[爬虫]5.数据解析及应用 之 xpath 【爬取某城市所有景点的所有评论】 |
您所在的位置:网站首页 › 博主精选评论是什么意思 › [爬虫]5.数据解析及应用 之 xpath 【爬取某城市所有景点的所有评论】 |
[爬虫]5.数据解析及应用 之 xpath 【爬取某城市所有景点的所有评论】
|
回顾,上节课我们学了什么?
#导入bs4的BeautifulSoup模块 from bs4 import BeautifulSoup #BeautifulSoup对象实例化 html文档解析 soup=BeautifulSoup(response,‘lxml’) #标签定位 soup.tagName#返回第一个tagName标签的整体html soup.find(‘tagname’,attrName=‘value’)#返回第一个找到标签的整体html list=soup.find_all(‘tagname’,attrName=‘value’)#返回所有找到标签的整体html list=soup.select(‘CSS格式选择器’)’)#返回所有找到标签的整体html #获取标签内的文本 soup.tagName.text soup.tagName.get_text() soup.tagName.string #获取标签中的属性值 soup.tagName['attrName'] 1.聚焦爬虫:爬取页面中指定的页面内容。 2.编码流程: 指定url发起请求获取响应数据数据解析持久化存储 3.数据解析方式分类: 正则表达式正则表达式的语法汇总_神奇洋葱头的博客-CSDN博客_正则表达式 结束符bs4模块Python中BeautifulSoup库的用法_阎_松的博客xpath模块【译】:lxml.etree官方文档_anywen5590的博客-CSDN博客 4.xpath数据解析原理概述: 