科学网 |
您所在的位置:网站首页 › 华硕vg27a设置 › 科学网 |
科学网
|
[转载]微生物常见统计检验方法比较及选择
已有 115 次阅读 2023-4-19 10:41 |系统分类:科研笔记|文章来源:转载
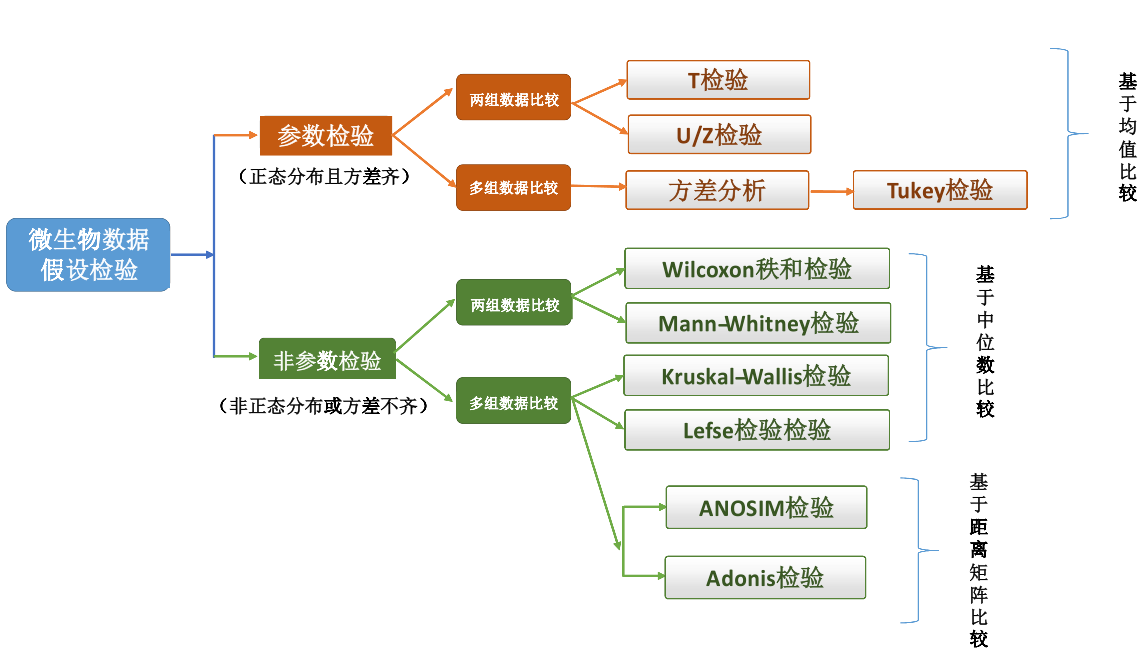
微生物组经由二代测序分析得到庞大数据结果,其中包括OTU/ASV表,物种丰度表,alpha多样性、beta多样性指数,代谢功能预测丰度表等,这些数据构成了微生物组的变量,大量数据构成了高纬度数据信息。 针对不同的微生物数据,和研究目的的不同,数据分析时需要用到不同的统计分析方法,例如降维、聚类、机器学习等。 本文将介绍和比较微生物测序数据统计方法和分析工具,以及微生物组数据分析结果展示原则。旨在帮助谷禾合作方或客户更好地理解和解读微生物组数据分析结果。 ✦ 假设检验假设检验是根据一定的假设条件,由样本推断总体的一种方法。 假设检验的基本思想是小概率反证法思想,小概率思想认为小概率事件在一次试验中基本上不可能发生,在这个方法下,我们首先对总体作出一个假设,这个假设大概率会成立,如果在一次试验中,试验结果和原假设相背离,也就是小概率事件竟然发生了,那我们就有理由怀疑原假设的真实性,从而拒绝这一假设。 根据微生物组研究目的的不同,可以将数据检验方法分为: 1)组间差异检验 2)微生物组与临床或实验数据之间的相关性检验 ✦ 组间差异分析组间差异分析或者叫组间差异显著性检验,差异显著性检验是微生物数据分析时用到的最多的统计学方法。 