基于共现的《红楼梦》贾宝玉与十二金钗关系图谱Python实现,附加代码+详细解释 |
您所在的位置:网站首页 › 十二金钗个人喜好 › 基于共现的《红楼梦》贾宝玉与十二金钗关系图谱Python实现,附加代码+详细解释 |
基于共现的《红楼梦》贾宝玉与十二金钗关系图谱Python实现,附加代码+详细解释
|
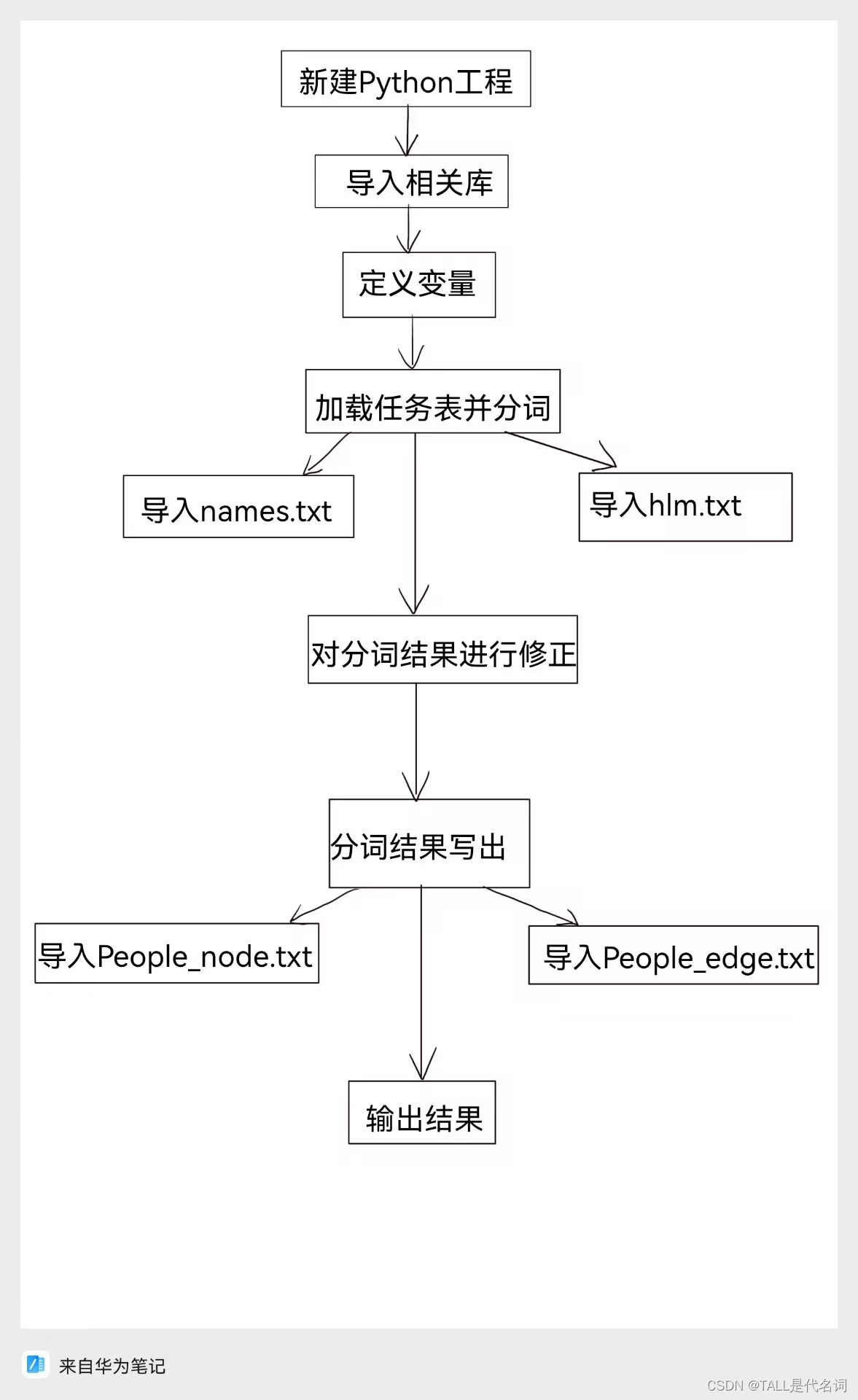
分享一下过程,代码以及详细注释,希望对大家有所帮助!!! 文中涉及到的4个.txt链接: 链接:https://pan.baidu.com/s/1bwMnKncHEiBNo1uJ32JdVw 提取码:uwy9 1.该实验主要技术基础Jieba:是一款中文分词工具,它是用 Python 编写的开源库。jieba 主要用于中文文本的分词,即将一段中文文本切分成一个个有意义的词语。分词是中文自然语言处理中的一个重要预处理步骤,对于文本的理解和处理具有关键性的作用。jieba 支持三种分词模式:精确模式、全模式和搜索引擎模式 2.实验方法与步骤新建python工程,生成基于共现的《红楼梦》贾宝玉与十二金钗关系图谱 3.实验内容 1·准备阶段:·提前安装好jieba库、matplotlib库、networkx库 ·四个.txt文件(name.txt,hlm.txt,People_edge.txt,People_node.txt) 2·步骤: 1)定义变量 names = {} #姓名 relationships = {} #关系 lineNames = [] #人物列表 2)加载任务表并分词 #2·加载任务表并分词 ''' 首先加载了自定义的人物表 "names.txt", 然后打开了 "hlm.txt" 文件,对每一行进行分词, 并将其中的人物名添加到 `lineNames` 中。 对于每个词语,如果词性不是 "nr"(人名)或者词的长度小于2, 则被视为不是人名。 最后统计了每个人物出现的次数,并初始化了人物关系字典 ''' jieba.load_userdict("names.txt") # 加载人物表 with codecs.open("hlm.txt", 'r', 'utf8') as f: for line in f.readlines(): poss = pseg.cut(line) # 分词 返回词性 lineNames.append([]) # 为本段添加一个人物列表 for w in poss: if w.flag != 'nr' or len(w.word) < 2: continue # 当分词长度小于2或该词词性不为nr(人名)时认为改词不为人名 lineNames[-1].append(w.word) # 为当前段的环境增加一个人物 if names.get(w.word) is None: # 如果某人物(w.word)不在人物字典中 names[w.word] = 0 relationships[w.word] = {} names[w.word] += 1 3)对分词结果进行修正 # 3·对分词结果进行修正 ''' 基于已经提取的人物名列表‘lineNames’构建人物关系图谱, 并尝试解决因分词不准确而导致的冗余边问题。 对分词结果进行了修正,遍历了 `lineNames` 中的每一行, 对于每一行里的每个人物对(name1和name2),检查它们之间的关系。 统计了它们之间的关系,并对关系进行了修正。 如果两个人名不相同,且它们之间的关系在‘relationships’字典中不存在, 则将新的关系计数设置为1; 如果关系已经存在,则将关系计数加1。 ''' for line in lineNames: for name1 in line: for name2 in line: if name1 == name2: continue if relationships[name1].get(name2) is None: relationships[name1][name2] = 1 else: relationships[name1][name2] = relationships[name1][name2] + 1 # 由于分词的不准确会出现很多不是人名的“人名” 从而导致出很多冗余边 # 为此可设置阈值为10 即当边出现10次以上则认为不是冗余 4)分词结果写出 # 4·分词结果写出 ''' 分词结果写出,将节点写入文件 "People_node.txt", 包括人物的ID、标签和权重。