基于Pytorch实现卷积神经网络feature map/特征图可视化(以残差网络ResNet18为例) |
您所在的位置:网站首页 › 卷积层bias › 基于Pytorch实现卷积神经网络feature map/特征图可视化(以残差网络ResNet18为例) |
基于Pytorch实现卷积神经网络feature map/特征图可视化(以残差网络ResNet18为例)
|
写在前面 一篇好的论文,除了与同行相比有优异的性能,还要有酷炫的可视化,而对于特征提取过程细节的可视化尤其重要。feature map即特征图的可视化让我们很好地了解了卷积神经网络的运行本质:从低级特征开始提取,一直到高级特征 本文以ResNet18网络举例,对该残差网络的每一个卷积层进行特征图可视化,并顺利验证了低级特征到高级特征提取这一现象。具体来说,本文目的是:输入一张原始图片,输出该原图经过卷积神经网络(这里以ResNet18为例)每一个卷积层得到的feature map(特征图) 本文主要参考视频:卷积网络feature map可视化||特征图可视化(pytorch残差网络举例)_哔哩哔哩_bilibili,但由于没有获取到视频中的数据集,所以根据自己的图片数据对代码做了相应修改,这是第一处不同;同时,本文使用了两种ResNet模型来提取卷积层特征图,一种是官方提供的ResNet预训练模型,另一种是在自己的数据集上微调后的ResNet模型 ResNet18模型结构在可视化之前,先看一下ResNet18模型的结构,从而了解哪些层是卷积层 关于ResNet模型之前已经写过详细的文章,可以参考:Reconcile:ResNet(深度残差网络)原理及代码实现(基于Pytorch)(一)print可视化Pytorch自带模型可视化的功能,其基础调用格式如下: import torchvision model = torchvision.models.resnet18(pretrained=True) print(model)结果如下: ResNet( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (1): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer2): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer3): Sequential( (0): BasicBlock( (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer4): Sequential( (0): BasicBlock( (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (fc): Linear(in_features=512, out_features=1000, bias=True) )显然,该方法只是对模型含有的modules做了一个对象及其参数的打印 (二)torchsummary可视化我们更希望输出每一层的layer类型、参数量以及输出feature map的尺寸等。torchsummary提供了更详细的信息分析,包括模块信息(每一层的类型、输出shape和参数量)、模型整体的参数量、模型大小、一次前向或者反向传播需要的内存大小等 torchsummary的使用方法如下,只要提供给summary函数:模型,以及输入的size,即可 from torchsummary import summary summary(model, input_size = (channels, H, W))使用torchsummary可视化ResNet18模型结构的代码如下: import torch import torchvision from torchsummary import summary device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = torchvision.models.resnet18(pretrained=True) model.to(device) summary(model,(3,224,224)) # resnet-18输入图片的尺寸是3*224*224结果如下: ---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 64, 112, 112] 9,408 BatchNorm2d-2 [-1, 64, 112, 112] 128 ReLU-3 [-1, 64, 112, 112] 0 MaxPool2d-4 [-1, 64, 56, 56] 0 Conv2d-5 [-1, 64, 56, 56] 36,864 BatchNorm2d-6 [-1, 64, 56, 56] 128 ReLU-7 [-1, 64, 56, 56] 0 Conv2d-8 [-1, 64, 56, 56] 36,864 BatchNorm2d-9 [-1, 64, 56, 56] 128 ReLU-10 [-1, 64, 56, 56] 0 BasicBlock-11 [-1, 64, 56, 56] 0 Conv2d-12 [-1, 64, 56, 56] 36,864 BatchNorm2d-13 [-1, 64, 56, 56] 128 ReLU-14 [-1, 64, 56, 56] 0 Conv2d-15 [-1, 64, 56, 56] 36,864 BatchNorm2d-16 [-1, 64, 56, 56] 128 ReLU-17 [-1, 64, 56, 56] 0 BasicBlock-18 [-1, 64, 56, 56] 0 Conv2d-19 [-1, 128, 28, 28] 73,728 BatchNorm2d-20 [-1, 128, 28, 28] 256 ReLU-21 [-1, 128, 28, 28] 0 Conv2d-22 [-1, 128, 28, 28] 147,456 BatchNorm2d-23 [-1, 128, 28, 28] 256 Conv2d-24 [-1, 128, 28, 28] 8,192 BatchNorm2d-25 [-1, 128, 28, 28] 256 ReLU-26 [-1, 128, 28, 28] 0 BasicBlock-27 [-1, 128, 28, 28] 0 Conv2d-28 [-1, 128, 28, 28] 