【Python】上海小区数据爬取和清洗(安居客、链家和房天下) |
您所在的位置:网站首页 › 南京所有的小区名称 › 【Python】上海小区数据爬取和清洗(安居客、链家和房天下) |
【Python】上海小区数据爬取和清洗(安居客、链家和房天下)
|
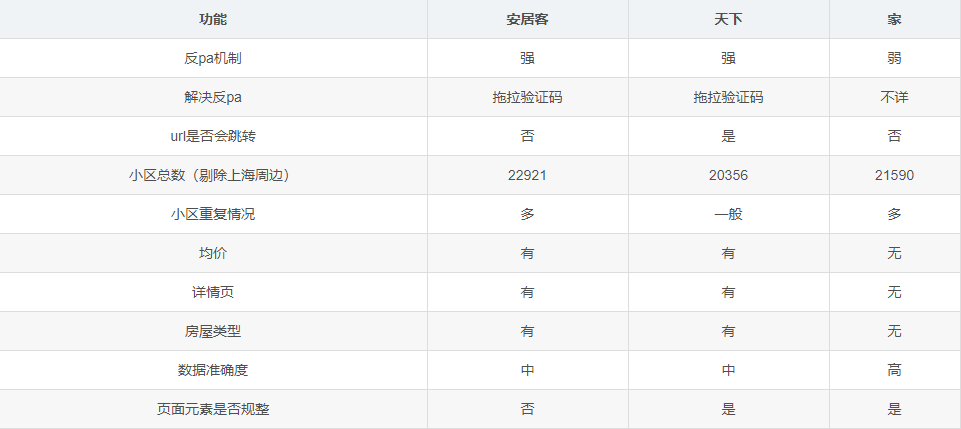
一、前言:安居客、链家和房天下是目前网上可以获取小区数据较为精准的网站,之前已经发过链家和房天下的部分区域(仅浦东)获取攻略。这次因为工作原因,需要获取整个上海的所有小区数据(仅别墅和住宅),所以过年这几天在不断的数据分析、获取、清洗和验证。特此记录一下,也把代码和各位分享。 二、爬取思路:不管是安居客、链家还是房天下,获取数据的思路都是一致的:1、获取不同行政区的网址2、获取不同行政区下不同商圈/街镇的网址3、获取不同行政区下每一个商圈/街镇中所有小区的网址4、根据3中获得的网址,把需要的页面元素爬下来 三、安居客、房天下和链家对比:
我把三个网站的数据都爬下来了,不过最后只用了安居客的数据 四、链家代码  1 import requests
2 from bs4 import BeautifulSoup
3 import re
4 import time
5 import traceback
6 import math
7
8 headers = {
9 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
10 'Host': 'sh.lianjia.com',
11 'Cookie': ''
12 }
13
14 def read_Lregion_dict():
15 '''读取行政区域的文件,并输出为字典'''
16 with open('行政区url.txt', 'r') as f:
17 large_region_list = f.readlines()
18 large_region_dict = {}
19 for ele in large_region_list:
20 url, region = ele.split(' ')
21 region = region.replace('\n', '')
22 large_region_dict[url] = region
23 return large_region_dict
24
25 def get_jiezhen_urls():
26 '''获取街镇的url'''
27 large_region_dict = read_Lregion_dict()
28 small_region_dict = {}
29 for k, v in large_region_dict.items():
30 if v != '上海周边':
31 url = 'https://sh.lianjia.com' + k
32 r = requests.get(url=url, headers=headers)
33 soup = BeautifulSoup(r.text, 'lxml')
34 a = soup.find(name='div', attrs={'data-role': 'ershoufang'})
35 esf_urls = a.find_all(name='a')
36 for ele in esf_urls:
37 href = ele.attrs['href']
38 name = ele.string
39 if name in large_region_dict.values():
40 continue
41 else:
42 small_region_dict[href] = name
43 with open('街镇url.txt', 'a', encoding='utf-8') as file:
44 file.write(','.join([v, name, href]))
45 file.write('\n')
46 print(v, name, href)
47
48 def region_total(url):
49 '''获取该区域的小区数量'''
50 url = r"https://sh.lianjia.com" + url + '?from=rec'
51 r = requests.get(url=url, headers=headers)
52 soup = BeautifulSoup(r.text, 'lxml')
53 total_find = soup.find(name='h2', attrs={'class': 'total fl'})
54 total_num = int(total_find.find(name='span').string.strip())
55 return total_num
56
57 def get_all_urls():
58 '''获取所有小区名字和链接'''
59 with open('街镇url.txt', 'r', encoding='utf-8') as f:
60 small_region_list = f.readlines()
61 for ele in small_region_list:
62 l_region, s_region, url = ele.split(',')
63 url = url.replace('\n', '')
64 total_num = region_total(url)
65 pages = int(math.ceil(int(total_num)/30))
66 for i in range(1, pages+1):
67 if i == 1:
68 i = ""
69 else:
70 i = 'pg' + str(i)
71 tmp_url = r"https://sh.lianjia.com" + url + i
72 r = requests.get(url=tmp_url, headers=headers)
73 soup = BeautifulSoup(r.text, 'lxml')
74 for j in soup.find_all(name='div', attrs={'class': 'title'}):
75 community = str(j)
76 if '''target="_blank"''' in community:
77 community_list = re.search('''(.*?).*?''', community)
78 community_url = community_list.group(1)
79 community_name = community_list.group(2)
80 with open('小区url.txt', 'a', encoding='utf-8') as file:
81 file.write(','.join([l_region, s_region, community_name, community_url]))
82 file.write('\n')
83 time.sleep(1)