通常我们需要比较两组或多组数据之间是否有显著差异性,同时还要根据显著性检验识别出不同分组之间的差异变量。这需要用到统计学上的假设检验方法,检验分组之间是否有差异性,并且计算其差异程度。 注:所有的差异检验都基于一个假设:组间没有差异,及变量之间没有关系(即原假设,H0)。 假设检验方法在统计学上,假设检验方法可分为两大类,参数检验和非参数检验。
➦ 参数检验参数检验(Parameter test)是基于样本的观测数据对总体参数(比如总体均值、方差)及总体参数差异性的检验。 •参数检验需要具备一定的条件 参数检验要求总体具备一定条件才能适用,例如总体需呈正态分布、涉及两个总体时两总体必须满足方差同质性(即方差相等)。t检验、F检验(方差分析),都属于参数检验方法。 ➦ 非参数检验在实际分析过程中,数据会经常遇到不满足参数检验前提条件的情况,比如总体不服从正态分布,或者总体分布未知,这时就不能使用参数检验方法,不然得到的检验结果会不准确。在参数检验方法不适用的情况,就需要采用非参数检验方法进行统计检验。 •总体分布情况未知可使用非参数检验 非参数检验(Non-parametric test)是在总体分布未知或者知之甚少的情况下,通过样本数据对总体分布形态等特征进行推断的统计检验方法。 由于此种检验方法在由样本数据推断总体的过程中不涉及总体分布的参数,不要求总体分布满足某些条件,使用条件较为宽松,因此被称为非参数检验。 参数检验与非参数检验的一些区别
