合肥工业大学2020 |
您所在的位置:网站首页 › 动物实验报告总结 › 合肥工业大学2020 |
合肥工业大学2020
|
实验2的报告抄袭自报告,存粹是为了完成作业,不带任何商业目的。侵删! 文章目录 1 实验1:基于UCI soybean Dataset的分类任务1.1 实验目的1.2 实验任务 1.3 实验环境1.4 实验内容1.4.1 数据导入1.4.2 数据清洗1.4.3 kNN算法1.4.4 决策树算法1.4.5 多层感知器分类器(MLP Classifier)1.4.6 朴素贝叶斯算法1.4.7 SVM算法1.4.8 随机森林算法1.4.9 bagging算法 1.5 实验分析1.5.1 算法最佳性能对比1.5.2 算法平均性能对比1.5.3 测试样例占比对算法结果的影响1.5.4 初始化随机数对算法结果的影响 1.6 实验总结附录 2 实验2:基于UCI Groceries Dataset的关联分析任务2.1 背景2.2 问题描述2.3 实验环境2.4 数据集及实现的技术方案2.4.1 数据集介绍及预处理2.4.2 频繁项集挖掘2.4.3 频繁项目集挖掘 2.5 实验结果附录 3 实验3:基于PACS RAW Labeled Dataset的聚类任务3.1 实验目的3.2 实验任务3.3 实验环境3.4 实验内容3.4.1 库函数引用3.4.2 密度聚类(DBSCAN)3.4.3 伪代码与流程图3.4.4 核心代码 3.5 实验分析附录 源代码 1 实验1:基于UCI soybean Dataset的分类任务 1.1 实验目的• 熟练掌握基本的数据预处理技术; • 学会运用决策树、随机森林等方法解决分类任务。 1.2 实验任务基于Molecular Biology DataSet完成分类任务,kNN、决策树、多层感知器、朴素贝叶斯、SVM、随机森林、bagging方法任选或组合,且不限于上述方法和策略,允许有预处理步骤。 1.3 实验环境• 硬件:Dell G3 3579笔记本 • 软件: OS:Windows 10 Pro N for Workstations 平台工具:PyCharm 2019.3.4 (Professional Edition)、Python 3.7.4、OriginPro 2018(64-bit) 1.4 实验内容 1.4.1 数据导入原始数据集中的数据为csv格式,使用Python的第三方库pandas的csv读取方法可以方便地处理。