浅谈发票识别方案 |
您所在的位置:网站首页 › 发票二维码扫描自动勾选 › 浅谈发票识别方案 |
浅谈发票识别方案
|
背景
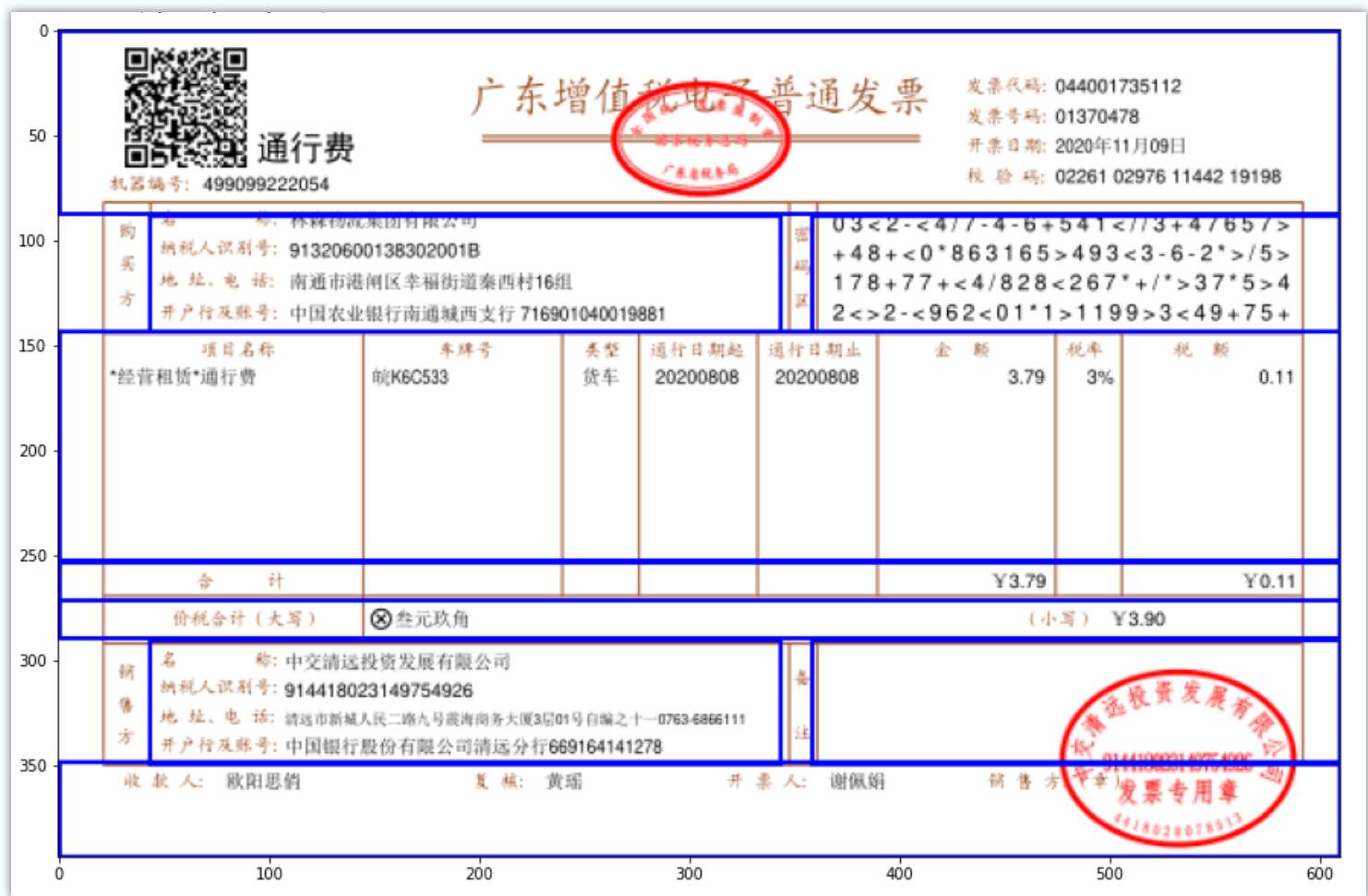
发票解析或者发票内容识别,简言之就是从PDF文件(电子版或扫描版)、发票照片等来源获取发票票面信息以及查验发票真伪。本文尝试从不同角度讲述发票解析及处理的一些技术手段。需要说明的是,这只是根据我自己过往的经验得到的方法与结论。 发票样式首先,不论载体是PDF文件还是照片文件,发票的基本样式包括以下8种(来源为税务总局网站) 注:机动车销售统一发票、增值税普通发票(卷票)和二手车销售统一发票格式跟其余五种发票样式存在较大的差别,不在本文讨论范围内。 方案一:税务局api? 第一种想法是:既然税务局发票查验平台能够查询发票真伪,那么是否可以用相关api实现发票内容获取呢?很遗憾,找了一遍发现并无此类api提供。当然,既然能够通过网络查询,就能使用相关网络爬虫等技术实现发票的自动查询,那么也就进一步可以获得发票内容了,同时,也解决了发票真伪查验的问题,不过这种方案难度较大,本系列文章后续会介绍。
方案二:PDF解析 第一种想法是:既然税务局发票查验平台能够查询发票真伪,那么是否可以用相关api实现发票内容获取呢?很遗憾,找了一遍发现并无此类api提供。当然,既然能够通过网络查询,就能使用相关网络爬虫等技术实现发票的自动查询,那么也就进一步可以获得发票内容了,同时,也解决了发票真伪查验的问题,不过这种方案难度较大,本系列文章后续会介绍。
方案二:PDF解析
第二种方案是通过解析PDF文字内容和线段内容,反向构建出表格,然后根据表格来寻找内容。 该方案可以通过python的 pdfplumber 库( pip install pdfplumber )读取文字和线段: import pdfplumber as ppb doc = ppb.open('') page1 = doc.pages[0] words = page1.extract_words() lines = page1.lines但是该库获取到的线段并不是完整的线段,而是残缺的,比如下图(左)示意,此时需要构建算法将线段补充完整(右图) 然后查找线段交点,根据交点划分出矩形: 和尾部的内容: 上面的方案可以解决很大一部分发票的识别问题,但是,有些发票,你会发现使用 pdfplumber 读取不到文字内容和线段。这样上面这种方案就束手无策了,具体哪些发票会读取不了呢,PDF版本在1.7之前的都识别不了。 方案二:PDF解析改进既然方案一提到 pdfplumber 在某些情况下无法读取pdf的内容,那就需要寻找一个替代工具,经探索发现 fitz 这个库( pip install pymupdf 注意这个库使用名称跟安装名称不一致)可以读取更大范围的pdf文件,在博主试验的pdf中,那些不能被pdfplumber读取的文件都可以被 fitz 读取 ,但是 fitz 是获取不到线段的,因此,自然而然想到一种方案就是:将 pdfplumber构建的矩形储存下来,这些矩形指示了每一个内容块的位置信息。