GPT |
您所在的位置:网站首页 › 动漫的声音合成软件有哪些 › GPT |
GPT

想象一下你第一次听到机器发出的声音,听起来就像是人类的声音。你既惊讶又难以置信,对这项技术能走多远充满好奇。GPT-SoVITS 不仅突破了界限,还重新定义了界限。这不仅仅是机器说话;而是它们用一种带有人类语言的细微差别、情感和独特性的声音说话,标志着语音技术的未来已经到来。 GPT-SoVITS 的主要特点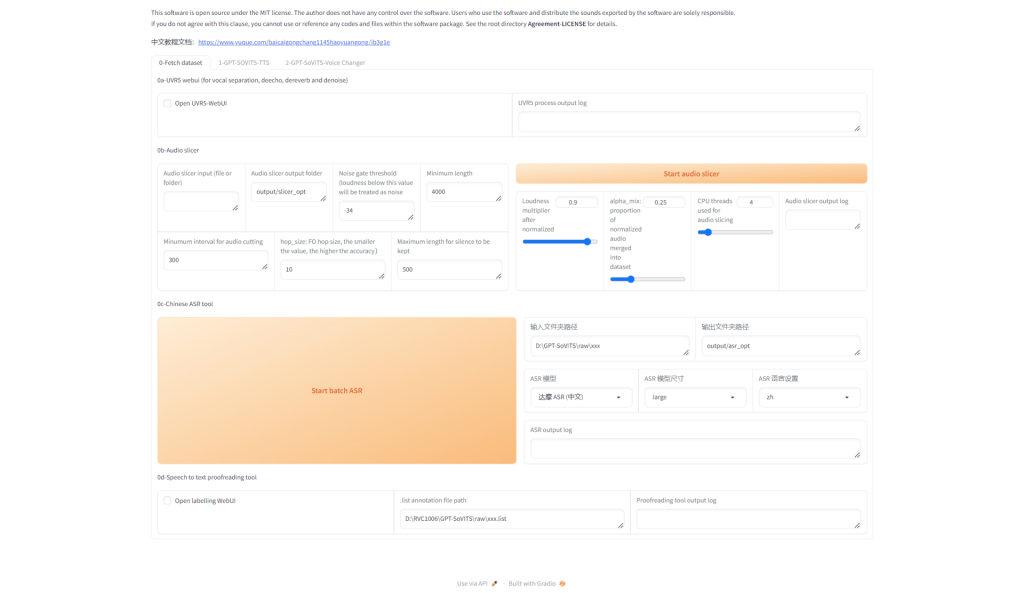
GPT-SoVITS 不仅仅是一个工具;它是语音技术的一项突破,带来了多项创新功能。让我们详细探讨一下这些功能: 零样本 TTS:未来展望 即时语音克隆:借助零样本 TTS,GPT-SoVITS 只需使用任何语音的 5 秒样本即可进行文本到语音的转换。此功能类似于在快照中捕捉声音的本质,然后用该声音将书面文字变为现实,而这一切都不需要大量训练数据。 小样本 TTS:用最少的数据创造真实感 增强语音相似度: GPT-SoVITS 的少样本 TTS 功能简直神奇。通过仅使用 1 分钟的语音数据训练模型,它可以实现非凡的语音相似度和真实度。这对于创建个性化语音助手、有声读物或任何以语音独特性为关键的应用程序尤其有益。 跨语言支持:打破语言障碍 多语言推理: GPT-SoVITS 的一大突出特点是能够使用不同于训练数据集的语言进行推理。目前,它支持英语、日语和中文等主要语言。这种跨语言支持为全球交流和内容创作开辟了无限可能,使其成为全球用户的多功能工具。 集成的 WebUI 工具:赋能创作者 全面的工具包: GPT-SoVITS 附带一套集成的 WebUI 工具,旨在简化语音克隆和 TTS 模型创建过程。这些工具包括: 语音伴奏分离:将人声与背景音乐隔离,更容易创建干净的训练数据集。 自动训练集分割:通过自动分割语音数据简化训练集的创建。 中文 ASR 和文本标注:这些功能可帮助用户转录和标注中文语音数据,从而促进具有中文支持的 TTS 模型的训练。这些功能共同使 GPT-SoVITS 成为任何想要探索语音技术前沿的人(从业余爱好者和内容创作者到该领域的研究人员和专业人士)的综合解决方案。 安装 GPT-SoVITS:准备环境设置 GPT-SoVITS 需要根据您的操作系统进行特定准备。