如1.4.1所述,严重缺失数据的列(仅对于训练数据)应当删除,数据缺失不严重的使用sklearn的SimpleImputer进行补全,本次实验SimpleImputer的参数设置为most_frequent。最后将格式化的数据存入df中,并返回df的值。实现代码如下所示: url = "data/soybean-large.data" dataset = pd.read_csv(url, names=names) dataset = dataset.replace({'?': np.nan}) for item in dataset.columns.values: drop_col(dataset, item, cutoff=0.8) df1 = dataset.iloc[:, 1:] df2 = dataset.iloc[:, :1] imr = SimpleImputer(strategy='most_frequent') imr = imr.fit(df1) imputed_data = imr.transform(df1.values) df = pd.DataFrame(imputed_data) df = pd.concat([df2, df], axis=1) return df 1.4.2 数据清洗数据集中有的数据项严重缺失,为了方便下一步工作,需要剔除训练数据中缺失值大于90%的列。具体操作是构建函数drop_col,以待剔除数据集、列名与阈值为参数,在导入训练数据时调用其进行筛除。实现代码如下所示: def drop_col(df, col_name, cutoff=0.9): n = len(df) cnt = df[col_name].count() if (float(cnt) / n) //扫描 D 用来计数 5) Ct = subset(Ck,t); //找出事务 t 中包含的所有候选 k 项集, 6) for each candidate c∈Ct //对事务 t 包含的每个候选 k 项集的计数加一 7) c.count++; 8) } 9) Lk={c∈Ck | c.count ≥ min_sup} 10) } 11) return L = ∪kLk; procedure apriori_gen(Lk-1: frequent (k-1)-itemset; min_sup: support) 1) for each itemset l1∈Lk-1 2) for each itemset l2∈Lk-1 3) if (l1[1]=l2[1])∧...∧(l1[k-2]=l2[k-2])∧(l1[k-1] # cluster index C = 1 for each unvisited point p in dataset { mark p as visited # find neighbors Neighbors N = find the neighboring points of p if |N|>=MinPts: N = N U N' if p' is not a member of any cluster: add p' to cluster C }DBSCAN算法的流程图如图所示。  图 3.4.1 基本DBSCAN算法流程图
3.4.4 核心代码
图 3.4.1 基本DBSCAN算法流程图
3.4.4 核心代码
本次实验使用Python所实现DBSCAN代码如下所示。 def dbscan(X, eps, minpts): rows = X.shape[0] classification_result = [INITIAL] * rows core_point_list = list() cluster_id = 0 for i in range(rows): if classification_result[i] == INITIAL: neighborhoods = pointsWithinEps(X[i],X,eps) if len(neighborhoods) 0: need_check_index = unClassification_neighborhoods[0] check_result = pointsWithinEps(X[need_check_index],X,eps) if len(check_result) >= minpts: core_point_list.append(need_check_index) for