如下示意了存储的一共22个矩形信息: 这样,解析流程就变成了如下: 该方案能解决一部分 pdfplumber 不能读取的文件,但是,不同类型的发票,pdf内部的表格边框并不完全一致,这导致矩形坐标不一致的内容会错乱,比如: 上面这两张发票的矩形宽度就不是一致的。这种情况下需要为每一种发票都保存一份位置文件。进一步的,你还必须判断出正在处理的发票属于哪一种。 方案三:PDF解析再次改进方案二中依赖确定的位置去解析内容,对于不同类型的发票位置会不一样,那么使用文字位置去定位边框可不可行呢?该方案便是基于这样的思想。首先使用 fitz 读取所有文字及其位置。然后,根据文字所在内容块特有的单词去定位内容块的边框,比如:我定位了如下8个关键词 然后根据这8个点将内容块划分为9部分:
这个方案是目前为止能够克服前面两个方案缺点的替代,但是它自身也存在一定问题,最关键的一点就是:由于分块依赖于关键文字的位置,如果关键文字查找不到或者关键字跟发票内容混淆,那么这个方案就不可取了。 另一方面,在用列空隙分割的时候,如果列内部的文字内容本身偏离较大且超过了列之间间隙的时候,对列的分割就会出现误判。 改进下图所示,”数量“这一列只有一个内容”3“,由于”3“跟”数量“偏离较大,此时划分出来的列就会将”3“单独作为一列,这便是误判。为了克服这种情况,这里博主介绍一种新方法来改进。
回归到问题的初衷,是将列内容块分离开来,由于定位不到分割二者的直线,我们才引入了“空隙分割法”。而“空隙分割法”本质上是一种图像处理技术,既然用到了图像处理技术,我们是不是可以直接一点,直接来寻找直线呢?事实上这是可行的。这里我引入一个图像处理库:opencv ,python中通过命令安装:pip install opencv-python。 opencv可以检测图象上的直线,具体原理是霍夫变换。 import cv2 rect = split_rects(page)['rect4'] pix = page.getPixmap(clip=rect) img = np.array(tuple(pix.samples), dtype=np.uint8).reshape([pix.height, pix.width, -1]) gImg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) edges = cv2.Canny(gImg, 50, 150, apertureSize=3) lines = cv2.HoughLinesP(edges, 1, np.pi / 180, 60, minLineLength=50, maxLineGap=5)检测出直线后挑选出竖线,下图红色线:
现在通过这些竖线分割的矩形块就是完全准确的。 这时候你突然想到:既然可以用直线识别的方法找到分割线,那是不是可以全局使用这种方法查找横竖线然后构建分割的表格呢?哈哈,Absolutely!!! 