以下是分步指南,可确保您已准备好使用 GPT-SoVITS 进入高级语音合成的世界。 系统硬解要求训练:1.Windows10/11操作系统,支持 CUDA 的 nVIDIA 显卡,8G以上显存;2.macOS 12.3或更高版本,搭载Apple芯片(M系列芯片)或AMD GPU的Mac推理:1.Windows10/11操作系统,支持 CUDA 的 nVIDIA 显卡,4G以上显存;2.macOS 12.3或更高版本,搭载Apple芯片(M系列芯片)或AMD GPU的Mac Docker 部署对于系统硬解方面的要求相同。 对于 Windows 用户: 必备下载: Windows 用户需要下载ffmpeg.exe和ffprobe.exe。这些对于处理多媒体文件至关重要,应直接放在 GPT-SoVITS 根目录中。这允许 GPT-SoVITS 无缝处理音频文件。 环境设置:首先设置合适的 Python 环境。建议使用 Conda 来有效管理依赖项。 对于Mac用户: 系统要求: Mac 用户应检查其系统的兼容性,尤其是 GPU 支持。GPT-SoVITS 针对配备 Apple 芯片或 AMD GPU 的 Mac 进行了优化。此外,请确保您的 macOS 版本为 12.3 或更高版本,以充分利用 GPU 功能。 Conda 环境:与 Windows 类似,首先创建一个 Conda 环境。这会将您的 GPT-SoVITS 设置与其他 Python 项目隔离开来,确保依赖项管理轻松无忧。 安装步骤: Conda 环境创建: 执行conda create -n GPTSoVits python=3.9以使用 Python 3.9 创建一个名为“GPTSoVits”的新环境。选择此版本是因为它与 GPT-SoVITS 要求兼容。 使用 激活新环境conda activate GPTSoVits。 依赖项安装: 使用 安装必要的 Python 包pip install -r requirements.txt。此命令读取requirements.txt文件中列出的所有依赖项并将其安装在您的 Conda 环境中。 FFmpeg 安装: Windows:下载ffmpeg.exe和后ffprobe.exe,确保它们位于 GPT-SoVITS 根目录中。 