解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储,列如图片在 xpath是最常用最便捷高效的一种解析方式,不仅python中可以用,c语言,java中也可以用,具有通用性。 xpath解析原理: 1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。 2.调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获。 5.xpath安装(1)终端输入 pip install lxml(2)pycharm包管理器安装
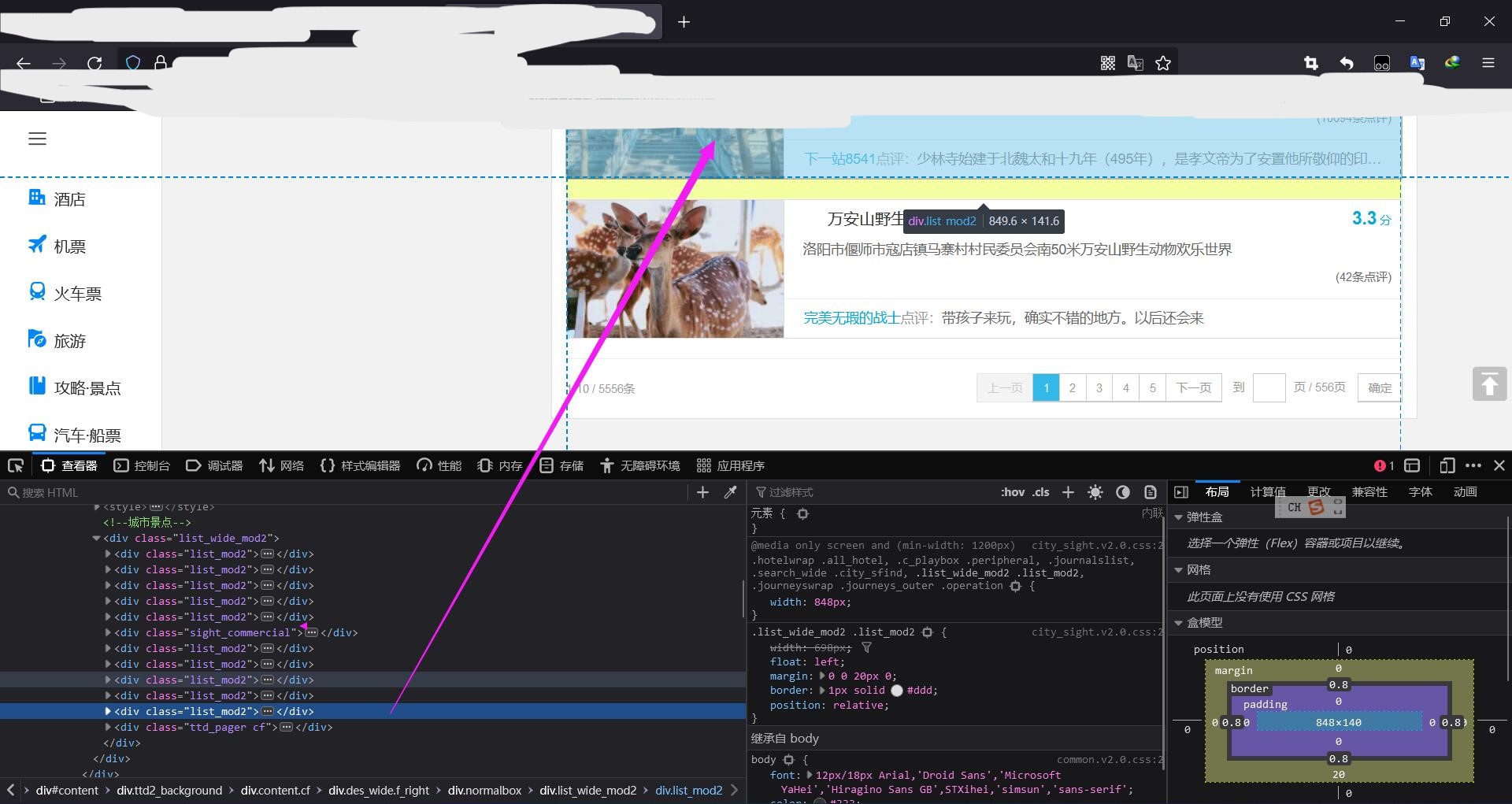
(1)导入lxml的etree模块 from lxml import etree(2)实例化etree对象: 1.将本地的html文档中的数据加载到该对象中; etree.parse(filePath) 2.将互联网上获取的页面源码加载到该对象中; etree.HTML('page_text') (3)xpath查找 标签定位 xpath('xpath表达式') (4)标签内容的处理保存 7.xpath代码API#导入lxml的etree模块 from lxml import etree #实例化etree对象 tree=etree.HTML('page_text') page_text:网上获取的页面源码 #xpath查找 标签定位 tree.xpath('xpath表达式') tree.xpath('/html/body/div')#返回/html/body/div的div列表/:表示从根节点开始,表示下一个层级,直系 tree.xpath('//div')#返回所有div标签列表//:表示多个层级 