基于人脸识别的口罩识别算法 |
您所在的位置:网站首页 › 华为人脸识别不了口罩 › 基于人脸识别的口罩识别算法 |
基于人脸识别的口罩识别算法
|
文章目录
前言1、 作品创意与功能2、 设计思路与理念2.1 口罩的识别2.2 图片检测2.3 视频流数据的检测
3、 实现路径3.1 数据集及评估指标3.2 口罩识别部分3.3 图片检测部分3.4 视频检测部分
4、 应用价值总结
前言
在许多的场景下人们都需要进行口罩的佩戴的,如果进行人工的检查将会浪费大量的人力,口罩识别某些方面能更好的代替人力进行检测 地址: https://github.com/beordbeordie/face-mask-detector 觉得有用的话还望帮忙点个 star 1、 作品创意与功能 虽然国内的疫情形势比较稳定,但是不排除境外输入的可能,因此在公共场合应该佩戴口罩,但是存在某些人群抱着侥幸心理进入公共场合不佩戴口罩,如果在每个场所出入口都设置人员进行排查将会浪费大量的人力、物力,因此萌发了设计一个能够自动检测行人是否戴口罩算法的想法,并付诸行动。算法最终的成品效果是通过抓取视频接口的视频流数据作为输入送给算法进行处理、或者直接将图片输入给算法,输出标记完成的视频或图片,其中包括人脸的检测及口罩的识别标记。 2、 设计思路与理念算法主要分为三个组成部分。 2.1 口罩的识别 戴口罩和不带口罩是一个很明确的二分类问题,通过对戴口罩人脸和不戴口罩人脸两个数据集进行图片特征提取,再利用一个分类器进行分类,由于现实中的许多遮盖因素的干扰,将分类的概率进行调整(70%以上才有可能被认定为带了口罩),通过模型评估和优化之后将模型保存供下两个模块的使用。 """ 作者:30500 日期:2021年02月26日 简介: """ # 构造参数解析器并解析参数 ap = argparse.ArgumentParser() ap.add_argument("-d", "--dataset", default = "dataset", help="path to input dataset") ap.add_argument("-p", "--plot", type=str, default="plot.png", help="path to output loss/accuracy plot") ap.add_argument("-m", "--model", type=str, default="mask_detector.model", help="path to output face mask detector model") args = vars(ap.parse_args()) # 设置初始化初始学习速率,要训练的迭代数和批次读入图片的大小 INIT_LR = 1e-4 EPOCHS = 20 BS = 32 # 获取数据集目录中的图像列表,然后初始化数据列表(即图像)和图像标签 print("[INFO] loading images...") imagePaths = list(paths.list_images(args["dataset"])) data = [] labels = [] # 在图像路径上循环 将训练数据和标签数据读入 for imagePath in imagePaths: # 利用路径分隔符 从文件名中提取类标签 label = imagePath.split(os.path.sep)[-2] # 测试代码 # label1 = imagePath.split(os.path.sep)[1] # print(label, label1) # 加载输入图像并对其进行预处理 读入大小为(224*224)为了适用MobileNetV2模型的输入 image = load_img(imagePath, target_size=(224, 224)) image = img_to_array(image) image = preprocess_input(image) # 分别更新数据和标签列表 将图片数据和对应标签数据添加到列表中 data.append(image) labels.append(label) # 将数据和标签转换为NumPy数组格式 便于数据的处理 data = np.array(data, dtype="float32") labels = np.array(labels) # 将with_mask without_mask标签转换成二值模式并转换成 one hot 格式 lb = LabelBinarizer() labels = lb.fit_transform(labels) labels = to_categorical(labels) # 进行数据的划分 # 将数据划分为使用80%用于训练 # 剩余的20%用于测试 (trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.20, stratify=labels, random_state=42) # 构建用于数据增强的训练图像生成器 aug = ImageDataGenerator( rotation_range=20, # 旋转范围 