Mac:使用 Homebrew 运行 安装 FFmpeg brew install ffmpeg。这简化了安装过程并确保 FFmpeg 与您的系统很好地集成。 最后检查: 验证所有安装是否成功以及环境是否正确设置。运行一个简单的测试(例如使用 GPT-SoVITS 功能的 Python 脚本或命令)可以帮助确认一切正常。通过遵循这些步骤,您将拥有一个强大的环境来探索 GPT-SoVITS 的功能,无论您使用的是 Windows 还是 Mac。这种准备可确保您可以专注于创建和试验语音合成,而不必担心技术故障。 在 Windows 上安装 GPT-SoVITS步骤指南: 下载预压缩文件: 导航到 GPT-SoVITS 存储库并下载针对 Windows 用户定制的prezip 文件。 解压缩文件: 在您的计算机上找到下载的文件并使用您喜欢的存档管理器将其解压缩。 启动 GPT-SoVITS: 在解压后的文件夹中,找到并双击go-webui.bat。此操作将启动 GPT-SoVITS WebUI,使应用程序可供使用。 安装 FFmpeg(如果需要): ffmpeg.exe从可信来源下载ffprobe.exe。将这些文件放在 GPT-SoVITS 的根目录中以启用音频处理功能。 预训练模型: 为了实现语音分离或混响消除等增强功能,请下载额外的预训练模型并将其放在 GPT-SoVITS 文件夹内的指定目录中。通过遵循这些步骤,Windows 用户可以轻松设置 GPT-SoVITS 并探索其语音克隆功能。 使用 Docker 在 Mac/Linux 上安装 GPT-SoVITS步骤指南(以 Mac 为例。Linux 的步骤基本类似) 准备你的Mac: 确保您的 Mac 配备了 Apple 芯片或 AMD GPU 并且运行的是 macOS 12.3 或更高版本。 xcode-select --install通过在终端中执行来安装 Xcode 命令行工具。 Docker 安装/设置: 如果尚未安装,请从 Docker 官方网站下载并安装 Docker for Mac。克隆 GPT-SoVITS 存储库: 使用 Git 将 GPT-SoVITS 存储库克隆到本地机器或直接从 GitHub 下载。 