tree.xpath('//div[@attrName="attrvalue"]')#返回所有有特殊属性的div标签列表attrName:属性名id,class,src等 attrvalue:属性值 tree.xpath('//div[3]')#返回所有div标签列表中第3个div,索引从1开始#取文本 tree.xpath('//div[3]/text()')[0]#返回所有div标签列表中第3个div中文本array数组[str],后面加上[0]就是取出文本 /text:表示直系文本内容 //text表示标签包括的所有文本内容 #取属性 tree.xpath('//div[3]/@attarName')#返回所有div标签列表中第3个div中attarName的值 8.爬取所有景点的评论,并单独形成景点文档网站地址: 举例网址 一、爬取所有景点名称和评分并单独形成文档:(1)打开F12 查看每个网页景点的html结构
每个景点都在div[@class="list_mod2"]中,其他的class是广告 (2)提取出一个景点查看html结构  万安山野生动物欢乐世界
洛阳市偃师市寇店镇马寨村村民委员会南50米万安山野生动物欢乐世界
3.3;分
(42条点评)
万安山野生动物欢乐世界
洛阳市偃师市寇店镇马寨村村民委员会南50米万安山野生动物欢乐世界
3.3;分
(42条点评)
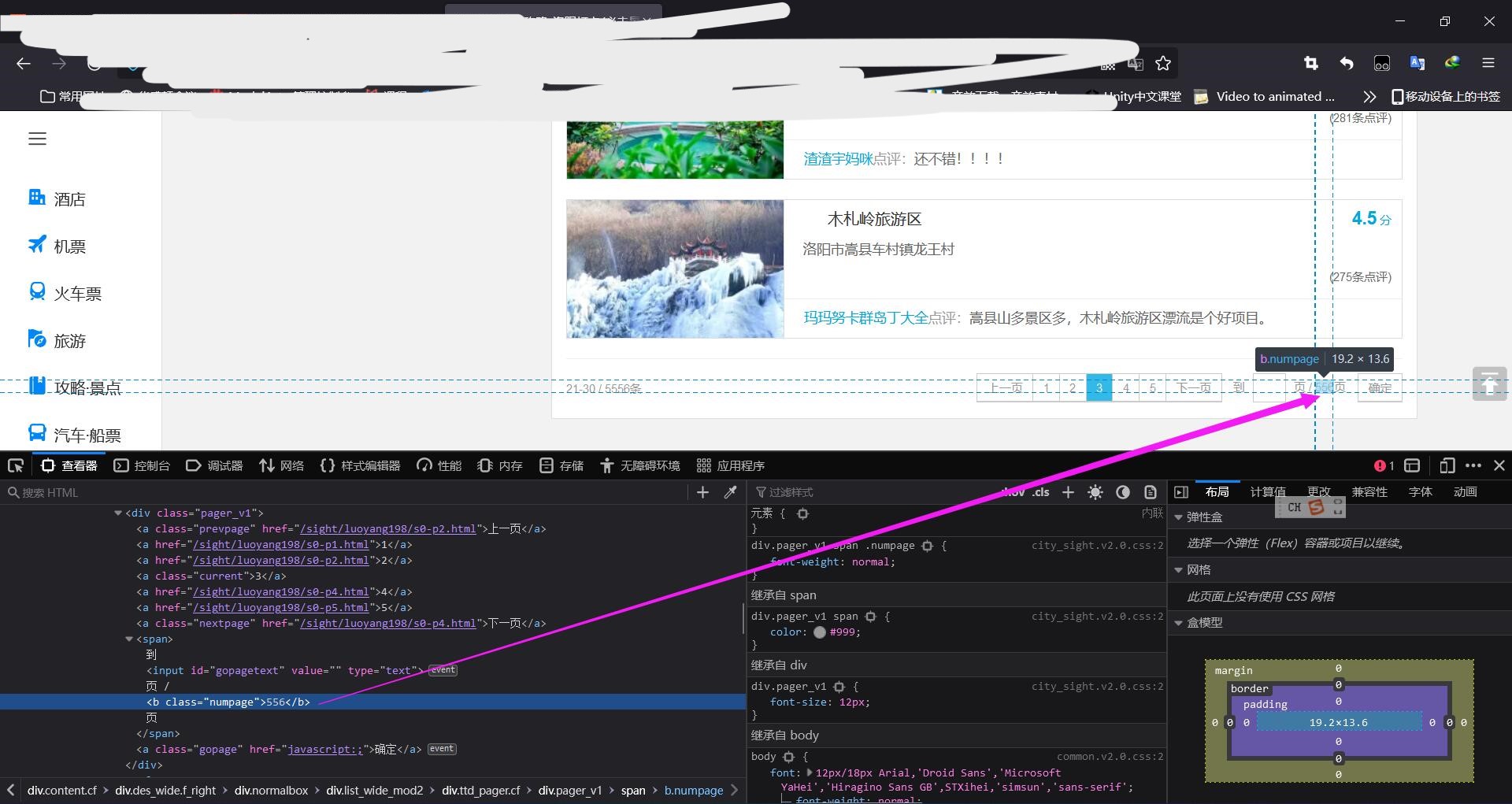
完美无瑕的战士点评:带孩子来玩,确实不错的地方。以后还会来 其中div[@class="list_mod2"]/div[@class="rdetailbox"]/dl/dt/a//text()里是景点名称 div[@class="list_mod2"]/div[@class="rdetailbox"]/dl/dt/a/@href是详细景点网址 