i in range(len(check_result)): point = check_result[i] if classification_result[point] == INITIAL or classification_result[point] == NOISE: if classification_result[point] == INITIAL: unClassification_neighborhoods.append(point) classification_result[point] = cluster_id unClassification_neighborhoods = unClassification_neighborhoods[1:] cluster_id = cluster_id + 1 core_point_list.sort() return [classification_result,core_point_list] 3.5 实验分析如图3.5.1至图3.5.3所示为本次实验结果。 图片次序: abcd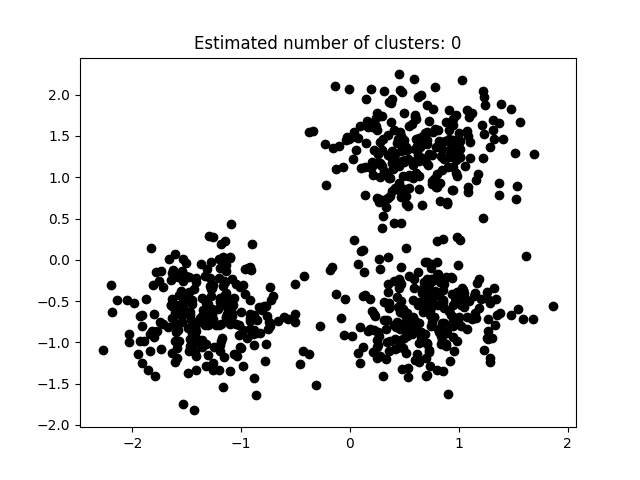 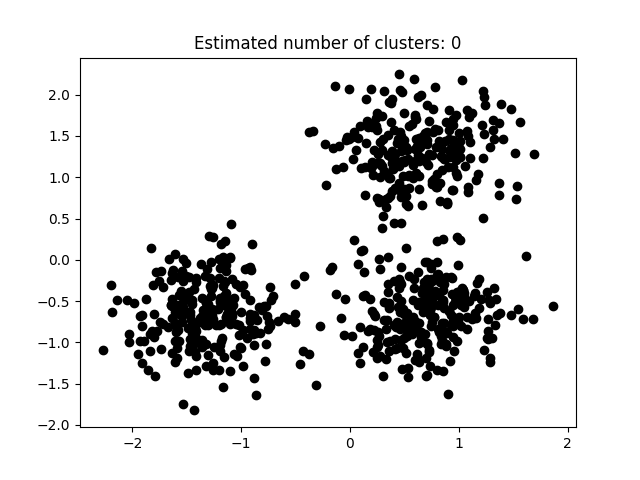 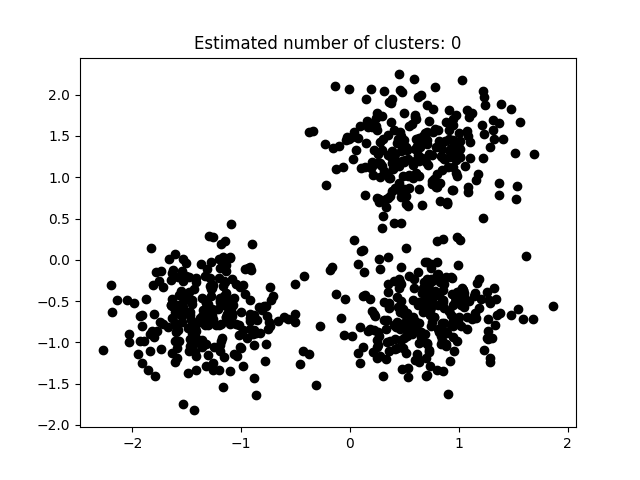 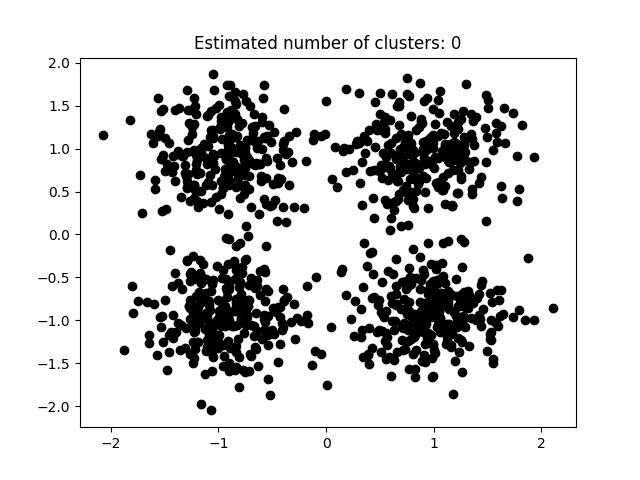 图 3.5.1 聚类结果-1
图 3.5.1 聚类结果-1
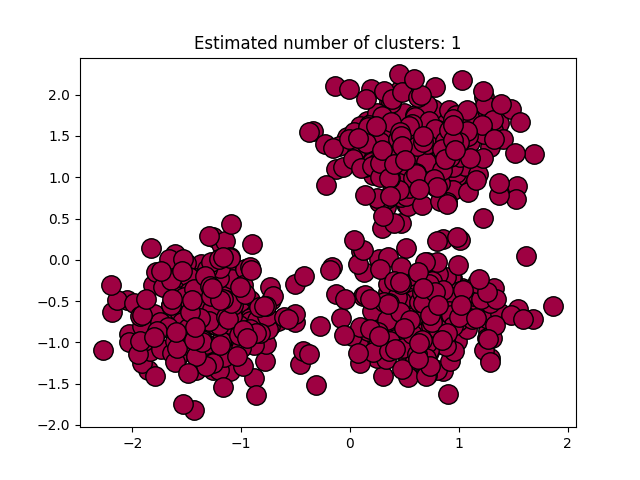 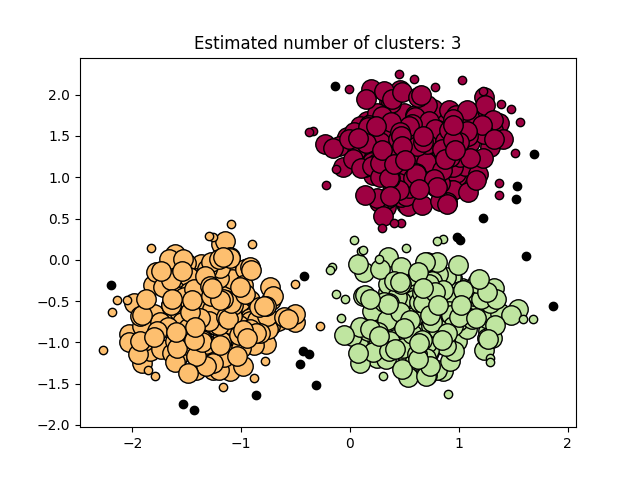 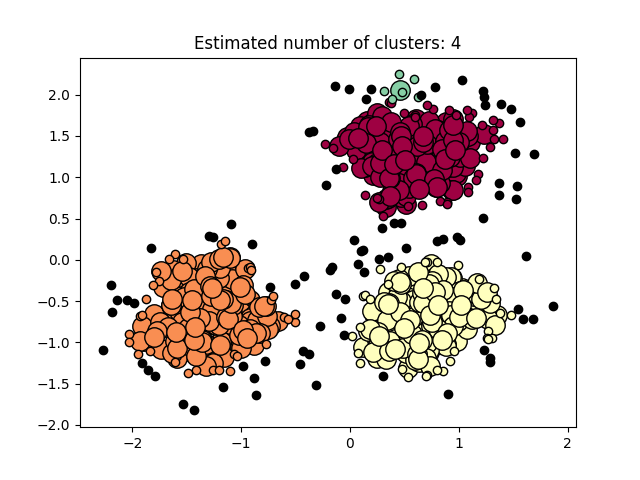 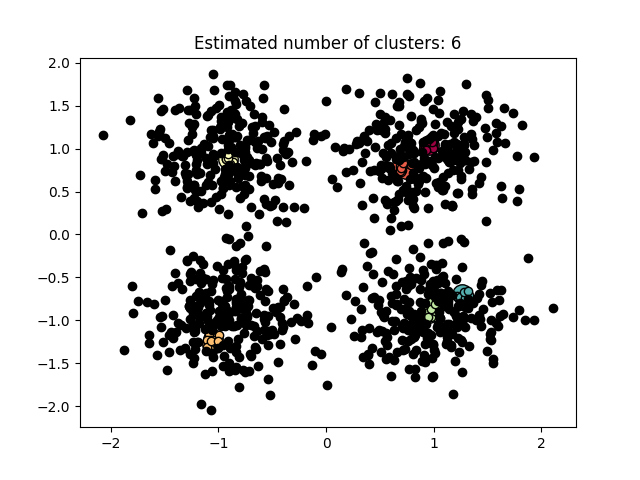 图 3.5.2 聚类结果-2
图 3.5.2 聚类结果-2
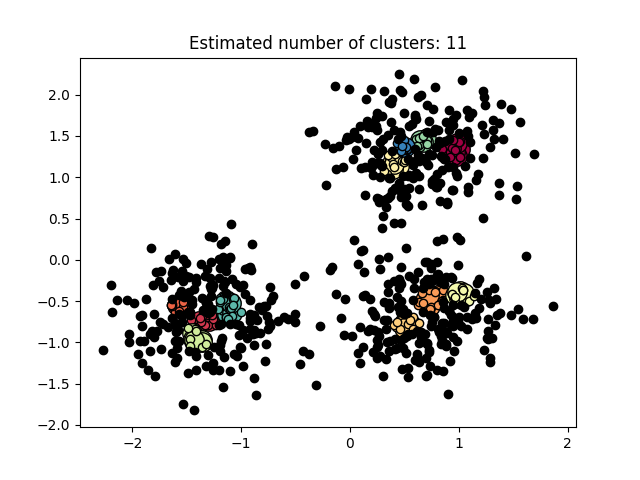 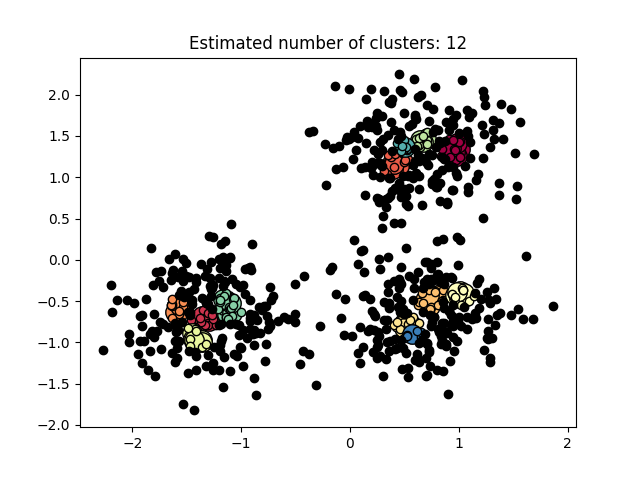 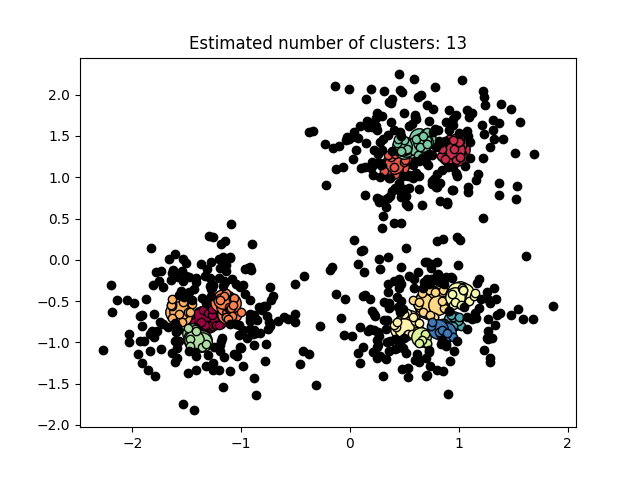 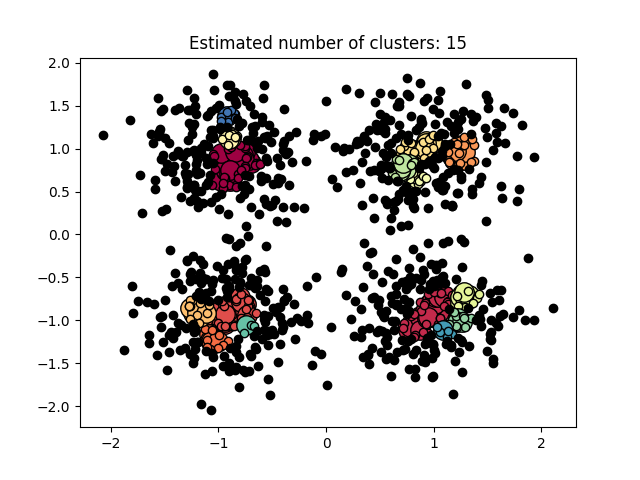 图 3.5.3 聚类结果-3