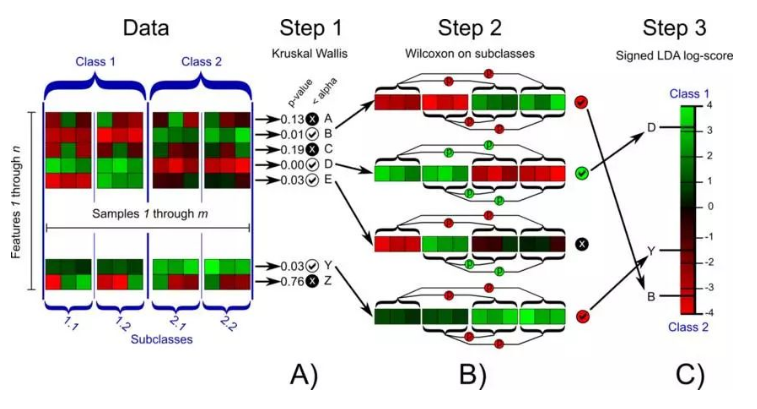
★ 微生物组数据的特点微生物组数据具有以下特点: 1.多样性高:微生物组数据通常包含大量的微生物种类,且种类之间的相对丰度差异较大。 2.维度高:微生物组数据通常包含大量的特征,例如16S rRNA基因序列或基因组序列,每个特征都可以看作是一个维度。 3.数据稀疏:微生物组数据通常是稀疏的,即大部分微生物种类的相对丰度很低,只有少数微生物种类的相对丰度较高。 4.非正态分布:微生物组数据通常不满足正态分布假设,且方差通常与均值相关。 5.数据复杂性高:微生物组数据中存在许多复杂的相互作用和关系,例如共生、拮抗和协同作用等。 考虑到微生物数据的以上特点,我们更推荐采用非参数假设检验的算法,在报告中我们大部分也采用的是非参数检验方法对组间差异进行检验。 差异显著性检验的方法有很多种,需要根据不同的情况,选择适合自身实验情况的方法进行分析。接下来对几种常见的统计检验方法进行介绍。 参数检验1 T 检验 Student t检验(Student’s t test),亦称T检验,是用t分布理论来推论差异发生的概率,从而比较小样本量两组间的差异是否显著,主要用于样本含量较小(例如n0.75:大差异;R>0.5:中等差异,R>0.25:小差异。R等于0或在0附近,说明组间没有差异。R偶尔也会F):通过置换检验获得的P值,P值越小,表明组间差异显著性越强。 Lefse分析――筛选组间差异标记物LEfSe(LDA EffectSize)是用于发现生物标识和揭示基因组特征的软件。