Python之requests+xpath爬取猫眼电影并写入数据库(图文教程) |
您所在的位置:网站首页 › 十大互联网大厂 › Python之requests+xpath爬取猫眼电影并写入数据库(图文教程) |
Python之requests+xpath爬取猫眼电影并写入数据库(图文教程)
|
文章目录
一、pyhton连接mysql数据库二、用xpath抓取有用信息说几个比较容易掉坑的地方一二三效果
一、pyhton连接mysql数据库
我是写了一个py文件来封装一下,然后在爬取猫眼的py文件里直接调用,需要使用到pymysql库, 没有安装这个库的同学要事先安装一下,这里直接上代码 #coding=utf-8 import pymysql class mysqlConn: def get_conn(self, dbname): """提供你要连接的数据库名,并连接数据库""" self.conn = pymysql.connect( host="127.0.0.1", user="root", password="你的密码", db=dbname, #可选择要连接的数据库名 charset="utf8" ) self.cur = self.conn.cursor() def exe_sql(self, sql): """执行不返回结果的sql语句, 例如增删改""" self.cur.execute(sql) self.conn.commit() # print("事物提交成功") def select_sql(self, sql): """执行查询语句""" self.cur.execute(sql) return self.cur.fetchall() def close_conn(self): if self.cur: self.cur.close() if self.conn: self.conn.close() if __name__ == "__main__": #找一个数据库表来执行一下看能不能行 connection = mysqlConn() connection.get_conn("school") #连接'school'数据库 sql = '''insert into student2 (name, nickname) values ("赵六", "六娃")''' connection.exe_sql(sql) connection.close_conn()注意文件开头有个#coding=utf-8,不写会提示一个小报错,以前都没写这个的习惯,看来以后要习惯写了 来看看结果 猫眼电影网站地址: https://maoyan.com/films?showType=3 先来看最后的数据库,看看我们要抓取哪些信息
