Bag-of-Words Model)与Skip-gram模型。 CBOW CBOW就是根据某个词前面的C个词和后面的C个连续的词,来计算某个词出现的概率。 网络结构分为三层: INPUT:输入层,自己设定窗口大小,在窗口中的词的one-hot向量 。 假设单词向量空间的维度为V,即整个词库大小为V,上下文单词窗口的大小为C。假设当前输入的文本为“我爱中国”,现在关注“爱”这个词,令C=2,则其上下文为“我”,“中国”。模型把“我”,“中国”的one-hot向量(大小为1*V)作为输入。 PROJECTION:隐藏层,直接将输入的向量进行累加求和(先进行线性变换,然后求加和)。我们最终所需要的词向量就是隐藏层的权重向量。 假设最终词向量的维度大小为N,则图中的权值共享矩阵为W。W的大小为 V * N,并且初始化。C个1 * V大小的向量分别跟同一个V * N大小的权值共享矩阵W相乘,得到的是C个1 * N大小的Hidden layer向量。这些隐层向量取平均(或加和等操作)得到一个1 * N大小的向量,即图中的Hidden layer。 OUTPUT:输出层,层次softmax,对应一个二叉树,词典库中的词当做叶子结点,以各词出现的次数当做权值,来构建Huffman树。也可以是softmax,但是对于类别较多时,softmax会对所有的词进行排序,然后取最大值,这种做法耗时大。为了提升效率,采用了层次softmax,将复杂度有O(n)降为O(log(n))。 输出权重矩阵 与真实值标签比较,求loss。 具体公式推导可参考 https://blog.csdn.net/lanyu_01/article/details/80097350 层次softmax (Hierarchical softmax) 参考下面的文章 1. https://blog.csdn.net/sir_TI/article/details/89199084 2. https://blog.csdn.net/lanyu_01/article/details/80097350 使用一棵二叉树来表示词汇表中的所有单词。所有的V个单词都在二叉树的叶节点上,非叶子节点一共有V−1个。对于每个叶子节点,从根节点root到该叶子节点只有一条路径。这条路径用来评估该叶子节点(单词)的概率值。 结构如图4所示, 其中白色的树节点代表的是词汇表中的单词,灰色节点为内部节点。图中高亮显示的是一条从根节点到 假定我们需要计算单词 负采样 (Negative Sampling) 在每次迭代的过程中,有大量的输出向量需要更新,为了解决这一困难,negative sampling提出了只更新其中一部分输出向量的解决方案。显然,最终需要输出的上下文单词(正样本)在采样的过程中应该保留下来并更新,同时我们需要采集一些单词作为负样本(因此称为“negative sampling”)。 具体做法,参考下面的文章 1. https://blog.csdn.net/sir_TI/article/details/89199084 Skip-Gram Skip-Gram是根据某个词,然后分别计算它前后出现某几个词的各个概率。 思路基本上与CBOW是一样的,不过,Skip-Gram是输入一个词而要预测多个上下文词,这时候需要其他的处理。 无论是CBOW还是Skip-Gram,本质还是要基于word和context做文章,即可以理解为模型在学习word和context的co-occurrence。
那么,Word2vec问世,为什么大火,而之前已经有了一些embedding的研究了呀? 这里借用复旦大学邱锡鹏老师在知乎上的回答。 Word2vec训练方面采用的Hierarchical Softmax以及负采样虽然是前人已有的工作,但Word2vec流行主要原因在于以下3点: (1)极快的训练速度。以前的语言模型优化的目标是极大似然估计MLE,只能说词向量是其副产品。Mikolov应该是第一个提出抛弃MLE(和困惑度)指标,就是要学习一个好的词嵌入。如果不追求MLE,模型就可以大幅简化,去除隐藏层。再利用HSoftmax以及负采样的加速方法,可以使得训练在小时级别完成。而原来的语言模型可能需要几周时间。再者,矩阵分解MF类的方法是global方法,训练大规模语料的能力远远不如word2vec。 (2)一个很酷炫的man-woman=king-queen的示例。这个示例使得人们发现词嵌入还可以这么玩,并促使词嵌入学习成为了一个研究方向,而不再仅仅是神经网络中的一些参数。MF类的算法在这种类比analogies task上有明显劣势。 (3)word2vec里有大量的tricks,比如噪声分布如何选?如何采样?如何负采样?等等。这些tricks虽然摆不上台面,但是对于得到一个好的词向量至关重要。 2.4 GloveGlove,综合利用全局特征的矩阵分解方法,和利用局部上下文的方法,即结合了global matrix factorization and local context window methods。 要讲GloVe模型的思想方法,我们先介绍两个其他方法: 一个是基于奇异值分解(SVD)的LSA算法,该方法对term-document矩阵(矩阵的每个元素为tf-idf)进行奇异值分解,从而得到term的向量表示和document的向量表示。