git clone https://github.com/RVC-Boss/GPT-SoVITS.git导航到 GPT-SoVITS 目录: 打开终端窗口并导航到克隆或下载的 GPT-SoVITS 目录。Docker 组成: 在 GPT-SoVITS 目录中找到该docker-compose.yaml文件。确保它根据您的需要进行配置,并根据需要调整环境变量和卷配置。使用 Docker Compose 启动: docker compose -f "docker-compose.yaml" up -d在终端中运行。此命令将在 Docker 容器中启动 GPT-SoVITS 应用程序。访问 GPT-SoVITS: 一旦容器启动并运行,您可以通过导航到终端输出中提供的本地地址,通过 Web 浏览器访问 GPT-SoVITS WebUI。通过利用 Docker,Mac 用户可以克服兼容性问题并利用 GPT-SoVITS 的高级语音合成功能,而无需在 macOS 上直接安装。 博主的开发机运行的是 Ubuntu 22.04,所以我将 docker 版本的 GPT-SoVITS 部署在 Ubuntu 22.04 上。后续的示例均在 Ubuntu 22.04 + GPT-SoVITS docker 运行。 上手使用 GPT-SoVITS接下来我们开始使用 GPT-SoVITS进行声音处理,训练自己的声音模型,并基于训练好的声音模型进行推理。所有的操作均使用 GPT-SoVITS 的web界面,如果您按照前面的步骤安装好 GPT-SoVITS 的话,可以按照下面的步骤执行。如果您没有自己的 GPT-SoVITS 部署环境的话,可以访问 HY’s AI Playgound 在博主部署好的环境里进行体验,选择 GPT-SoVITS,点击链接栏的地址即可访问。  声音准备和处理
声音准备和处理
准备一段超过1分钟的纯净语音音频文件进行训练,理想情况下应在安静的环境中完成录制。如果录音中包含任何背景噪音或杂音,进行以下处理是声音处理必要的;若没有,则此步骤不强制要求,但仍然推荐执行。 1. 人声分离这个过程涉及到使用UVR5(一款音频处理软件)来提炼出清晰的人声,我们将使用这些提炼后的干声音频进行训练。启动程序后,根据下图指示选择“Open UVR5-Webui”以进入操作界面。 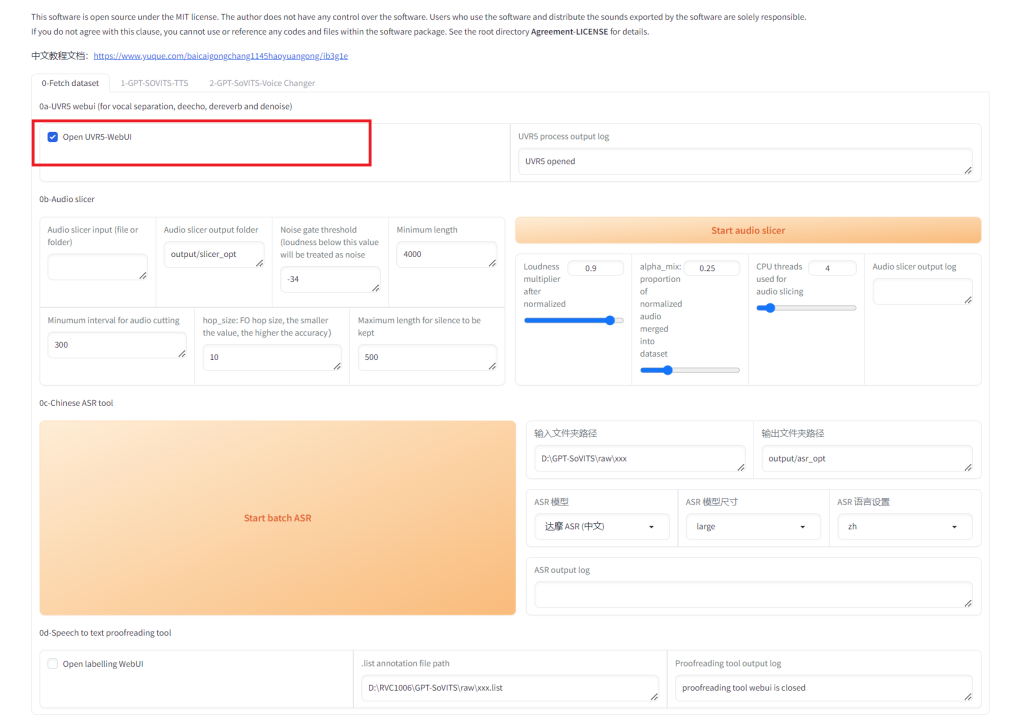