84 print('{}, {}总共有{}个小区,共有{}页,已全部url爬取完成!'.format(l_region, s_region, total_num, pages))
85
86 def get_communityInfo(l_region, s_region, community_name, community_url):
87 '''获取某个小区的信息'''
88 r = requests.get(url=community_url, headers=headers)
89 soup = BeautifulSoup(r.text, 'lxml')
90 try:
91 unitPrice = soup.find(name='span', attrs={'class': 'xiaoquUnitPrice'}).string #小区均价
92 except:
93 unitPrice = '空'
94 try:
95 address = soup.find(name='div', attrs={'class': 'detailDesc'}).string #小区地址
96 address = '"' + address + '"'
97 except:
98 address = '空'
99 try:
100 xiaoquInfo = soup.find_all(name='span', attrs={'class': 'xiaoquInfoContent'}) #小区信息
101 xiaoquInfo_list = [l_region, s_region]
102 community_name = '"' + community_name + '"'
103 xiaoquInfo_list.append(community_name)
104 xiaoquInfo_list.append(address)
105 xiaoquInfo_list.append(unitPrice)
106 for info in xiaoquInfo:
107 xiaoquInfo_list.append(info.string)
108 xiaoquInfo_list.pop()
109 export_communityInfo(xiaoquInfo_list)
110 time.sleep(1)
111 print('已爬取{},{}的{}信息'.format(l_region, s_region, community_name))
112 except:
113 print('{},{}的{}爬取错误,url是{}'.format(l_region, s_region, community_name, community_url))
114
115 def export_communityInfo(xiaoquInfo_list):
116 '''导出小区信息'''
117 with open('上海地区小区信息.txt', 'a', encoding='utf-8') as file:
118 file.write(','.join(xiaoquInfo_list))
119 file.write('\n')
120
121 if __name__ == "__main__":
122 # get_jiezhen_urls() #获取街镇的url
123 # get_all_urls() #获取所有小区名字和链接
124 with open('小区url.csv', 'r') as f:
125 xiaoqu_list = f.readlines()
126 for ele in xiaoqu_list:
127 l_region, s_region, community_name, community_url = ele.split(',')
128 community_url = community_url.replace('\n', '')
129 try:
130 get_communityInfo(l_region, s_region, community_name, community_url)
131 except:
132 traceback.print_exc()
133 break
View Code
1 import requests
2 from bs4 import BeautifulSoup
3 import re
4 import time
5 import traceback
6 import math
7
8 headers = {
9 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
10 'Host': 'sh.lianjia.com',
11 'Cookie': ''
12 }
13
14 def read_Lregion_dict():
15 '''读取行政区域的文件,并输出为字典'''
16 with open('行政区url.txt', 'r') as f:
17 large_region_list = f.readlines()
18 large_region_dict = {}
19 for ele in large_region_list:
20 url, region = ele.split(' ')
21 region = region.replace('\n', '')
22 large_region_dict[url] = region
23 return large_region_dict
24
25 def get_jiezhen_urls():
26 '''获取街镇的url'''
27 large_region_dict = read_Lregion_dict()
28 small_region_dict = {}
29 for k, v in large_region_dict.items():
30 if v != '上海周边':
31 url = 'https://sh.lianjia.com' + k
32 r = requests.get(url=url, headers=headers)
33 soup = BeautifulSoup(r.text, 'lxml')
34 a = soup.find(name='div', attrs={'data-role': 'ershoufang'})
35 esf_urls = a.find_all(name='a')
36 for ele in esf_urls:
37 href = ele.attrs['href']
38 name = ele.string
39 if name in large_region_dict.values():
40 continue
41 else:
42 small_region_dict[href] = name
43 with open('街镇url.txt', 'a', encoding='utf-8') as file:
44 file.write(','.join([v, name, href]))