当然,这样的改进也存在不足,博主在试验中发现仍旧会有部分发票在图像识别时会存在错误,主要表现为线段不全或者变多。 方案四:二维码识别上述三个方案虽说基本能解决大部分问题,但是有这样一个前提:必须是PDF电子版发票,对于扫描版或者照片怎么办呢?观察发票,会发票大部分发票上会印有一个二维码,这个二维码其实包含了一部分发票信息,一个例子如下:
扫描这个二维码,所携带的信息如下: 01,10,033002000111,67536084,2241.51,20200609,80200846912530403376,EF03,该字符串以逗号分隔每一个属性值,从左到右依次是: 01:第一个属性值,尚未搞清楚含义; 10:第二个属性值,代表发票种类代码,10-增值税电子普通发票,04-增值税普通发票,01-增值税专用发票; 033002000111:第三个属性值,代表发票代码; 67536084:第四个属性值,代表发票号码; 2241.51:第五个属性值,代表开票金额; 20200609:第六个属性值,代表开票日期; 80200846912530403376:第七个属性值,代码发票校验码,增值税专用发票是没有发票校验码的,没有则为空字符串; EF03:第八个属性值,为CRC算法产生的机密信息; 缺点这种方案有不足之处,其一是发票必须有二维码,其二是只能获取到5个关键信息(发票代码、号码、开票日期、校验码、开具金额),想要获取其他信息就不行了。 使用请参考:在线使用 参考 电子发票相关知识,可以参考下面这篇文章:电子发票的耐人寻味pdfplumber 库地址:pdfplumberpymupdf 库地址:PyMuPDF |




 最后将单词放入矩形框内部:
最后将单词放入矩形框内部:  上述步骤实现了把文字放入到其对应的矩形框内部,然后,就可以根据不同矩形框所属的组来查找相应的内容,比如,对于一张发票来说,我们明确知道,在第一个矩形框中出现的内容是"购买方"三个字,第二个矩形框中出现的内容是购买方的详细信息,包括“名称”、“纳税人识别号”、“地址、电话”和“开户行及帐号”。
上述步骤实现了把文字放入到其对应的矩形框内部,然后,就可以根据不同矩形框所属的组来查找相应的内容,比如,对于一张发票来说,我们明确知道,在第一个矩形框中出现的内容是"购买方"三个字,第二个矩形框中出现的内容是购买方的详细信息,包括“名称”、“纳税人识别号”、“地址、电话”和“开户行及帐号”。  依次提取对所有矩形框内的内容就能把表格内的内容找到。 此外,有两个部分的内容是不在矩形内部的,分别是头部:
依次提取对所有矩形框内的内容就能把表格内的内容找到。 此外,有两个部分的内容是不在矩形内部的,分别是头部: 
 不过,这两个部分可以分别当作一个矩形框来处理。
不过,这两个部分可以分别当作一个矩形框来处理。




 这9个内容块分别是:头部内容块、购买方信息块、密码区信息块、详细内容块、合计块、价税合计块、销售方信息块、备注区信息块、尾部信息块。 对于这9个信息块,大部分的内容分离是比较容易的,可以通过关键词查找模式搜索,这里不赘述,但是“详细内容信息块”有些难度。 仔细观察“详细内容信息块发现”:
这9个内容块分别是:头部内容块、购买方信息块、密码区信息块、详细内容块、合计块、价税合计块、销售方信息块、备注区信息块、尾部信息块。 对于这9个信息块,大部分的内容分离是比较容易的,可以通过关键词查找模式搜索,这里不赘述,但是“详细内容信息块”有些难度。 仔细观察“详细内容信息块发现”: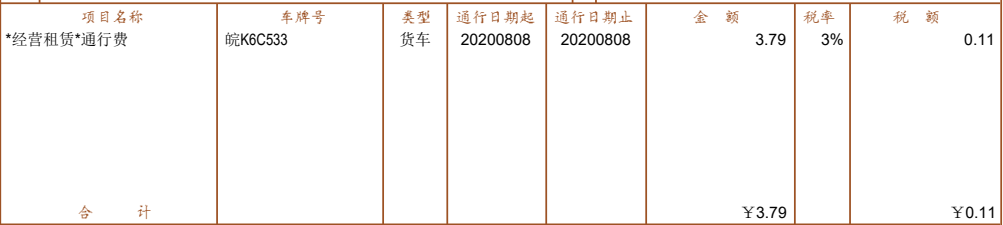
 关键词一个是“项目名称”,另一个是“货物或应税劳务、服务名称”,等。不过规律也是有的,出现不同的关键词类型并不会很多
关键词一个是“项目名称”,另一个是“货物或应税劳务、服务名称”,等。不过规律也是有的,出现不同的关键词类型并不会很多 为了将“详细信息内容块”中的不同列分割开来,博主采用了一种图像处理技术中的一种方式:将内容块中的所有文字边框绘制到一张图片上,然后对图片的垂直方向像素求和,这样,对于没有文字的部分,求和便会是0,而其他部分会是大于0的值,如下:
为了将“详细信息内容块”中的不同列分割开来,博主采用了一种图像处理技术中的一种方式:将内容块中的所有文字边框绘制到一张图片上,然后对图片的垂直方向像素求和,这样,对于没有文字的部分,求和便会是0,而其他部分会是大于0的值,如下: 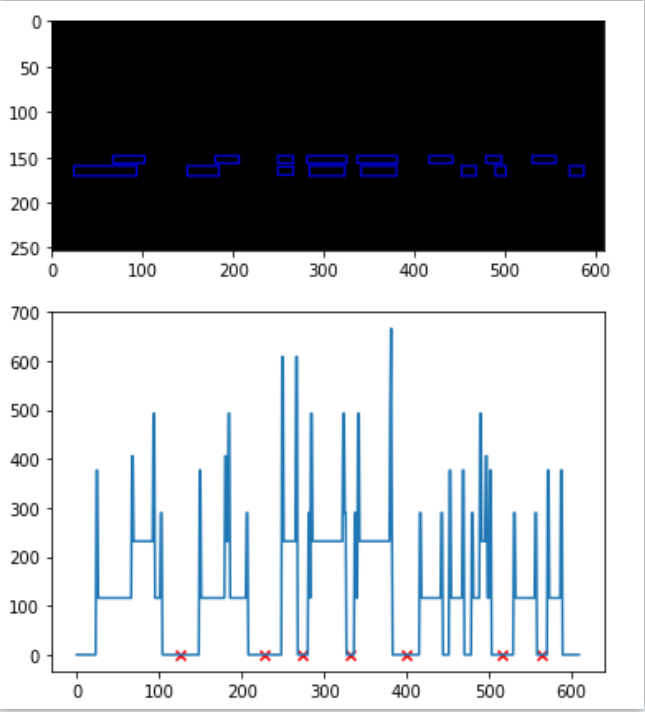 上图中,图一是将文字边框绘制到图象上,图二是在竖直方向对像素求和,观察求和后的序列,那些等于0的值就是空隙,对空隙从大到小排序取前7便是列分割的位置,将这些位置绘制到图象上(上图中红色x) 这样,只需要对每列中的内容进行搜索即可。
上图中,图一是将文字边框绘制到图象上,图二是在竖直方向对像素求和,观察求和后的序列,那些等于0的值就是空隙,对空隙从大到小排序取前7便是列分割的位置,将这些位置绘制到图象上(上图中红色x) 这样,只需要对每列中的内容进行搜索即可。


【本文地址】