div[@class="list_mod2"]//a[@class="score"]/text()里面是评分 (3)景点翻页 点击翻页发现网址有规律的发生了变化,只要动态拼凑网页就可以完成 那么怎么获取总页数呢? 通过html查看
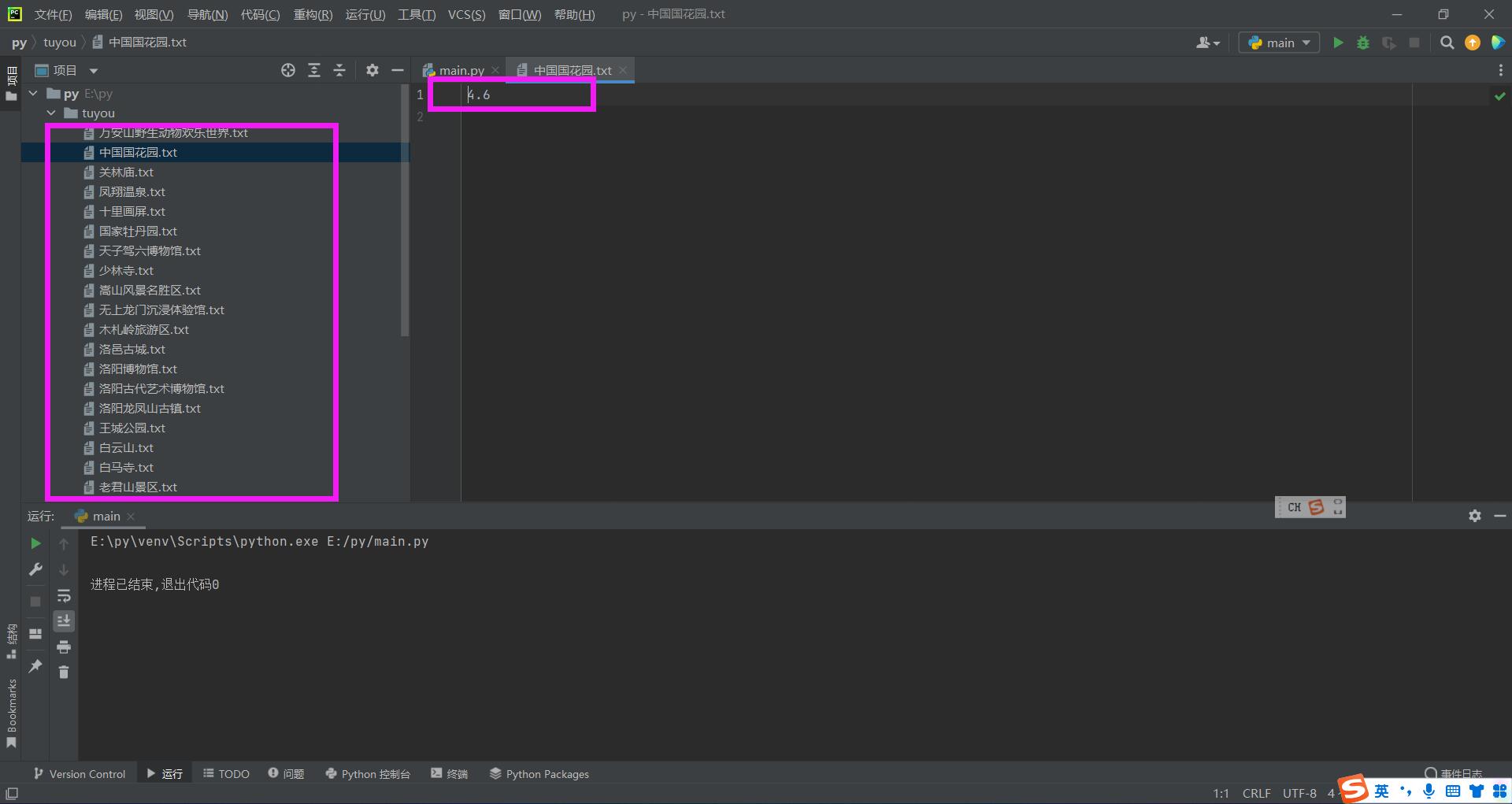
b class="numpage"里面包含了总页数 (4)代码开始 为了使得快速运行,不浪费时间,先测试爬取前3页景点,并单独形成文档和评分就可以 #4.1 from lxml import etree import requests import os #创建放景点评论的文件夹 if not os.path.exists("./tuyou"): os.mkdir("./tuyou") # 指定所有景点的主目录网址url mainurl = "https://you.ctrip.com/sight/luoyang198.html" # UA伪装 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:105.0) Gecko/20100101 Firefox/105.0", } #获取响应数据 one_page_text = requests.get(url=mainurl, headers=headers).text#注意转成text类型 #实例化etree对象 tree=etree.HTML(one_page_text) #获取总页数 numpage=tree.xpath('//b[@class="numpage"]/text()')[0] for i in range(1,4):#爬取前3页,爬取所有页将4换成numpage