t检验的几种应用案例 |
您所在的位置:网站首页 › 单样本t检验案例分析例题 › t检验的几种应用案例 |
t检验的几种应用案例
|
根据如上数据,可计算样本均值xbar为550.75,样本标准差s为4.25,所以t统计量的值为0.706。 步骤四:对比结果下结论 对比计算的t统计量和理论t分布的临界值,如果统计量的值大于临界值,则拒绝原假设(即认为样本均值与总体均值之间存在显著的差异),否则接受原假设。参照t分布的临界值表,在置信水平为0.05,自由度为15的情况下,对应的临界值为0.821。对比发现,t统计量0.706是小于临界值0.821的,故不能拒绝原假设,即认为饮料净含量的检验结果是合格的。 在平时的学习或工作中,如需使用Python完成单样本t检验的落地,可以调用scipy的子模块stats中的ttest_1samp函数。接下来利用ttest_1samp函数,对如上介绍的饮料净含量数据作单样本t检验操作,代码如下: # 导入子模块 fromscipy importstats # 饮料净含量数据 data = [558,551,542,557,552,547,551,549,548,551,553,557,548,550,546,552] # 单样本t检验 stats.ttest_1samp(a = data, # 指定待检验的数据 popmean = 550, # 指定总体均值 # 指定缺失值的处理办法(如果数据中存在缺失值,则检验结果返回nan) nan_policy = 'propagate' ) out: Ttest_1sampResult(statistic=0.7058009503746899, pvalue=0.49112911593287567) 如上结果所示,ttest_1samp函数返回两部分的结果,一部分是t统计量,另一部分是概率p值。其中,t统计量与上文手工计算的结果一致,从概率p值来看,其值大于0.05,故不能拒绝原假设。 二、独立样本t检验 独立样本t检验,是针对两组不相关样本(各样本量可以相等也可以不相等),检验它们在某数值型指标上,均值之间的差异。对于该检验方法而言,同样需要满足两个前提假设,即样本服从正态分布,且样本之间不存在相关性。与单样本t检验相比,还存在一个非常重要的差异,就是构造t统计量时需要考虑两组样本的方差是否满足齐性(即方差相等)。下面利用统计学中的四步法完成独立样本的t检验: 步骤一:提出原假设和备择假设
步骤二:构造t统计量 当两组样本的方差相等时
其中,n1为样本组1的样本量,n2为样本组2的样本量,由两组样本的方差构成,它的计算公式为:
在原假设满足的情况下,t统计量服从自由度为n1+n2-2的t分布。 当两组样本的方差不相等时
其中,df为方差不相等时,t统计量的自由度,其计算公式如下:
步骤三:计算t统计量 根据步骤二中的计算公式,便可以轻松地得到t统计量的值,这里不妨以前文介绍的服务员小费数据为例,判断男女顾客在支付小费金额上是否存在显著差异。需要注意的是,在计算t统计量之前,应该检验两样本之间的方差是否相等。 读者在使用Python时,可以借助于scipy子模块stats中的levene函数实现方差齐性的检验,借助于ttest_ind函数实现独立样本t检验。接下来结合这两个函数,完成小费金额的t检验,代码及输出结果如下: # 男性客户支付的小费 male_tips = tips.loc[tips.sex == 'Male', 'tip'] # 男性客户支付的小费 female_tips = tips.loc[tips.sex == 'Female', 'tip'] # 检验两样本之间的方差是否相等 stats.levene(male_tips, female_tips) out: LeveneResult(statistic=1.9909710178779405, pvalue=0.1595236359896614) 步骤四:对比结果下结论 如上结果所示,经过方差齐性检验后,发现统计量所对应的概率p值大于0.05,说明两组样本之间的方差满足齐性。所以,在计算t统计量的值时,应该选择方差相等所对应的公式。 三、配对样本t检验 配对样本t检验,是针对同一组样本在不同场景下,某数值型指标均值之间的差异。实际上读者也可以将该检验理解为单样本t检验,检验的是两配对样本差值的均值是否等于0,如果等于0,则认为配对样本之间的均值没有差异,否则存在差异。所以,该检验也遵循两个前提假设,即正态性分布假设和样本独立性假设。下面利用统计学中的四步法完成配对样本的t检验: 步骤一:提出原假设和备择假设
步骤二:构造t统计量
其中,xbar为配对样本差的均值,s为配对样本差的标准差。在原假设满足的情况下,t统计量服从自由度为n-1的t分布。 步骤三:计算t统计量 根据步骤二中的计算公式,可以计算得到配对样本t检验的统计量值,这里不妨以我国各省2016年和2017年的人均可支配收入数据为例(数据来源于中国统计局),判断2016年和2017年该指标是否存在显著差异。读者既可以选择实现单样本t检验的ttest_1samp函数,也可以直接选择实现配对样本t检验的ttest_rel函数。接下来结合这两个函数,完成可支配收入的t检验,代码如下: # 读取人均可支配收入数据 ppgnp = pd.read_excel(r'C:UsersAdministratorDesktopPPGNP.xlsx') # 计算两年人均可支配收入之间的差值 diff = ppgnp.PPGNP_2017-ppgnp.PPGNP_2016 # 使用ttest_1samp函数计算配对样本的t统计量 stats.ttest_1samp(a = diff, popmean = 0) out: Ttest_1sampResult(statistic=13.983206457471795, pvalue=1.1154473504425075e-14) # 使用ttest_rel函数计算配对样本的t统计量 stats.ttest_rel(a = ppgnp.PPGNP_2017, b = ppgnp.PPGNP_2016) out: Ttest_relResult(statistic=13.983206457471795, pvalue=1.1154473504425075e-14) 步骤四:对比结果下结论 在步骤三中,不论采用单样本的t检验方法,还是采用配对样本的t检验方法,得到的t统计量都是相同的。从结果来看,由于概率p值远远小于0.05,故不能接受原假设,即认为2016年和2017年我国人均可支配收入是存在显著差异的。 结语 本期的内容就介绍到这里,如果你有任何问题,欢迎在公众号的留言区域表达你的疑问。同时,也欢迎各位朋友继续转发与分享文中的内容,让更多的人学习和进步。返回搜狐,查看更多 |


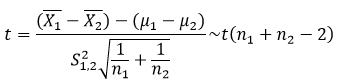
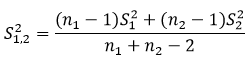
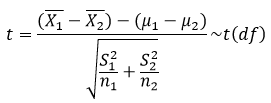
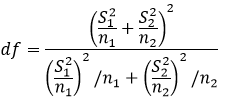

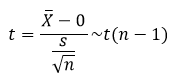
【本文地址】
今日新闻 |
推荐新闻 |