45 file.write('\n')
46 print(v, name, href)
47
48 def region_total(url):
49 '''获取该区域的小区数量'''
50 url = r"https://sh.lianjia.com" + url + '?from=rec'
51 r = requests.get(url=url, headers=headers)
52 soup = BeautifulSoup(r.text, 'lxml')
53 total_find = soup.find(name='h2', attrs={'class': 'total fl'})
54 total_num = int(total_find.find(name='span').string.strip())
55 return total_num
56
57 def get_all_urls():
58 '''获取所有小区名字和链接'''
59 with open('街镇url.txt', 'r', encoding='utf-8') as f:
60 small_region_list = f.readlines()
61 for ele in small_region_list:
62 l_region, s_region, url = ele.split(',')
63 url = url.replace('\n', '')
64 total_num = region_total(url)
65 pages = int(math.ceil(int(total_num)/30))
66 for i in range(1, pages+1):
67 if i == 1:
68 i = ""
69 else:
70 i = 'pg' + str(i)
71 tmp_url = r"https://sh.lianjia.com" + url + i
72 r = requests.get(url=tmp_url, headers=headers)
73 soup = BeautifulSoup(r.text, 'lxml')
74 for j in soup.find_all(name='div', attrs={'class': 'title'}):
75 community = str(j)
76 if '''target="_blank"''' in community:
77 community_list = re.search('''(.*?).*?''', community)
78 community_url = community_list.group(1)
79 community_name = community_list.group(2)
80 with open('小区url.txt', 'a', encoding='utf-8') as file:
81 file.write(','.join([l_region, s_region, community_name, community_url]))
82 file.write('\n')
83 time.sleep(1)
84 print('{}, {}总共有{}个小区,共有{}页,已全部url爬取完成!'.format(l_region, s_region, total_num, pages))
85
86 def get_communityInfo(l_region, s_region, community_name, community_url):
87 '''获取某个小区的信息'''
88 r = requests.get(url=community_url, headers=headers)
89 soup = BeautifulSoup(r.text, 'lxml')
90 try:
91 unitPrice = soup.find(name='span', attrs={'class': 'xiaoquUnitPrice'}).string #小区均价
92 except:
93 unitPrice = '空'
94 try:
95 address = soup.find(name='div', attrs={'class': 'detailDesc'}).string #小区地址
96 address = '"' + address + '"'
97 except:
98 address = '空'
99 try:
100 xiaoquInfo = soup.find_all(name='span', attrs={'class': 'xiaoquInfoContent'}) #小区信息
101 xiaoquInfo_list = [l_region, s_region]
102 community_name = '"' + community_name + '"'
103 xiaoquInfo_list.append(community_name)
104 xiaoquInfo_list.append(address)
105 xiaoquInfo_list.append(unitPrice)
106 for info in xiaoquInfo:
107 xiaoquInfo_list.append(info.string)
108 xiaoquInfo_list.pop()
109 export_communityInfo(xiaoquInfo_list)
110 time.sleep(1)
111 print('已爬取{},{}的{}信息'.format(l_region, s_region, community_name))
112 except:
113 print('{},{}的{}爬取错误,url是{}'.format(l_region, s_region, community_name, community_url))
114
115 def export_communityInfo(xiaoquInfo_list):
116 '''导出小区信息'''
117 with open('上海地区小区信息.txt', 'a', encoding='utf-8') as file:
118 file.write(','.join(xiaoquInfo_list))
119 file.write('\n')
120
121 if __name__ == "__main__":
122 # get_jiezhen_urls() #获取街镇的url
123 # get_all_urls() #获取所有小区名字和链接
124 with open('小区url.csv', 'r') as f:
125 xiaoqu_list = f.readlines()
126 for ele in xiaoqu_list:
127 l_region, s_region, community_name, community_url = ele.split(',')
128 community_url = community_url.replace('\n', '')