url='https://you.ctrip.com/sight/luoyang198/s0-p'+str(i)+'.html' page_text = requests.get(url=url, headers=headers).text # 实例化etree对象 tree = etree.HTML(page_text) #获取每个景点的列表 div_list=tree.xpath('//div[@class="list_mod2"]') for div in div_list: #获取每个景点的名称 name=div.xpath('.//dt/a/text()')[0] #获取每个景点的评分 try:#有些景点没有评分,需要错误捕获 score=div.xpath('.//a[@class="score"]/strong/text()')[0] except: score="暂无评分" #形成每个景点的文档 with open("./tuyou/"+name+".txt","w",encoding="utf-8") as f: f.write(score+"\n")
(1)进入详细景点网址查看结构
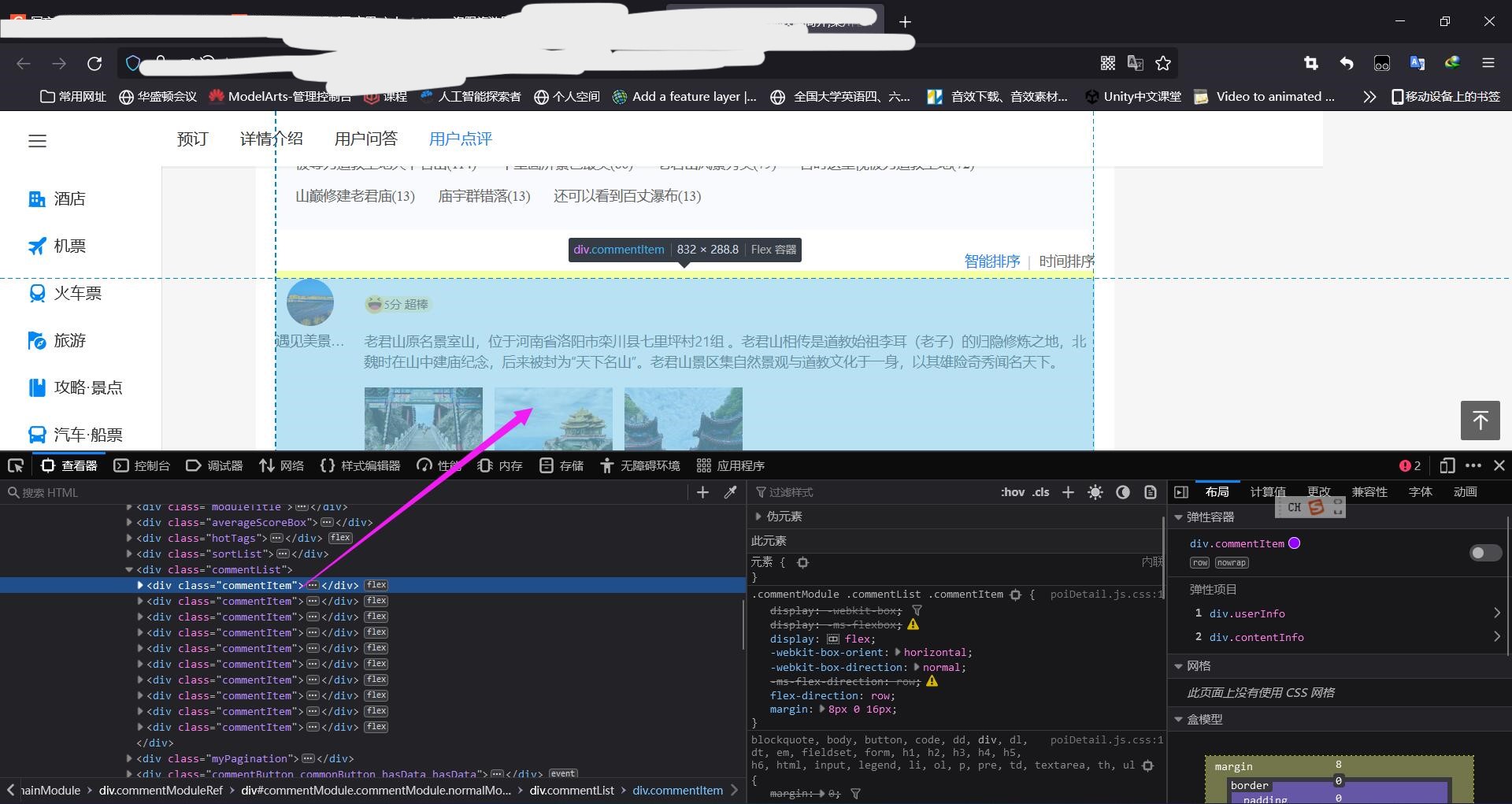
(2)提取出每一个评论查看HTML  遇见美景,快乐欣赏
遇见美景,快乐欣赏
 5分 超棒
老君山原名景室山,位于河南省洛阳市栾川县七里坪村21组 。老君山相传是道教始祖李耳(老子)的归隐修炼之地,北魏时在山中建庙纪念,后来被封为“天下名山”。老君山景区集自然景观与道教文化于一身,以其雄险奇秀闻名天下。 5分 超棒
老君山原名景室山,位于河南省洛阳市栾川县七里坪村21组 。老君山相传是道教始祖李耳(老子)的归隐修炼之地,北魏时在山中建庙纪念,后来被封为“天下名山”。老君山景区集自然景观与道教文化于一身,以其雄险奇秀闻名天下。
