Python 分析台湾省台北市房地产价格报告 |
您所在的位置:网站首页 › 台北市区房价排名 › Python 分析台湾省台北市房地产价格报告 |
Python 分析台湾省台北市房地产价格报告
|
文章目录
项目概述分析目标数据理解数据清洗异常值处理描述性数据分析数据整理回归分析结论
项目概述
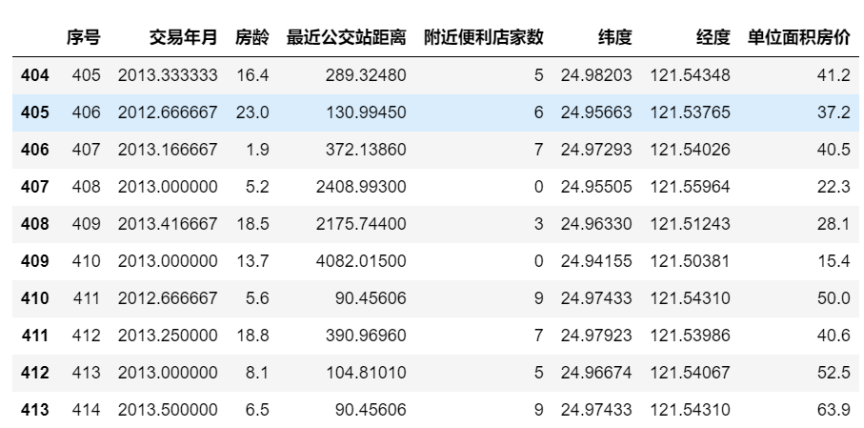
本项目旨在分析台湾省台北市房地产价格。我们将使用台北房产数据集进行数据清洗、整理、分析和可视化。通过对不同的解释变量的分析,我们将探究对房地产价格的影响因素,并对单位面积房价进行预测。最后,我们将根据分析结果得出结论,并对房地产市场进行评价。 分析目标 清洗数据,处理缺失值和异常值,确保数据质量。对数据进行描述性统计分析,了解数据分布情况。利用回归分析方法研究影响房价的因素。对单位面积房价进行预测,预测未来房价的变化趋势。 5.根据分析结果,得出结论并给出改进建议。 数据集介绍 我国台湾省台北市房地产价格分析 1、数据集名称:台北房产数据集.xlsx 2、数据集介绍 台北房产数据集的数据是来自于新台北市新店区的房产信息,文件格式为xlsx,共有414 条记录,NA代表缺失数据,有6个解释变量,分别为: X1=交易年月(比如,2013.250表示2013年3月,2013.500表示2013年6月,依次类推)X2=房龄(单位:年)X3=最近公交站距离(单位:米)X4=附近便利店家数(整数)X5=地理坐标纬度(单位:度)、X6=地理坐标经度(单位:度) ‘’ 被解释变量:Y=单位面积房价(每坪价格,新台币计,1坪=3.3平米) 数据理解读入了一个名为“台北房产数据集.xlsx”的Excel文件,并将其存储在一个名为df的Pandas数据框中。然后我们为数据框的列赋予了名称,并使用df.info()命令查看了数据框的基本信息 输出前10行数据
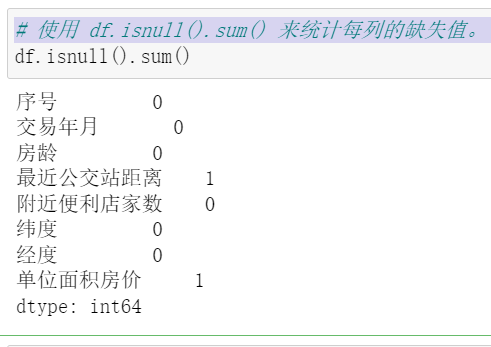
识别并输出数据集中所有变量的类型 df.dtypes用于获取数据框中所有列的数据类型,并以Series的形式输出。 “序号”:整数类型(int64);“交易年月”:浮点数类型(float64);“房龄”:浮点数类型(float64);“最近公交站距离”:浮点数类型(float64);“附近便利店家数”:整数类型(int64);“纬度”:浮点数类型(float64);“经度”:浮点数类型(float64);“单位面积房价”:浮点数类型(float64)。 数据清洗缺失值处理,使用 df.isnull().sum() 来统计每列的缺失值。