129 try:
130 get_communityInfo(l_region, s_region, community_name, community_url)
131 except:
132 traceback.print_exc()
133 break
View Code
五、房天下代码
1 import requests
2 from bs4 import BeautifulSoup
3 import pandas as pd
4 import time
5 import traceback
6
7 headers = {
8 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
9 'cookie': ''''''
10 }
11
12 def get_true_url(old_url):
13 '''获得正确的url'''
14 r = requests.get(url=old_url, headers=headers)
15 if r'跳转...' in r.text:
16 soup = BeautifulSoup(r.text, 'lxml')
17 new_url = soup.find(name='a', attrs={'class': 'btn-redir'}).attrs['href']
18 return new_url
19 return old_url
20
21 def get_region_urls():
22 '''获得上海行政区中不同街镇的url和名称'''
23 sh_dict = {'浦东': '25', '嘉定': '29', '宝山': '30', '闵行': '18', '松江': '586', '普陀': '28',
24 '静安': '21', '黄浦': '24', '虹口': '23', '青浦': '31', '奉贤': '32', '金山': '35',
25 '杨浦': '26', '徐汇': '19', '长宁': '20', '崇明': '996'}
26 for l_region_name, l_region_url in sh_dict.items():
27 url = r"https://sh.esf.fang.com/housing/" + l_region_url + '__0_3_0_0_1_0_0_0/'
28 true_url = get_true_url(url)
29 r = requests.get(url=true_url, headers=headers)
30 soup = BeautifulSoup(r.text, 'lxml')
31 a = soup.find(name='p', attrs={'id': 'shangQuancontain', 'class': 'contain'})
32 for i in a.find_all(name='a'):
33 if i.string != '不限':
34 this_url = r"https://sh.esf.fang.com" + i.attrs['href']
35 this_url_list = get_region_url(this_url)
36 with open('上海地区街镇url.txt', 'a', encoding='utf-8') as file:
37 for tmp_url in this_url_list:
38 file.write(','.join([l_region_name, i.string, tmp_url]))
39 file.write('\n')
40 print('{}已完成'.format(l_region_name))
41
42 def get_region_url(old_url):
43 '''获得这个区域的其它page_url'''
44 true_url = get_true_url(old_url)
45 r = requests.get(url=true_url, headers=headers)
46 soup = BeautifulSoup(r.text, 'lxml')
47 page_url = soup.find(name='div', attrs={'class': 'fanye gray6'})
48 page_url_list = []
49 page_url_list.append(old_url)
50 for j in page_url.find_all(name='a'):
51 if 'href' in j.attrs:
52 temp_url = r'https://sh.esf.fang.com/' + j.attrs['href'][1:]
53 if temp_url not in page_url_list:
54 page_url_list.append(temp_url)
55 return page_url_list
56
57 def get_xiaoqu_url(bigregion, smallregion, old_url):
58 '''获得某区域某一页的小区信息和url'''
59 true_url = get_true_url(old_url)
60 r = requests.get(url=true_url, headers=headers)
61 soup = BeautifulSoup(r.text, 'lxml')
62 j = 0
63 for i in soup.find_all(name='a', attrs={'class': 'plotTit', 'target': '_blank'}):
64 xiaoqu_type = soup.find('a', text=i.string, attrs={'class': 'plotTit', 'target': '_blank'}).parent.find('span', attrs={'class':'plotFangType'}).string
65 xiaoqu_name = i.string
66 xiaoqu_url = 'https://sh.esf.fang.com/' + i.attrs['href'][1:]
67 xiaoqu_url = xiaoqu_url.replace('.htm', '/housedetail.htm')
68 print(bigregion, smallregion, xiaoqu_name, xiaoqu_type, xiaoqu_url)
69 j += 1
70 with open('上海地区小区url.txt', 'a', encoding='utf-8') as file:
71 file.write(','.join([bigregion, smallregion, xiaoqu_name, xiaoqu_type, xiaoqu_url]))
72 file.write('\n')
73 time.sleep(1)
