Python概率分布大全(含可视化) |
您所在的位置:网站首页 › 各种分布的概率函数 › Python概率分布大全(含可视化) |
Python概率分布大全(含可视化)
|
文章目录
术语前言整数浮点数抽取字节洗牌排列贝塔分布二项分布卡方分布狄利克雷分布指数分布F分布伽玛分布几何分布耿贝尔分布超几何分布拉普拉斯分布(双指数分布)逻辑斯谛分布正态分布(高斯分布)对数正态分布对数分布多项分布多元正态分布负二项分布非中心卡方分布非中心F分布帕累托分布(Lomax Distribution)泊松分布幂律分布瑞利分布柯西分布(洛伦兹分布)标准指数分布标准伽马分布标准正态分布学生t分布三角形分布(辛普森分布)均匀分布冯·米塞斯分布(循环正态分布)逆高斯分布(Wald Distribution)韦伯分布齐夫分布参考文献绘图代码
术语
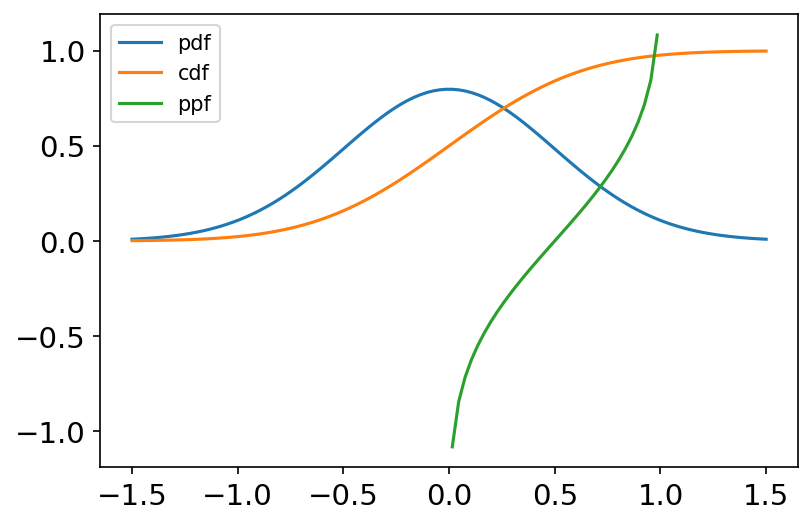
pdf,概率密度函数(Probability Density Function),连续型随机变量的概率。cdf,累积分布函数(Cumulative Distribution Function),pdf的积分。ppf,百分点函数(Percent Point Function),cdf的倒数。pmf,概率质量函数(Probability Mass Function),离散型随机变量的概率。
正态分布的各种函数 使用numpy.random.generator的Generator类 默认导入 import numpy as np from scipy import stats import matplotlib.pyplot as plt %matplotlib inline rng = np.random.default_rng() # 构造一个默认位生成器(PCG64) 整数integers(low, high=None, size=None, dtype='int64', endpoint=False) low下限,high上限,取值 [low, high) endpoint=True时取值 [low, high] size尺寸或形状 print(rng.integers(low=0, high=10, size=10)) # [0,10)的10个随机整数 print(rng.integers(low=0, high=10, size=10, endpoint=True)) # [0,10]的10个随机整数 print(rng.integers(low=0, high=10, size=(2, 4))) # 形状为(2, 4) print(rng.integers(low=0, high=[1, 10, 100])) # 上限不同 # [3 8 4 2 7 1 1 9 7 4] # [ 9 10 8 1 7 3 7 8 8 6] # [[4 4 1 2] # [2 6 3 8]] # [0 9 2]
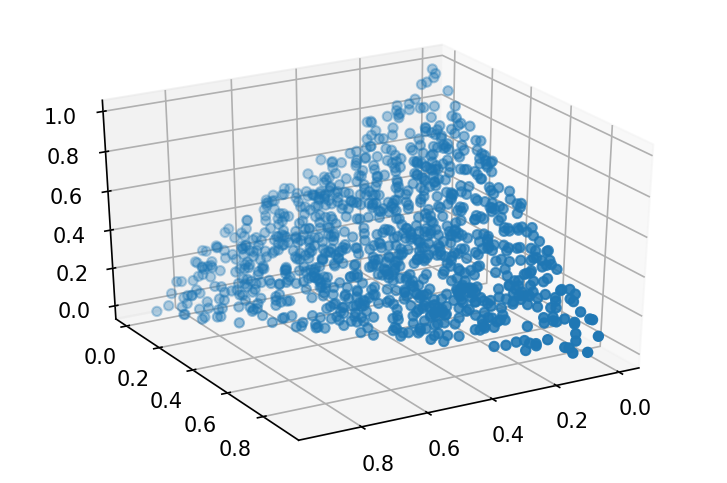
random(size=None, dtype='d', out=None) size尺寸或形状 print(rng.random(size=10)) # [0.0, 1.0)的10个随机浮点数 print(rng.random(size=(2, 4))) # 形状为(2, 4) # [0.6986286 0.7083849 0.86588093 0.63301974 0.89362993 0.97340382 0.79295529 0.14079166 0.50348895 0.73972237] # [[0.54939163 0.04432164 0.6797271 0.49858971] # [0.3781034 0.89830482 0.06314135 0.25944355]] low = 0 high = 10 print((high-low)*rng.random(size=10)+low) # [0.0, 10.0)的10个随机浮点数 # [8.92076148 8.11545414 9.34270912 4.95565778 0.88044604 7.9555204 3.3780767 7.9214436 3.64540636 1.29831035]
choice(a, size=None, replace=True, p=None, axis=0) a 抽取范围 int或1维数组 size尺寸或形状 replace是否放回原处 p 每个元素的抽取概率 1维数组 print(rng.choice(a=10, size=3)) # [0,10)的3个随机整数,a=10调用了np.arange(10),相当于rng.integers(low=0, high=10, size=3) print(rng.integers(low=0, high=10, size=3)) # [2 6 0] # [8 4 4] print(rng.choice(a=[1,2,3,4,5], size=5)) # 从中抽3个 print(rng.choice(a=[1,2,3,4,5], size=5, replace=False)) # 不放回 # [1 2 2 5 2] # [5 4 1 3 2]
bytes(length) print(rng.bytes(10)) # b'\xf7\x8f@{\x9d\xbb\xdfk\x9c\x97' 洗牌shuffle(x)返回空值,影响原数组 l = np.arange(10) # list也行 print(l) rng.shuffle(l) print(l) # [0 1 2 3 4 5 6 7 8 9] # [6 8 9 2 0 3 5 4 7 1]