结果你们可以自己去打印一下,如果没有遇到验证码就能爬到了 最后的抓取猫眼电影的全部代码,封装成类,养成良好的代码习惯 import requests from lxml import etree from mysql_api import mysqlConn from fake_useragent import UserAgent from pymysql import err class maoYan_spider: headers = { "User-Agent": UserAgent().random } def get_urls(self, url): """返回一个电影首页捕获到的所有海报地址和电影详情url""" print("url: " + url) resp = requests.get(url=url, headers=self.headers) tree = etree.HTML(resp.text) # 完整的图片地址,可以直接打开 img_ar = tree.xpath('//dl/dd//img[2]/@data-src') # 只有地址的后半段,需要拼接'https://maoyan.com' urls_ar = tree.xpath('//dd/div[@class="movie-item film-channel"]/a/@href') #只有py具有返回多个参数的特性,其他语言只能返回一个 return img_ar, urls_ar def save_data(self, img_src, url): """将电影详情写入数据库""" #print("url: " + url) resp = requests.get(url=url, headers=self.headers) tree = etree.HTML(resp.content.decode("utf-8")) name = str(tree.xpath('string(//h1)')) print("正在储存电影......".format(name)) if name == "": print("遇到验证码, 程序停止") return False actors_ar = tree.xpath('//div[@class="celebrity-group"][2]//li/div[@class="info"]/a/text()') # 演员列表 types = tree.xpath('string(//li[@class="ellipsis"])').replace("\n", "").replace(" ", "") # 