74 print(bigregion, smallregion, old_url, '所有小区url获取完毕,共有{}条数据'.format(j))
75 print('-'*100)
76
77 def get_all_urls(last_url=None):
78 '''获得所有小区的URL'''
79 '''获得结果后还需要清洗一下,因为有些小区跨区域,所以会有重复'''
80 with open('上海地区街镇url.txt', 'r', encoding='utf-8') as f:
81 region_list = f.readlines()
82 event_tracking = False
83 for i in range(len(region_list)):
84 l_region, s_region, url = region_list[i].split(',')
85 url = url.replace('\n', '')
86 if last_url == url:
87 event_tracking = True
88 if event_tracking:
89 print(l_region, s_region, url)
90 get_xiaoqu_url(l_region, s_region, url)
91
92 def get_total_informations(l_region, s_region, community_name, community_type, community_url):
93 '''爬取某个小区的有用信息'''
94 r = requests.get(url=community_url, headers=headers)
95 soup = BeautifulSoup(r.text, 'lxml')
96 informations = soup.find(name='div', attrs={'class': 'village_info base_info'})
97 if not informations:
98 print('{}, {}, {}, {}爬取失败!'.format(l_region, s_region, community_name, community_url))
99 return None
100 else:
101 all_info = [l_region, s_region, community_name, community_type]
102 for ele in ['本月均价', '小区地址', '产权描述', '环线位置', '建筑年代', '建筑面积', '占地面积', '房屋总数', '楼栋总数', '绿 化 率', '容 积 率', '物 业 费', '开 发 商', '物业公司']:
103 try:
104 all_info.append(informations.find('span', text=ele).parent.find(name='p').text.strip().replace('\r', '').replace('\n', '、').replace('\t', '').replace(',', ','))
105 except:
106 try:
107 all_info.append(informations.find('span', text=ele).parent.find(name='a').text.strip().replace('\r', '').replace('\n', '、').replace('\t', '').replace(',', ','))
108 except:
109 all_info.append('')
110 return all_info
111
112 def get_data(last_url=None):
113 '''主程序,爬所有小区信息'''
114 with open('上海地区小区url.txt', 'r', encoding='utf-8') as f:
115 village_list = f.readlines()
116 error_count = 0
117 if last_url == None:
118 event_tracking = True
119 else:
120 event_tracking = False
121 for i in range(len(village_list)):
122 l_region, s_region, community_name, community_type, community_url = village_list[i].split(',')
123 community_url = community_url.replace('\n', '')
124 if last_url == community_url:
125 event_tracking = True
126 if event_tracking == True:
127 if community_type=='住宅' or community_type=='别墅':
128 # print(l_region, s_region, community_name, community_type,community_url)
129 try:
130 with open('上海小区数据.txt', 'a', encoding='utf-8') as file:
131 back = get_total_informations(l_region, s_region, community_name, community_type, community_url)
132 if not back:
133 if error_count>=2:
134 break
135 else:
136 error_count +=1
137 time.sleep(1)
138 continue
139 else:
140 error_count = 0
141 file.write(','.join(back))
142 file.write('\n')
143 print('{}, {}, {}, {}爬取成功!'.format(l_region, s_region, community_name, community_type, community_url))
144 time.sleep(1)
145 except:
146 print('{}, {}, {}, {}爬取失败!'.format(l_region, s_region, community_name, community_url))
147 traceback.print_exc()
148 break
149 else:
150 continue
151
152 if __name__ == "__main__":
153 get_region_urls() #得上海行政区中不同街镇的url和名称
154 get_xiaoqu_url() #获得某区域某一页的小区信息和url,这里应该是遍历,代码不完全
155 get_data() #爬取所有小区信息