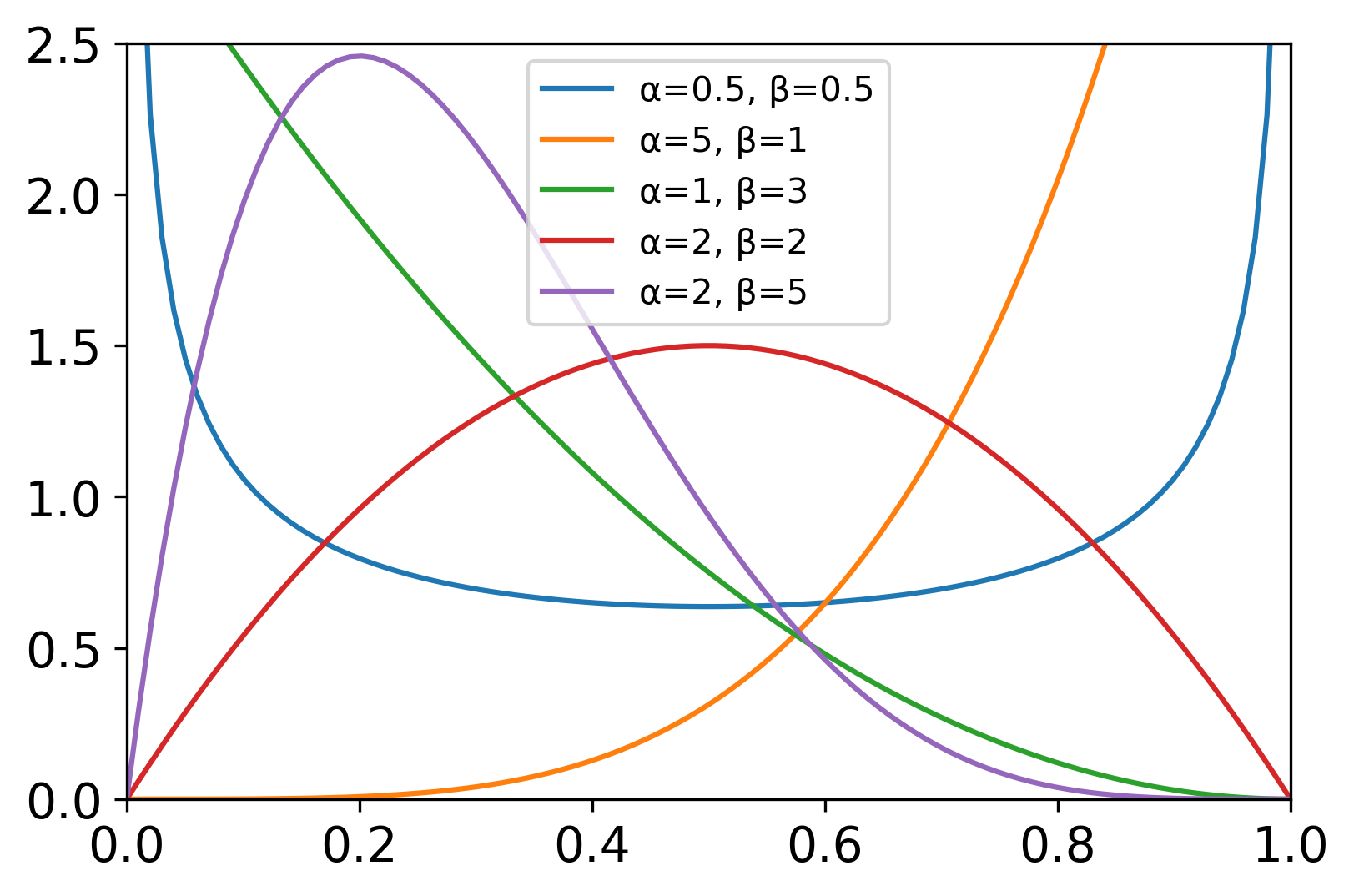
permutation(x)类似洗牌,只影响最外层 x int或数组 print(rng.permutation(10)) # 随机排列0-9的数组 print(rng.permutation(np.arange(10))) #同上 # [7 8 6 0 2 1 9 3 4 5] # [0 5 7 2 8 6 4 3 9 1] arr = np.arange(9).reshape((3, 3)) print(arr) print(rng.permutation(arr)) # 只影响最外层的顺序 print(arr) # [[0 1 2] # [3 4 5] # [6 7 8]] # [[3 4 5] # [6 7 8] # [0 1 2]] # [[0 1 2] # [3 4 5] # [6 7 8]] 贝塔分布beta(a, b, size=None) 贝塔分布是狄利克雷分布的特例,与伽马分布有关。 贝塔分布是伯努利分布和二项式分布的共轭先验分布的密度函数,也称B分布,是一组定义在(0,1)的连续概率分布(概率的概率分布)。 概率分布函数: f ( x ; α , β ) = 1 B ( α , β ) x α − 1 ( 1 − x ) β − 1 f\left( x;\alpha ,\beta \right) =\frac{1}{\text{B}\left( \alpha ,\beta \right)}x^{\alpha -1}\left( 1-x \right) ^{\beta -1} f(x;α,β)=B(α,β)1xα−1(1−x)β−1 随机变量 X X X服从参数为 α , β \alpha ,\beta α,β的B分布写作 X Be ( α , β ) \text{X~Be}\left(\alpha ,\beta \right) X Be(α,β) 常用于贝叶斯推理和顺序统计问题
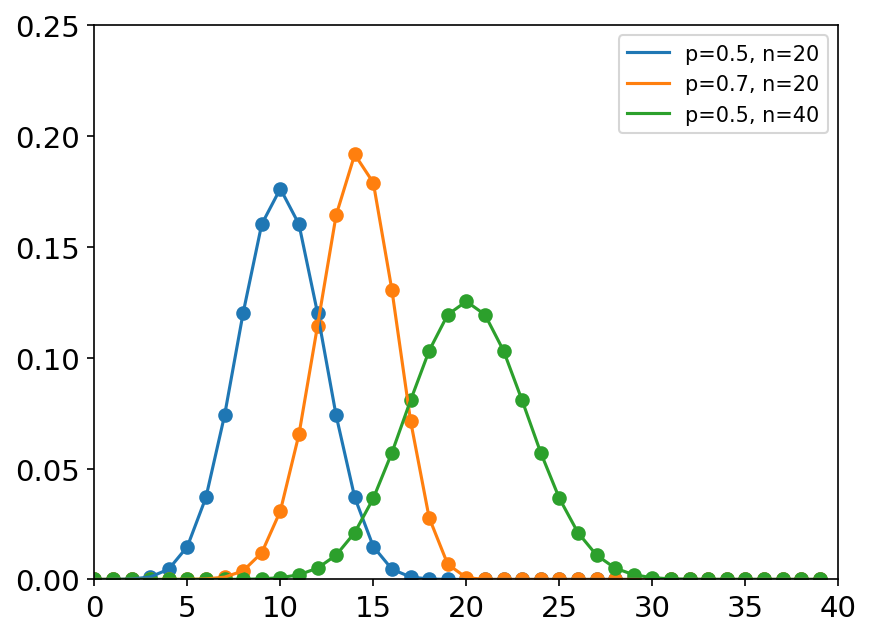
binomial(n, p, size=None) 二项分布是重复n次的独立的伯努利试验(事件发生概率为p),每次试验相互独立,如抛硬币。 概率密度函数: P ( N ) = ( n N ) p N ( 1 − p ) n − N P\left( N \right) =\left( \begin{array}{c} n\\ N\\ \end{array} \right) p^N\left( 1-p \right) ^{n-N} P(N)=(nN)pN(1−p)n−N 其中n是试验次数,p是成功的概率,N是成功的次数。
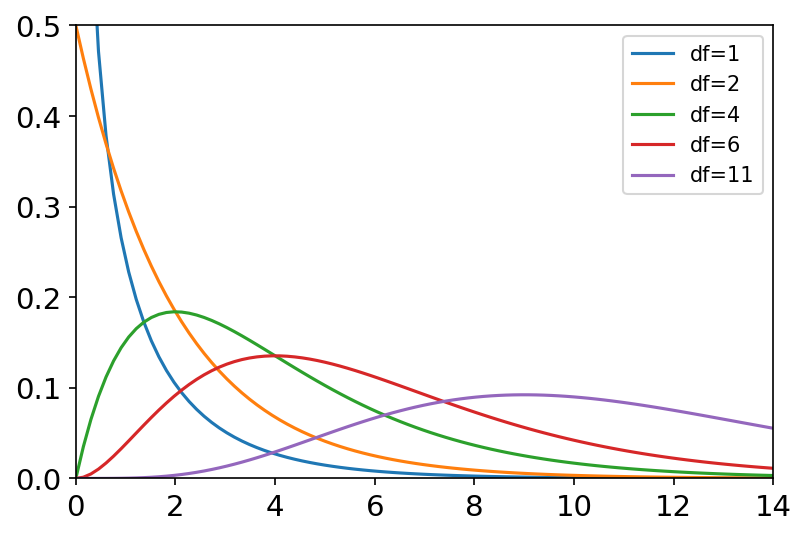
chisquare(df, size=None) df(自由度数)是独立随机变量,每个变量是标准正态分布(均值为0,方差为1),将其进行平方求和,得到卡方分布。 概率密度函数: p ( x ) = ( 1 / 2 ) k / 2 Γ ( k / 2 ) x k / 2 − 1 e − x / 2 p\left( x \right) =\frac{\left( 1/2 \right) ^{k/2}}{\Gamma \left( k/2 \right)}x^{k/2-1}e^{-x/2} p(x)=Γ(k/2)(1/2)k/2xk/2−1e−x/2 其中 Γ \Gamma Γ是伽马函数: Γ ( x ) = ∫ 0 − ∞ t x − 1 e − t d t \Gamma \left( x \right) =\int_0^{-\infty}{t^{x-1}e^{-t}dt} Γ(x)=∫0−∞tx−1e−tdt 常用于假设检验。
性别与宠物偏爱是否有关 列联表 猫狗男207282女231242列联表2行2列,则自由度df=(r-1)(c-1)=(2-1)*(2-1)=1 x = [[207, 282], [231, 242]] chi2, p, df, expected = stats.chi2_contingency(x, correction=False) # 结果分别为:卡方值、P值、自由度、理论值,无需耶茨连续性修正 value = stats.chi2.ppf(0.95, df=df) # 变量相关概率为0.95时对应的卡方值 print('自由度{}'.format(df)) print('数据卡方值{:.2f}大于变量相关为0.95的卡方值{:.2f}'.format(chi2, value)) print('因此变量相关的可能性大于0.95') print('变量相关的可能性具体为{:.2f}'.format(1-p)) # 自由度1 # 数据卡方值4.10大于变量相关为0.95的卡方值3.84 # 因此变量相关的可能性大于0.95 # 变量相关的可能性具体为0.96 狄利克雷分布狄利克雷分布是贝塔分布在高维的推广,常作为贝叶斯统计的先验概率。 概率密度函数: Dir ( X| α ) = 1 B ( α ) ∏ i − 1 K x i α i − 1 \text{Dir}\left( \text{X|}\alpha \right) =\frac{1}{\text{B}\left( \alpha \right)}\prod_{i-1}^K{x_{i}^{\alpha _i-1}} Dir(X|α)=B(α)1∏i−1Kxiαi−1 B ( α ) = ∏ i − 1 K Γ ( α i ) Γ ( ∑ i = 1 K α i ) \text{B}\left( \alpha \right) =\frac{\prod_{i-1}^{\text{K}}{\Gamma \left( \alpha _i \right)}}{\Gamma \left( \sum_{i=1}^{\text{K}}{\alpha _i} \right)} B(α)=Γ(∑i=1Kαi)∏i−1KΓ(αi) α = ( α 1 , . . . , α K ) \alpha =\left( \alpha _1,...,\alpha _{\text{K}} \right) α=(α1,...,αK) 常用于自然语言处理,特别是主题模型的研究。