(ID Label Weight) 然后将边的关系写入文件 "People_edge.txt",包括关系的起点、终点和权重。 ''' with codecs.open("People_node.txt", "w", "utf8") as f:#新建 # 使用‘codecs.open’打开文件"People_node.txt",以写入("w")的方式,并指定编码为"utf8"。 # 打开一个文件,如果文件已存在则覆盖,如果文件不存在则新建 f.write("ID Label Weight\r\n") # 结果写出 # 在文件中写入"ID Label Weight"并换行 for name, times in names.items(): # 遍历名为names的字典中的每个键值对(name, times) if times > 10: # 如果times大于10 f.write(name + " " + name + " " + str(times) + "\r\n") # 在文件中写入name、name、times并换行 with codecs.open("People_edge.txt", "w", "utf8") as f: # 新建 f.write("Source Target Weight\r\n") # 结果写出 #写入标题行"SourceTargetWeight\r\n", # 表示后续数据的含义, # 其中"Source"和"Target"代表关系的起始和结束节点, # "Weight"代表关系的权重。 for name, edges in relationships.items(): # 遍历‘relationships’字典中的每个人物及其关系,使用‘items()’方法获取人物及其关系。 for v, w in edges.items(): # 对于每个人物的关系,遍历其中的每个关联人物及其权重。 if w > 10: # 如果两者之间的关系权重大于10, # 将这些关系及其权重写入文件"People_edge.txt"中,每行表示一对关系, # 格式为"Source,Target,Weight",以空格分隔,末尾添加换行符"\r\n"。 f.write(name + " " + v + " " + str(w) + "\r\n") # 输出结果 f = open('People_ 5)输出结果 # 5.输出结果 f = open('People_edge.txt', 'r', encoding='utf-8') # 打开"People_edge.txt"文件,以只读模式打开 f2 = open('names.txt', 'r', encoding='utf-8').read() # 打开文件"names.txt"和读取其内容 lines = f.readlines() # 读取 # 读取文件内容,将每一行的内容作为一个元素存入列表`lines`。 ''' 定义一个空列表`A`。 遍历文件内容的每一行,去除换行符后, 按空格分割每行的内容,并将结果存入列表`m`, 然后将`m`添加到列表`A`中。 ''' A = [] # 定义空列表 for line in lines: # 遍历 # 遍历文件中的每一行 A.append([]) # 在列表A中添加一个空列表 m = line.strip('\n').split(' ') # 去除换行符后,按空格分割当前行的内容,并将结果存入列表m中 for x in m: # 遍历列表m中的每个元素 A[-1].append(x) # 将列表m中的每个元素添加到列表A的最后一个子列表中遍历列表`A`中的每个元素, # 检查每个元素是否在列表`A`中, # 然后检查当前元素的第一个和第二个元素是否不在文件内容中, # 如果条件满足,则删除当前元素。 for items in A: # 遍历列表A中的每个元素 if items[0] and items[1] not in f2: # 检查当前元素是否在列表A中 del items # 检查当前元素的第一个和第二个元素是否不在文件内容中 f.close() # 关闭文件 print(A) # 输出列表 4.代码运行最终结果展示注:由于结果太多,这里仅展示其中一部分结果
|

【本文地址】
今日新闻 |
推荐新闻 |