以上分析我们找出了分组的差异显著性。 而Lefse的作用就是找出各分组的微生物标记物,即biomarker的筛选,以及这些特征对组间差异的影响程度,用于发现不同分组样本中最能解释组间差异的特征。 √ 分析步骤 A)软件首先使用Kruskal-Wallis (KW) (非参数因子克鲁斯卡尔―沃利斯秩和验检)检测多分组间具有显著丰度差异特征。 B)找出与丰度有显著性差异的物种后进一步使用Wilcoxon 秩和检验进行组间差异分析。 C)最后Lefse采用线性判别分析(LDA)估计每个分组的差异特征对差异效果的影响大小(即LDA score值)。
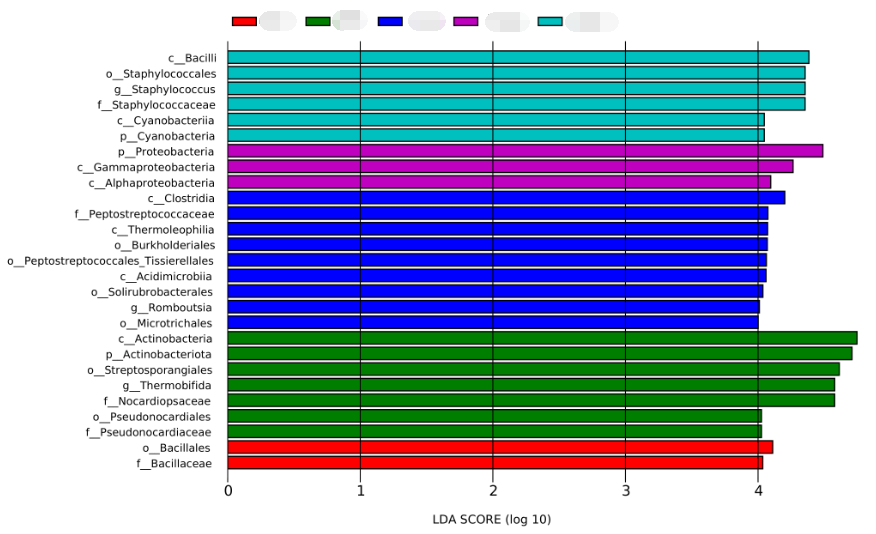
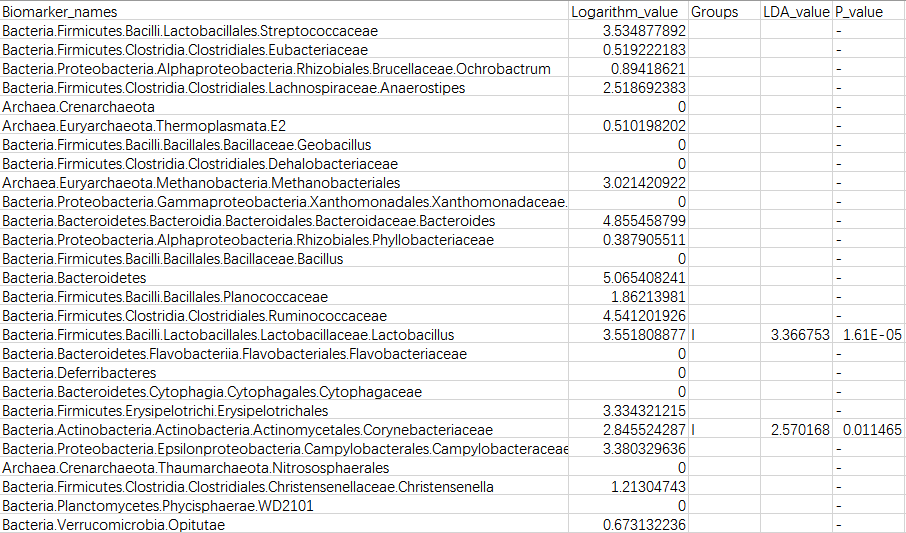
LEfSe结果包含两张图一张表,即(LDA值分布柱状图、 进化分支图及特征表)。 ✦ LDA值分布柱状图 LDA值分布柱状图中展示了LDA Score大于设定值(默认设置为2)的差异物种,即组间具有统计学差异的Biomarker。 展示了不同组中丰度差异显著的物种,柱状图的颜色代表各自的组别,柱状图的长度代表差异物种的影响大小(即为 LDA Score),即不同组间显著差异物种的影响程度。
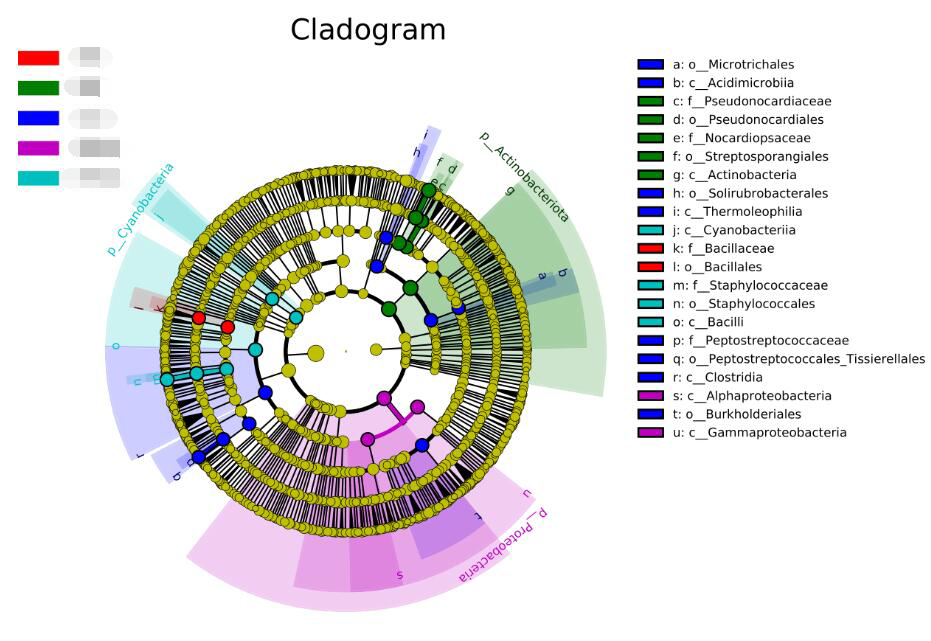