图 3.5.3 聚类结果-3
图3.5.1中图a)至图d)的eps与minpts依次分别为:[0.015, 10]、[0.020, 10]、[0.035, 20]与[0.061, 20]。 图3.5.2中图a)至图d)的eps与minpts依次分别为:[0.9, 40]、[0.3, 10]、[0.2, 10]与[0.07, 10]。 图3.5.3中图a)至图d)的eps与minpts依次分别为:[0.091, 10]、[0.093, 10]、[0.10, 10]与[0.0.096, 10]。 表 3.5.1 聚类结果参数与聚类数目 epsminptsEstimated number of cluster(s)0.0151000.021000.0352000.0612000.94010.31030.21040.071060.09110110.09310120.110130.0961015表3.5.1所示为图3.5.1至图3.5.3的参数与估计聚类数目汇总,从实验结果可知:minpts与eps的比值过大时,估计的聚类数目一般为0;随着两者比值减小,估计的聚类数目增大;当比值到达某一阈值时,估计的聚类数目又开始减少。 本次实验所使用的聚类算法是DBSCAN,与K-Means相比,其具有以下优点: •原始数据分布规律没有明显要求,能适应任意数据集分布形状的空间聚类,因此数据集适用性更广,尤其是对非凸装、圆环形等异性簇分布的识别较好; •无需指定聚类数量,对结果的先验要求不高; •由于DBSCAN可区分核心对象、边界点和噪点,因此对噪声的过滤效果好,能有效应对数据噪点。 由于他对整个数据集进行操作且聚类时使用了一个全局性的表征密度的参数,因此也存在比较明显的弱点: •对于高纬度问题,基于半径和密度的定义成问题; •当簇的密度变化太大时,聚类结果较差; •当数据量增大时,要求较大的内存支持,I/O消耗也很大。 附录验收时老师提问与个人回答 问:聚类聚了几类? 答:本次实验我使用的聚类算法是DBSCAN,每次的实验结果随着minpts与eps的不同而变化。 源代码链接 |
【本文地址】
今日新闻 |
推荐新闻 |