开启“ Open UVR5-Webui ”后,GPT-SoVITS 将会开启另外一个端口 9873 用于人声分离。访问博主搭建的服务器的9873端口:https://nas.yanghong.dev:9873,将看到如下的界面: 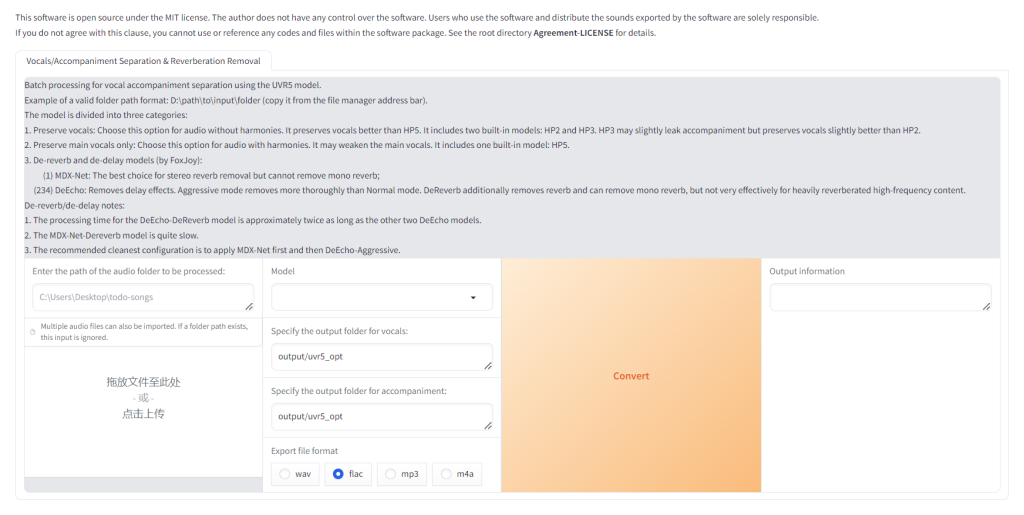
进入到UVR5的界面,按如下操作步骤按顺序操作: 选择录制好的声音文件(我录制了一分钟的声音文件 audio_record.wav ) 选择声音分离的模型 (我这里使用 HP5_only_main_vocal ) 点击 Convert 开始分离
等待处理完成。看到 “audio-record.wav->Success” 信息则表示处理已经成功完成了。 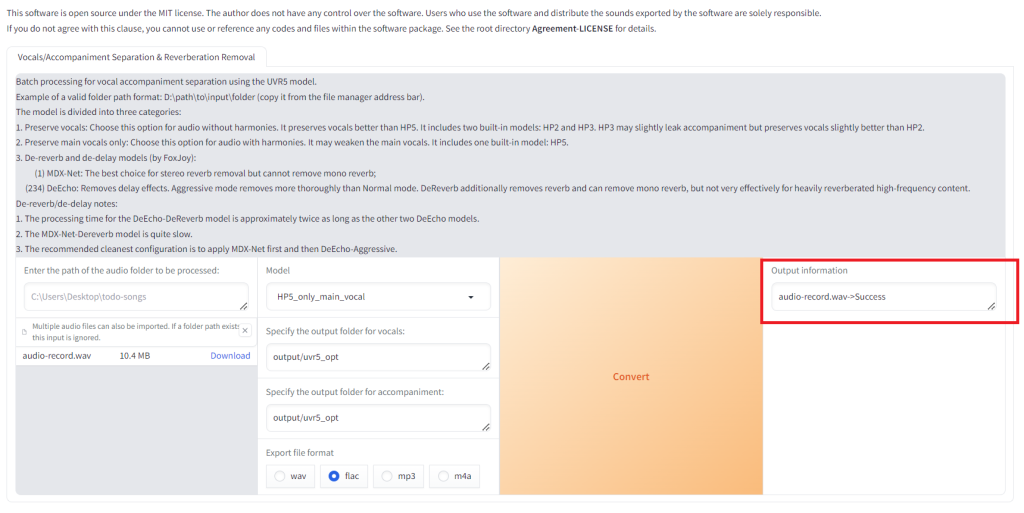
登录服务器后台 output 目录,可以看到如下两个文件已经生成。vocal 开头的文件是分离出来的人声,instrument 开头的文件是分离出来的背景音乐和其它声音。可以把instrument开头的文件删除,只保留人声。(您在试用博主部署的 GPT-SoVITS docker 的时候没有权限登录后台,所以此步无法操作可跳过。) 
使用DeEchoAggressive把干声再处理一次,注意路径要写对。我配置的 GPT-SoVITS docker 在这里使用目录 /workspace/output/uvr5_opt 。 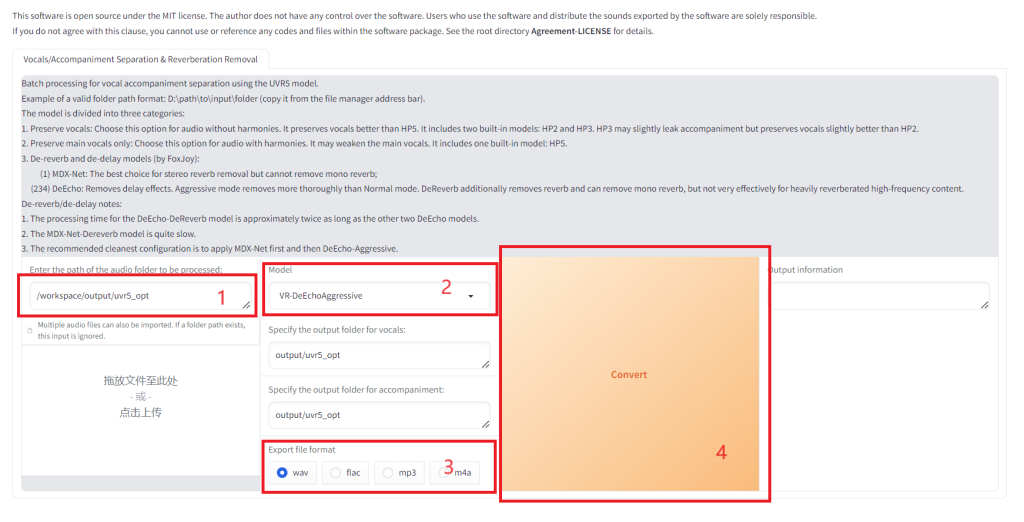
看到如下红框内的字样表示转换已经成功。我这里没有删除 instrument 文件所以两个都转了。 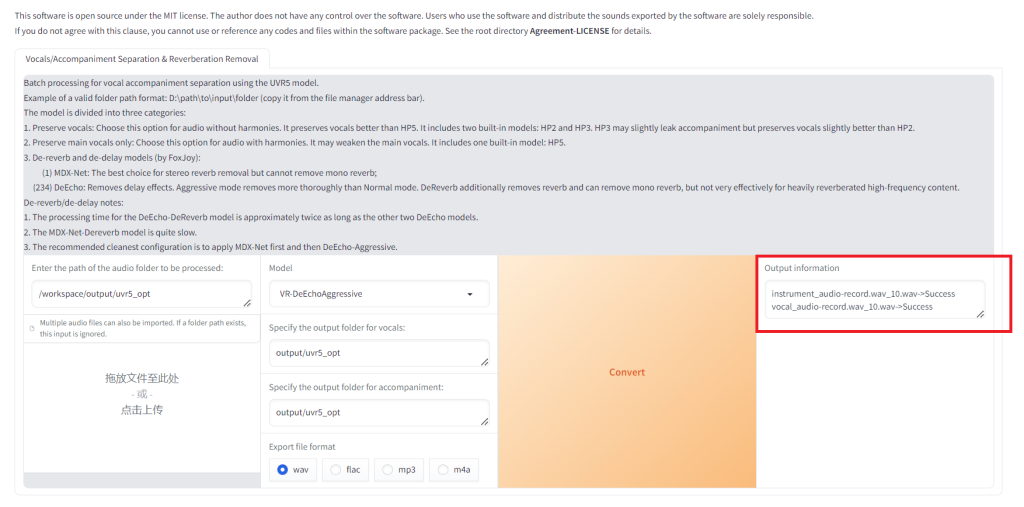
登录服务器后台 output 目录,可以看到有几个新的文件已经生成。我们将使用到的文件名为 vocal_vocal_audio-record.wav_10.wav_10.wav 。可以把其它文件都删掉,只保留 vocal_vocal_audio-record.wav_10.wav_10.wav 即可(您在试用博主部署的 GPT-SoVITS docker 的时候没有权限登录后台,所以此步无法操作可跳过。) 