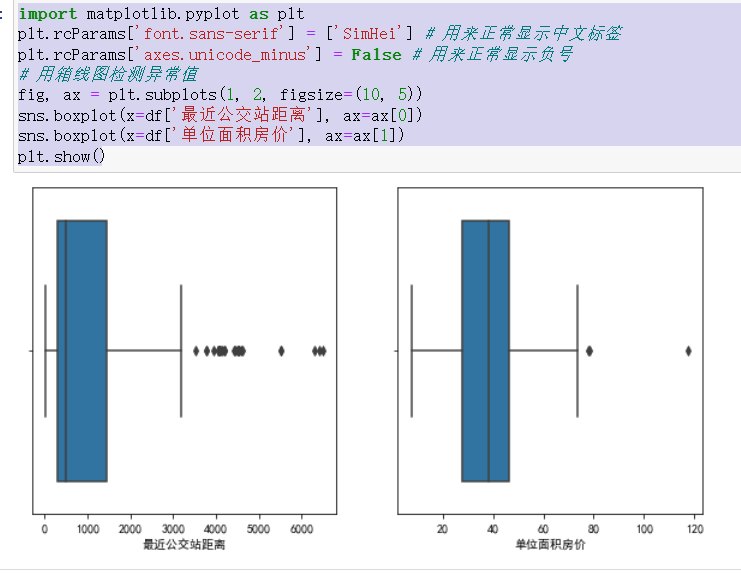
我选择使用平均值补缺,选择使用平均值补缺的方式处理缺失值的原因是: 平均值具有代表性:平均值可以代表数据的一个中心值,是数据的平均分布情况。 平均值容易计算:平均值可以通过简单的计算方法(把所有数据相加再除以数据数量)得到。 平均值可以有效地补缺:在数据缺失较少的情况下,使用平均值补缺可以有效地保证数据分布的一致性。因此,在数据缺失较少的情况下,使用平均值补缺是一种简单有效的方法。但是,在数据缺失较多或数据分布不均匀的情况下,使用平均值补缺的效果可能不够理想。 箱线图是一种用于检测异常值的图形,它通过显示数据的分布和离群点的情况来识别异常值。在箱线图中,数据点分布在箱子内,而箱子的上限为上四分位数加上1.5倍的四分位距,下限为下四分位数减去1.5倍的四分位距,四分位数分别是25%、50%、75%的数据点。如果数据点落在箱子外,那么它们将被视为异常值。 在上面的代码中,我们使用了seaborn库中的boxplot函数,并通过设置参数x来选择要检测的列。最后,我们使用plt.show()函数显示箱线图。 上面的代码实现了将“最近公交站距离”和“单位面积房价”两列的异常值处理为该列的平均值的过程。 首先,程序通过 quantile 函数计算出每列的四分位数,然后计算出每列的四分位数范围(IQR)。在这个过程中,Q1 代表第一四分位数,Q3 代表第三四分位数。接下来,程序通过 1.5 * IQR 计算出异常值边界。异常值被定义为比第三四分位数大 1.5 倍四分位数范围的数或比第一四分位数小 1.5 倍四分位数范围的数。最后,程序通过 pandas 的 loc 函数将每列中超出异常值边界的数值替换为该列的平均值。 按照同样的方法处理附近便利店家数和房龄,其中房龄不存在异常值,附近便利店家数存在一个很大的异常值,选择使用众数来替换了。 描述性数据分析
对房龄,最近公交站距离,附近便利店家数,交易年月和单位面积房价都做了散点图。 根据散点图的分析,我们可以发现以下几点: 1.房龄与单位面积房价关系不明显。从图中可以看出,房龄与单位面积房价之间没有明显的相关性。 2.最近公交站距离与单位面积房价的关系也不明显。从图中可以看出,最近公交站距离与单位面积房价之间没有明显的相关性。 3.附近便利店家数与单位面积房价的关系明显。从图中.附近便利店家数和单位面积有可能是存在正相关的关系。 4.交易年月与单位面积房价关系不明显。