bzip2原理分享 |
您所在的位置:网站首页 › 压缩包的压缩原理 › bzip2原理分享 |
bzip2原理分享
|
bzip2原理分享
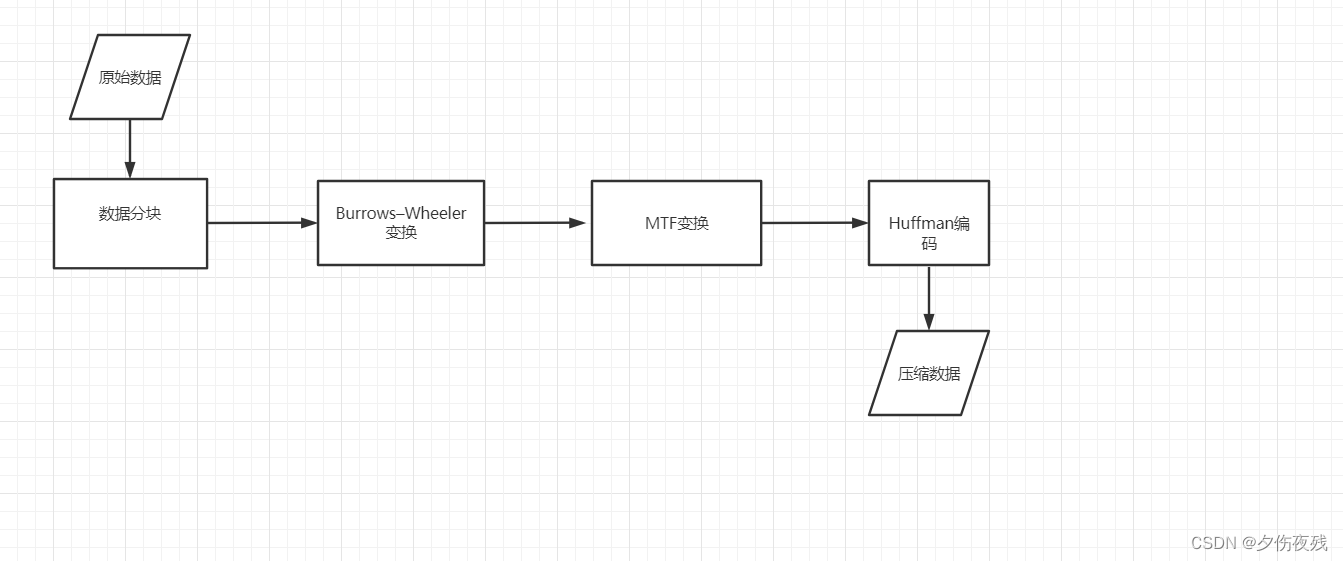
实现压缩bzip2 运行原理BWT变换过程逆变换过程
MTF变换huffman编码bzip2 的算法特性优势:''字典''越小,bzip2效果越好参考资料
实现压缩
对数据进行压缩,通常有两个思路: 字典转换 ( dictionary transforms ) 减少数据中不同符号的数量(即让“字母表”尽可能小);【目前所有的主流压缩算法,比如GZIP或者7-Zip,都会在核心转换步骤中使用字典转换】变长编码 (variable-length codes) 用更少的位数对更常见的符号进行编码(即最常见的“字母”所用的位数最少)。【bzip2 基于该点对数据进行压缩】 bzip2 运行原理wiki 描述 wiki 描述 wiki 描述 wiki 描述
Burrows–Wheeler变换(BWT,也称作块排序压缩),是一个被应用在数据压缩技术(如bzip2)中的算法。该算法于1994年被Michael Burrows和David Wheeler在位于加利福尼亚州帕洛阿尔托的DEC系统研究中心发明。它的基础是之前Wheeler在1983年发明的一种没有公开的转换方法。 BWT会打乱数据流中符号的顺序,并试图让相同的符号簇彼此靠近。 例如字符串S="BANANA"经过BWT后变成S 1 _1 1=“NNBAAA”
假定输入流是BANANA,那么需要将它写在表的第一行。然后,在接下来的每一行,我们都会对该字符串进行一次循环右移一位操作。也就是说,将除了最右边的字符之外的所有字符向右移一位,然后将最右边的字符放在最前面。继续进行这样的移位操作,直到对所有的字符都操作了一遍,如下所示。 BANANA ABANAN NABANA ANABAN NANABA ANANAB 将每一行字符串从上往下按字典序排序,矩阵的最后一列就为变换后的S 1 _1 1=“NNBAAA”,经过BWT之后使用游程编码或者前移MTF将很好处理。 ABANAN ANABAN ANANAB BANANA NABANA NANABA 逆变换过程为什么不直接进行排序得到相同的结果?