此处使用的tf-idf主要还是term的全局统计特征。 另一个方法是word2vec算法,该算法可以分为skip-gram 和 continuous bag-of-words(CBOW)两类,但都是基于局部滑动窗口计算的。即,该方法利用了局部的上下文特征(local context) LSA和word2vec作为两大类方法的代表,一个是利用了全局特征的矩阵分解方法,一个是利用局部上下文的方法。 GloVe模型就是将这两中特征合并到一起的,即使用了语料库的全局统计(overall statistics)特征,也使用了局部的上下文特征(即滑动窗口)。为了做到这一点GloVe模型引入了Co-occurrence Probabilities Matrix。 具体参考https://blog.csdn.net/coderTC/article/details/73864097?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task 2.5 fastTextfastText是一个快速文本分类算法,与基于神经网络的分类算法相比有两大优点: 1、fastText在保持高精度的情况下加快了训练速度和测试速度 2、fastText不需要预训练好的词向量,fastText会自己训练词向量 3、fastText两个重要的优化:Hierarchical Softmax、N-gram fastText模型架构和word2vec中的CBOW很相似,不同之处是fastText预测标签而CBOW预测的是中间词,即模型架构类似但是模型的任务不同。
其中x1,x2,…,xN−1,xN表示一个文本中的n-gram向量,每个特征是词向量的平均值。这和前文中提到的cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别。n-gram是基于语言模型的算法,基本思想是将文本内容按照序列顺序进行大小为N的窗口滑动操作,最终形成窗口为N的字节片段序列。 2.6 ELMoELMo核心就是两点, 1.基于语言模型训练,使用双向的LSTM 2.启发于深度学习中的层次表示(hierarchical representation) 两点结合得到 Deep LSTM 具体细节可参考 https://zhuanlan.zhihu.com/p/51679783 2.7 BERT参考 https://zhuanlan.zhihu.com/p/46652512 https://mp.weixin.qq.com/s/c2PktKruzq_teXm3GAwe1Q BERT,Bidirectional Encoder Representation from Transformers,其设计了两个任务来预训练该模型, 第一个,Masked Language Model,通俗地说就是在输入一句话的时候,随机地选一些要预测的词,然后用一个特殊的符号[MASK]来代替它们,之后让模型根据所给的标签去学习这些地方该填的词。 第二个,Next Sentence Prediction,在双向语言模型的基础上额外增加了一个句子级别的连续性预测任务,即预测输入 BERT 的两段文本是否为连续的文本,引入这个任务可以更好地让模型学到连续的文本片段之间的关系。 对比OpenAI GPT(Generative pre-trained transformer),BERT是双向的Transformer block连接;就像单向rnn和双向rnn的区别,直觉上来讲效果会好一些。 对比ELMo,虽然都是“双向”,但目标函数其实是不同的。ELMo是分别以 Masked LM 在训练过程中作者随机mask 15%的token,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token。 Mask如何做也是有技巧的,如果一直用标记[MASK]代替(在实际预测时是碰不到这个标记的)会影响模型,所以随机mask的时候10%的单词会被替代成其他单词,10%的单词不替换,剩下80%才被替换为[MASK]。 预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇( 10% 概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。 因为序列长度太大(512)会影响训练速度,所以90%的steps都用seq_len=128训练,余下的10%步数训练512长度的输入。 Masked LM 并不是严格意义上的语言模型,因为整个训练过程并不是利用语言模型方式来训练的。BERT随机把一些单词通过MASK标签来代替,并接着去预测被MASK的这个单词,过程其实就是DAE(Denoising Autoencoder)的过程。 Next Sentence Prediction 因为涉及到QA和NLI之类的任务,增加了第二个预训练任务,目的是让模型理解两个句子之间的联系。训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,模型预测B是不是A的下一句。 作者从文本语料库中随机选择 50% 正确语句对和 50% 错误语句对进行训练,与 Masked LM 任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。