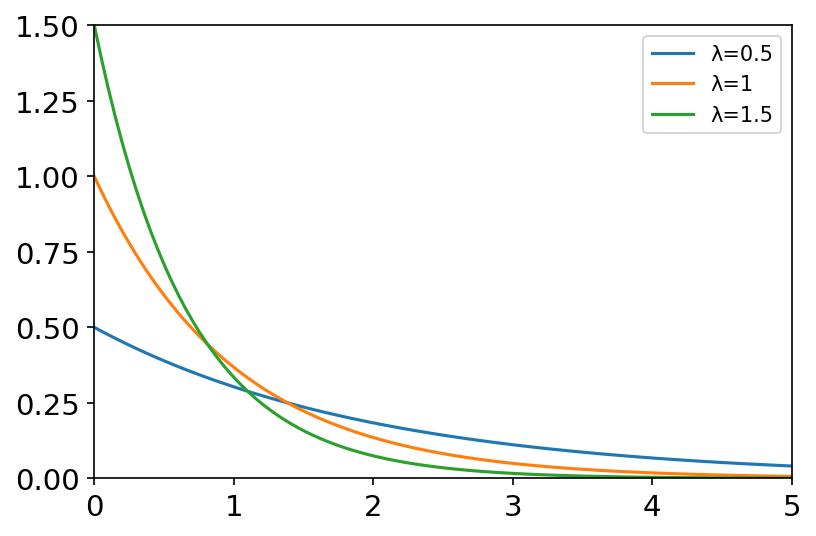
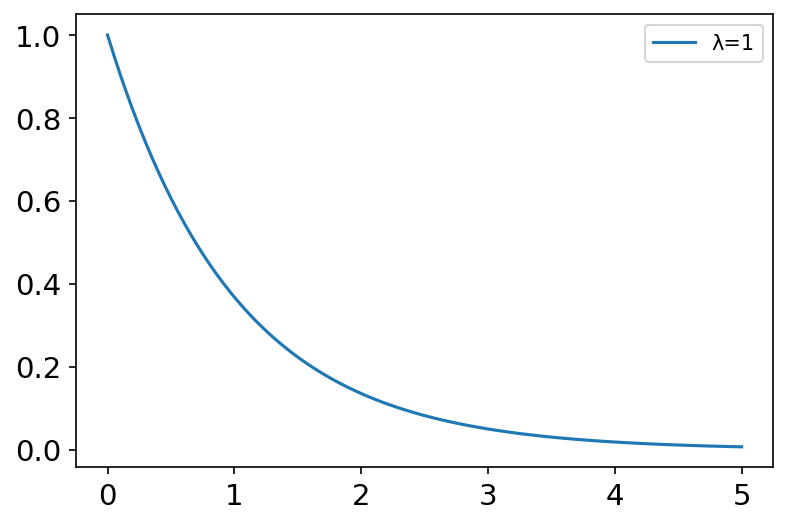
exponential(scale=1.0, size=None) 指数分布是描述泊松过程中的事件之间的时间的概率分布,即事件以恒定平均速率连续且独立地发生的过程。 概率密度函数: f ( x ; λ ) = λ e − λ x , x ≥ 0 f\left( x;\lambda \right) =\lambda e^{-\lambda x},\ x\ge 0 f(x;λ)=λe−λx, x≥0 其中 λ \lambda λ为单位时间发生的次数。 常用于预估电子产品寿命,页面请求间的时间间隔。
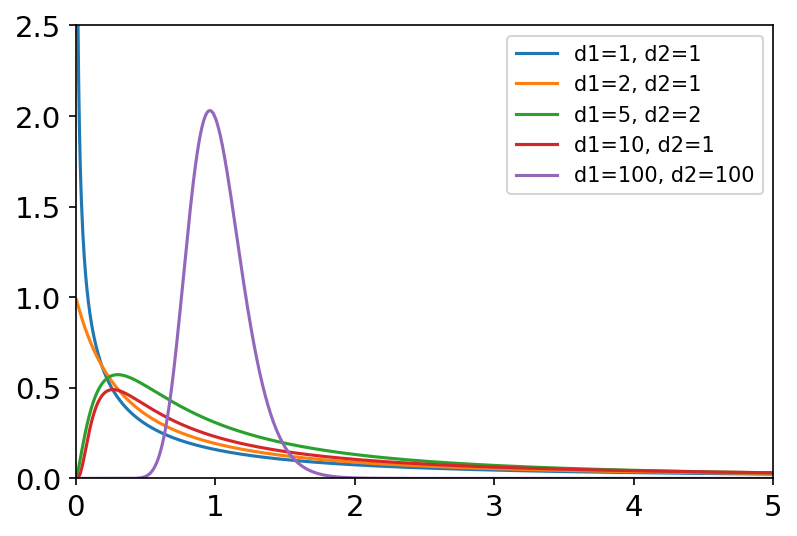
f(dfnum, dfden, size=None) dfnum分子自由度,dfden分母自由度。 F分布是一种非对称连续概率分布,有两个自由度,且位置不可互换。 F分布的随机变量是两个卡方分布除以自由度: U 1 / d 1 U 2 / d 2 = U 1 / U 2 d 1 / d 2 \frac{U_1/d_1}{U_2/d_2}=\frac{U_1/U_2}{d_1/d_2} U2/d2U1/d1=d1/d2U1/U2 概率密度函数: f ( x ; d 1 , d 2 ) = ( d 1 x ) d 1 d 2 d 2 ( d 1 x + d 2 ) d 1 + d 2 x B ( d 1 2 , d 2 2 ) f\left( x;d_1,d_2 \right) =\frac{\sqrt{\frac{\left( d_1x \right) ^{d_1}d_2^{d_2}}{\left( d_1x+d_2 \right) ^{d_1+d_2}}}}{x\text{B}\left( \frac{d_1}{2},\frac{d_2}{2} \right)} f(x;d1,d2)=xB(2d1,2d2)(d1x+d2)d1+d2(d1x)d1d2d2 常用于方差分析,回归方程的显著性检验。
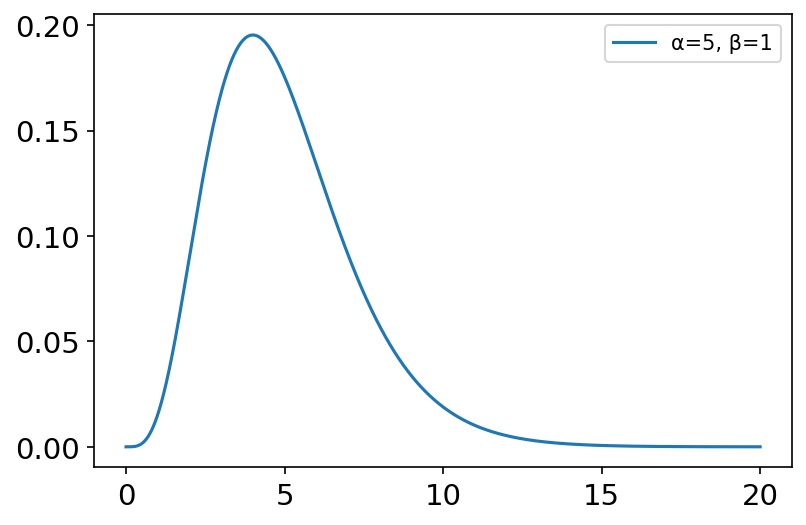
gamma(shape, scale=1.0, size=None) 伽玛分布是一种连续型概率分布, α \alpha α为形状参数, β \beta β为尺度参数。指数分布和卡方分布都是伽玛分布的特例。 假设 X 1 , X 2 , . . . , X n \text{X}_1,\text{X}_2,...,\text{X}_{\text{n}} X1,X2,...,Xn为连续发生事件的等候时间,且这n次等候时间独立,那么这n次等候时间之和Y服从伽玛分布,即 Y ∼ Γ ( α , β ) \text{Y}\thicksim \varGamma \left( \alpha ,\,\,\beta \right) Y∼Γ(α,β),其中 α = n , β = λ \alpha=n,\beta =\lambda α=n,β=λ 概率密度函数: f ( x ) = x ( α − 1 ) β α e ( − β x ) Γ ( α ) , x > 0 f\left( x \right) =\frac{x^{\left( \alpha -1 \right)}\beta ^{\alpha}e^{\left( -\beta x \right)}}{\Gamma \left( \alpha \right)},\ x>0 f(x)=Γ(α)x(α−1)βαe(−βx), x>0 其中
Γ
(
α
)
\Gamma \left( \alpha \right)
Γ(α)为:
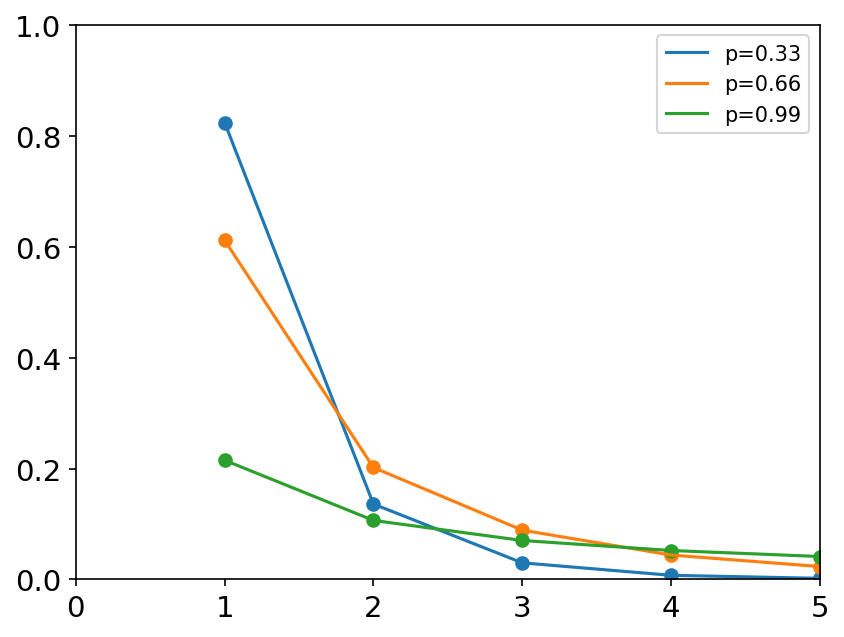
geometric(p, size=None) 几何分布是一种离散型概率分布。在n次伯努利试验中,前k-1次都失败,第k次成功的概率。如不停地掷骰子直到掷到1是一个p=1/6的几何分布。 概率质量函数: f ( x ) = ( 1 − p ) x − 1 p , x = 1 , 2 , . . . f\left( x \right) =\left( 1-p \right) ^{x-1}p,\ x=1,2,... f(x)=(1−p)x−1p, x=1,2,...
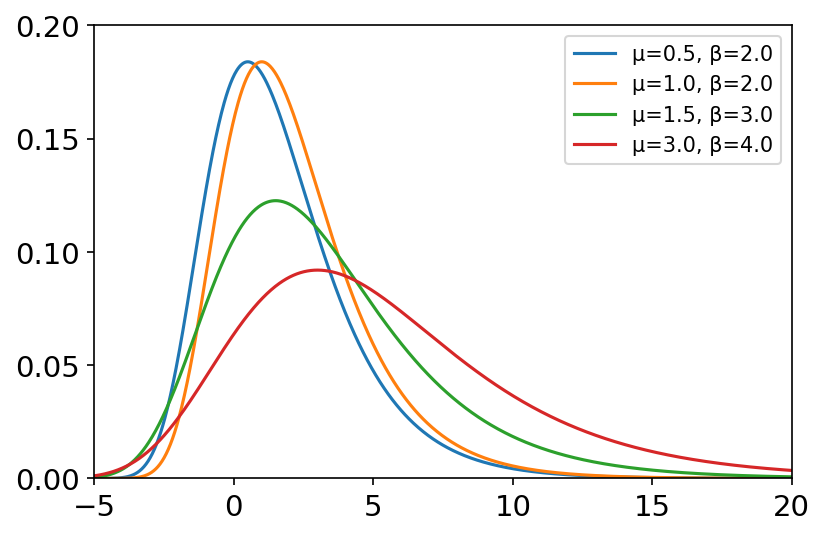
gumbel(loc=0.0, scale=1.0, size=None) 耿贝尔分布是一种连续型概率分布,模拟不同分布的最大值(或最小值)的分布。 μ \mu μ为中心参数, β \beta β为展宽参数。 概率密度函数: f ( x ) = 1 β e − ( z + e − z ) f\left( x \right) =\frac{1}{\beta}e^{-\left( z+e^{-z} \right)} f(x)=β1e−(z+e−z) 其中 z = x − μ β z=\frac{x-\mu}{\beta} z=βx−μ 常用于多年一遇事件,最大风速计算,极端潮位,预测地震洪水或其他自然灾害发生的几率等。