147,456 BatchNorm2d-29 [-1, 128, 28, 28] 256 ReLU-30 [-1, 128, 28, 28] 0 Conv2d-31 [-1, 128, 28, 28] 147,456 BatchNorm2d-32 [-1, 128, 28, 28] 256 ReLU-33 [-1, 128, 28, 28] 0 BasicBlock-34 [-1, 128, 28, 28] 0 Conv2d-35 [-1, 256, 14, 14] 294,912 BatchNorm2d-36 [-1, 256, 14, 14] 512 ReLU-37 [-1, 256, 14, 14] 0 Conv2d-38 [-1, 256, 14, 14] 589,824 BatchNorm2d-39 [-1, 256, 14, 14] 512 Conv2d-40 [-1, 256, 14, 14] 32,768 BatchNorm2d-41 [-1, 256, 14, 14] 512 ReLU-42 [-1, 256, 14, 14] 0 BasicBlock-43 [-1, 256, 14, 14] 0 Conv2d-44 [-1, 256, 14, 14] 589,824 BatchNorm2d-45 [-1, 256, 14, 14] 512 ReLU-46 [-1, 256, 14, 14] 0 Conv2d-47 [-1, 256, 14, 14] 589,824 BatchNorm2d-48 [-1, 256, 14, 14] 512 ReLU-49 [-1, 256, 14, 14] 0 BasicBlock-50 [-1, 256, 14, 14] 0 Conv2d-51 [-1, 512, 7, 7] 1,179,648 BatchNorm2d-52 [-1, 512, 7, 7] 1,024 ReLU-53 [-1, 512, 7, 7] 0 Conv2d-54 [-1, 512, 7, 7] 2,359,296 BatchNorm2d-55 [-1, 512, 7, 7] 1,024 Conv2d-56 [-1, 512, 7, 7] 131,072 BatchNorm2d-57 [-1, 512, 7, 7] 1,024 ReLU-58 [-1, 512, 7, 7] 0 BasicBlock-59 [-1, 512, 7, 7] 0 Conv2d-60 [-1, 512, 7, 7] 2,359,296 BatchNorm2d-61 [-1, 512, 7, 7] 1,024 ReLU-62 [-1, 512, 7, 7] 0 Conv2d-63 [-1, 512, 7, 7] 2,359,296 BatchNorm2d-64 [-1, 512, 7, 7] 1,024 ReLU-65 [-1, 512, 7, 7] 0 BasicBlock-66 [-1, 512, 7, 7] 0 AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0 Linear-68 [-1, 1000] 513,000 ================================================================ Total params: 11,689,512 Trainable params: 11,689,512 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.57 Forward/backward pass size (MB): 62.79 Params size (MB): 44.59 Estimated Total Size (MB): 107.96 ----------------------------------------------------------------总结可以看出,ResNet18模型里,最表层只有一个卷积层:conv1;其他卷积层都在Sequential里,故后面需要使用嵌套循环来获取每一个卷积层 上面的代码是使用官方提供的预训练好的ResNet18模型。如果想加载在自己数据集上微调过的模型,只需要使用 model = torch.load(),括号里写上.pth文件保存地址即可 数据读取及处理 100186.jpg 原始图片from PIL import Image
from torchvision import transforms
# 从硬盘里加载图片
image = Image.open('100186.jpg')
transforms = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
# 图片需要经过一系列数据增强手段以及统计信息(符合ImageNet数据集统计信息)的调整,才能输入模型
image = transforms(image)
print(f"Image shape before: {image.shape}")
image = image.unsqueeze(0)
print(f"Image shape after: {image.shape}")
image = image.to(device) 100186.jpg 原始图片from PIL import Image
from torchvision import transforms
# 从硬盘里加载图片
image = Image.open('100186.jpg')
transforms = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
# 图片需要经过一系列数据增强手段以及统计信息(符合ImageNet数据集统计信息)的调整,才能输入模型
image = transforms(image)
print(f"Image shape before: {image.shape}")
image = image.unsqueeze(0)
print(f"Image shape after: {image.shape}")
image = image.to(device) 遍历得到ResNet18所有卷积层及权重model_weights = [] # append模型的权重
conv_layers = [] # append模型的卷积层本身
# get all the model children as list
model_children = list(model.children())