View Code
六、安居客代码
1 import requests
2 from bs4 import BeautifulSoup
3 import re
4 import time
5 import traceback
6
7 headers = {
8 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
9 'Cookie': ''
10 }
11
12 def get_jiezhen_urls():
13 '''获取所有街镇的url'''
14 lregion_dict = {'浦东': 'pudong', '闵行': 'minhang', '松江': 'songjiang', '宝山': 'baoshan', '嘉定':'jiading',
15 '徐汇':'xuhui', '青浦':'qingpu', '静安':'jingan', '普陀':'putuo', '杨浦':'yangpu',
16 '奉贤': 'fengxian', '黄浦':'huangpu', '虹口':'hongkou', '长宁':'changning','金山':'jinshan',
17 '崇明':'chongming'}
18 for k, v in lregion_dict.items():
19 url = 'https://shanghai.anjuke.com/community/' + v + '/'
20 r = requests.get(url=url, headers=headers)
21 soup = BeautifulSoup(r.text, 'lxml')
22 a = soup.find_all('li', attrs={'class': 'region-item'})
23 for i in range(19, len(a)):
24 temp = a[i].find('a')
25 with open('街镇url.txt', 'a', encoding='utf-8') as file:
26 file.write(','.join([k, temp.text, temp.attrs['href']]))
27 file.write('\n')
28 print('{}区域的url都爬取完毕!'.format(k))
29 time.sleep(1)
30
31 def region_total(url):
32 '''获取该区域的小区数量'''
33 r = requests.get(url=url, headers=headers)
34 soup = BeautifulSoup(r.text, 'lxml')
35 # print(soup)
36 total_find = soup.find(name='span', attrs={'class': 'total-info'})
37 total_num = int(total_find.text.replace('共找到 ', '').replace(' 个小区', ''))
38 return total_num
39
40 def get_all_urls():
41 '''获取所有小区名字和链接'''
42 with open('街镇url.txt', 'r', encoding='utf-8') as f:
43 small_region_list = f.readlines()
44 for ele in small_region_list:
45 l_region, s_region, url = ele.split(',')
46 url = url.replace('\n', '')
47 total_num = region_total(url)
48 pages = int(math.ceil(int(total_num)/25))
49 for i in range(1, pages+1):
50 i = 'p' + str(i) + '/'
51 tmp_url = url + i
52 r = requests.get(url=tmp_url, headers=headers)
53 soup = BeautifulSoup(r.text, 'lxml')
54 a = soup.find_all('div', attrs={'class': 'li-info'})
55 for ele in a:
56 xiaoqu_name = ele.find('div', attrs={'class': 'li-title'}).text.strip()
57 xiaoqu_address = ele.find('div', attrs={'class': 'props nowrap'}).text.split(' - ')[-1].strip()
58 xiaoqu_tag = ele.find_all('span', attrs={'class': 'prop-tag'})
59 xiaoqu_url = ele.find('span', text='小区解读').parent.find('a').attrs['href']
60 xiaoqu_url = xiaoqu_url.replace('props/sale', 'view')
61 tag_list = []
62 for tag in xiaoqu_tag:
63 if 'display:none' in str(tag):
64 continue
65 else:
66 tag_list.append(tag.text)
67 with open('小区url.txt', 'a', encoding='utf-8') as file:
68 file.write('$'.join([l_region, s_region, xiaoqu_name, xiaoqu_address, str(tag_list), xiaoqu_url]))
69 file.write('\n')
70 time.sleep(1)
71 print('{}, {}总共有{}个小区,共有{}页,已全部url爬取完成!'.format(l_region, s_region, total_num, pages))
72
73 def get_communityInfo(l_region, s_region, community_name, community_address, community_tag, community_url):
74 '''获取某个小区的信息'''
75 r = requests.get(url=community_url, headers=headers)
76 soup = BeautifulSoup(r.text, 'lxml')
77 # print(soup)
78 if '访问验证-ajk' in str(soup):
79 print('触发反爬机制了!url是', community_url)
80 exit()
81 else:
82 # print('pa虫运行正常!')
