使用python中的pandas对csv文件进行拆分 |
您所在的位置:网站首页 › 卖酒文案短句霸气图片搞笑 › 使用python中的pandas对csv文件进行拆分 |
使用python中的pandas对csv文件进行拆分
|
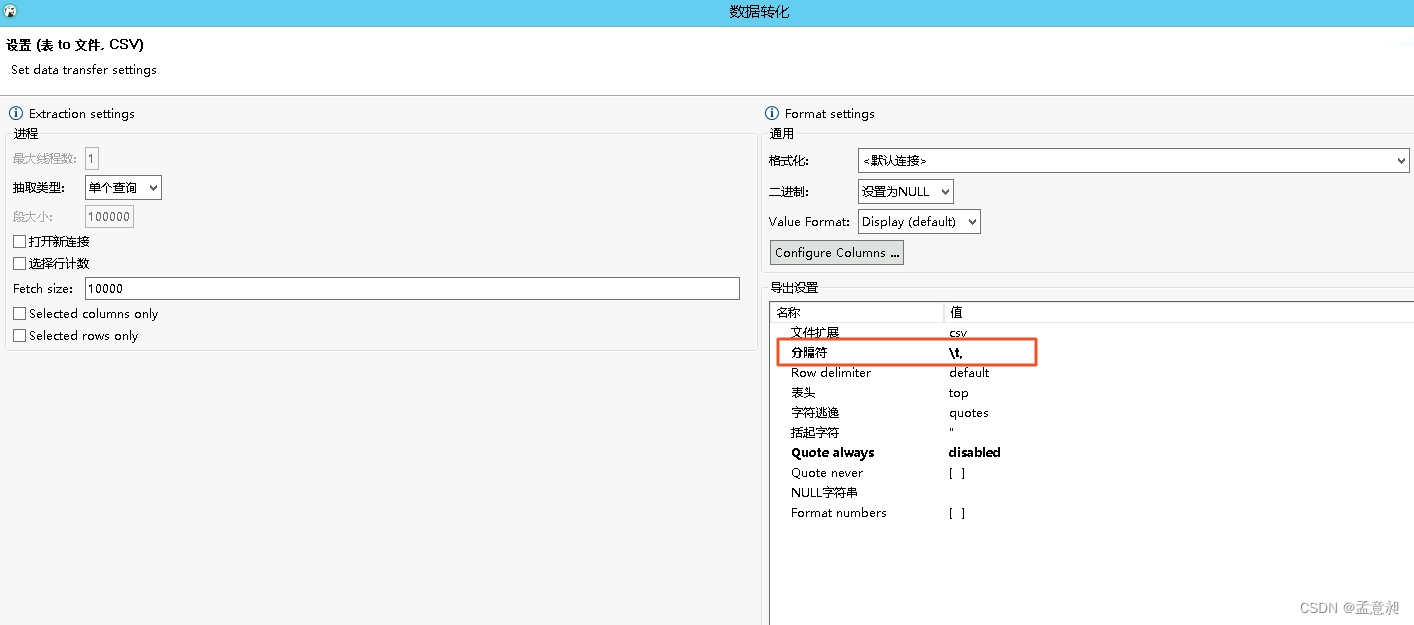
之前写过一篇对大型csv文件进行拆分的文章 使用python对csv文件进行拆分 本来用着还挺顺手,直到最近在工作里,需要拆分七八百万行的csv文件,用原来的那套逻辑,居然要跑一个多小时,未免有些太慢了,于是就改用pandas处理,只需要两分钟就可以搞定 首先是导入库和确定文件路径 import pandas as pd import datetime start_time = datetime.datetime.now() # 获取程序开始时间 path = r'D:\需要处理的文件.csv' result_path_dir = r'D:\拆分后的输出文件路径' #输出文件的路径这里设置start_time是为了获取程序开始执行的时间,在程序结束的时候,可以方便查看这套逻辑总共运行了多久 2. 读取csv文件 data = pd.read_csv(path,encoding='GBK',dtype = str)read_csv可以有很多参数,但在这次需求里,只需要目标文件、目标文件格式和字段类型就可以,本来这里是没加dtype参数的,但后来导出数据时,发现数字会变成科学计数法,不利于业务方使用,于是就可以在读取数据的时候,直接限制每个字段都是str类型,就可以避免这个问题 多说一句,目标文件我是从dbeaver导出来的,按默认导出方式,也会出现科学计数法的情况,可以通过更改配置的方式避免,这里也一并记录一下,把分隔符由默认的,改为\t, 其中,row_num字段就是目标文件的总行数,size就是根据需求,将大文件切分后生成小文件的行数,可以根据自己需要进行调整,这里设置的是30万行 4. 开始对目标文件进行切分 j = 1 for start in range(0, row_num, size): stop = start + size filename = "{}\切分后的小文件名称_{}.csv".format(result_path_dir,j) d = data[start: stop] #d['小保单号'] = d['小保单号'].astype(str) print("Saving file : " + filename + ", data size : " + str(len(d))) d.to_csv(filename,encoding='GBK', index=None) j = j + 1 end_time = datetime.datetime.now() # 获取程序结束时间 print(start_time) print(end_time)这里j变量的作用是为了方便我们知道,当前是切分了多少个小文件,而循环主体实现的功能,实际就是从0开始,每次切割size长度的行数,直到最后的row_num,期间每生成一个小文件都会输出到指定目录下,并拼接上j变量的值作为后缀,最后打印的两个时间,就可以看出来这段逻辑执行所需时间。个人亲测,这段逻辑用来切分800万行的csv文件,用时不到2分钟,最后附上完整代码 import pandas as pd import datetime start_time = datetime.datetime.now() # 获取程序开始时间 path = r'D:\需要处理的文件.csv' result_path_dir = r'D:\拆分后的输出文件路径' #输出文件的路径 data = pd.read_csv(path,encoding='GBK',dtype = str) #dtype = str # 获取文件总行数 row_num = len(data) # 确定每个小文件要包含的数据量 size = 300000 j = 1 for start in range(0, row_num, size): stop = start + size filename = "{}\切分后的小文件名称_{}.csv".format(result_path_dir,j) d = data[start: stop] #d['小保单号'] = d['小保单号'].astype(str) print("Saving file : " + filename + ", data size : " + str(len(d))) d.to_csv(filename,encoding='GBK', index=None) j = j + 1 end_time = datetime.datetime.now() # 获取程序结束时间 print(start_time) print(end_time) |
 3. 确认文件总行数和切分后的文件行数
3. 确认文件总行数和切分后的文件行数【本文地址】
今日新闻 |
推荐新闻 |