✦ 进化分支图 进化分支图中,由内至外辐射的圆圈代表了由门至属的分类级别。在不同分类级别上的每一个小圆圈代表该水平下的一个分类,小圆圈直径大小与相对丰度大小呈正比。 着色原则:无显著差异的物种统一着色为黄色,差异物种Biomarker跟随组进行着色,红色节点表示在红色组别中起到重要作用的微生物类群,绿色节点表示在绿色组别中起到重要作用的微生物类群。 注:图中英文字母表示的物种名称在右侧图例中进行展示。(为了美观,右侧默认只显示门到科的差异物种)。
✦ 特征表解读: 第一列:Biomarker名称; 第二列:各组分丰度平均值中最大值的log10,如果平均丰度小于10的按照10来计算; 第三列:差异基因或物种富集的组名; 第四列:LDA值; 第五列:P值,若不是Biomarker用“-”表示。
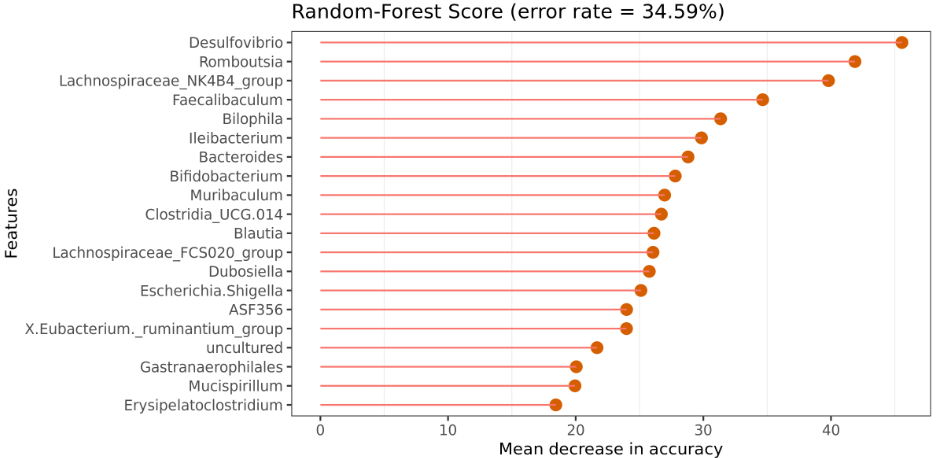
基于微生物组数据的高维度、稀疏性,传统的统计方法不一定能很好的适用于微生物数据统计分析,机器学习面对复杂的数据结构逐渐成为更优的选择。 机器学习(machine learning,ML)就是计算机能够自主“学习” (拟合训练数据),通过神经网络、决策树等算法,从数据中自动分析寻找规律,从而生成经验模型,用于新数据的预测或分类。 ➤ 随机森林随机森林(Random Forest)是一种基于决策树(Decisiontree)的机器学习算法。属于非线性分类器。 通过对对象和变量进行抽样构建预测模型,即生成多个决策树,并依次对对象进行分类。最后将各决策树的分类结果汇总,得出随机森林最终预测的分类结果。 •随机森林可以对样本进行分类和预测 随机森林可以对样本进行分类和预测。16S测序数据通过RandomForest随机森林可以找出与分组有关的关键物种/功能。