83 try:
84 unitPrice = soup.find(name='span', attrs={'class': 'average'}).string #小区均价
85 except:
86 unitPrice = '暂无均价'
87 xiaoquInfo = soup.find_all(name='div', attrs={'class': 'hover-inner'}) #小区信息
88 xiaoquInfo_list = [l_region, s_region, community_name, community_address, community_tag, unitPrice]
89 for info in xiaoquInfo:
90 temp = info.find('div', attrs={'class': 'hover-value'})
91 if temp:
92 xiaoquInfo_list.append(temp.text.replace('\n', '').strip())
93 export_communityInfo(xiaoquInfo_list)
94 time.sleep(0.5)
95 print('已pa取{},{}的{}信息'.format(l_region, s_region, community_name))
96
97 def export_communityInfo(xiaoquInfo_list):
98 '''导出小区信息'''
99 with open('上海地区小区信息.txt', 'a', encoding='utf-8') as file:
100 file.write('&'.join(xiaoquInfo_list))
101 file.write('\n')
102
103 if __name__ == "__main__":
104 # get_jiezhen_urls() #获取所有街镇的url
105 # get_all_urls() #获取所有小区名字和链接
106 with open('小区url.txt', 'r', encoding='utf-8') as f:
107 xiaoqu_list = f.readlines()
108 last_url = 'https://shanghai.anjuke.com/community/view/8338/'
109 stop_place = False
110 for ele in xiaoqu_list:
111 l_region, s_region, community_name, community_address, community_tag, community_url = ele.split('$')
112 community_url = community_url.replace('\n', '')
113 if community_url == last_url or last_url == '':
114 stop_place = True
115 if stop_place:
116 try:
117 get_communityInfo(l_region, s_region, community_name, community_address, community_tag, community_url)
118 except:
119 print('{}爬取失败,url是:{}'.format(community_name, community_url))
120 traceback.print_exc()
121 break
View Code
七、数据清洗和特征工程 获取的数据很脏,有重复值需要剔重,有异常值需要修正(比如明显是外环的数据被归纳为内环);需要根据业务场景,区分小区是否高档;需要根据需要,与内部数据结合…我这边就举例几种场景,供大家参考(以安居客数据为例): 1、从标签中判断小区是否靠近地铁 1 data['是否靠近地铁'] = data['标签'].apply(lambda x: '是' if '近地铁' in str(x) or '号线' in str(x) else '否') 2、从标签中判断环线位置 1 def huanxian_position(text): 2 '''环线位置''' 3 if '内环以内' in str(text): 4 return '内环以内' 5 elif '内中环之间' in str(text): 6 return '内中环之间' 7 elif '郊环以外' in str(text): 8 return '郊环以外' 9 elif '外郊环之间' in str(text): 10 return '外郊环之间' 11 elif '中外环之间' in str(text): 12 return '中外环之间' 13 else: 14 return np.nan 15 16 data['环线位置'] = data['标签'].apply(huanxian_position) 3、纠正环线位置 1 data_pivot = data.pivot_table(index='所属商圈', columns='环线位置', values='名称', aggfunc='count').reset_index() 2 data_pivot['环线位置2'] = '' 3 for i in range(data_pivot.shape[0]): 4 huan_dict = {} 5 huan_dict['中外环之间'] = data_pivot.iloc[i,1] 6 huan_dict['内中环之间'] = data_pivot.iloc[i,2] 7 huan_dict['内环以内'] = data_pivot.iloc[i,3] 8 huan_dict['外郊环之间'] = data_pivot.iloc[i,4] 9 huan_dict['郊环以外'] = data_pivot.iloc[i,5] 