干声提取成功后,UVR5的界面就可以关掉了,因为后面还会打开几个界面,担心不熟悉的朋友会懵,不关也可以。请记住文件名 vocal_vocal_audio-record.wav_10.wav_10.wav,并将红色的部分用您自己的文件名代替,后续步骤需要使用到这个文件名。 2. 切割音频接下来我们要将干声音频切割。这一步必须要做,否则可能会爆显存。按照如下的步骤开始切割。 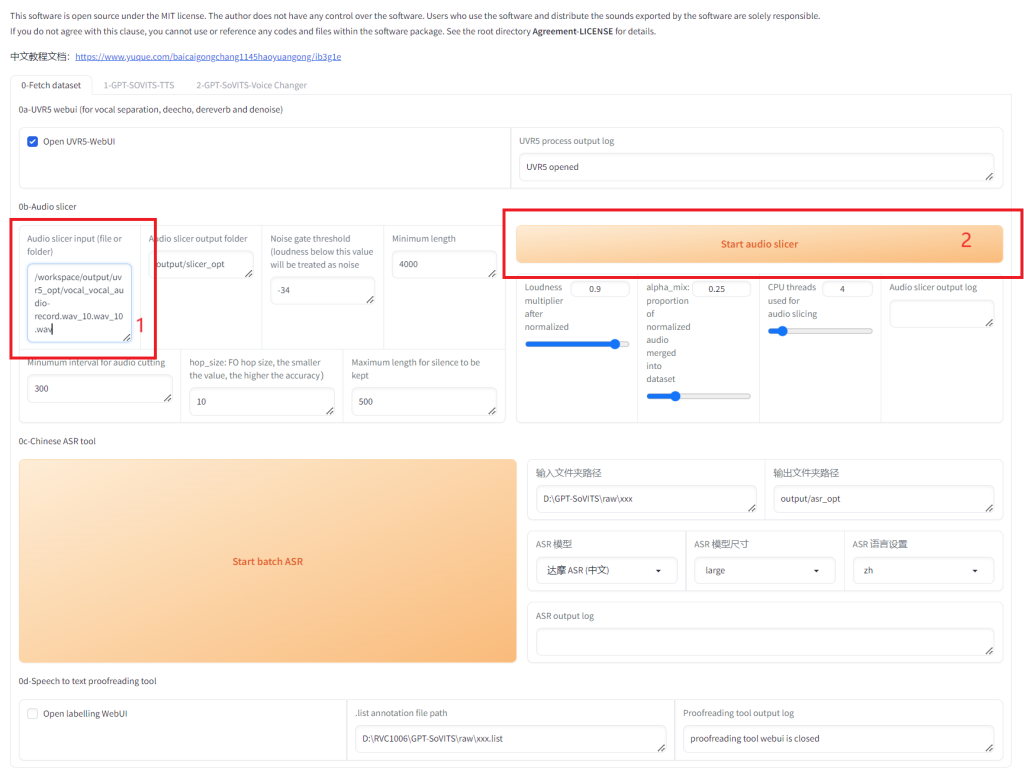
等待切割完成。 
回到系统后台,可以看到音频被切割为多个小段音频(您在试用博主部署的 GPT-SoVITS docker 的时候没有权限登录后台,所以此步无法操作可跳过。)  3 打标
3 打标
打标的过程自动把输入的干净语音音频转换成文本,以指导训练系统理解在音频的具体时间点上对应的是哪些文字。请注意,所输入的路径应为上一步骤中切割好的音频文件路径。 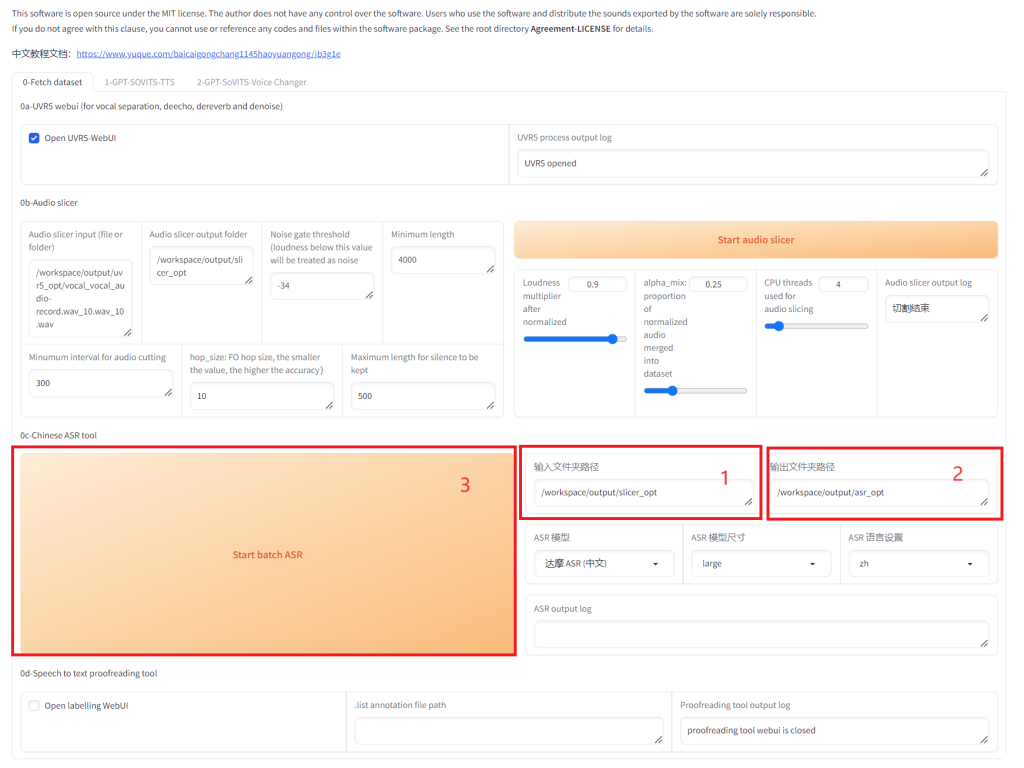
看到如下红框内的信息表示 ASR 语音识别过程已经完成。 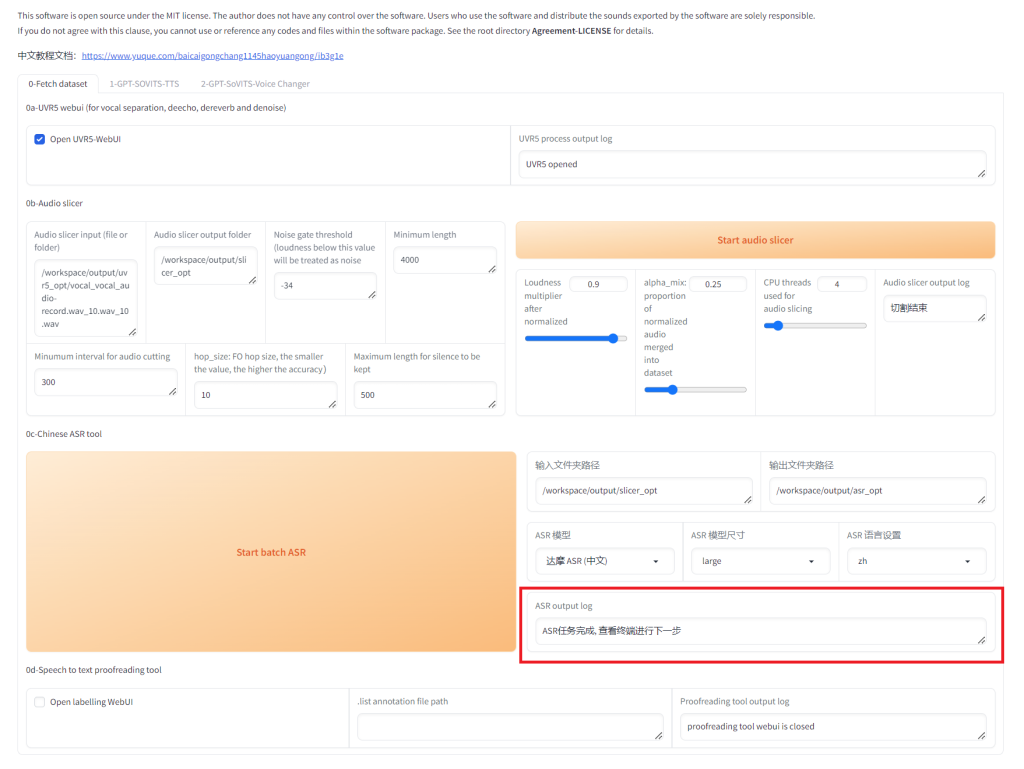
进入后台可以看到 slicer_opt.list 文件已经生成。这个就是自动打标生成的文件(您在试用博主部署的 GPT-SoVITS docker 的时候没有权限登录后台,所以此步无法操作可跳过。)  4 人工校对
4 人工校对
上一步的打标工作是自动做的,可能有些识别的不准,所以人工校对一下,看看是否有需要调整的地方。一般来讲系统自动识别的已经很准确了,所以这个步骤也可以跳过。 按照如下的步骤开启人工打标 WebUI。请注意步骤的先后顺序,先输入 .list 文件的路径,然后再开启 labelling WebUI。 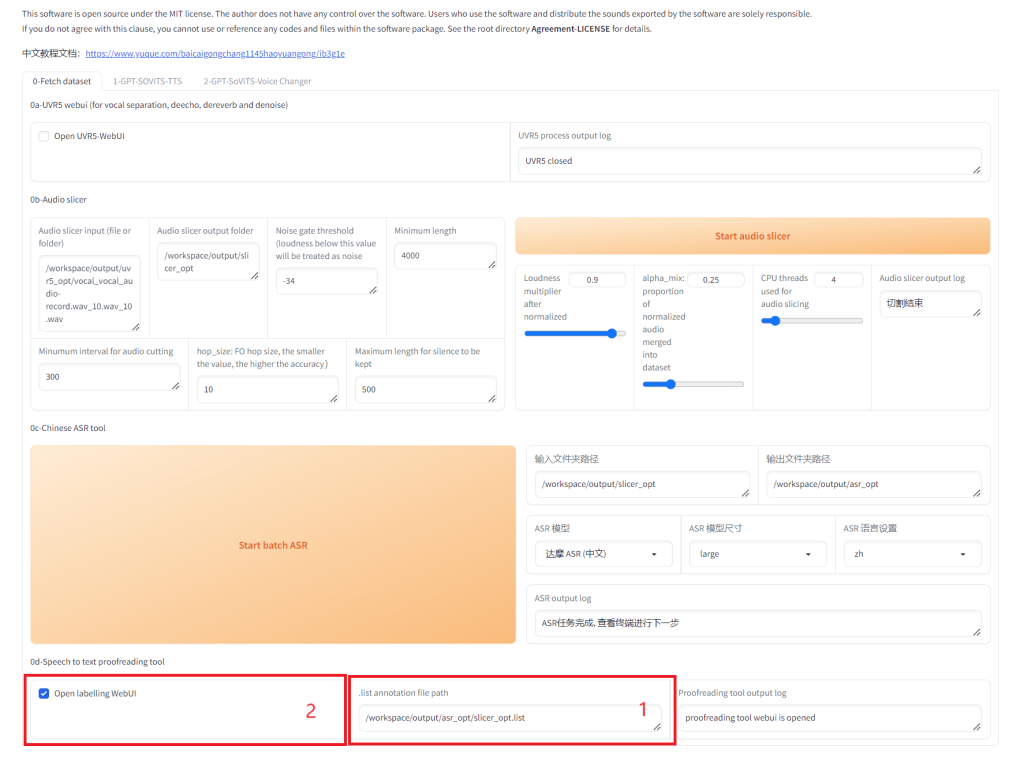
开启 labelling WebUI 后,GPT-SoVITS 会启用端口9871。访问博主的 GPT-SoVITS 服务器来进行人工校对:https://nas.yanghong.dev:9871。 以下是人工校对的web界面,列出了部分自动识别结果,可根据情况修改然后保存。 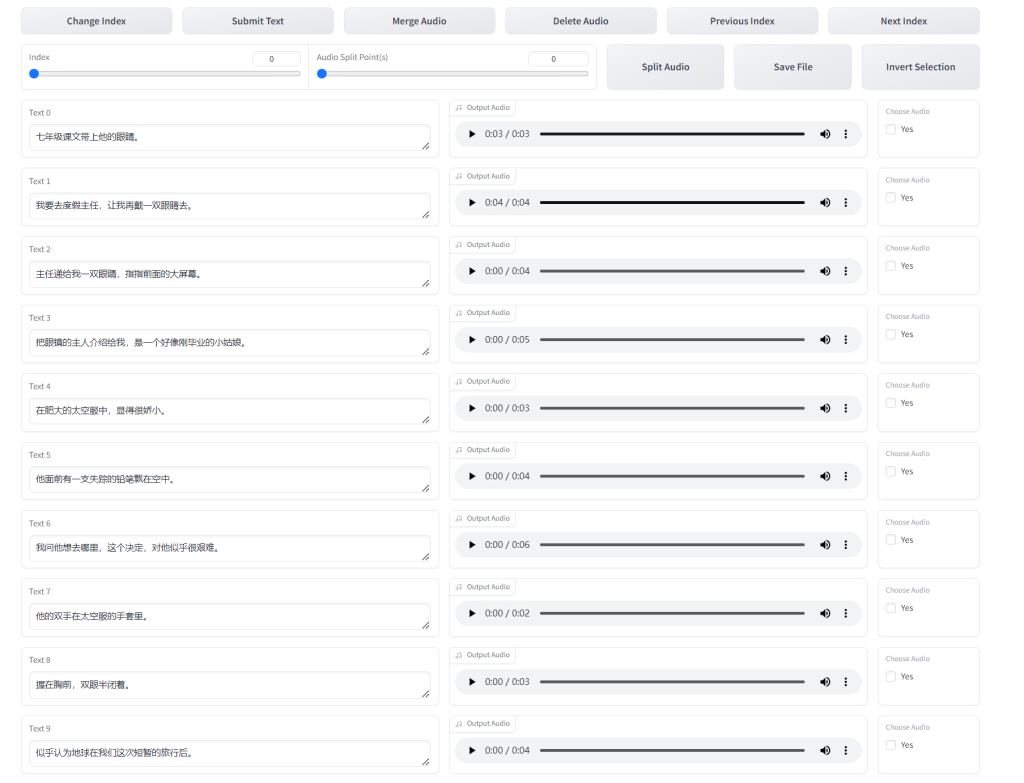 训练