zoom_range=0.15, # 缩放范围 width_shift_range=0.2, # 水平平移范围 height_shift_range=0.2, # 垂直平移范围 shear_range=0.15, # 透视变换范围 horizontal_flip=True, # 水平翻转 fill_mode="nearest") # 填充模式 # 加载 MobileNetV2 网络,将数据的输出层关闭,只用于提取数据的特征用于构建自己的处理模型 baseModel = MobileNetV2(weights="imagenet", include_top=False, input_tensor=Input(shape=(224, 224, 3))) # 构造顶部的模型放置在模型头部 # 基本模型 平均池化层 全连接层 隐藏层 Dropout层 输出层 headModel = baseModel.output headModel = AveragePooling2D(pool_size=(7, 7))(headModel) headModel = Flatten(name="flatten")(headModel) headModel = Dense(128, activation="relu")(headModel) headModel = Dropout(0.5)(headModel) headModel = Dense(2, activation="sigmoid")(headModel) # 模型整合 model = Model(inputs=baseModel.input, outputs=headModel) # 冻结MobileNetV2网络中加载的模型层 不再进行相应的权重更新 for layer in baseModel.layers: layer.trainable = False # 模型配置 损失函数二分类 优化参数加入学习率衰减 print("[INFO] compiling model...") opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS) model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"]) # 训练网络 print("[INFO] training head...") H = model.fit( aug.flow(trainX, trainY, batch_size=BS), # 数据打乱增强 steps_per_epoch=len(trainX) // BS, validation_data=(testX, testY), # 模型的数据验证 validation_steps=len(testX) // BS, epochs=2) 2.2 图片检测 通过对单张图片中的佩戴口罩的情况进行测试,并在输出的图片中进行识别标注和识别率的打印,来对算法进行先期评估优化。 # 加载口罩检测器模型 print("[INFO] loading face mask detector model...") model = load_model(args["model"]) # 从磁盘加载输入图像,复制并抓取图像的尺寸大小 image = cv2.imread(args["image"]) orig = image.copy() (h, w) = image.shape[:2] # 从图像中构造一个BLOB 进行图像的预处理 缩放输入 减均值 blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300), (104.0, 177.0, 123.0)) # 通过网络传递BLOB到模型 前向获得人脸检测结果 print("[INFO] computing face detections...") net.setInput(blob) detections = net.forward() # 在探测上循环 for i in range(0, detections.shape[2]): # 提取与检测相关的置信度(即概率) confidence = detections[0, 0, i, 2] # 通过确保置信度大于最小置信度来过滤弱检测 > 0.5 if confidence > args["confidence"]: # 计算对象的包围框的(x,y)坐标 box = detections[0, 0, i, 3:7] * np.array([w, h, w, h]) (startX, startY, endX, endY) = box.astype("int") # 确保边界框在框架的尺寸范围内 (startX, startY) = (max(0, startX), max(0, startY)) (endX, endY) = (min(w - 1, endX), min(h - 1, endY)) # 提取人脸ROI,将其从BGR转换为RGB通道排序,将其调整为224x224,并对其进行预处理 输入给口罩模型进行判断是否佩戴口罩 face = image[startY:endY, startX:endX] face = cv2.cvtColor(face, cv2.COLOR_BGR2RGB) face = cv2.resize(face, (224, 224)) face = img_to_array(face) face = preprocess_input(face) face = np.expand_dims(face, axis=0) # 通过模型来判断人脸是否有口罩 (mask, withoutMask) = model.predict(face)[0] # 确定类标签和颜色,将使用它来绘制边框和文本 label = "Mask" if mask > 0.75 else "No Mask" color = (0, 255, 0) if label == "Mask" else (0, 0, 255) # 包括标签中的概率 label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100) # 在输出框上显示标签和边框矩形 cv2.putText(image, label, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(image, (startX, startY), (endX, endY), color, 2) # 显示输出图像 cv2.imwrite ("result/people_mask_result.jpg", image) cv2.imshow("Output", image) cv2.waitKey(0) 2.3 视频流数据的检测 通过调取摄像头进行取帧处理,每秒帧数为20,将处理后的图片再进行整合输出,达到视频检测的目的,通过对视频的实时调取和处理输出来达到实时检测的一个效果。实现中应该采用不仅限于一个模型的迁移,通过对不同模型的迁移来训练观察最终在测试集上的准确率来判别选用哪个模型。 masknet = load_model('mask_detector.model') def Iou(bbox1, bbox2): # 计算Iou # bbox1,bbox为xyxy数据 area1 = (bbox1[2] - bbox1[0]) * (bbox1[3] - bbox1[1]) area2 = (bbox2[2] - bbox2[0]) * (bbox2[3] - bbox2[1]) w = min(bbox1[3], bbox2[3]) - max(bbox1[1], bbox2[1]) h = min(bbox1[2], bbox2[2]) - max(bbox1[0], bbox2[0]) if w 1600: for k in range(len(bbox_buffer)): if Iou(bbox, bbox_buffer[k]) > 0.1 and k not in index: index.append(k) break bbox_upgrade.append((left, top, right, bottom)) else: preds.append([left, top, right, bottom]) faces.append(img[top:bottom, left:right]) bbox_buffer = bbox_upgrade.copy() if len(faces) > 0: count = 0 for face in faces: face = cv2.cvtColor(face, cv2.COLOR_BGR2RGB) face = cv2.resize(face, (224, 224)) face = img_to_array(face) face = preprocess_input(face) face = np.expand_dims(face, axis=0) (mask, withoutMask) = maskNet.predict(face)[0] lable = "Mask" if mask > withoutMask else "No Mask" color = (0, 255, 0) if lable == "Mask" else (0, 0, 255) lable = "{}:{:.2f}%".format(lable, max(mask, withoutMask) * 100) cv2.putText(img, lable, (preds[count][0], preds[count][1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(img, (preds[count][0], preds[count][1]), (preds[count][2], preds[count][3]), color, 2) count += 1 cv2.imwrite(out_path + '/%d.jpg' % i, img) print('正在进行{}张图的处理'.format(i)) GetFace('img', 'demo', masknet) 3、 实现路径算法流程图 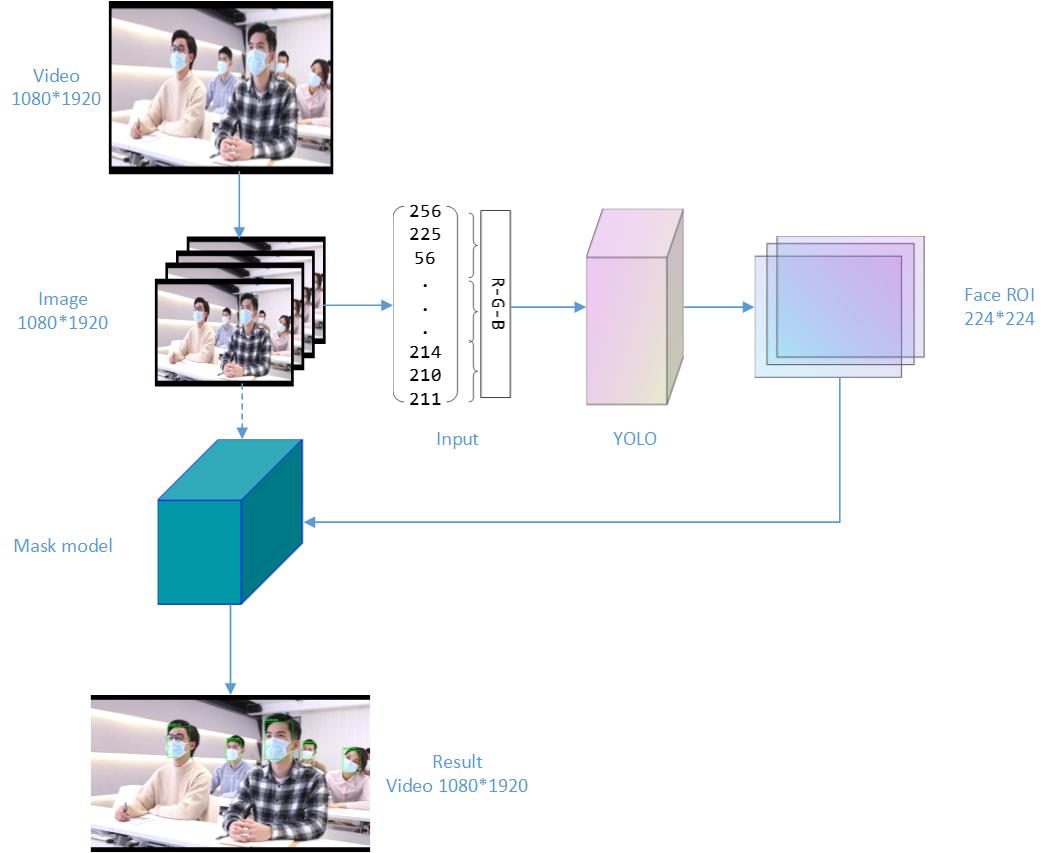 3.1 数据集及评估指标