字符串 intro = str(tree.xpath('string(//span[@class="dra"])')) actors = '|'.join(actors_ar).replace("\n", "").replace(" ", "") #将演员列表拼接为字符串 sql = 'insert into maoyan (m_name, m_type, m_src, m_link, m_intro, m_actors) values ("%s","%s","%s","%s","%s","%s")' % (name, types, img_src, url, intro, actors) try: self.connect.exe_sql(sql) except err.ProgrammingError: print("该条编码有问题,舍弃") return True def run(self): self.connect = mysqlConn() self.connect.get_conn("movies") tag = True #爬取前两页的电影 for i in range(2): main_url = "https://maoyan.com/films?showType=3&offset={}".format(30 * i) imgs, urls = self.get_urls(main_url) if len(imgs) == 0: print("遇到验证码, 程序停止") print("再次尝试...") imgs, urls = self.get_urls(main_url) for img, url in zip(imgs, urls): img = img.split('@')[0] url = 'https://maoyan.com' + url tag = self.save_data(img, url) while not tag: tag = True print("再次尝试...") tag = self.save_data(img, url) self.connect.close_conn() if __name__ == "__main__": # conn1 = mysqlConn() # conn1.get_conn("movies") # sql = """create table maoyan( # m_id int primary key auto_increment, # m_name varchar(30) not null, # m_type varchar(20) null, # m_src