TPS低,CPU高 |
您所在的位置:网站首页 › 压测tps上不去 › TPS低,CPU高 |
TPS低,CPU高
|
一、业务背景+系统架构 本次场景为kafka+storm+redis+hbase,通过kafka的数据,进入storm的spout组件接收,转由storm的Bolt节点进行业务逻辑处理,最后再推送进kafka。 表数据相关的逻辑为:查询Hbase表数据,首次查询会写入redis和storm cache,再次查询,会直接从redis或cache中取值。 storm应用:
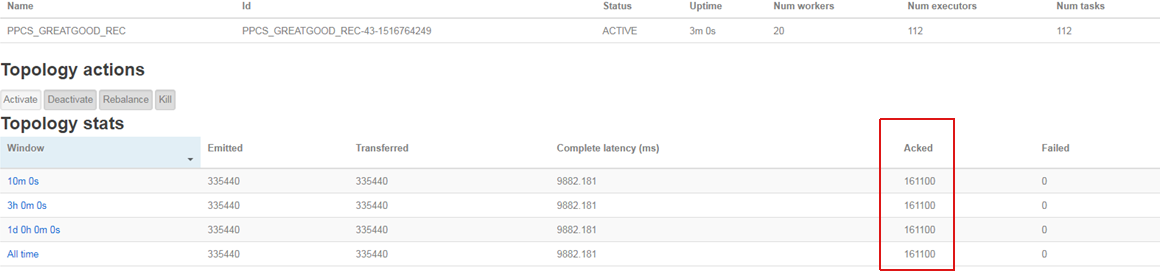
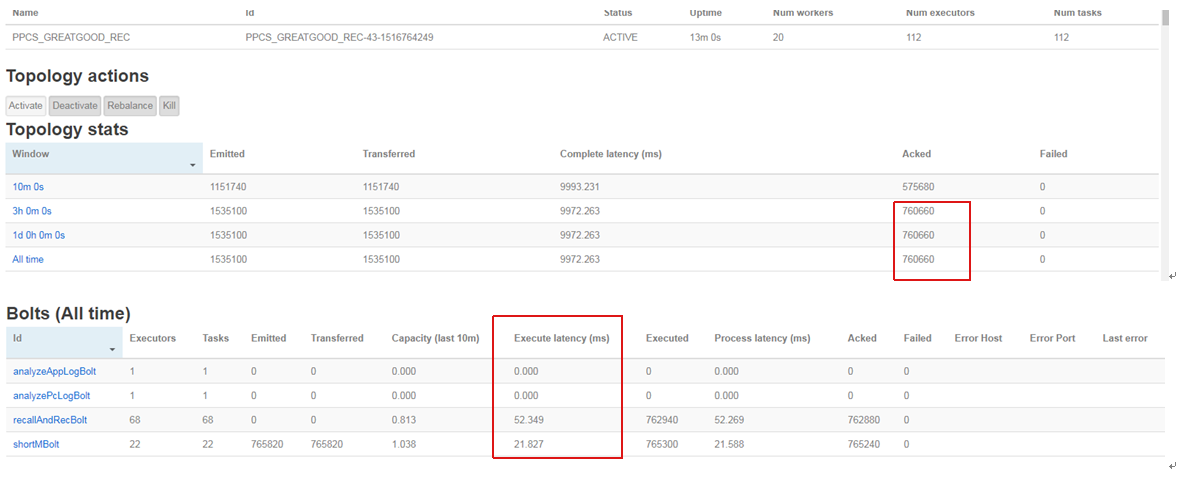
二、性能测试场景 1.数据:json类型的用户偏好数据700万 2.灌入方式:java脚本 3.hbase表:生产全量数据导入 4.storm集群:5台 (Nimbus+sup01+sup02+sup03+sup04) 三、性能过程截图 三分钟时处理数据量:
storm响应时间(不包含kafka延时)
十三分钟处理数据量:
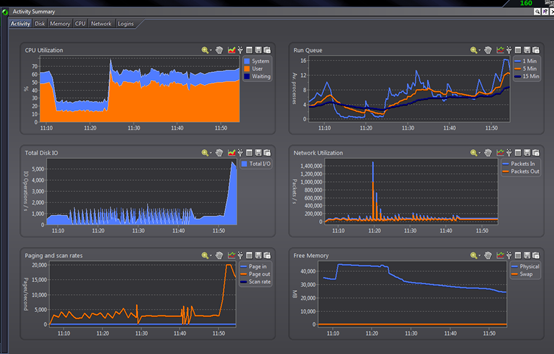
从stormUI接口估算出的TPS大约为970左右,远没有达到我们业务要求。 四、性能瓶颈分析: 1、直接查看storm应用服务器的情况:
发现 cpu从20%直接到80%