hypergeometric(ngood, nbad, nsample, size=None) 超几何分布是一种离散型概率分布,不放回抽样。 二项分布和几何分布均基于伯努利试验,即每次试验概率不变,而超几何分布的概率会随着每一次试验而改变。 概率质量函数: P ( X = k ) = C M k C N − M n − k C N n , k ∈ { 0 , 1 , 2... min ( n , N ) } P\left( X=k \right) =\frac{C_{M}^{k}C_{N-M}^{n-k}}{C_{N}^{n}},\ k\in \left\{ 0,1,2...\min \left( n,N \right) \right\} P(X=k)=CNnCMkCN−Mn−k, k∈{0,1,2...min(n,N)} 抽到正例数k,正反例总数M,正例总数n,抽样次数N,则: p ( k , M ; n ; N ) = ( n k ) ( M − n N − k ) ( M N ) p\left( k,M;n;N \right) =\frac{\left( \begin{array}{c} n\\ k\\ \end{array} \right) \left( \begin{array}{c} M-n\\ N-k\\ \end{array} \right)}{\left( \begin{array}{c} M\\ N\\ \end{array} \right)} p(k,M;n;N)=(MN)(nk)(M−nN−k) 常用于抽奖、质检。
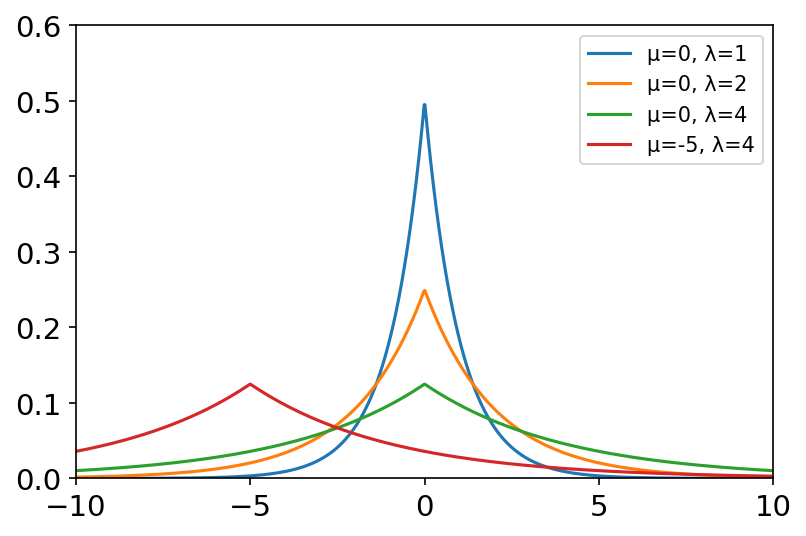
laplace(loc=0.0, scale=1.0, size=None) 拉普拉斯分布与正态分布相似,但峰值更尖锐,尾部更宽。它表示两个独立的、恒等分布的指数随机变量间的差。 概率密度函数: f ( x ; μ , λ ) = 1 2 b exp ( − ∣ x − μ ∣ b ) f\left( x;\mu ,\lambda \right) =\frac{1}{2b}\exp \left( -\frac{|x-\mu |}{b} \right) f(x;μ,λ)=2b1exp(−b∣x−μ∣) 其中, μ \mu μ为位置参数, λ \lambda λ为尺度参数。 常用于建立经济模型和生命科学模型。
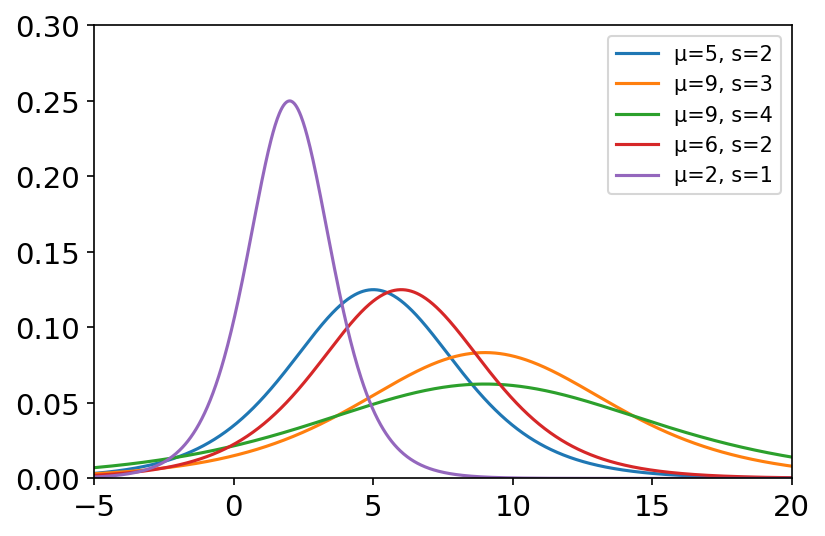
logistic(loc=0.0, scale=1.0, size=None) 逻辑斯谛分布用于极值问题,在流行病学中可作为耿贝尔分布的混合。在国际象棋协会的埃洛等级分系统中,假设每个棋手的表现是一个逻辑斯谛分布的随机变量。 概率密度函数: P ( x ) = e − ( x − μ ) / s s ( 1 + e − ( x − μ ) / s ) 2 P\left( x \right) =\frac{e^{-\left( x-\mu \right) /s}}{s\left( 1+e^{-\left( x-\mu \right) /s} \right) ^2} P(x)=s(1+e−(x−μ)/s)2e−(x−μ)/s 其中, μ \mu μ为位置参数, s s s为尺度参数。 常用于逻辑回归,电子传导,河流流量和降雨量的分布,游戏评级。
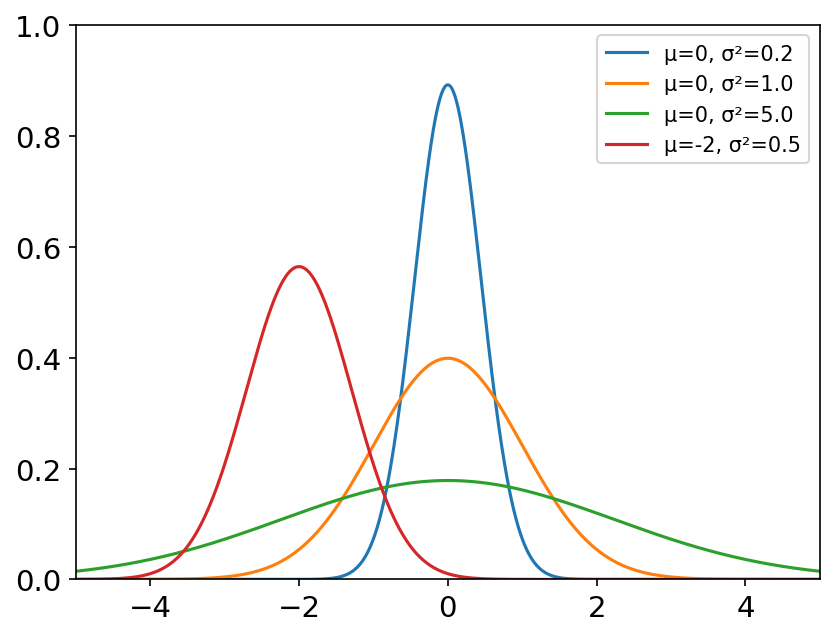
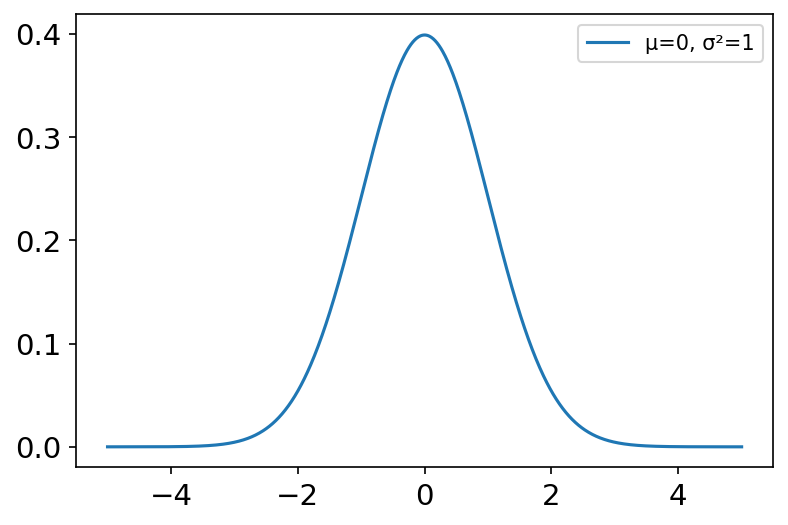
normal(loc=0.0, scale=1.0, size=None) 正态分布是一种连续型概率分布, μ \mu μ为位置参数, σ \sigma σ为尺度参数。正态分布在自然界中很常见,如身高、寿命、考试成绩等,属于各种因素相加对结果的影响。 若随机变量 X X X服从一个数学期望为 μ \mu μ,方差为 σ 2 \sigma ^2 σ2的正态分布,记为 N ( μ , σ 2 ) N\left( \mu ,\sigma ^2 \right) N(μ,σ2) μ = 0 , σ = 1 \mu =0, \sigma =1 μ=0,σ=1的正态分布是标准正态分布。 常用于频数分布,估计参考值范围。
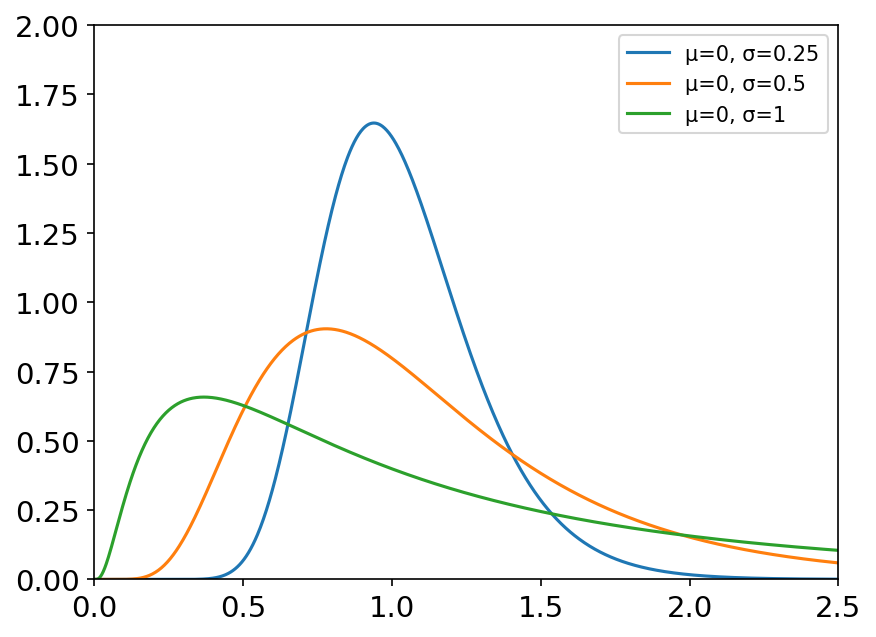
lognormal(mean=0.0, sigma=1.0, size=None) 对数正态分布与正态分布十分相似,不过各种因素对结果的影响不是相加,而是相乘。如财富分配,图像有条长尾。 如果 Y Y Y是正态分布的随机变量,则 e Y e^Y eY为对数正态分布;同样,如果 X {X} X是对数正态分布,则 ln X {\ln X} lnX为正态分布。 概率密度函数: f ( x ; μ , σ ) = 1 σ x 2 π e − ( ln x − μ ) 2 / 2 σ 2 f\left( x;\mu ,\sigma \right) =\frac{1}{\sigma x\sqrt{2\pi}}e^{-\left( \ln x-\mu \right) ^2/2\sigma ^2} f(x;μ,σ)=σx2π 1e−(lnx−μ)2/2σ2 其中, μ \mu μ为原正态分布的均值, σ \sigma σ为原正态分布的标准差。 常用于描述增长率。
logseries(p, size=None) 对数分布是一种离散型概率分布,也称对数级数分布。 概率质量函数: f ( k ) = − p k k log ( 1 − p ) f\left( k \right) =-\frac{p^k}{k\log \left( 1-p \right)} f(k)=−klog(1−p)pk 常用于物种丰富度,群体遗传学。