因为排序的结果无法还原。但BWT具有逆向操作。 第一步将输出字符串写入下表中,它表示的是每一行的最后一个字符。 接下来将这两列合并,这样每行就都有两个字符了: 逆变换后的矩阵与原来矩阵完全相同,所以只要记住矩阵中原串的位置就能还原成功。 MTF(move to front)变换是一种可逆变换,也称为前移编码。MTF转换主要是利用空间局部性原理来减少信息熵。因为最近访问的字符总是出现在“recently used symbols”的前面位置,如果字符的空间局部性较好,编码之后就会出现很多小的数字,如”0“或”1“。从而将字典缩小。 https://zhuanlan.zhihu.com/p/494481767 通常MTF的输入结果为BWT的输出结果,以上述的S 1 _1 1="NNBAAA"为例。得到的序列为[13,0,2,2,0,0].保存压缩信息的同时需要保持字母表。 huffman编码 bzip2 的算法特性与其它压缩算法的对比: 可以发现bzip2的压缩比稍微优秀一些之外,bzip的压缩/解压缩速率,CPU占用率都不及其他主流压缩算法。 优势:'‘字典’'越小,bzip2效果越好BWT一直被当作一种边缘压缩算法。虽然最初在处理文本数据时,显示出非常好的效果,但是从性能角度来看,它永远无法与GZIP这样的算法去竞争。因此,BWT(或者说BZIP2,主流的BWT编码器)从来没有在压缩世界掀起什么风浪。 情况一直如此,直到人类开始对脱氧核糖核酸(deoxyribonucleic acid,DNA)测序。 人类的DNA分子结构虽然复杂,但是其组成非常简单,只包含4种基本的核苷酸碱基,分别标记为A、C、G和T。一个给定的基因组基本上可以看成是一个长字符串,包含这4个符号按不同的顺序排列。有多少这样的字符呢?据计算,人类基因组大约包含31.647 亿个DNA碱基对。结果表明,BWT这一块排序算法对DNA来说是一种理想的变换,可以使其更容易压缩、查询和检索。(事实上,有大量的论文证明了这一点。)当根据参照对新基因组进行读取校准时,大小的减小和可用性的提高对快速读取来说十分重要。 2008年,为了治疗人类疾病,降低疾病死亡率,科学家开始绘制和测试人类基因组。