python爬取北邮信息门户的每日通知 |
您所在的位置:网站首页 › 北邮信息门户密码 › python爬取北邮信息门户的每日通知 |
python爬取北邮信息门户的每日通知
|
python3.7爬虫初学者实例、北邮信息门户、爬取每日通知并下载相关文件一齐保存到桌面 前言对这篇博客的帮助很大的学习资料:1.网易云课堂Python网络爬虫实战里面的视频很有用,建议认真学一下。 2.博主kelvinmao的博客python网络爬虫学习(五) 模拟登陆北邮信息门户并爬取信息.让我减少了登陆验证的许多繁琐的事情,但也不知对我的能力提升是好是坏? 一、导入相关库import requestsimport http.cookiejar as cookielibfrom bs4 import BeautifulSoup as bsimport reimport pandas as pdimport osimport datetimetoday = datetime.date.today().isoformat()#日期格式 2019-07-05#在桌面建立一个文件夹用于储存文件folder_path = 'C:/Users/john/OneDrive/桌面/' + today +"/"if not os.path.exists(folder_path): os.makedirs(folder_path) 二、模拟登录
1.登录 #携带登陆数据,以post方式登录,response=s.post('https://auth.bupt.edu.cn/authserver/login?service=http%3A%2F%2Fmy.bupt.edu.cn%2Findex.portal',data=postdata,headers=header)#用get方式访问“校内通知”的页面res=s.get('http://my.bupt.edu.cn/index.portal?.pn=p1778',headers=header)#用beautifulsoup解析htmlsoup=bs(res.text,'html.parser')2.查找目标url 3.查找通知发布的日期。 4.爬取内文信息①标题的class=’.text-center’,使用soup.select()函数 ②具体内容的class=’singleinfo’,里面的全部的p标签的内容需要合并 如果日期为今天,就调用函数getNewsDetail()然后存入news_totol[],最后使用pandas的dataframe()和to_excel(),保存文件。 news_total=[]for i in range(0,29): if date[i]!=today+' ': continue newsary=getNewsDetail(url[i]) news_total.append(newsary)df=pd.DataFrame(news_total)df.to_excel(folder_path+'news.xlsx') 五、整体代码# -*- coding: utf-8 -*-"""Created on Fri Jul 5 16:49:28 2019@author: byrwyj"""import requestsimport http.cookiejar as cookielibfrom bs4 import BeautifulSoup as bsimport reimport pandas as pdimport osimport datetimetoday = datetime.date.today().isoformat()folder_path = 'C:/Users/john/OneDrive/桌面/' + today +"/"if not os.path.exists(folder_path): os.makedirs(folder_path)def getLt(str): lt=bs(str,'html.parser') dic={} for inp in lt.form.find_all('input'): if(inp.get('name'))!=None: dic[inp.get('name')]=inp.get('value') return dicheader={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}#setting cookies=requests.Session()s.cookies=cookielib.CookieJar()r=s.get('https://auth.bupt.edu.cn/authserver/login?service=http%3A%2F%2Fmy.bupt.edu.cn%2Findex.portal',headers=header)dic=getLt(r.text)postdata={ 'username':'######',#此处为你的学号 'password':'######',#你的密码 'lt':dic['lt'], 'execution':'e1s1', '_eventId':'submit', 'rmShown':'1'}def getNewsDetail(newsurl): result={} res=s.get(newsurl,headers=header) res.encoding='utf-8' soup=bs(res.text,'html.parser') result['Title']=soup.select('.text-center')[0].text article=[] for p in soup.select('.singleinfo p'): article.append(p.text.strip()) result['article']=article[0] downloadurl=[] filename=[] Docurl=soup.find_all(href=re.compile("attachment")) for k in Docurl: downloadurl.append('http://my.bupt.edu.cn/'+k.get('href')) filename.append(k.string) if filename: for k in range(0,len(filename)): download=s.get(downloadurl[k],headers=header) with