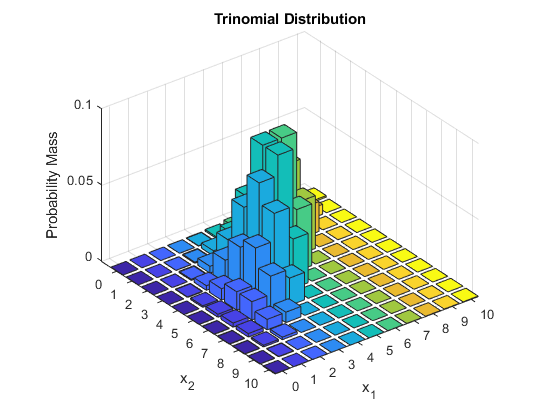
multinomial(n, pvals, size=None) 多项分布是二项分布的多元推广,如扔骰子。 概率质量函数: f ( k ) = n ! x 1 ! ⋯ x k ! p 1 x 1 ⋯ p k x k f\left( k \right) =\frac{n!}{x_1!\cdots x_k!}p_{1}^{x_1}\cdots p_{k}^{x_k} f(k)=x1!⋯xk!n!p1x1⋯pkxk PS:scipy.stats.multinomial的项个数为2时和scipy.stats.binom的结果数值有微小区别。
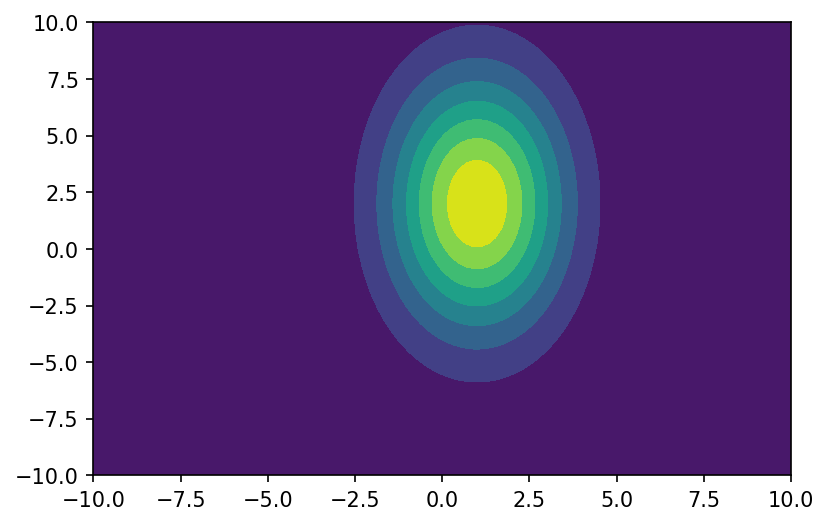
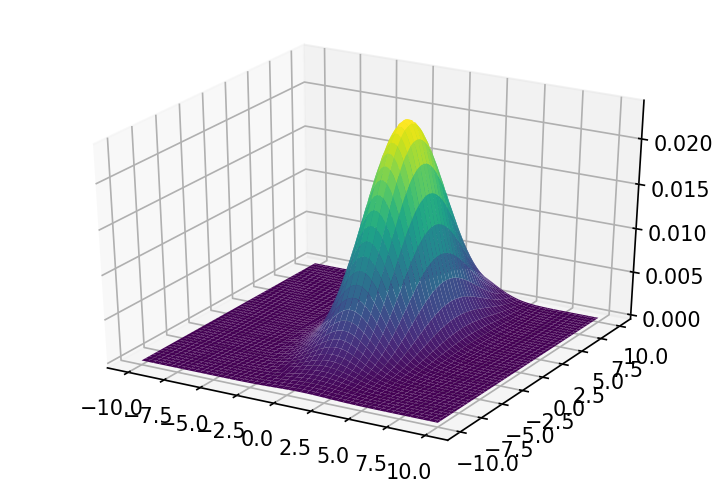
multivariate_normal(mean, cov, size=None, check_valid='warn', tol=1e-8) 多元正态分布是正态分布的高维推广,图像由均值和协方差矩阵决定。 概率密度函数: f ( x ) = 1 ( 2 π ) k det ∑ exp ( − 1 2 ( x − μ ) T ∑ − 1 ( x − μ ) ) f\left( x \right) =\frac{1}{\sqrt{\left( 2\pi \right) ^k\det \sum{}}}\exp \left( -\frac{1}{2}\left( x-\mu \right) ^T\sum{^{-1}\left( x-\mu \right)} \right) f(x)=(2π)kdet∑ 1exp(−21(x−μ)T∑−1(x−μ)) 其中 μ \mu μ是均值, ∑ \sum ∑是协方差矩阵, k k k是空间维度。
negative_binomial(n, p, size=None) 负二项分布是一种离散型概率分布,成功即失败。持续到n次成功,n为正整数时,又称帕斯卡分布。 如果一个人重复掷一个骰子,直到第三次出现一个“1”,那么在第三个“1”之前出现的非“1”的数目的概率分布就是一个负的二项分布。 概率质量函数: P ( N ; n , p ) = Γ ( N + n ) N ! Γ ( n ) p n ( 1 − p ) N P\left( N;n,p \right) =\frac{\Gamma \left( N+n \right)}{N!\Gamma \left( n \right)}p^n\left( 1-p \right) ^N P(N;n,p)=N!Γ(n)Γ(N+n)pn(1−p)N
noncentral_chisquare(df, nonc, size=None) 概率密度函数: P ( x ; d f , n o n c ) = ∑ i = 0 ∞ e − n o n c / 2 ( n o n c / 2 ) i i ! P Y d f + 2 i ( x ) P\left( x;df,nonc \right) =\sum_{i=0}^{\infty}{\frac{e^{-nonc/2}\left( nonc/2 \right) ^i}{i!}P_{Y_{df+2i}}\left( x \right)} P(x;df,nonc)=∑i=0∞i!e−nonc/2(nonc/2)iPYdf+2i(x) 常用于概率比测试。
noncentral_f(dfnum, dfden, nonc, size=None)
pareto(a, size=None) 帕累托分布(II型)在现实世界的许多问题中都很有用,经典的二八定律。 概率密度函数: P ( X > x ) = ( x x min ) − k \text{P}\left( X>x \right) =\left( \frac{x}{x_{\min}} \right) ^{-k} P(X>x)=(xminx)−k 常用于经济学领域如财富分配,除外它还被称为布拉德福分布,用于保险、web页面访问统计、油田大小、项目下载频率,即厚尾分布。
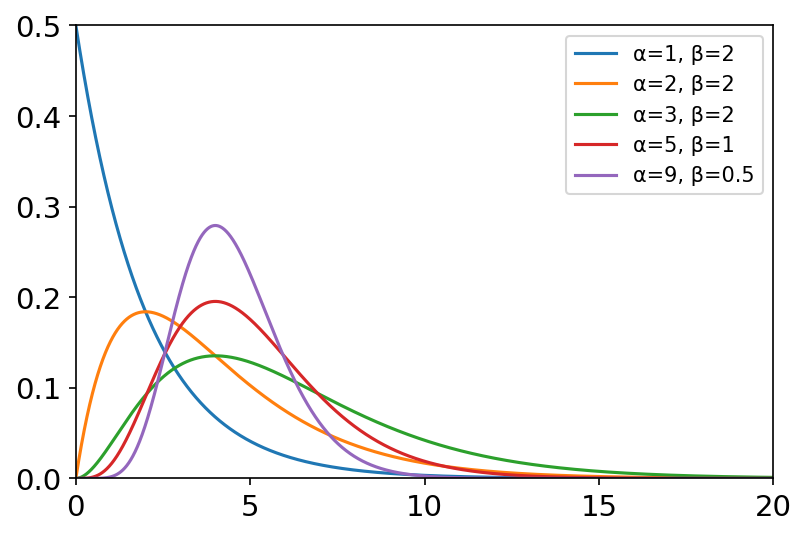
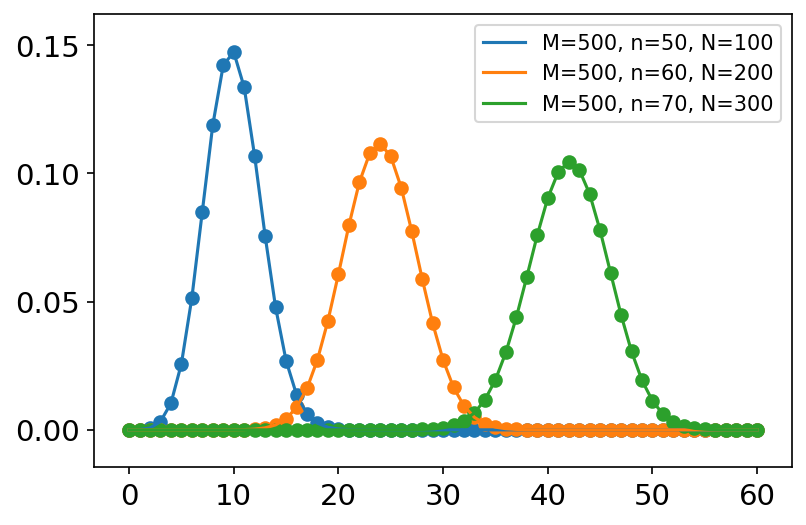
poisson(lam=1.0, size=None) 泊松分布是 N N N非常大的情况下二项分布的极限。 概率质量函数: f ( k ) = e − μ μ k k ! f\left( k \right) =\frac{e^{-\mu}\mu ^k}{k!} f(k)=k!e−μμk μ \mu μ是单位时间(或单位面积)内随机事件的平均发生率。 常用于描述单位时间(或空间)内随机事件发生的次数。如汽车站台的候客人数,机器出现的故障数,自然灾害发生的次数,一块产品上的缺陷数,显微镜下单位分区内的细菌数等。
power(a, size=None) 概率密度函数: P ( x ; a ) = a x a − 1 , 0 ≤ x ≤ 1 , a > 0 P\left( x;a \right) =ax^{a-1},0\le x\le 1,a>0 P(x;a)=axa−1,0≤x≤1,a>0
rayleigh(scale=1.0, size=None) 当一个随机二维向量的两个分量呈独立的、有着相同的方差的正态分布时,这个向量的模呈瑞利分布。 概率密度函数: f ( x ) = x σ 2 e − x 2 2 σ 2 , x > 0 f\left( x \right) =\frac{x}{\sigma ^2}e^{-\frac{x^2}{2\sigma ^2}},x>0 f(x)=σ2xe−2σ2x2,x>0 常用于无线网络,信号处理领域。