单个基因组序列就包含了大量的数据,仅仅是描述人类基因组成的数据就超过了14GB。这样的数据大小超出了大多数系统能处理的范围(当时云计算还不是热门话题)。数据压缩再一次成为解决问题的利器。研究人员发现,BWT是最有效的存储DNA信息的压缩格式,甚至无须解压就能对数据进行操作。到了2014年,研究人员通过将可扩展的云计算与主机之间的压缩数据传输结合起来,创造了全球最快的蛋白质折叠计算之一。 结果表明,BWT这一块排序算法对DNA来说是一种理想的变换,可以使其更容易压缩、查询和检索。(事实上,有大量的论文证明了这一点。)当根据参照对新基因组进行读取校准时,大小的减小和可用性的提高对快速读取来说十分重要。 参考资料 各种压缩算法对比Fast and accurate short read alignment with Burrows-Wheeler transform数据压缩入门bzip2上游社区 |
 数据解压为上述流程的逆过程。
数据解压为上述流程的逆过程。 ==》
==》
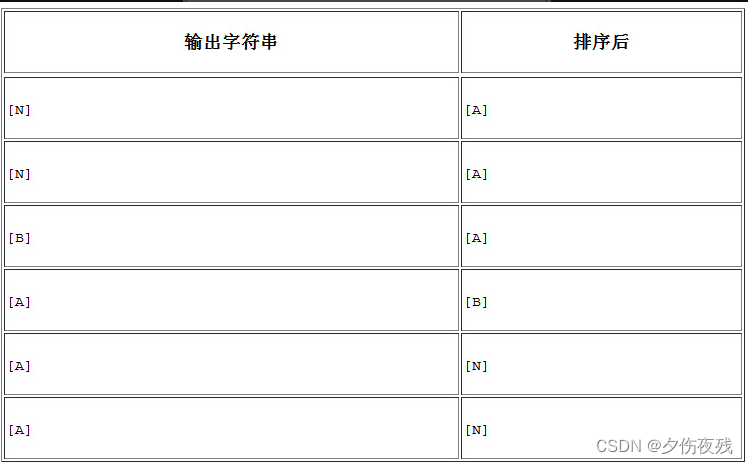
 按字典顺序对每行排序,结果如下:
按字典顺序对每行排序,结果如下:  接着,将原始的输出字符串(NNBAAA)按顺序添加每行字符串的最前面(每行添加1个字符),所得结果如下所示:
接着,将原始的输出字符串(NNBAAA)按顺序添加每行字符串的最前面(每行添加1个字符),所得结果如下所示: 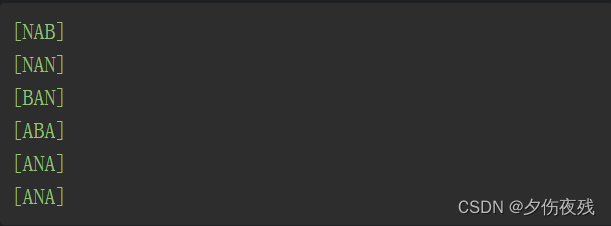
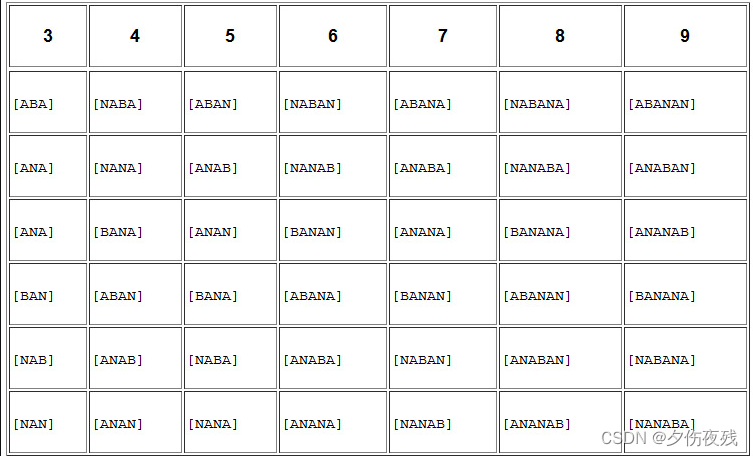 BWT的空间复杂度为O(n^2),因此实际使用时需要对数据进行分块。 BWT原理:Fast and accurate short read alignment with Burrows-Wheeler transform
BWT的空间复杂度为O(n^2),因此实际使用时需要对数据进行分块。 BWT原理:Fast and accurate short read alignment with Burrows-Wheeler transform
【本文地址】
今日新闻 |
推荐新闻 |