从图中可以看出,交易年月与单位面积房价之间没有明显的相关性。 于是统计不同的附近便利店家数单位面积房价的平均值 附近便利店家数 count mean 0 67 26.462687 1 46 30.110638 2 24 31.412500 3 46 29.619334 4 32 37.631250 5 67 44.729851 6 37 46.951351 7 30 43.893333 8 30 44.696667 9 25 48.519148 10 10 48.430000 首先,从上面的统计结果中我们可以看出,单位面积房价与附近便利店家数之间存在一定的相关性。随着附近便利店家数的增加,单位面积房价的平均值也在增加。这说明附近便利店家数可能是影响房价的重要因素。 数据整理(1)根据数据清洗结果对数据集转化并生成新的数据集 对于删除有缺失值的行,使用了dropna()方法,参数how='any’表示当该行存在任何一个缺失值时,将该行删除。对于删除某一列,使用了drop()方法,参数columns = [“序号”] 表示删除名为"序号"的列。最后,将处理完的数据赋值给df_cleaned,生成了一个新的数据集。 (2)数据标准化 上面代码实现了对数据进行标准化的处理。首先,我们通过导入 StandardScaler 类来创建一个标准化的对象,然后使用 fit_transform 函数对 df_cleaned 进行标准化处理,最后我们将处理后的数据转换为一个数据框并命名为 df_scaled。标准化处理的目的是将数据缩放到同一尺度上,方便后续分析比较。 (3)数据集随机分割2/3用于训练,1/3用于测试 这段代码是将变换并处理后的数据集(df_scaled)随机分割成两份,其中2/3作为训练数据集,1/3作为测试数据集。 使用train_test_split函数从df_scaled中随机选取33.3%的数据作为测试数据,其余数据作为训练数据,random_state设置为0,保证每次随机分割的数据集相同。 最后,通过输出数据集的大小,确保分割是正确的。 回归分析这是一个使用statsmodels库建立的线性回归模型,通过训练数据对单位面积房价进行预测。在建立模型之前,需要对自变量进行标准化处理,并在自变量前添加常数项。最终,通过输出的回归分析结果,可以了解各个自变量对因变量的影响程度,以及模型的整体拟合情况。
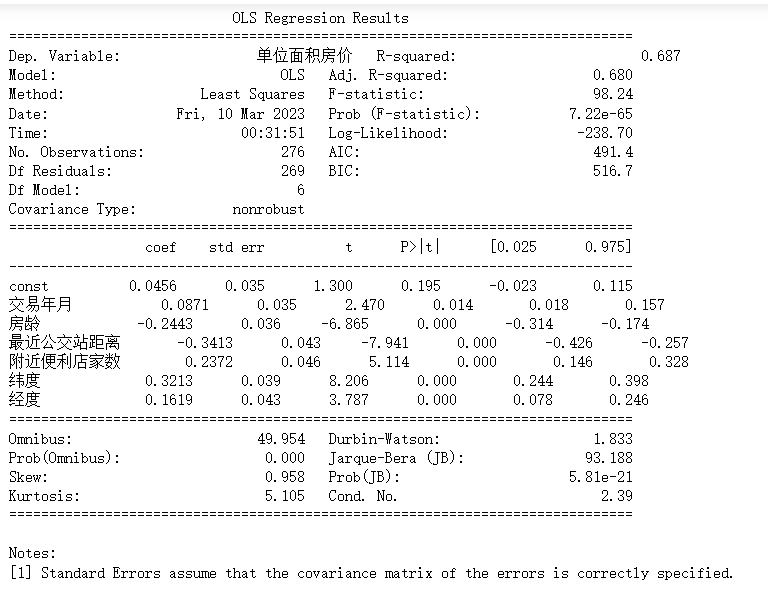