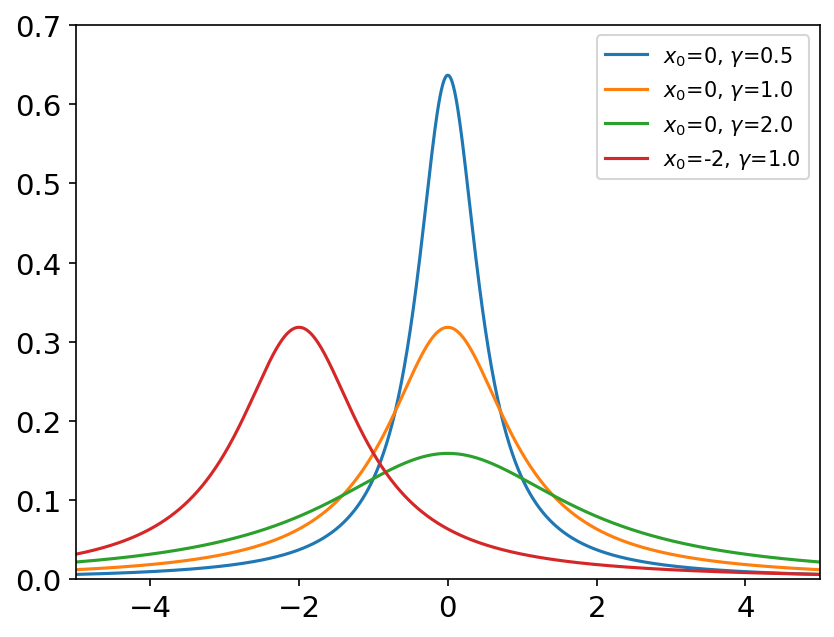
standard_cauchy(size=None) 柯西分布是一个数学期望不存在的连续型概率分布。 概率密度函数: P ( x ; x 0 , γ ) = 1 π γ [ 1 + ( x − x 0 γ ) 2 ] P\left( x;x_0,\gamma \right) =\frac{1}{\pi \gamma \left[ 1+\left( \frac{x-x_0}{\gamma} \right) ^2 \right]} P(x;x0,γ)=πγ[1+(γx−x0)2]1 x 0 = 0 , γ = 1 x_0=0, \gamma=1 x0=0,γ=1的柯西分布是标准柯西分布。
standard_exponential(size=None, dtype='d', method='zig', out=None) 即尺度参数为1的指数分布。 print(rng.standard_exponential(size=3)) # [1.9475 0.1347515 0.79339464]
standard_gamma(shape, size=None, dtype='d', out=None) 即尺度参数为1的伽马分布。
standard_normal(size=None, dtype='d', out=None) 即均值为0标准差为1的正态分布。
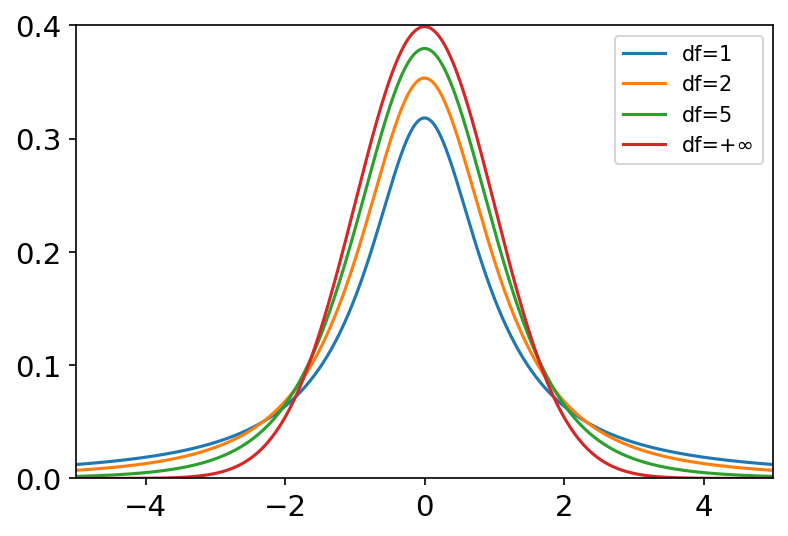
standard_t(df, size=None) 概率密度函数: P ( x , d f ) = Γ ( d f + 1 2 ) π d f Γ ( d f 2 ) ( 1 + x 2 d f ) − ( d f + 1 ) / 2 P\left( x,df \right) =\frac{\Gamma \left( \frac{df+1}{2} \right)}{\sqrt{\pi df}\Gamma \left( \frac{df}{2} \right)}\left( 1+\frac{x^2}{df} \right) ^{-\left( df+1 \right) /2} P(x,df)=πdf Γ(2df)Γ(2df+1)(1+dfx2)−(df+1)/2 t检验假设数据服从正态分布,检验样本均值是否是真实均值。 t分布用于根据小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。
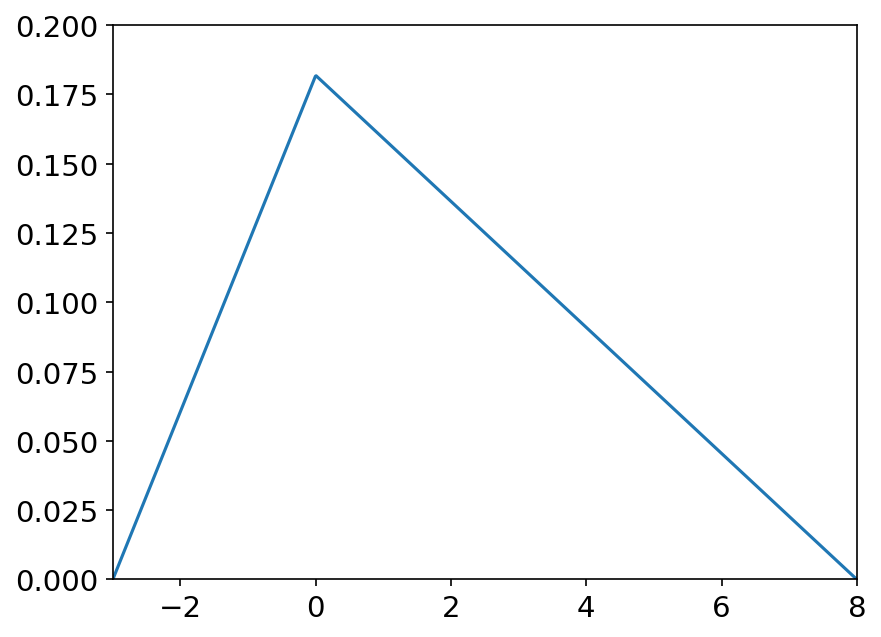
triangular(left, mode, right, size=None) 三角形分布是低限为l,众数为m,上限为r的连续概率分布。 概率密度函数: P ( x ; l , m , r ) = { 2 ( x − l ) ( r − l ) ( m − l ) , l ≤ x ≤ m 2 ( r − x ) ( r − l ) ( r − m ) , m ≤ x ≤ r P\left( x;l,m,r \right) =\left\{ \begin{array}{l} \frac{2\left( x-l \right)}{\left( r-l \right) \left( m-l \right)},l\le x\le m\\ \frac{2\left( r-x \right)}{\left( r-l \right) \left( r-m \right)},m\le x\le r\\ \end{array} \right. P(x;l,m,r)={(r−l)(m−l)2(x−l),l≤x≤m(r−l)(r−m)2(r−x),m≤x≤r 常用于商务决策和项目管理。
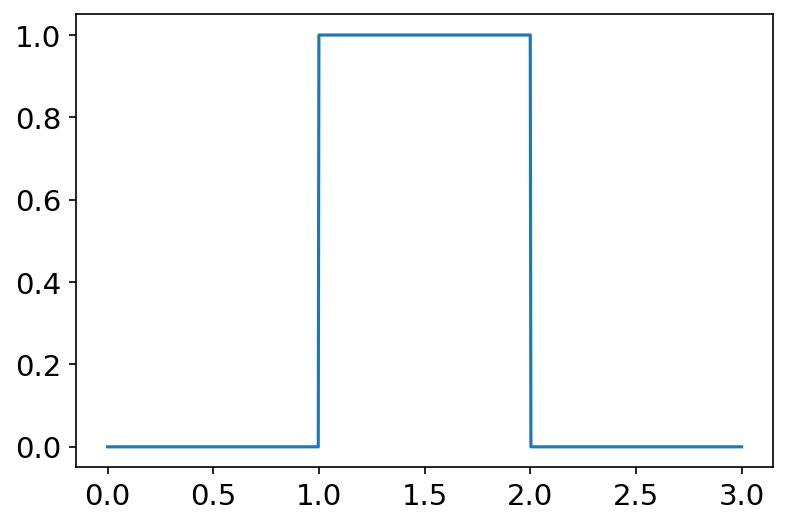
uniform(low=0.0, high=1.0, size=None) 概率密度函数:
p
(
x
)
=
1
b
−
a
p\left( x \right) =\frac{1}{b-a}
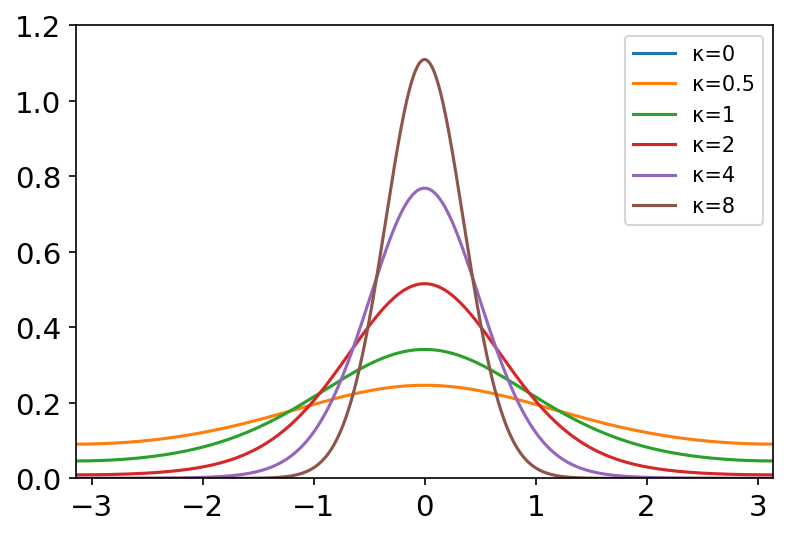
p(x)=b−a1 vonmises(mu, kappa, size=None) 概率密度函数: f ( x ; u , κ ) = e κ cos ( x − μ ) 2 π I 0 ( κ ) f\left( x;u,\kappa \right) =\frac{e^{\kappa}\cos \left( x-\mu \right)}{2\pi I_0\left( \kappa \right)} f(x;u,κ)=2πI0(κ)eκcos(x−μ)
wald(mean, scale, size=None) 逆高斯分布描述布朗运动达到一个固定的正水平所需要的时间分布。 概率密度函数: f ( x ; μ , λ ) = λ 2 π x 3 exp ( − λ ( x − μ ) 2 2 μ 2 x ) f\left( x;\mu ,\lambda \right) =\sqrt{\frac{\lambda}{2\pi x^3}}\exp \left( -\frac{\lambda \left( x-\mu \right) ^2}{2\mu ^2x} \right) f(x;μ,λ)=2πx3λ exp(−2μ2xλ(x−μ)2) 常用于寿命试验,卫生科学,精算学,生态学,昆虫学。 print(rng.wald(mean=3, scale=2, size=3)) # [ 0.23712345 2.06903186 26.01138062] 韦伯分布weibull(a, size=None) 概率密度函数: p ( x ) = a λ ( x λ ) a − 1 e − ( x / λ ) a p\left( x \right) =\frac{a}{\lambda}\left( \frac{x}{\lambda} \right) ^{a-1}e^{-\left( x/\lambda \right) ^a} p(x)=λa(λx)a−1e−(x/λ)a a = 1 a=1 a=1时,韦伯分布为指数分布。 a = 2 a=2 a=2时,韦伯分布为瑞利分布。 常用于可靠性分析和寿命检验。