10 best_answer = '' 11 best_v = 0 12 for k,v in huan_dict.items(): 13 if v == np.nan: 14 continue 15 elif v >= best_v: 16 best_answer = k 17 else: 18 continue 19 data_pivot.iloc[i,6] = best_answer 20 21 huan_dict = {} 22 for k,v in zip(data_pivot['所属商圈'].values, data_pivot['环线位置2'].values): 23 huan_dict[k] = v 24 25 data['环线位置'] = data['所属商圈'].map(huan_dict) 4、根据竣工时间判断小区年龄 1 def new_age(text): 2 '''竣工时间推导小区年龄''' 3 if str(text) != 'nan': 4 text = 2022 - int(text.split('、')[0].replace('年','')) 5 return text 6 else: 7 return np.nan 8 9 data['小区年龄'] = data['竣工时间'].apply(new_age) 5、判断是否商务楼宇、园区等(链家) 1 def if_business(text): 2 '''判断是否商务楼宇、园区等''' 3 for ele in ['商务', '园区', '大厦', '写字楼', '广场']: 4 if ele in text: 5 return '是' 6 else: 7 return '否' 8 9 data['是否商务楼宇等'] = data['小区名称'].apply(if_business) 6、提取物业费上下限(链家) 1 def wuyefei_down(text): 2 '''输出物业费下限''' 3 if text is np.nan: 4 return np.nan 5 elif '至' not in text: 6 return text.replace('元/平米/月','') 7 else: 8 down, up = text.split('至') 9 return down.replace('元/平米/月','') 10 11 def wuyefei_up(text): 12 '''输出物业费上限''' 13 if text is np.nan: 14 return np.nan 15 elif '至' not in text: 16 return text.replace('元/平米/月','') 17 else: 18 down, up = text.split('至') 19 return up.replace('元/平米/月','') 20 21 data['物业费下限'] = data['物业费'].apply(wuyefei_down) 22 data['物业费上限'] = data['物业费'].apply(wuyefei_up) 7、判断小区名字是否有地址 1 def if_number(text): 2 '''判断小区名称里是否有数字''' 3 if bool(re.search(r'\d', text)): 4 return '是' 5 else: 6 return '否' 7 8 data['小区名称里是否有数字'] = data['名称'].apply(if_number) 8、匹配百度经纬度 1 from urllib.request import urlopen, quote 2 import json 3 import math 4 from math import radians, cos, sin, asin, sqrt 5 import requests 6 7 def getjwd_bd(address): 8 '''根据地址获得经纬度(百度)''' 9 try: 10 url = 'http://api.map.baidu.com/geocoding/v3/?address=' 11 output = 'json' 12 ak = '******'#需填入自己申请应用后生成的ak 13 add = quote(address) #本文城市变量为中文,为防止乱码,先用quote进行编码 14 url2 = url+add+'&output='+output+"&ak="+ak 15 req = urlopen(url2) 16 res = req.read().decode() 17 temp = json.loads(res) 18 lng = float(temp['result']['location']['lng']) # 经度 Longitude 简写Lng 19 lat = float(temp['result']['location']['lat']) # 纬度 Latitude 简写Lat 20 return lng, lat 21 except: 22 return np.nan, np.nan 23 24 for i in tqdm(range(data.shape[0])): 25 region = data.iloc[i, 0] 26 if region=='浦东': 27 region = '上海市浦东新区' 28 else: 29 region = '上海市'+ region + '区' 30 xiaoqu_name = data.iloc[i, 2] 31 address = data.iloc[i, 3] 32 if str(data.iloc[i, 19]) !='nan': 33 continue 34 else: 35 lng1, lat1 = getjwd_bd(region+address+xiaoqu_name) 36 if 120 |
【本文地址】
今日新闻 |
推荐新闻 |