戴口罩和不戴口罩的图片总量为5000张,通过图片增强的预处理方式再次增大样本数量,测试和训练的比例为2:8,更好的让模型进行权重的更新学习,为了防止分类器出现过拟合的现象,再次用1000张没有训练过的图片进行模型测试。模型评估方式,模型优化的评估指标采取accuracy和precision的双重判断。
3.1 数据集及评估指标
戴口罩和不戴口罩的图片总量为5000张,通过图片增强的预处理方式再次增大样本数量,测试和训练的比例为2:8,更好的让模型进行权重的更新学习,为了防止分类器出现过拟合的现象,再次用1000张没有训练过的图片进行模型测试。模型评估方式,模型优化的评估指标采取accuracy和precision的双重判断。
训练数据 

模型评估  3.2 口罩识别部分
首先利用一个五层的全连接来提取图像特征,不仅训练速度慢,提取特征的效果不好,最终的测试效果也只有0.62。之后迁移VGG16及MobileNetV2来进行特征提取,两者在20个迭代内就达到了很好的训练结果,而且在测试集上的测试效果也达到了0.95的准确率,但是介于VGG模型结构大,在实际部署中可能会存在对硬件的一个要求较大,而后者小而快速,可以部署到移动端的特点,最终选用后者作为特征提取的模型。
3.3 图片检测部分
采用预先训练过的人脸识别的caffe模型来对图片中的人脸区域提取,置信率为0.5,将检测出的人脸送入第一阶段训练完毕的识别模型,通过模型预测之后在输出图片上添加人脸框和具体的识别的结果和概率标注,分析存在的问题,先期优化模型。
3.2 口罩识别部分
首先利用一个五层的全连接来提取图像特征,不仅训练速度慢,提取特征的效果不好,最终的测试效果也只有0.62。之后迁移VGG16及MobileNetV2来进行特征提取,两者在20个迭代内就达到了很好的训练结果,而且在测试集上的测试效果也达到了0.95的准确率,但是介于VGG模型结构大,在实际部署中可能会存在对硬件的一个要求较大,而后者小而快速,可以部署到移动端的特点,最终选用后者作为特征提取的模型。
3.3 图片检测部分
采用预先训练过的人脸识别的caffe模型来对图片中的人脸区域提取,置信率为0.5,将检测出的人脸送入第一阶段训练完毕的识别模型,通过模型预测之后在输出图片上添加人脸框和具体的识别的结果和概率标注,分析存在的问题,先期优化模型。
检测部分  3.4 视频检测部分
利用OpenCV的API函数调取摄像头进行检测,将图片分帧处理完毕之后进行合并输出,但限于电脑算力问题,实时检测时遇到卡帧的现象,因此将摄像头的数据替换为一段视频进行检测,最终的检测效果也不错,但是对于信息复杂的视频,caffe不能很好的进行检测,因此将视频模块的模型替换为YOLO3,达到很好的检测效果。
3.4 视频检测部分
利用OpenCV的API函数调取摄像头进行检测,将图片分帧处理完毕之后进行合并输出,但限于电脑算力问题,实时检测时遇到卡帧的现象,因此将摄像头的数据替换为一段视频进行检测,最终的检测效果也不错,但是对于信息复杂的视频,caffe不能很好的进行检测,因此将视频模块的模型替换为YOLO3,达到很好的检测效果。
视频处理  4、 应用价值
基础应用在公共卫生防治方面。为了避免空气接触带来的交叉感染,口罩的佩戴是必不可少的,但是医院每日的人流量较大,安保等检查人员往往应接不暇,可以用口罩识别来代替人工的识别,通过医院的门禁进行人员的口罩佩戴情况的检测,能够减少人力的投入。拓展可应用在各种安全方向的异常检测,例如工厂里面的防火安全检测、矿井内部的异常检测等,可及时发现异常事件并进行警告,能有效的避免一些事故的发生。也可再次训练用于刑侦方面的检测,配合摄像头的实时获取来对在逃嫌疑人进行检测,可增加发现率,帮助案件的侦破。特别是在疫情期间,国家在卫生防控方面增加了大量的人力物力,而用机器的口罩识别来代替人工的检测,可大大减少人力的输入及提高疫情工作的效率,减少在疫情上的经济支出、减少疫情的传播。
总结
4、 应用价值
基础应用在公共卫生防治方面。为了避免空气接触带来的交叉感染,口罩的佩戴是必不可少的,但是医院每日的人流量较大,安保等检查人员往往应接不暇,可以用口罩识别来代替人工的识别,通过医院的门禁进行人员的口罩佩戴情况的检测,能够减少人力的投入。拓展可应用在各种安全方向的异常检测,例如工厂里面的防火安全检测、矿井内部的异常检测等,可及时发现异常事件并进行警告,能有效的避免一些事故的发生。也可再次训练用于刑侦方面的检测,配合摄像头的实时获取来对在逃嫌疑人进行检测,可增加发现率,帮助案件的侦破。特别是在疫情期间,国家在卫生防控方面增加了大量的人力物力,而用机器的口罩识别来代替人工的检测,可大大减少人力的输入及提高疫情工作的效率,减少在疫情上的经济支出、减少疫情的传播。
总结
算法本质是局部区域上的特征检测,可通过对视频流数据的实时抓取处理来进行输出反馈,达到目标的实时检测效果。在数据处理时采用了多种口罩佩戴的数据集进行训练,可对不同形状、不同颜色的口罩进行检测识别,同时对不同表现的人脸进行了处理,可识别出侧脸等不是很规则的人脸,也可识别范围内的大量人脸。 |
【本文地址】
今日新闻 |
推荐新闻 |