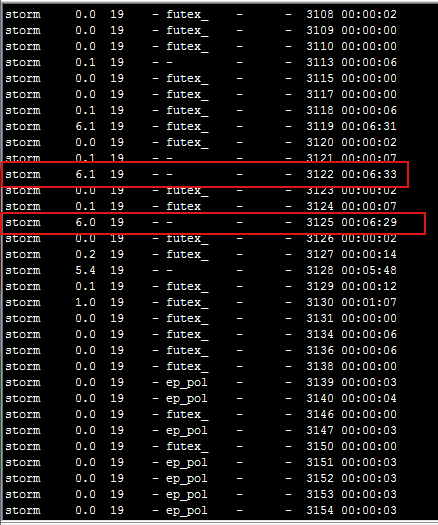
CPU资源显然在user态消耗的更多,判断为用户类进程占用的cpu时间片更多。 2、我们按消耗cpu资源的大小对进程进行排序,抓出最大的进程号16889,然后打印进程下面的线程: 命令:ps -mp pid -o THREAD,tid,time
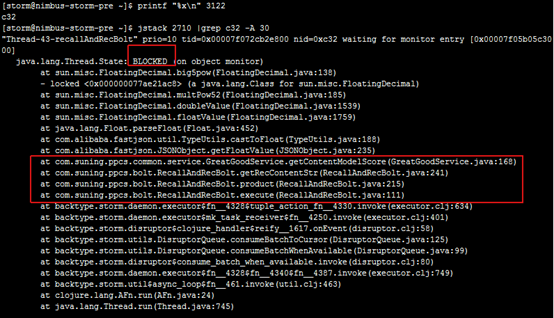
3.挑出占用cpu时间最高的线程,打印线程栈信息,注意线程id(tid)必须转化成16进制 命令:printf "%x\n" tid jstack pid |grep tid -A 30
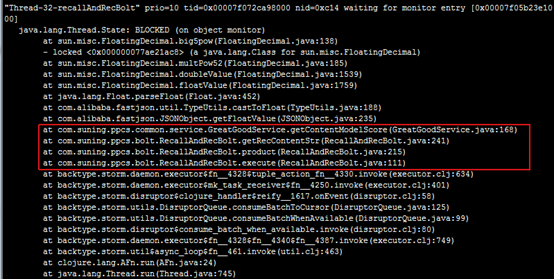
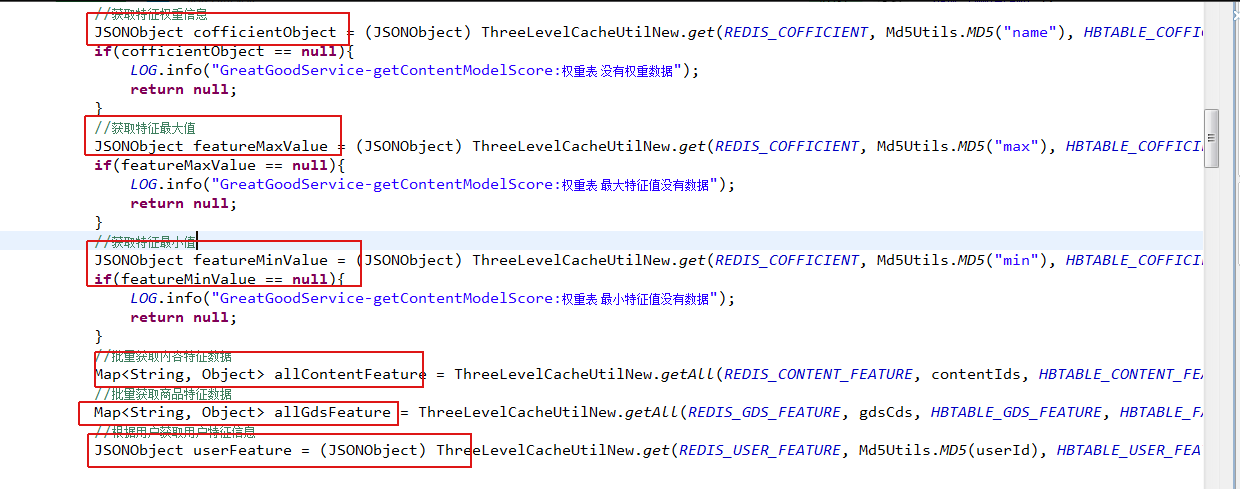
此处不逐一举例线程信息,Niubus主机和其他从机都需选取一些线程进行打印,发现耗时长的线程大部分都处于Blocked状态,线程状态为执行getcontentmodelscore方法。 检查getcontentmodelscore这部分代码:
发现这部分代码逻辑为从Hbase中获取得分数据和推荐商品数据,判断为hbase性能不佳引起的性能低下,由于PRE环境HBASE条件有限,没有监听端口,也无权限进行配置优化,此问题暂时没有进一步解决方案。
五、第二种排查方案: 由于stormUI提供了可视化的界面,我们可以点开处理时间长的bolt下找到对应的端口号:
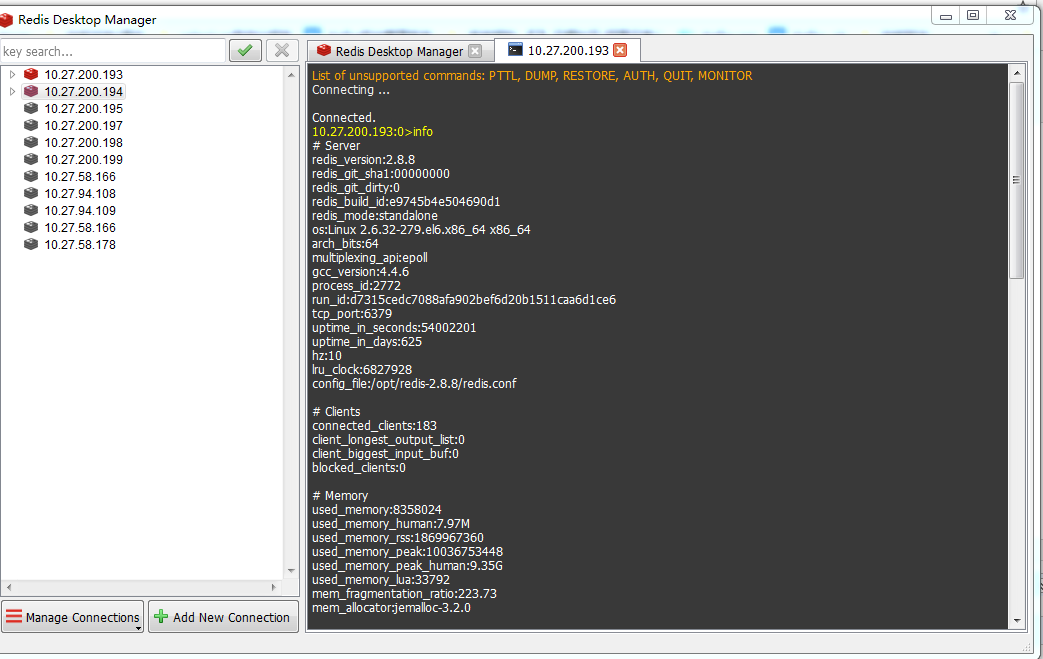
在host一栏查到对应的机器地址,通过Jps -m |grep 命令找到对应的进程号,此方法适用于多个业务系统公用一个集群,需要快速定位Pid的时候。 六、附redis监控:
在redis工具中敲入info,查看连接数和使用内存。 由于redis是在内存中运行,不需要考虑命中率;redis单线程运行,如果redis查得慢的话基本可能是一次获取的数据太多了或者程序逻辑不对,不需要考虑慢查询。对于redis,只要不一次获取太多的Key-value,基本不会出现性能问题。 七、strorm worker executor配置问题: storm中worker代表了进程,比如配置10个worker,5台机器,每个机器会均衡分配2个worker,executor代表线程数,对于每个Bolt,spout节点都可增大减小线程数,达到最佳的处理数据效率。 在本次压测时,10个worker配置了100个线程数,发现性能远不如10个worker配置60个线程,对于kafka,我们知道,一个kafka分区只需对应一个线程,多配置的线程也会处于闲置状态,但并没出现由于多配置线程儿造成的性能降低。而对于storm,对于多配置的线程,反而出现了性能的严重降低。此问题暂时未知道具体原因。 |




【本文地址】
今日新闻 |
推荐新闻 |