训练
声音处理完成,就可以开始进行训练了。 1. 数据集格式化进入 1-GPT-SOVITS-TTS – 1A-Dataset formatting 界面,按照下图填写,注意各个路径要按照实际情况正确填写。填写完成后,按照先后顺序分别点击下面三个按钮,每个按钮点完后,等待执行结束再点击下一个。 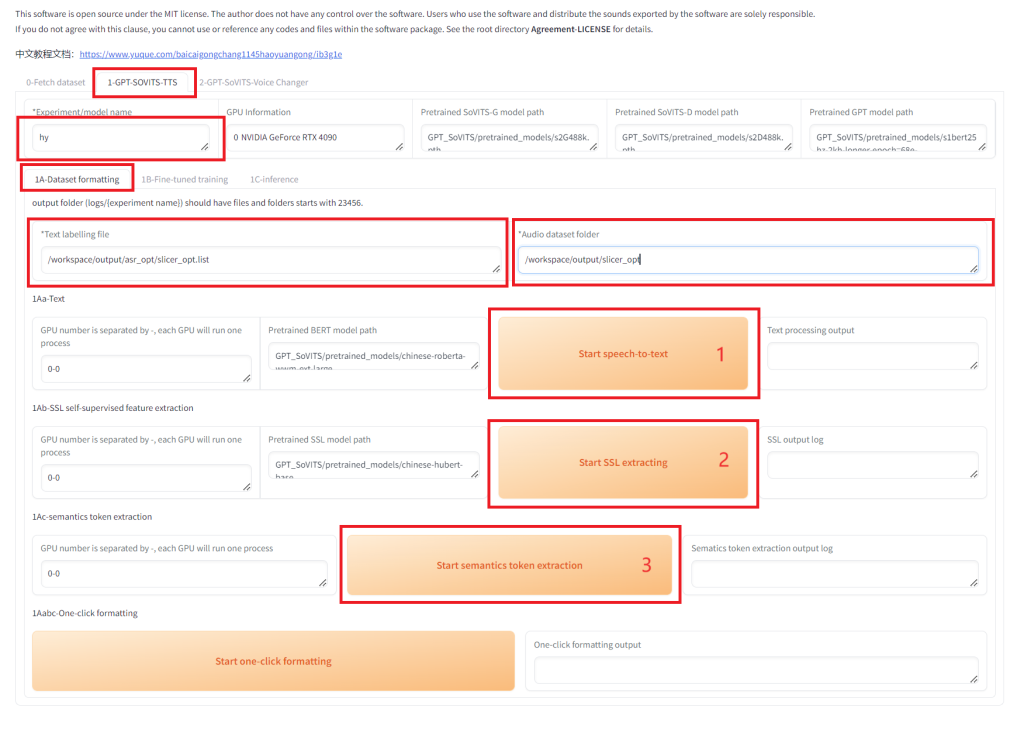
等待3个步骤都完成。 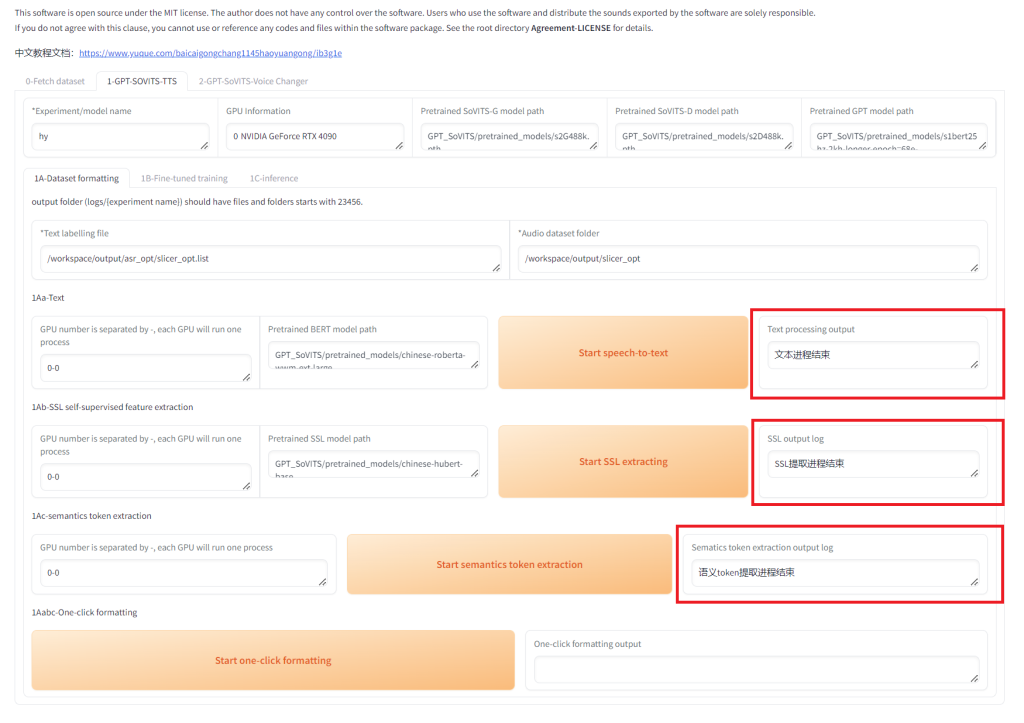 2 SoVITS训练
2 SoVITS训练
进入 1B-Fine-tuned training 界面,填写模型名称,设置batch size (位置3),建议batch_size设置为显存的一半,高了会爆显存。接着设置SoVITS模型轮数(total epochs,位置4),可以设置的高一点,GPT模型轮数(位置7)不能高于20(一般情况下)建议设置10。点击”Start SoVITS training”开始训练。 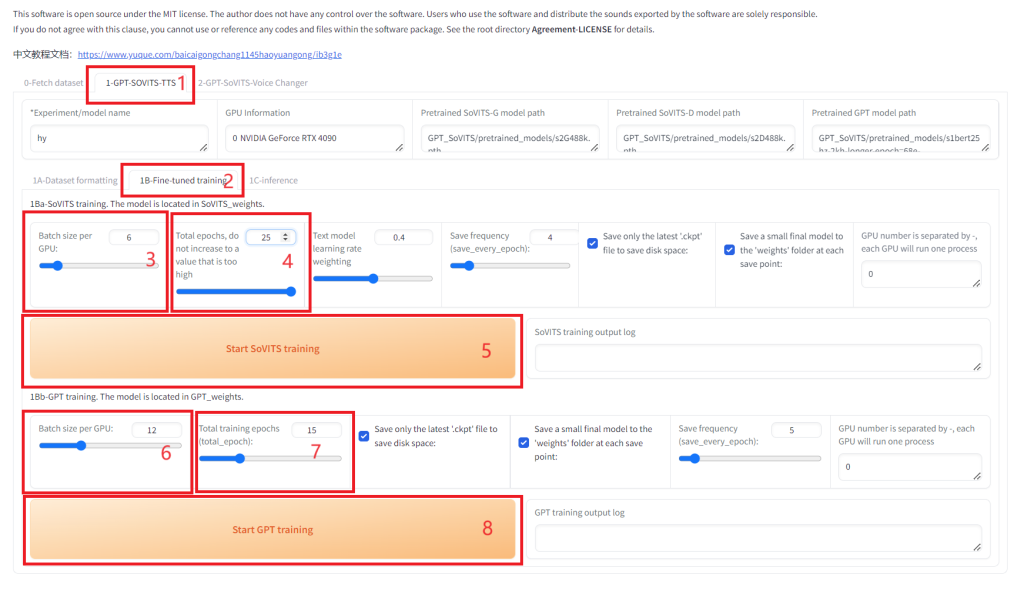
点击Start SoVITS traing之后,可以看到开始训练了。训练需要一点点时间,看到红框内的信息表示 SoVITS 部分的训练就完成了。 GPT 训练接下来点击 “Start GPT training” (上图的位置8)来开始 GPT 训练。 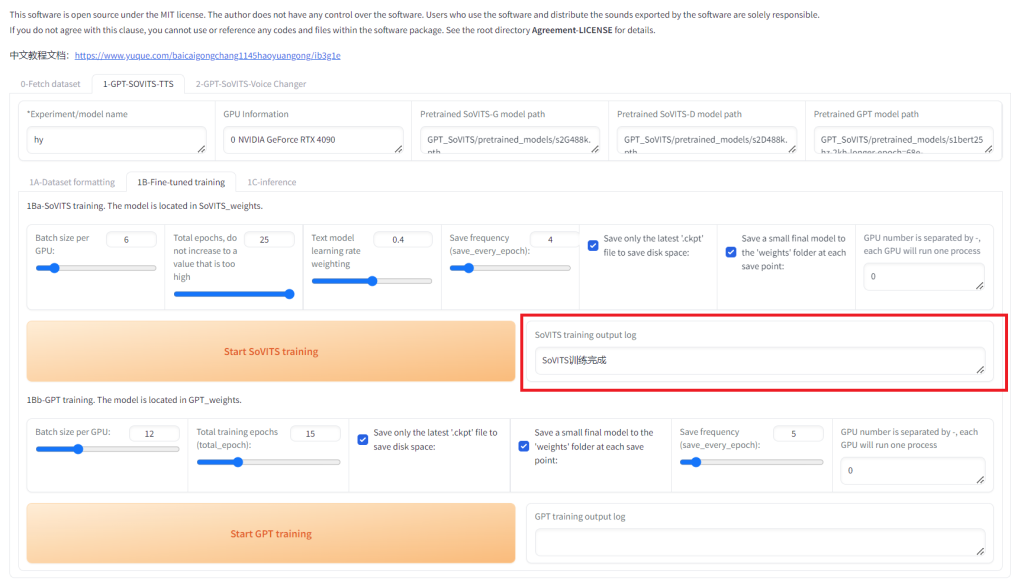
当看到红框内的信息的时候则表示 GPT 训练已经顺利完成。 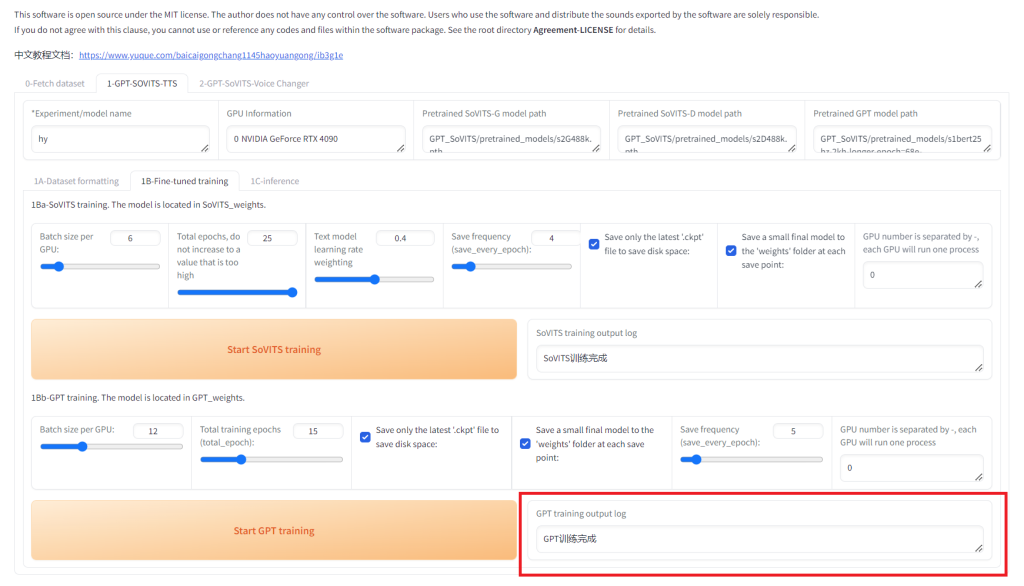
训练的时候可以如果爆显存了就调低batch size,或者存在过长的音频,需要在切割音频环节将过长音频再次切割。 训练完成后可以看到 SoVITS_weights 目录中多了几个模型,hy 是我前面指定的模型名。(您在试用博主部署的 GPT-SoVITS docker 的时候没有权限登录后台,所以此步无法操作可跳过。) 