varchar(100) not null, # m_link varchar(100) not NULL, # m_intro text null, # m_actors text null # )default charset = utf8""" # conn1.exe_sql(sql) # conn1.close_conn() spider = maoYan_spider() spider.run()
其他还有问题可以评论区留言讨论,今天算是学习爬虫几天以来第一个不看视频,自己独立抓完的作业啦,嘻嘻 效果
|

 从图上可以看出我们要抓取电影名字, 电影海报的链接, 电影详情页的链接, 电影的介绍,以及演员表. 现在看猫眼首页
从图上可以看出我们要抓取电影名字, 电影海报的链接, 电影详情页的链接, 电影的介绍,以及演员表. 现在看猫眼首页 
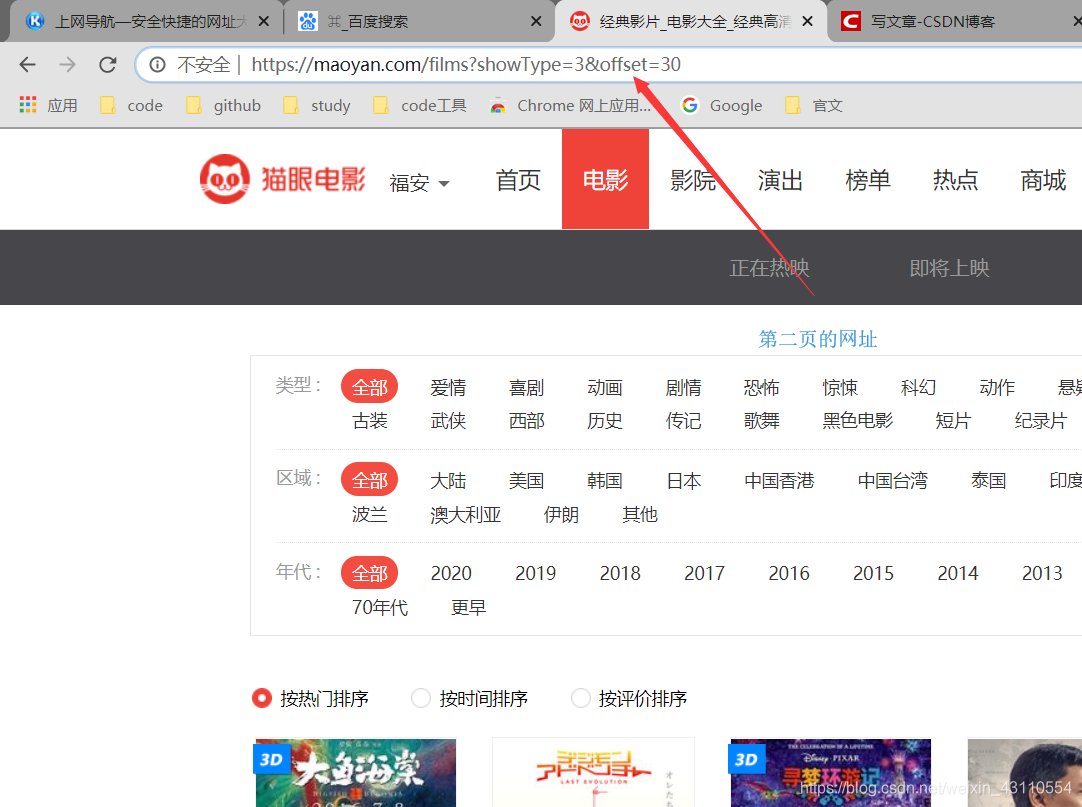 从这里我们已经能发现他网址变换的规律了 再抓取第一页的网址里不同电影的信息 先看海报地址
从这里我们已经能发现他网址变换的规律了 再抓取第一页的网址里不同电影的信息 先看海报地址  这里用了一个抓xpath的插件工具(XPath Helper),没有的同学可以去谷歌应用商店下载,安装之后按快捷键Ctrl+Shift+X就可以快速使用了
这里用了一个抓xpath的插件工具(XPath Helper),没有的同学可以去谷歌应用商店下载,安装之后按快捷键Ctrl+Shift+X就可以快速使用了 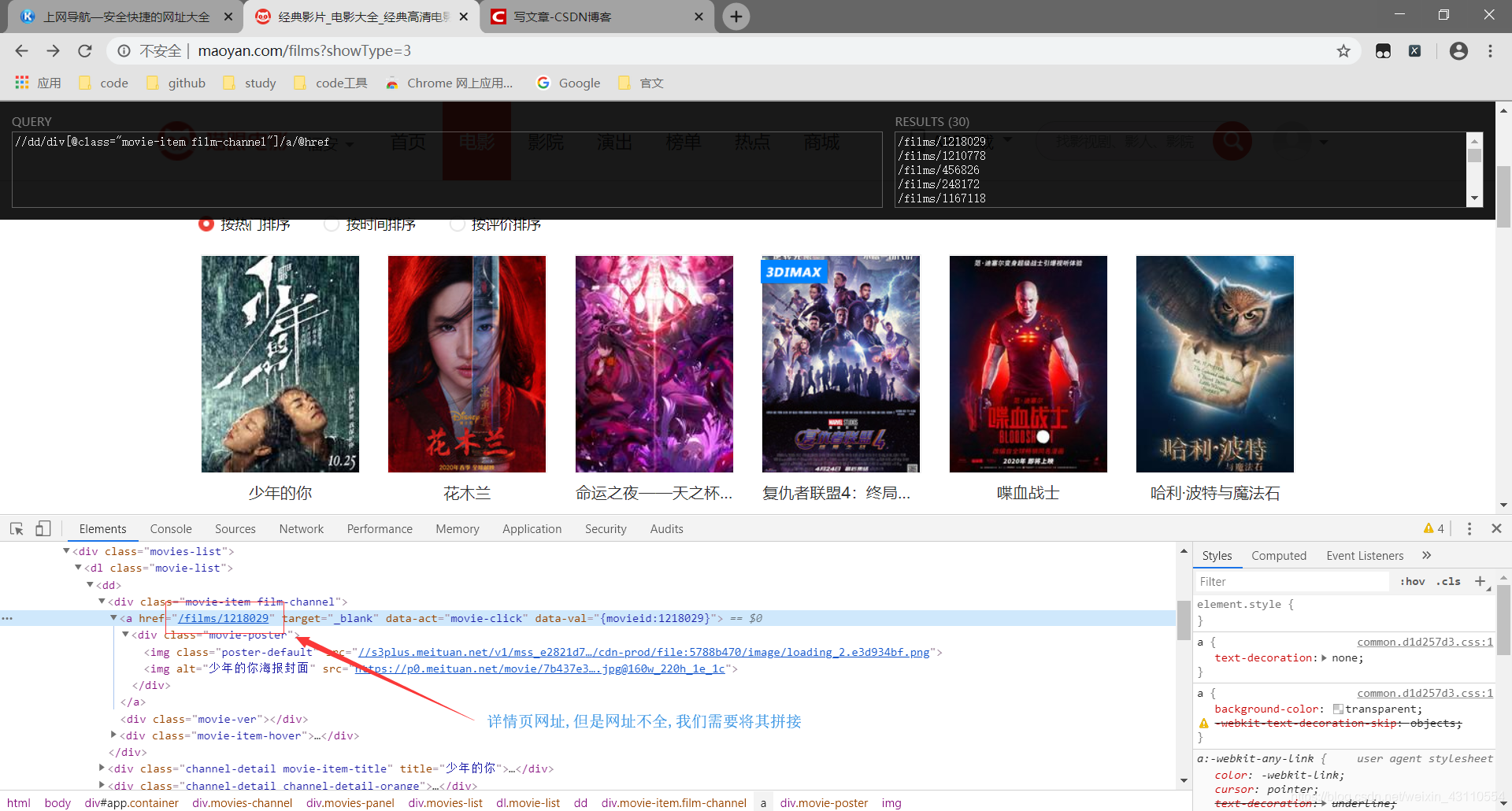 ok,现在电影首页的内容需要的两个内容已经抓取完毕,剩下的内容需要到详情页来抓取,我们先写一段首页抓取的代码来看看效果
ok,现在电影首页的内容需要的两个内容已经抓取完毕,剩下的内容需要到详情页来抓取,我们先写一段首页抓取的代码来看看效果 发现详情页地址抓到了,图片地址没抓到???真是原地裂开,到这里我也懵逼了一阵,以为是自己xpath没写对,那看来现在只能debug了,咱先打个断点
发现详情页地址抓到了,图片地址没抓到???真是原地裂开,到这里我也懵逼了一阵,以为是自己xpath没写对,那看来现在只能debug了,咱先打个断点  那现在我们将抓取图片的xpath改为’//dl/dd//img[2]/@data-src’再来试试,发现已经能成功抓取 现在我们来抓取详情界面信息的演员表 其中电影名字和简介都比较好抓,我就不截图了,一会一直贴xpath,你可以自己抓一抓