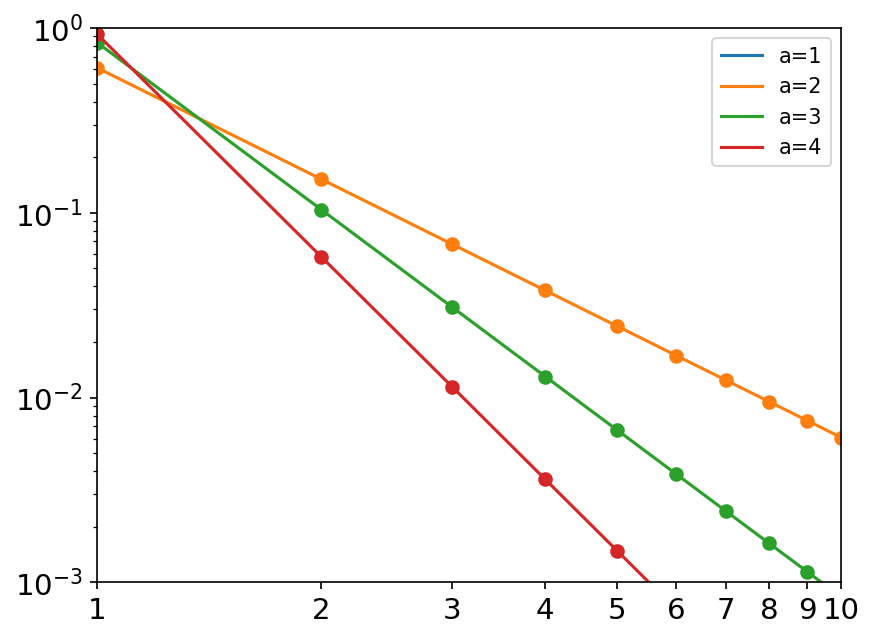
zipf(a, size=None) 概率质量函数: p ( x ) = x − a ζ ( a ) p\left( x \right) =\frac{x^{-a}}{\zeta \left( a \right)} p(x)=ζ(a)x−a 其中 ζ \zeta ζ是黎曼函数。 齐夫定律表述为:在自然语言的语料库里,一个单词出现的频率与它在频率表里的排名成反比。 常用于语言学,情报学,地理学,经济学。
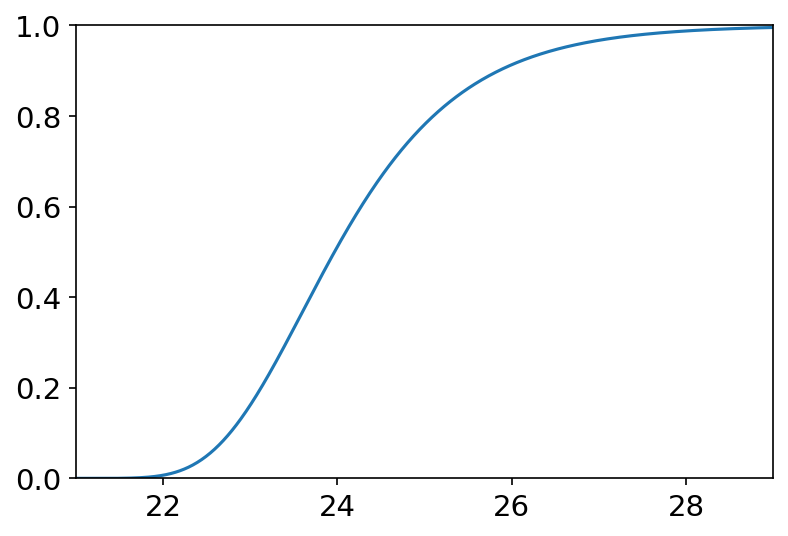
导入 import numpy as np from scipy import stats import matplotlib.pyplot as plt %matplotlib inline rng = np.random.default_rng() # 构造一个默认位生成器(PCG64)术语 x = np.linspace(-1.5, 1.5, 100) labels = [] f_list = [stats.norm.pdf, stats.norm.cdf, stats.norm.ppf] plt.figure(dpi=150) for f in f_list: labels.append(f) y = f(x, loc=0, scale=0.5) #标准正态分布,均值0,标准差0.5 plt.tick_params(axis='both', labelsize=14) plt.plot(x, y) plt.legend(labels=['pdf', 'cdf', 'ppf'], loc='best')
整数 x = rng.integers(low=0, high=10, size=1000, endpoint=True) # [0,10]的1000个随机整数 y = np.zeros(1000) plt.yticks([]) #去掉y轴 plt.axis([-2, 12, -1, 1]) # X∈[-2,12], Y∈[-1,1] ax = plt.gca() ax.spines['top'].set_visible(False) ax.spines['left'].set_visible(False) ax.spines['right'].set_visible(False) plt.tick_params(axis='both', labelsize=14) # 改字体 plt.plot(x, y)
卡方分布 x = np.linspace(0, 15, 100) labels = [] df_list = [1, 2, 4, 6, 11] plt.figure(dpi=150) for df in df_list: labels.append('df={}'.format(df)) y = stats.chi2.pdf(x, df) plt.axis([0, 14, 0, 0.5]) plt.tick_params(axis='both', labelsize=14) plt.plot(x, y) plt.legend(labels=labels, loc='best')
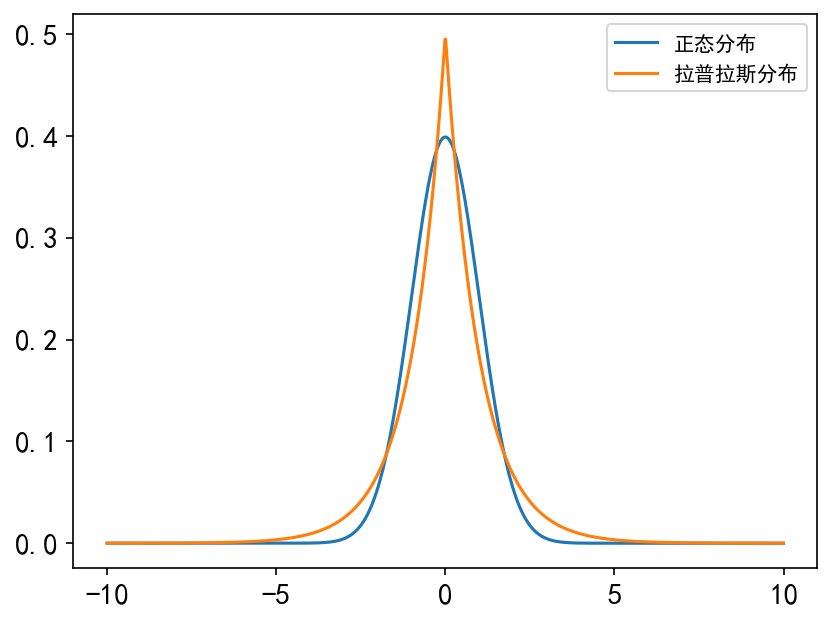
拉普拉斯分布(双指数分布) x = np.linspace(-10, 10, 1000) labels = [] f_list = [stats.norm.pdf, stats.laplace.pdf] plt.figure(dpi=150) for f in f_list: labels.append(f) y = f(x, loc=0, scale=1) plt.tick_params(axis='both', labelsize=14) plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False plt.plot(x, y) plt.legend(labels=['正态分布', '拉普拉斯分布'], loc='best') plt.rcdefaults() # 重置默认样式
参考Multinomial probability density function 多元正态分布 x = np.linspace(-10, 10, 100) y = np.linspace(-10, 10, 100) x, y = np.meshgrid(x, y) pos = np.dstack((x, y)) z = stats.multivariate_normal.pdf(pos, mean=[1, 2], cov=[[3, 0], [0, 15]]) plt.figure(dpi=150) plt.contourf(x, y, z)
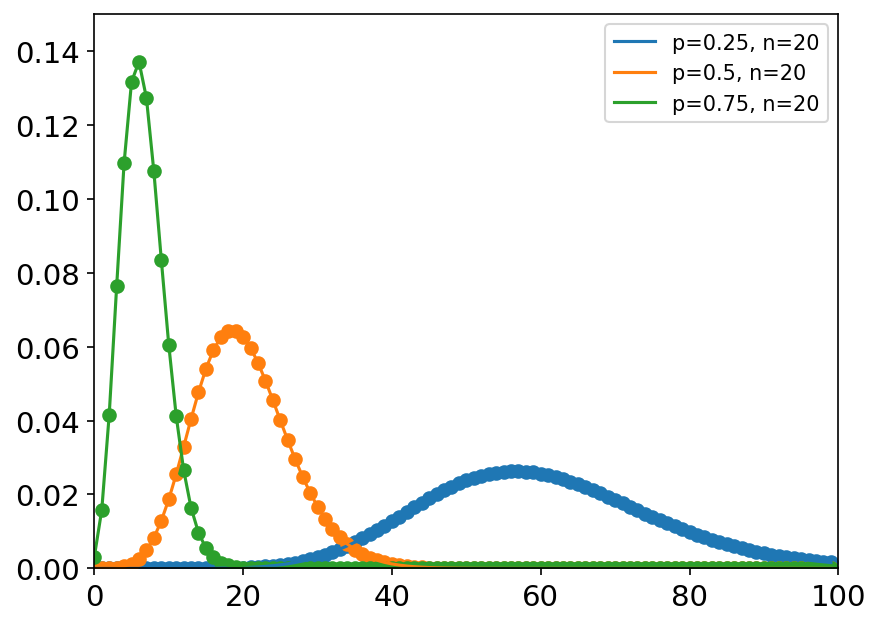