   2022-09-12IP属地:上海
举报13
2022-09-12IP属地:上海
举报13
评论在里面 (3)代码更新 #4..2 from lxml import etree import requests import os #创建放景点评论的文件夹 if not os.path.exists("./tuyou"): os.mkdir("./tuyou") # 指定所有景点的主目录网址url mainurl = "https://you.ctrip.com/sight/luoyang198.html" # UA伪装 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:105.0) Gecko/20100101 Firefox/105.0", } #获取响应数据 one_page_text = requests.get(url=mainurl, headers=headers).text#注意转成text类型 #实例化etree对象 tree=etree.HTML(one_page_text) #获取总页数 numpage=tree.xpath('//b[@class="numpage"]/text()')[0] for i in range(1,4):#爬取前3页,爬取所有页将4换成numpage page_url='https://you.ctrip.com/sight/luoyang198/s0-p'+str(i)+'.html' page_text = requests.get(url=page_url, headers=headers).text # 实例化etree对象 tree = etree.HTML(page_text) #获取每个景点的列表 div_list=tree.xpath('//div[@class="list_mod2"]') for div in div_list: #获取每个景点的名称 name=div.xpath('.//dt/a/text()')[0] #获取每个景点的评分 try:#有些景点没有评分,需要错误捕获 score=div.xpath('.//a[@class="score"]/strong/text()')[0] except: score="暂无评分" #获取每个景点的请求网址 url=div.xpath('.//dt/a/@href')[0] place_text = requests.get(url=url, headers=headers).text # 实例化etree对象 tree = etree.HTML(place_text) #获取评论列表 newcomment_list=[] comment_list=tree.xpath('//div[@class="commentDetail"]/text()') #单独评论处理 for comment in comment_list: comment=repr(comment)#不转义字符,保证每个人评论只是占一行 newcomment_list.append(comment) #形成每个景点的文档 with open("./tuyou/"+name+".txt","w",encoding="utf-8") as f: f.write(score+"\n") f.write("\n".join(newcomment_list)+"\n") print("已保存"+name)
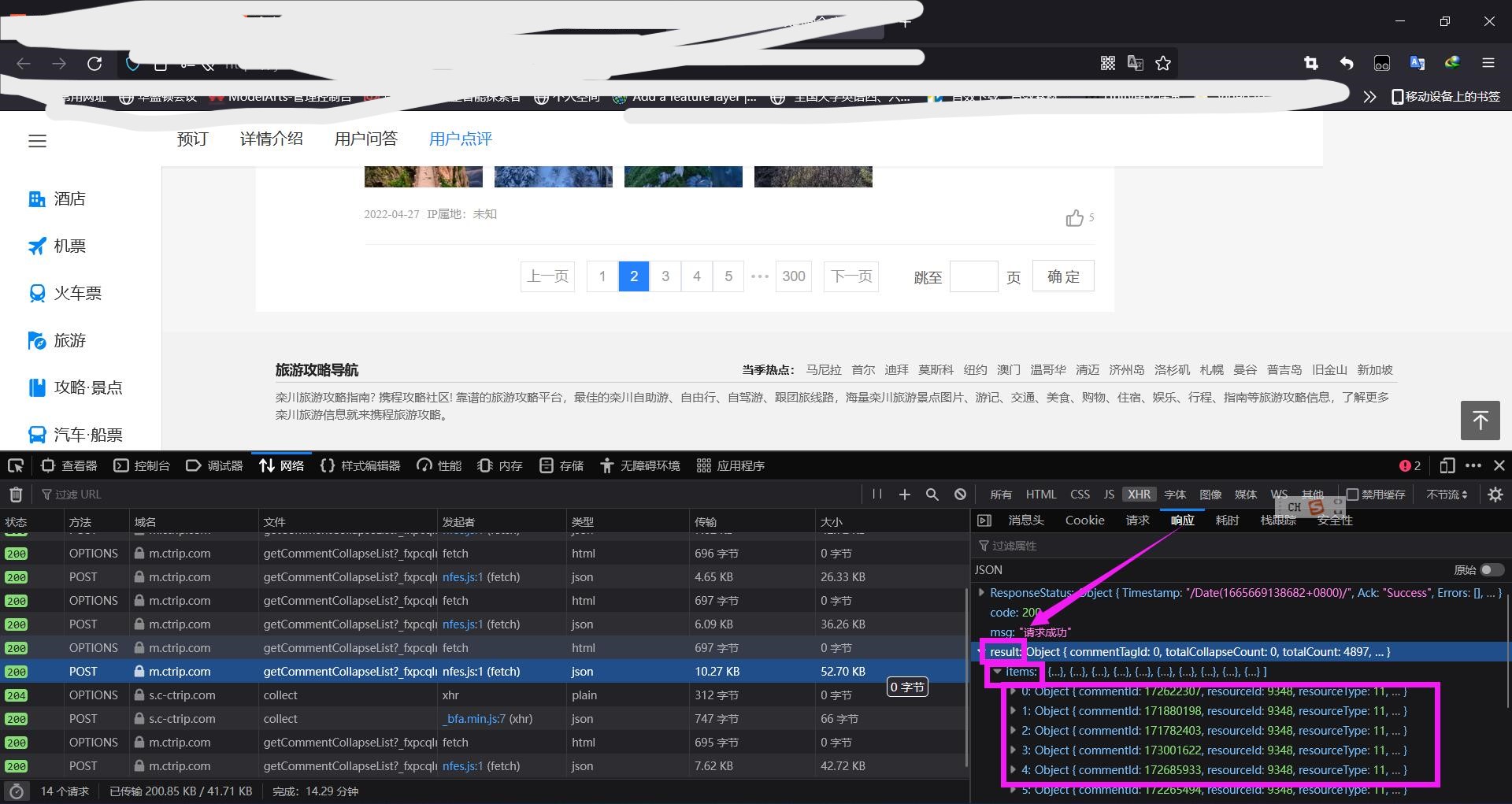
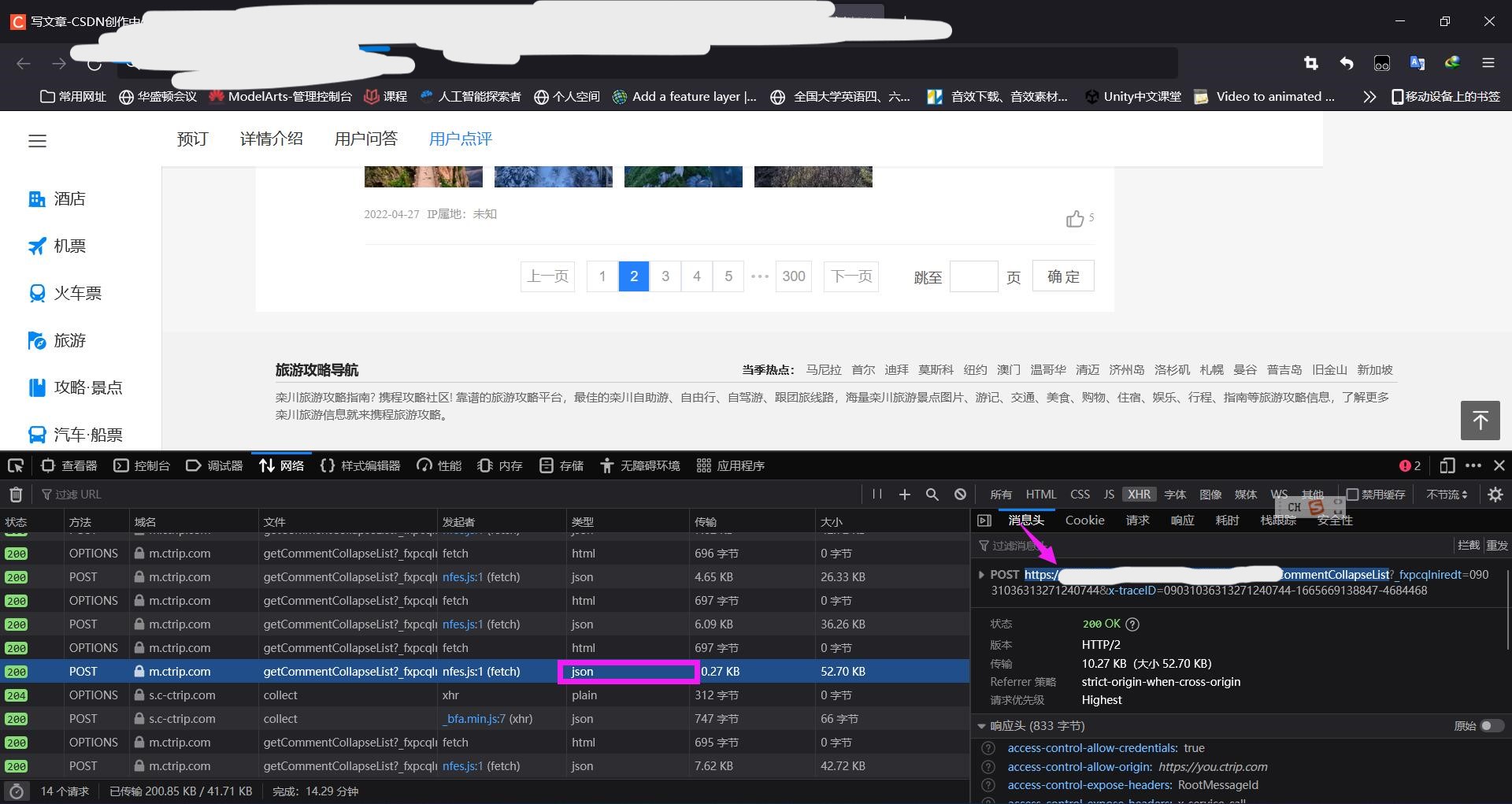