作者特意说了语料的选取很关键,要选用document-level的而不是sentence-level的,这样可以具备抽象连续长序列特征的能力。 BERT 模型通过对 Masked LM 任务和 Next Sentence Prediction 任务进行联合训练,使模型输出的每个字 / 词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。 BERT的缺点: 1. 训练数据和测试数据之间的不一致性,[MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现 2. 假设句子中多个单词被 Mask 掉,这些被 Mask 掉的单词之间没有任何关系,是条件独立的,然而有时候这些单词之间是有关系的,比如”New York is a city”,假设我们 Mask 住”New”和”York”两个词,那么给定”is a city”的条件下”New”和”York”并不独立,因为”New York”是一个实体,看到”New”则后面出现”York”的概率要比看到”Old”后面出现”York”概率要大得多。 3. 每批次数据中只有 15% 的标记被预测,这意味着模型可能需要更多的预训练步骤来收敛。 4. 并不能用来生成数据。由于BERT本身是依赖于DAE的结构来训练的,所以不像那些基于语言模型训练出来的模型具备很好地生成能力。 2.8 XLNet为什么要提出XLNet呢?这就需要从BERT的缺点说起。 基于BERT的缺点,学者们提出了XLNet, 而且也借鉴了语言模型,还有BERT的优缺点。最后设计出来的模型既可以很好地用来执行生成工作,也可以学习出上下文的向量表示。 首先,一般的语言模型是单向的,即便我们使用Bidirectional LSTM类模型,其实本质是使用了两套单向的模型。那又如何去解决呢?答案是他们使用了permutation language model, 也就是把所有可能的permutation全部考虑进来。 另外,为了迎合这种改变,他们在原来的Transformer Encoder架构上做了改进,这部分叫作Two-stream attention, 而且为了更好地处理较长的文本,进而使用的是Transformer-XL。 这就是XLNet的几大核心! 2.9 ALBERT知乎评论说的很不错,https://www.zhihu.com/question/347898375/answer/863537122 ALBERT 就是“A Lite Bert”,“轻量级”。 相比Bert的改进,主要有三点,其中前两项和“减少参数量”有关,最后一项才是用来“超越Bert前辈”的。 (1)Factorized Embedding Parameterization Bert中词向量维度 E 和隐层维度 H 是相等的,E 会随着 H 不断增加。ALBERT认为,预训练模型主要的捕获目标是 H 所代表的“上下文相关信息”而不是 E 所代表的“上下文无关信息,因此,在词表 V 到 隐层 H 的中间,插入一个小维度 E,多做一次尺度变换, (2)Cross-layer Parameter Sharing 共享所有层的参数。具体分为三种模式:只共享 attention 相关参数、只共享 FFN 相关参数、共享所有参数。 “all-shared”以后,ALBERT-BASE的参数量直接从 89M 变成了 12M,毕竟这种策略就相当于把12个完全相同的层摞起来 如果是只共享 attention 参数,不仅可以减维,还能保持性能不掉。作者为了追求"轻量级",坚持把 FFN 也共享了。 那掉了的指标从哪里补?答案之一是把 ALBERT-large 升级为 ALBERT-xxlarge,进一步加大模型规模,把参数量再加回去。 (3)Sentence Order Prediction(SOP) Bert 原版的 NSP 目标过于简单了,它把”topic prediction”和“coherence prediction”融合了起来,SOP 对其加强,将负样本换成了同一篇文章中的两个逆序的句子,进而消除“topic prediction”。
参考文献: [1] https://www.cnblogs.com/dyl222/p/11005948.html [2] https://blog.csdn.net/sir_TI/article/details/89199084 词向量的面经,写的不错 [3] https://blog.csdn.net/bitcarmanlee/article/details/82291968 [4] https://blog.csdn.net/lanyu_01/article/details/80097350 [5] https://zhuanlan.zhihu.com/p/46652512 [6] https://www.zhihu.com/question/347898375/answer/863537122 [7] https://mp.weixin.qq.com/s/c2PktKruzq_teXm3GAwe1Q bert的面经,很不错
|


【本文地址】
今日新闻 |
推荐新闻 |