那现在我们将抓取图片的xpath改为’//dl/dd//img[2]/@data-src’再来试试,发现已经能成功抓取 现在我们来抓取详情界面信息的演员表 其中电影名字和简介都比较好抓,我就不截图了,一会一直贴xpath,你可以自己抓一抓 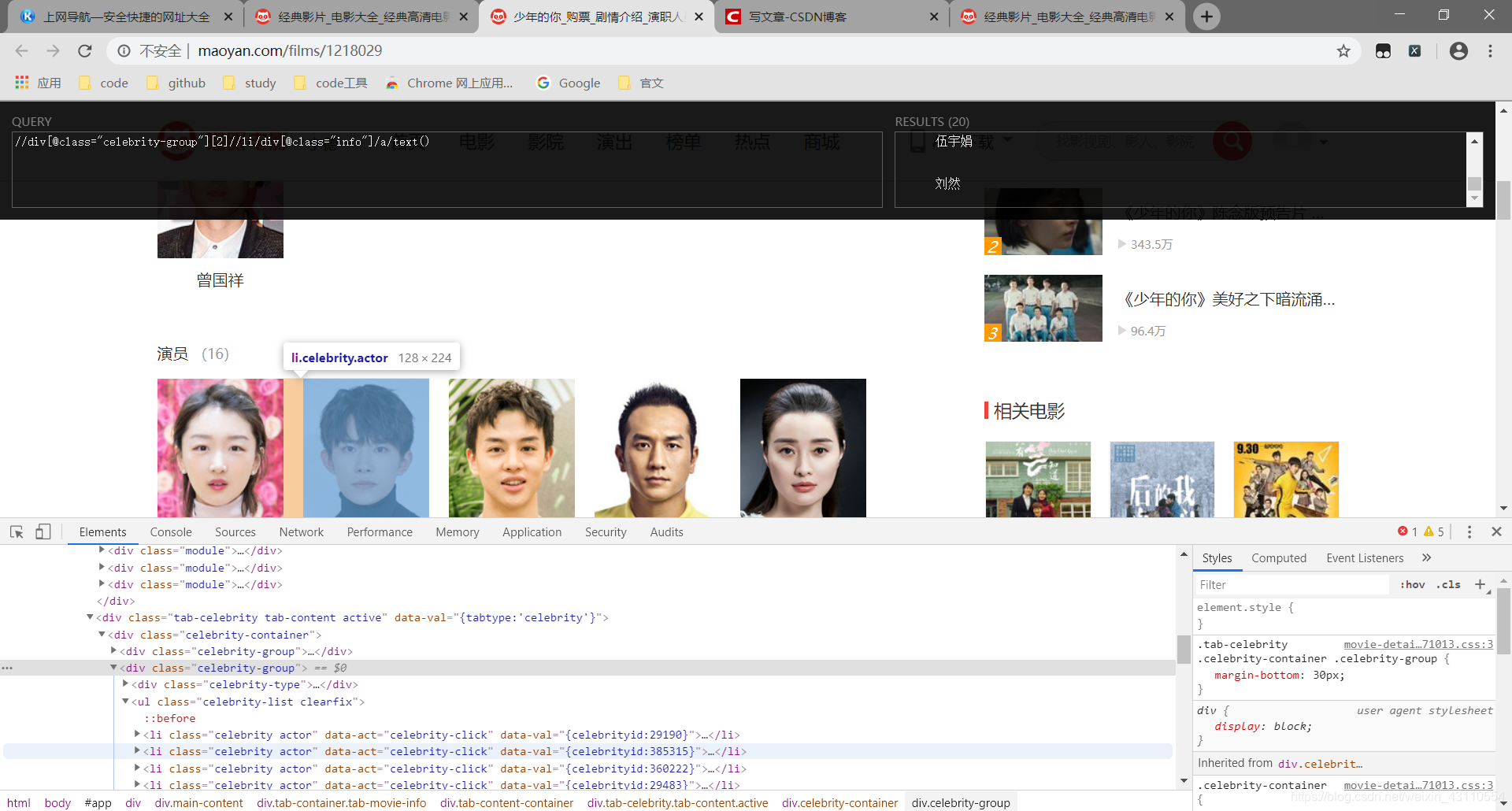 这里你可以尝试下其他写法,就不多重复了 爬取详情页的代码
这里你可以尝试下其他写法,就不多重复了 爬取详情页的代码 这是我连接数据库文件和爬取文件的位置,大概在同一个目录下就行了,你可以写在和同一个抓电影同一个页面下然后’from .mysql_api import mysqlConn’
这是我连接数据库文件和爬取文件的位置,大概在同一个目录下就行了,你可以写在和同一个抓电影同一个页面下然后’from .mysql_api import mysqlConn’ 这一段代码是建表的,前提是你要先自己在mysql里建好movies数据库 然后把这一段解除注释,把前面两行代码先注释了,然后运行,运行之后会有一个字符集编码警告,这个不打紧,运行结束你就可以注释掉这一段代码,然后将下面两行解除注释,开始爬虫,当然你也可以在数据库里先建好表,我是因为之前只用py写过增删改查,就想试试建表,不要问我为什么m_actors给了text类型,原本给了varchar(200),后来提示不够写,改成400还不够,我就去看了看是谁演员这么多—复联
这一段代码是建表的,前提是你要先自己在mysql里建好movies数据库 然后把这一段解除注释,把前面两行代码先注释了,然后运行,运行之后会有一个字符集编码警告,这个不打紧,运行结束你就可以注释掉这一段代码,然后将下面两行解除注释,开始爬虫,当然你也可以在数据库里先建好表,我是因为之前只用py写过增删改查,就想试试建表,不要问我为什么m_actors给了text类型,原本给了varchar(200),后来提示不够写,改成400还不够,我就去看了看是谁演员这么多—复联 这个sql语句,要注意占位符两边有双引号(一定要是双引号,因为在数据库里单引号有特殊意义,我查的文章里这么说的,具体是啥目前还不懂),我原先里面用了单引号,外面包裹sql的用的双引号,导致有好几个页面会引发’pymysql.err.ProgrammingError’, 我一直找不到问题所在,就只能捕获异常了,后来改了单引号就没这毛病了.
这个sql语句,要注意占位符两边有双引号(一定要是双引号,因为在数据库里单引号有特殊意义,我查的文章里这么说的,具体是啥目前还不懂),我原先里面用了单引号,外面包裹sql的用的双引号,导致有好几个页面会引发’pymysql.err.ProgrammingError’, 我一直找不到问题所在,就只能捕获异常了,后来改了单引号就没这毛病了.
【本文地址】
今日新闻 |
推荐新闻 |