点击翻页的时候,发现网址没有变化,是由于这是局部页面刷新,所以需要打开F12的抓包工具分析,找到请求的Ajax
查看请求地址和返回数据类型
查看返回数据结构
紧盯着post请求头参数格式可以得出以下结论: 翻页可以发现: "pageIndex": 1,是代表当前页数 去别的景点翻页评论发现 "poiId": 77806,代表是景点的id post每个响应头中的result中包含了object数组,其中最重要的是content评论部分 content:老君山原名景室山,位于河南省洛阳市栾川县七里坪村21组 。老君山相传是道教始祖李耳(老子)的归隐修炼之地,北魏时在山中建庙纪念,后来被封为“天下名山”。老君山景区集自然景观与道教文化于一身,以其雄险奇秀闻名天下。还有totalCount代表评论总数量,而每个页码有十条数据,就可以算出总共有多少页了(网站只是展示出前300页) 总结:所有评论可以只通过Ajax请求获取,所以我们只需要请求Ajax来获取评论 难点:请求头参数"poiId",代表景点ID的参数没有规律,不知道怎么获取,所以无法动态发送Ajax请求,留下疑问?以后来补充。 总结,这节课我们学了什么?#导入lxml的etree模块 from lxml import etree #实例化etree对象 tree=etree.HTML('page_text') #xpath查找 标签定位 tree.xpath('xpath表达式') tree.xpath('/html/body/div')tree.xpath('//div')tree.xpath('//div[@attrName="attrvalue"]')#取文本 tree.xpath('//div[3]/text()')[0] #取属性 tree.xpath('//div[3]/@attarName') |


【本文地址】
今日新闻 |
推荐新闻 |