open(folder_path+filename[k],"wb") as f: f.write(download.content) f.close() return resultresponse=s.post('https://auth.bupt.edu.cn/authserver/login?service=http%3A%2F%2Fmy.bupt.edu.cn%2Findex.portal',data=postdata,headers=header)res=s.get('http://my.bupt.edu.cn/index.portal?.pn=p1778',headers=header)soup=bs(res.text,'html.parser')news_total=[]date=[]url=[]for j in soup.find_all(href=re.compile("detach")): url.append('http://my.bupt.edu.cn/'+j.get('href'))for j in soup.find_all(class_='time'): date.append(j.string)for i in range(0,29): if date[i]!=today+' ': continue newsary=getNewsDetail(url[i]) news_total.append(newsary)df=pd.DataFrame(news_total)df.to_excel(folder_path+'news.xlsx') 六、这期间的一些坑1.看教学视频使用2倍速,还不听声音,结果大的框架没学会,又得回去看?2.被正则表达式弄得头晕,后来发现又可以不用它,正则表达式真是得细心学,一点一点写,不能急。3.到最后的时候被文件路径的/还是\给弄晕了,导致文件怎么也删除不掉,提示路径错误。重启、压缩后删除、文件粉碎器都试过了,仍是不行。这狗皮膏药真是烦人,最终还是被解决了?。①.打开记事本输入DEL /F /A /Q \?%1RD /S /Q \?%1②.把记事本另存为del.bat③.把要删除文件用鼠标拖入del.bat,删除成功! 这篇代码肯定有许多不完备的地方,但我写的少,也改进不了什么。还是自己太菜?。闲暇的时间才是自己的,才能做一些事情,这篇文章花了我两天时间,挺好,希望自己能学到更多的知识。 2019年07月05日 |
 分析提交的表单
分析提交的表单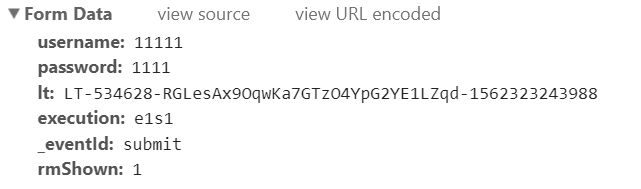 1.username#学号2.password#密码3.lt #这个是webflow发放的流水号4.execution#细心即可发现,是一个不变的值5._eventId:#也是一个不变的值6.rmShown#同是一个不变的值ps:关于lt:按我的理解解释一下:打开网页(即GET请求)时,会有一个流水号,我们可以在网页源代码中找到它。现在又出现一个问题,第二次POST请求(携带表单数据)时,lt就会变化,如何解决?答:可以使用requests的session方法来保持cookie,lt等参数不变。(相当于还是第一次的请求,不过是携带了数据)
1.username#学号2.password#密码3.lt #这个是webflow发放的流水号4.execution#细心即可发现,是一个不变的值5._eventId:#也是一个不变的值6.rmShown#同是一个不变的值ps:关于lt:按我的理解解释一下:打开网页(即GET请求)时,会有一个流水号,我们可以在网页源代码中找到它。现在又出现一个问题,第二次POST请求(携带表单数据)时,lt就会变化,如何解决?答:可以使用requests的session方法来保持cookie,lt等参数不变。(相当于还是第一次的请求,不过是携带了数据)
 如上图,a标签的href加上前缀就是超链接目标的URL,是我需要的信息,但是发现这个a标签既没有id,也没有class,所以使用re.compile()函数,发现每个href的前半部分都是一样的,故使字符串“detach”来进行匹配
如上图,a标签的href加上前缀就是超链接目标的URL,是我需要的信息,但是发现这个a标签既没有id,也没有class,所以使用re.compile()函数,发现每个href的前半部分都是一样的,故使字符串“detach”来进行匹配 日期的class为time,故代码如下
日期的class为time,故代码如下
 ③如果有文件,需要下载下来,文件的url处理方法和二、2一样,采用re.compile()函数;下载时使用open(),参数‘wb’(以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。)
③如果有文件,需要下载下来,文件的url处理方法和二、2一样,采用re.compile()函数;下载时使用open(),参数‘wb’(以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。) 此函数功能:传入url,下载文件,返回一个dict,包含title和article。
此函数功能:传入url,下载文件,返回一个dict,包含title和article。 DEL /F /A /Q \?%1RD /S /Q \?%1全句意思是:强制删除系统文件夹下所有的格式为tmp的文件(哪怕文件是只读的),并且在删除时不用向用户询问是否继续或终止!del 删除命令。/F 强制删除只读文件。/S 从所有子目录删除指定文件。/Q 安静模式。删除全局通配符时,不要求确认。/A 根据属性选择要删除的文件。/S 除目录本身外,还将删除指定目录下的所有子目录和文件。用于删除目录树。/Q 安静模式,加 /S 时,删除目录树结构不再要求确认\?%1 表示是此文件自己
DEL /F /A /Q \?%1RD /S /Q \?%1全句意思是:强制删除系统文件夹下所有的格式为tmp的文件(哪怕文件是只读的),并且在删除时不用向用户询问是否继续或终止!del 删除命令。/F 强制删除只读文件。/S 从所有子目录删除指定文件。/Q 安静模式。删除全局通配符时,不要求确认。/A 根据属性选择要删除的文件。/S 除目录本身外,还将删除指定目录下的所有子目录和文件。用于删除目录树。/Q 安静模式,加 /S 时,删除目录树结构不再要求确认\?%1 表示是此文件自己【本文地址】
今日新闻 |
推荐新闻 |