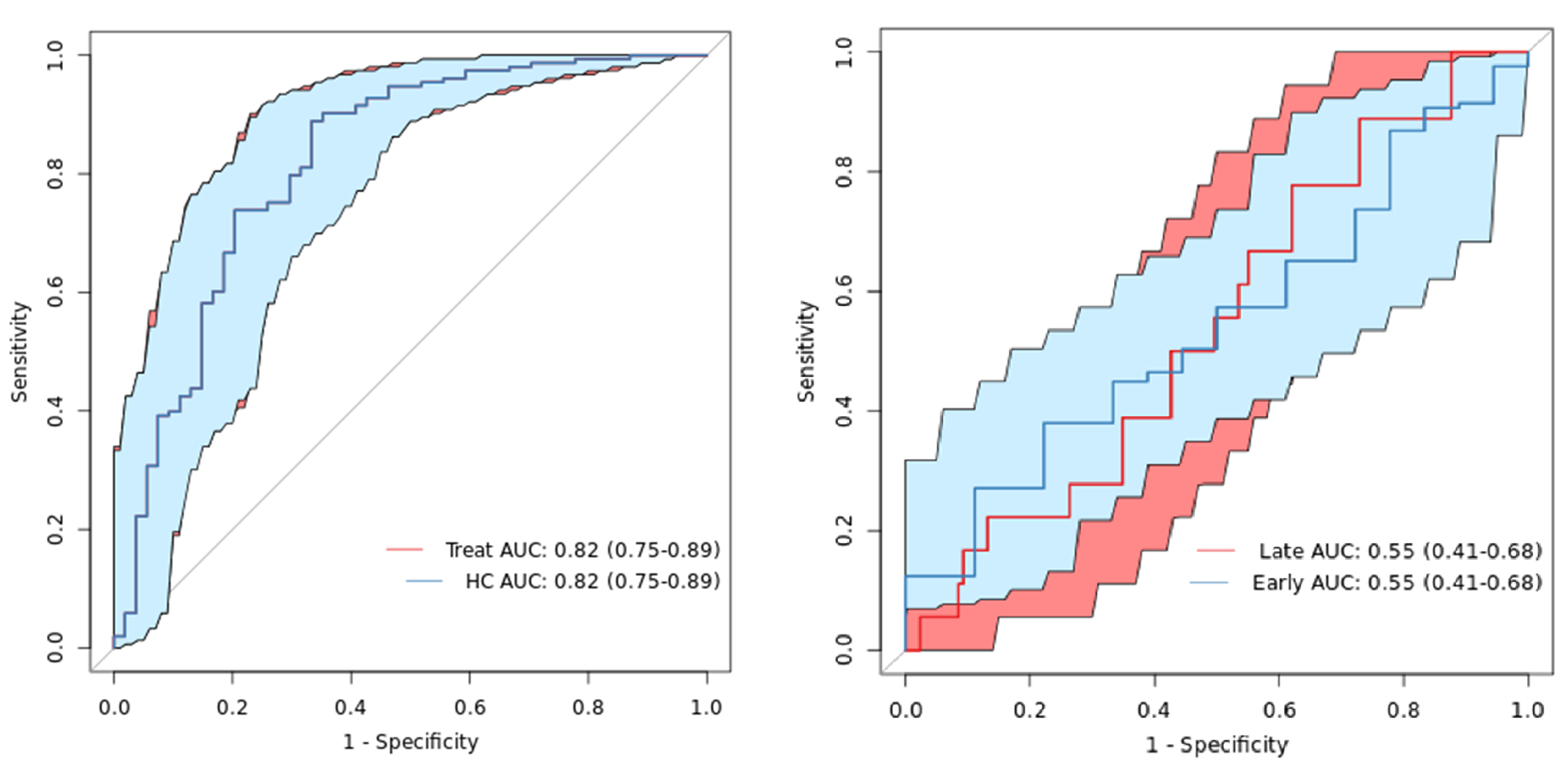
微生物数据通过RandomForest随机森林可以找出与分组有关的关键物种/功能。 图中展示了分类器中对分类效果起主要作用的特征,按重要性从大到小排列。Error rate :表示使用下方的特征进行随机森林方法预测分类的错误率,数值越高表示基于特征分类准确度不高,可能分组之间特征不明显。分值越低证明分组效果比较好。 ➤ ROC曲线根据随机森林方法筛选出的最佳模型,绘制ROC曲线,ROC是一种常用的统计学分析方法,在医学研究中主要用于评价诊断试验的效能,用来评判分类、检测结果的好坏。
根据曲线位置,把整个图划分成了两部分,曲线下方部分的面积被称为AUC,用来表示预测准确性。 AUC值越高,也就是曲线下方面积越大,说明预测准确率越高。曲线越接近左上角(X越小,Y越大),预测准确率越高。 ROC曲线下的面积值在1.0和0.5之间。在 AUC>0.5 的情况下,AUC越接近于1,说明诊断效果越好。 •AUC值不同时的准确性: AUC在0.5~0.7时有较低准确性,AUC在0.7~0.9时有一定准确性,AUC 在0.9以上时有较高准确性。AUC=0.5 时,说明诊断方法完全不起作用,无诊断价值。AUC 收藏 IP: 111.0.128.*| 热度| |


【本文地址】
今日新闻 |
推荐新闻 |