到这里整个训练的过程都完成了,下一步可以进行推理了。 4. 推理终于可以使用看效果了!推理又是另外一个界面。 先再 1-GPT-SOVITS-TTS 页面,将 Pretrained SoVITS-G model path , Pretrained SoVITS-D model path 和 Pretrained GPT model path 都设置为生成的模型的路径。我们这里的路径是 /workspace/SoVITS_weights 。然后进入 1C-inference 页面,点击 refreshing model paths 刷新模型清单。 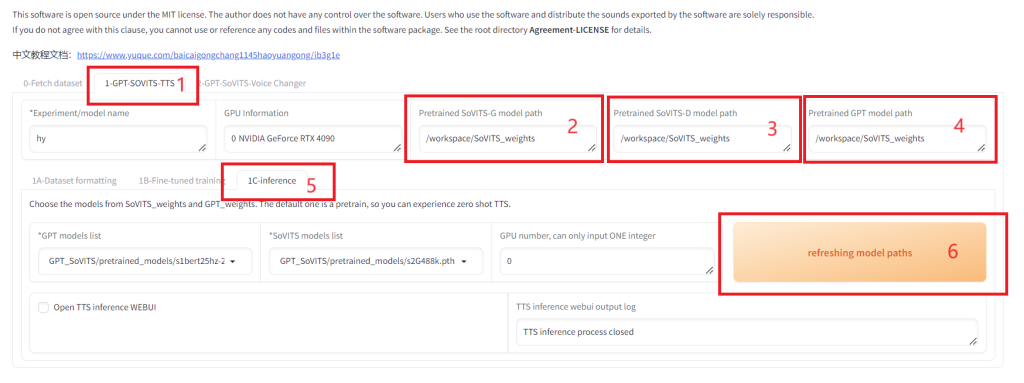
刷新模型后,我们在 GPT models list 和 SoVITS models list 里选择我们刚才训练好的模型,然后勾选 Open TTS inference WEBUI。它将打开另外一个端口 9872 。我们可以通过博主搭建的服务器来访问:https://nas.yanghong.dev:9872 。 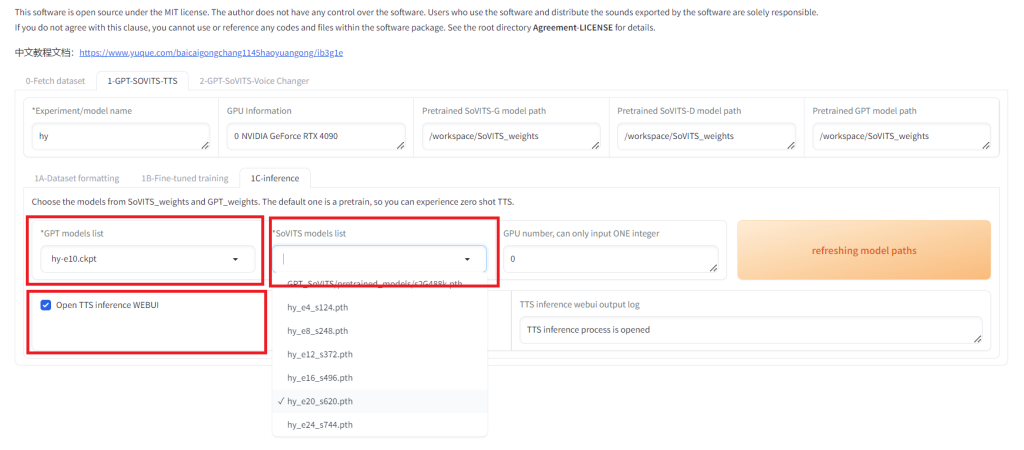
下图就是推理界面了。按照下图方式设置,位置1的 GPT weight list / SoVITS weight list 是我们在上一步选择的自己训练的模型,位置2处需要上传一个 3~12 秒的音频文件,位置3 Text for inference audio 是该音频文件对应的文字。位置4 Inference text 处输入你需要转成音频的文字,我这里输入了一篇小短文。如果文字较长,请在位置5 How to slic the sentence 处选择切词的方式,我这里选择了“按标点符号切”。设置好后就可以点击 Start inference 开始推理了。 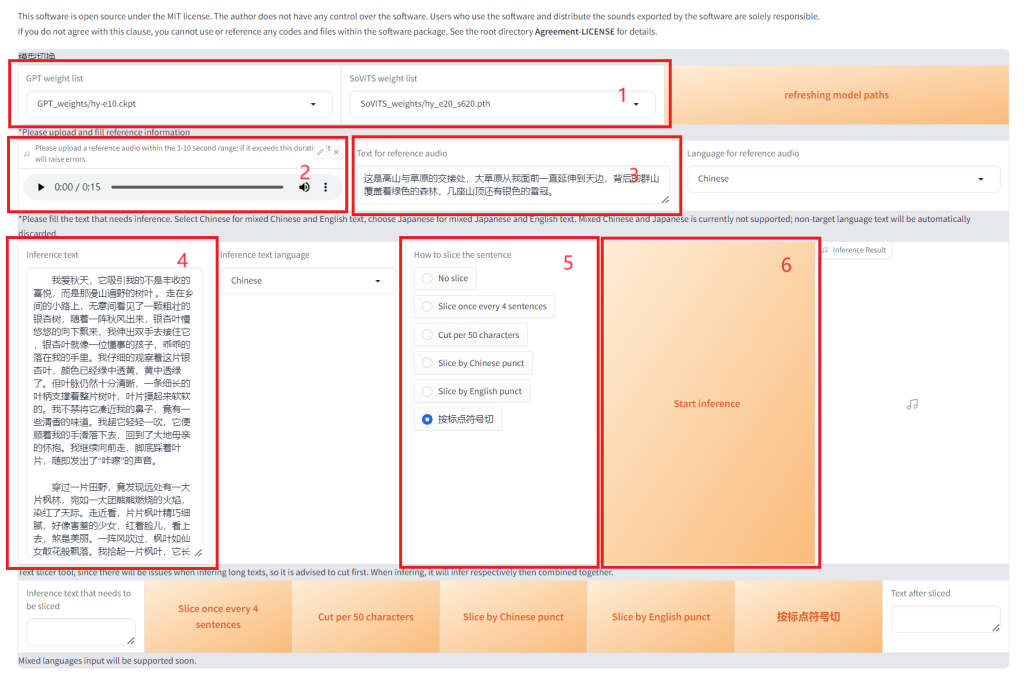
不出意外的话,稍等一会语音就合成好了,可以试听,也可以点击右边的三个小圆点下载到本地。 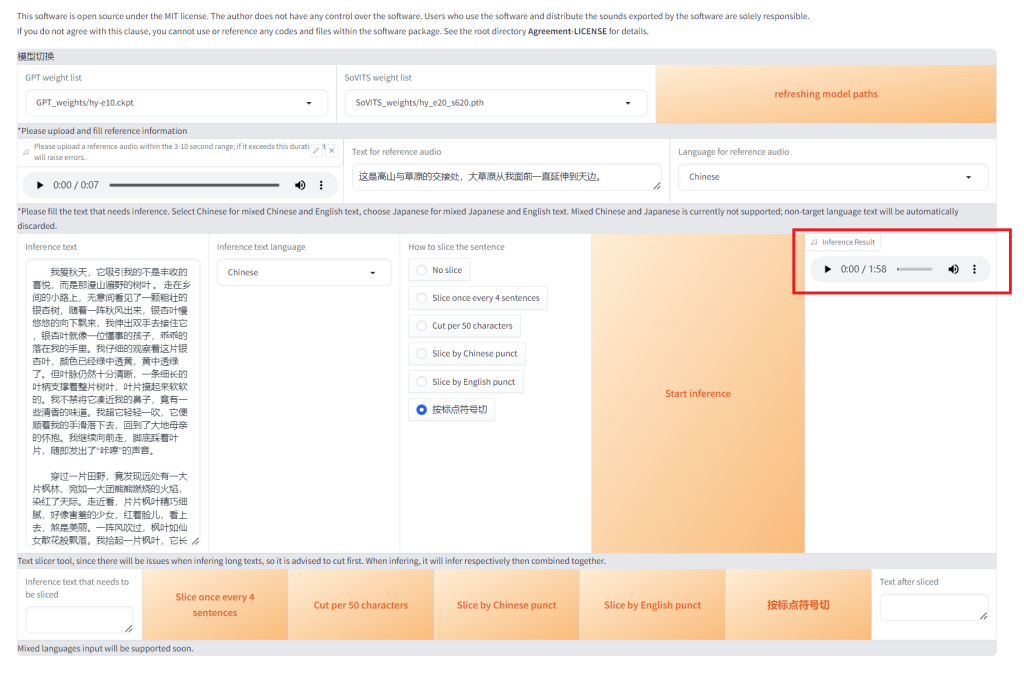
参考音频很重要,会学习参考音频中语速和语气,请认真选择。参考音频的文本是参考音频说什么就填什么,必须要填。语种也要对应。 浏览量: 1,807 |
【本文地址】