# counter to keep count of the conv layers
counter = 0 # 统计模型里共有多少个卷积层 遍历得到ResNet18所有卷积层及权重model_weights = [] # append模型的权重
conv_layers = [] # append模型的卷积层本身
# get all the model children as list
model_children = list(model.children())
# counter to keep count of the conv layers
counter = 0 # 统计模型里共有多少个卷积层model.children() 直接 print出来,结果是:即是generator类型,可迭代。有以下两种方式可以查看里面的内容: 方法一:迭代 for i in model.children(): print(i)结果如下: Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ReLU(inplace=True) MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) Sequential( (0): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (1): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) Sequential( (0): BasicBlock( (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) Sequential( (0): BasicBlock( (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) Sequential( (0): BasicBlock( (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) AdaptiveAvgPool2d(output_size=(1, 1)) Linear(in_features=512, out_features=1000, bias=True)方法2:list() model_children = list(model.children()) print(model_children)结果如下: [Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False), BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True), ReLU(inplace=True), MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False), Sequential( (0): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (1): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ), Sequential( (0): BasicBlock( (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ), Sequential( (0): BasicBlock( (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ), Sequential( (0): BasicBlock( (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ), AdaptiveAvgPool2d(output_size=(1, 1)), Linear(in_features=512, out_features=1000, bias=True)]采用嵌套循环,将所有卷积层和对应的权重append到上面创建的两个list里: from torch import nn # append all the conv layers and their respective wights to the list for i in range(len(model_children)): # 遍历最表层(Sequential就是最表层) if type(model_children[i]) == nn.Conv2d: # 最表层只有一个卷积层 counter+=1 model_weights.append(model_children[i].weight) conv_layers.append(model_children[i]) elif type(model_children[i]) == nn.Sequential: for j in range(len(model_children[i])): for child in model_children[i][j].children(): if type(child) == nn.Conv2d: counter+=1 model_weights.append(child.weight) conv_layers.append(child) print(f"Total convolution layers: {counter}")最外层的 for i in range(len(model_children)) 就是指模型的最表层结构,这里 len(model_children) = 10 第二层循环 for j in range(len(model_children[i])) 指的是 Sequential 里的结构,这里 len(model_children[i]) = 2,打印出 Sequential 结构里的卷积层如下,可以发现 Sequential 里的 downsample 里的 Conv2d 是不被统计在内的 # layer1的Sequential Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) # layer2的Sequential Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) # layer3的Sequential Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) # layer4的Sequential Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)所以,最表层的1层卷积+Sequential里的16层卷积(每个layer的Sequential有4层,共4个layer),最终打印出的卷积层个数为17,如下:  生成原始图片经过每一个卷积层的feature map 生成原始图片经过每一个卷积层的feature map注意,所有卷积层已经存储在了列表 conv_layers 里 outputs = [] names = [] for layer in conv_layers[0:]: # conv_layers即是存储了所有卷积层的列表 image = layer(image) # 每个卷积层对image做计算,得到以矩阵形式存储的图片,需要通过matplotlib画出 outputs.append(image) names.append(str(layer)) print(len(outputs)) for feature_map in outputs: print(feature_map.shape)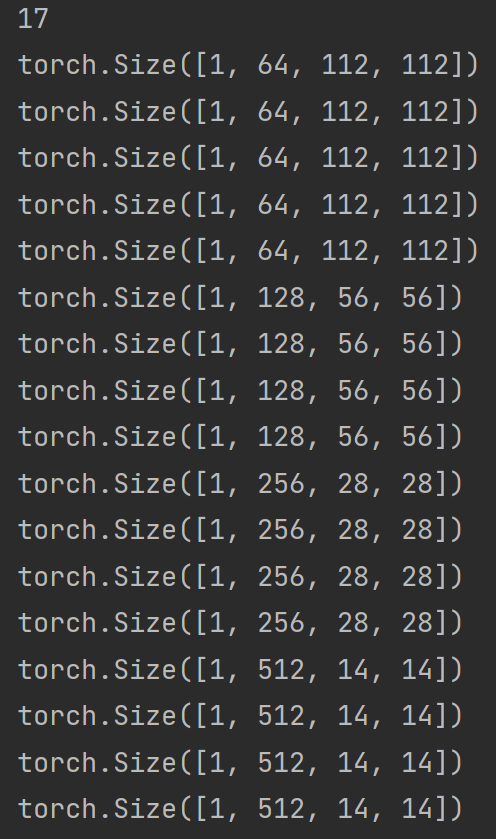 打印出列表 names 看一下:  for循环依次取出里面每一个元素,打印出来:  使用matplotlib绘出feature map 使用matplotlib绘出feature map在可视化之前,需要对 outputs 列表里的 feature map 进行一些处理 先看一下 output,即 feature map 的维度,及维度转换 print(outputs[1].shape) # torch.Size([1, 64, 112, 112]) 1代表图片数量,即1张图片;64代表颜色通道;后面两个是尺寸信息,为112*112的方块 print(outputs[1].squeeze(0).shape) # torch.Size([64, 112, 112]) 因为matplotlib绘画,这个第0维没用 print(torch.sum(outputs[1].squeeze(0),0).shape) # torch.Size([112, 112]).squeeze(0) 这一步是去掉 batch_size 的维度。由于 torch 模型的输入输出都是四个维度:(batch_size, channel, width, height),而我们绘画只需要三个维度,即 (channel, width, height) 而我们可视化选择的是灰度图,即无颜色通道,所以再次 .squeeze 将颜色通道这个维度去除 torch.sum(outputs[1].squeeze(0), 0) 这句代码的意思是:将64个颜色通道的 feature map 加起来,变为一张 112*112 的 feature map,否则全部打印出来的话太多了【sum是把几十上百张灰度图像映射到一张,因为每次卷积操作后会出现几十上百张feature map,而为了显示的方便,每层卷积只显示了一张,这一张就是取了几十上百张 feature map 的平均值】 processed = [] for feature_map in outputs: feature_map = feature_map.squeeze(0) # torch.Size([1, 64, 112, 112]) —> torch.Size([64, 112, 112]) 去掉第0维 即batch_size维 gray_scale = torch.sum(feature_map,0) gray_scale = gray_scale / feature_map.shape[0] # torch.Size([64, 112, 112]) —> torch.Size([112, 112]) 从彩色图片变为黑白图片 压缩64个颜色通道维度,否则feature map太多张 processed.append(gray_scale.data.cpu().numpy()) # .data是读取Variable中的tensor .cpu是把数据转移到cpu上 .numpy是把tensor转为numpy for fm in processed: print(fm.shape)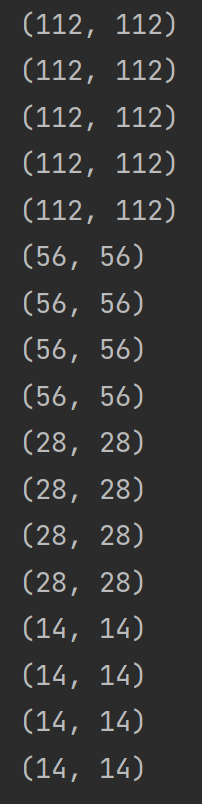 import matplotlib.pyplot as plt
fig = plt.figure(figsize=(30, 50))
for i in range(len(processed)): # len(processed) = 17
a = fig.add_subplot(5, 4, i+1)
img_plot = plt.imshow(processed[i])
a.axis("off")
a.set_title(names[i].split('(')[0], fontsize=30) # names[i].split('(')[0] 结果为Conv2d
plt.savefig('resnet18_feature_maps.jpg', bbox_inches='tight') # 若不加bbox_inches='tight',保存的图片可能不完整 import matplotlib.pyplot as plt
fig = plt.figure(figsize=(30, 50))
for i in range(len(processed)): # len(processed) = 17
a = fig.add_subplot(5, 4, i+1)
img_plot = plt.imshow(processed[i])
a.axis("off")
a.set_title(names[i].split('(')[0], fontsize=30) # names[i].split('(')[0] 结果为Conv2d
plt.savefig('resnet18_feature_maps.jpg', bbox_inches='tight') # 若不加bbox_inches='tight',保存的图片可能不完整 通过观察原始图片经过每一层卷积层得到的 feature map,可以知道大致信息:前面卷积层提取的是图片的细致信息;而后面卷积层提取的是图片的宏观信息,人类无法识别 |
【本文地址】