此回归分析结果显示了自变量的系数(coef),标准误差(std err),t值,P值和置信区间(95%)。检验的结果为93.188,P值为5.81e-21,说明残差不是正态分布;Kurtosis的值为5.105,说明残差的峰度比正态分布的峰度大。 从上表可以看出,交易年月,房龄,最近公交站距离,附近便利店家数,纬度和经度对房价有显著的影响。交易年月对房价的影响显著,P值为0.014;房龄对房价的影响显著,P值为0.000;最近公交站距离对房价的影响显著,P值为0.000;附近便利店家数对房价的影响显著,P值为0.000;纬度对房价的影响显著,P值为0.000;经度对房价的影响显著,P值为0.000。 模型的R平方为0.687,说明解释变量对因变量的解释能力较强;调整后的R平方为0.680,说明解释变量对因变量的解释能力还不错。模型的F-statistic为98.24,P值为7.22e-65,说明模型具有显著性;Log-Likelihood为-238.70,AIC为491.4,BIC为516.7。Omnibus检验的结果为49.954,P值为0.000,说明残差不是正态分布;Durbin-Watson值为1.833,说明残差不存在自相关性; 房龄回归系数为-0.2443,说明房龄越大,单位面积房价越低;最近公交站距离回归系数为-0.3413,说明距离公交站越近,单位面积房价越高;附近便利店家数回归系数为0.2372,说明附近便利店家数越多,单位面积房价越高;纬度回归系数为0.3213,说明纬度越高,单位面积房价越高;经度回归系数为0.1619,说明经度越高,单位面积房价越高。
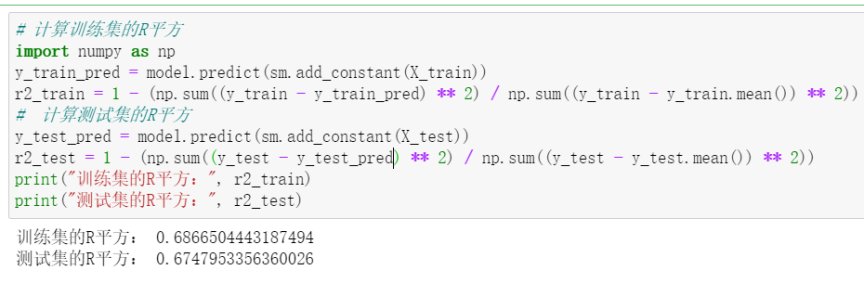
由上面的结果可以得知,训练集的R平方为0.6867,测试集的R平方为0.6748,说明模型对训练集和测试集都有了很好的拟合。R平方越高,说明模型拟合得越好,因此我们可以说,该回归模型对数据的拟合效果很好。 结论通过对台北市新店区房产价格的数据分析,我们得出了以下结论: 单位面积房价与交易年月、房龄、最近公交站距离、附近便利店家数、纬度和经度有显著的线性关系。 回归分析结果显示,交易年月、房龄、最近公交站距离、附近便利店家数、纬度和经度都对单位面积房价产生了显著的影响。 训练集和测试集的R平方值分别为0.69和0.67,说明模型对训练数据和测试数据都有较好的预测效果。 综上所述,通过本次分析我们可以得出,在台北市新店区,交易年月、房龄、最近公交站距离、附近便利店家数、纬度和经度都是影响房价的重要因素。对于房产市场投资者来说,在选择房产投资时,应该充分考虑这些因素,以便获得较高的回报。 |










【本文地址】