负二项分布 x = np.arange(100) labels = [] p_list = [0.25, 0.5, 0.75] n_list = [20, 20, 20] plt.figure(dpi=150) for p, n in zip(p_list, n_list): labels.append('p={}, n={}'.format(p, n)) y = stats.nbinom.pmf(x, n=n, p=p) plt.axis([0, 100, 0, 0.15]) plt.tick_params(axis='both', labelsize=14) plt.scatter(x, y) plt.plot(x, y) plt.legend(labels=labels, loc='best')
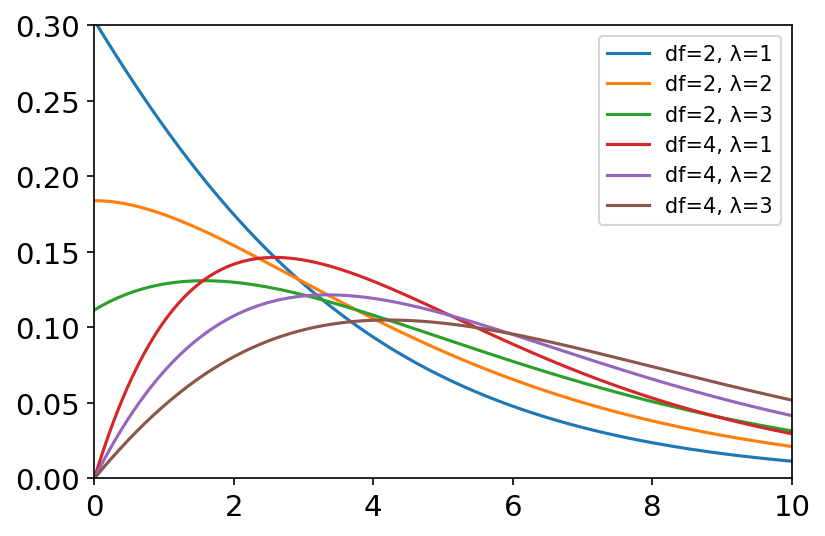
非中心F分布 x = np.linspace(0, 10, 1000) labels = [] df_list = [5, 10] lambda_list = [0.000001, 1, 5, 10, 20] # λ为0时则为F分布 plt.figure(dpi=150) for la in lambda_list: labels.append('λ={}'.format(la)) y = stats.ncf.pdf(x, dfn=5, dfd=10, nc=la) # 分子自由度和分母自由度分别为5、10 plt.axis([0, 10, 0, 0.8]) plt.tick_params(axis='both', labelsize=14) plt.plot(x, y) plt.legend(labels=labels, loc='best')
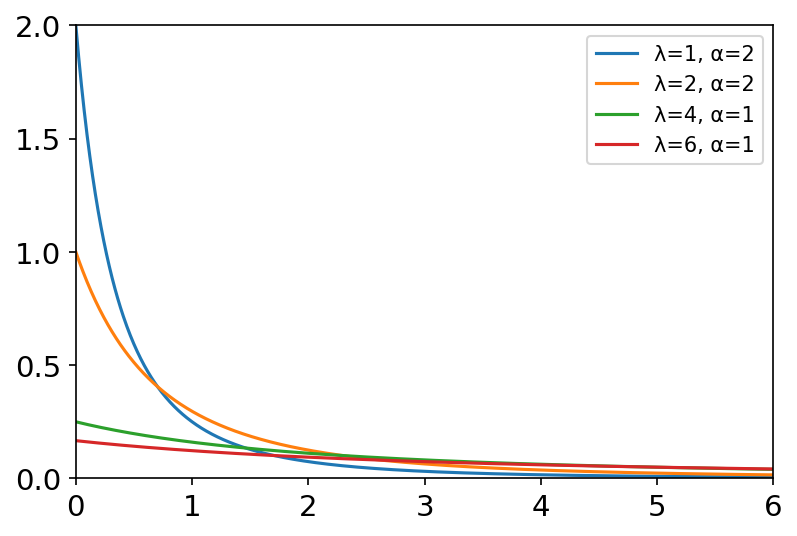
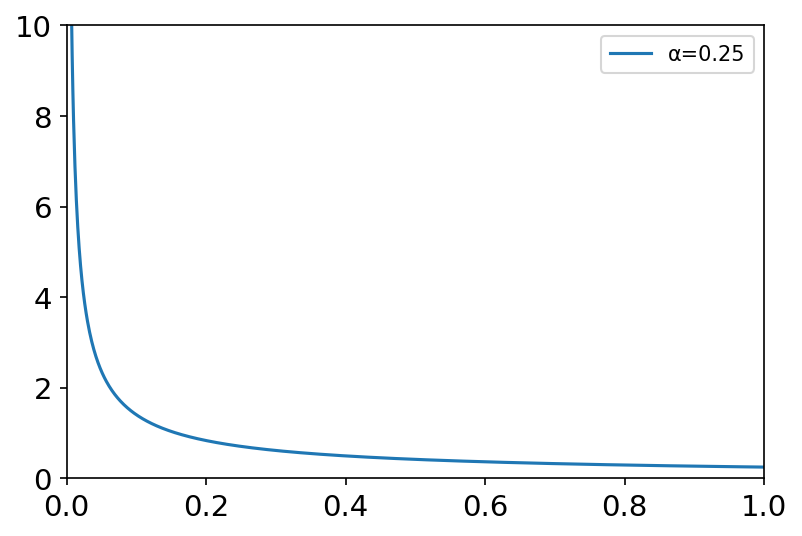
帕累托分布II型(Lomax Distribution) x = np.linspace(0, 6, 1000) labels = [] lambda_list = [1, 2, 4, 6] alpha_list = [2, 2, 1, 1] plt.figure(dpi=150) for la, alpha in zip(lambda_list, alpha_list): labels.append('λ={}, α={}'.format(la, alpha)) y = stats.lomax.pdf(x, c=alpha, scale=la) plt.axis([0, 6, 0, 2]) plt.tick_params(axis='both', labelsize=14) plt.plot(x, y) plt.legend(labels=labels, loc='best')
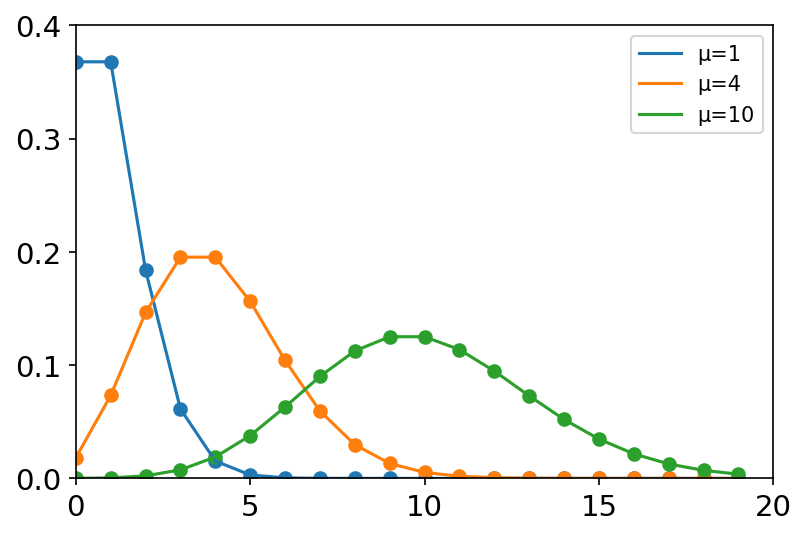
泊松分布 x = np.arange(20) labels = [] mu_list = [1, 4, 10] plt.figure(dpi=150) for mu in mu_list: labels.append('μ={}'.format(mu)) y = stats.poisson.pmf(x, mu=mu) plt.axis([0, 20, 0, 0.4]) plt.tick_params(axis='both', labelsize=14) plt.scatter(x, y) plt.plot(x, y) plt.legend(labels=labels, loc='best')
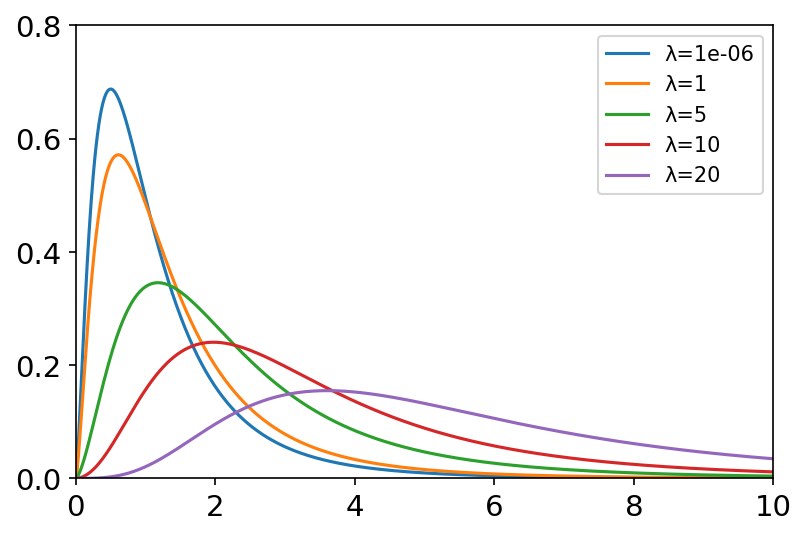
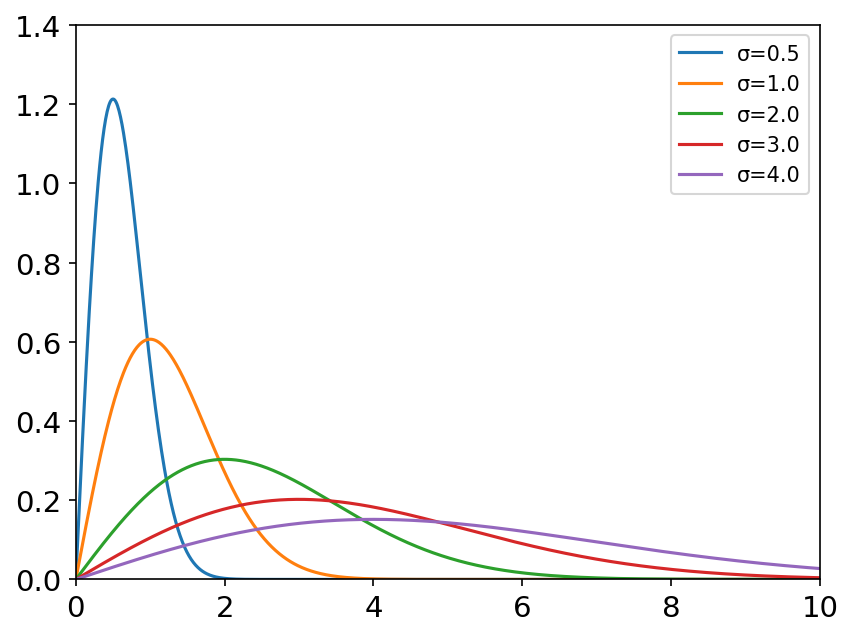
瑞利分布 x = np.linspace(0, 10, 1000) labels = [] sigma_list = [0.5, 1.0, 2.0, 3.0, 4.0] plt.figure(dpi=150) for sigma in sigma_list: labels.append('σ={}'.format(sigma)) y = stats.rayleigh.pdf(x, scale=sigma) plt.axis([0, 10, 0, 1.4]) plt.tick_params(axis='both', labelsize=14) plt.plot(x, y) plt.legend(labels=labels, loc='best')
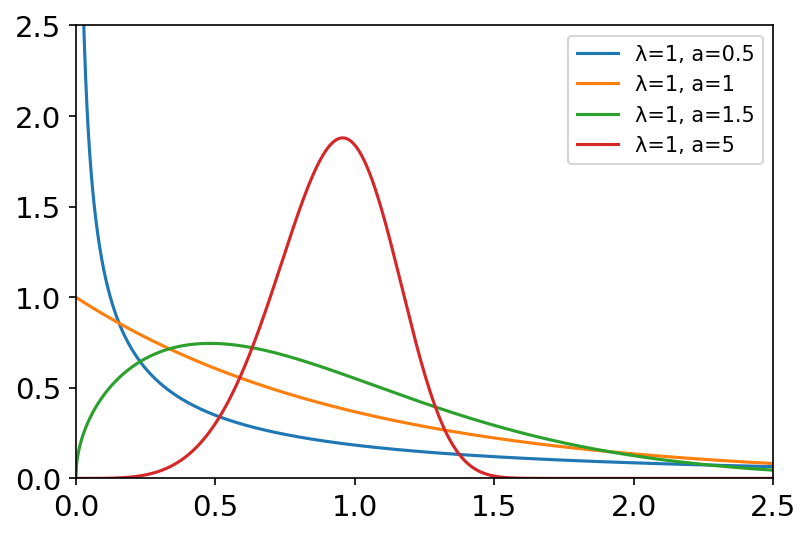
韦伯分布 x = np.linspace(0, 2.5, 1000) labels = [] lambda_list = [1, 1, 1, 1] a_list = [0.5, 1, 1.5, 5] plt.figure(dpi=150) for la, a in zip(lambda_list, a_list): labels.append('λ={}, a={}'.format(la, a)) y = stats.weibull_min.pdf(x, c=a, scale=la) plt.axis([0, 2.5, 0, 2.5]) plt.tick_params(axis='both', labelsize=14) plt.plot(x, y) plt.legend(labels=labels, loc='best')
|


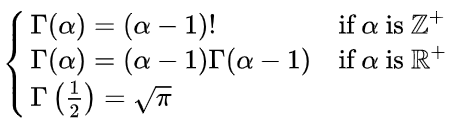
 浮点数
浮点数 洗牌
洗牌【本文地址】
今日新闻 |
推荐新闻 |