Python数据分析从入门到进阶:模型评估和选择(含详细代码) |
您所在的位置:网站首页 › 利用python建模 › Python数据分析从入门到进阶:模型评估和选择(含详细代码) |
Python数据分析从入门到进阶:模型评估和选择(含详细代码)
|
引言
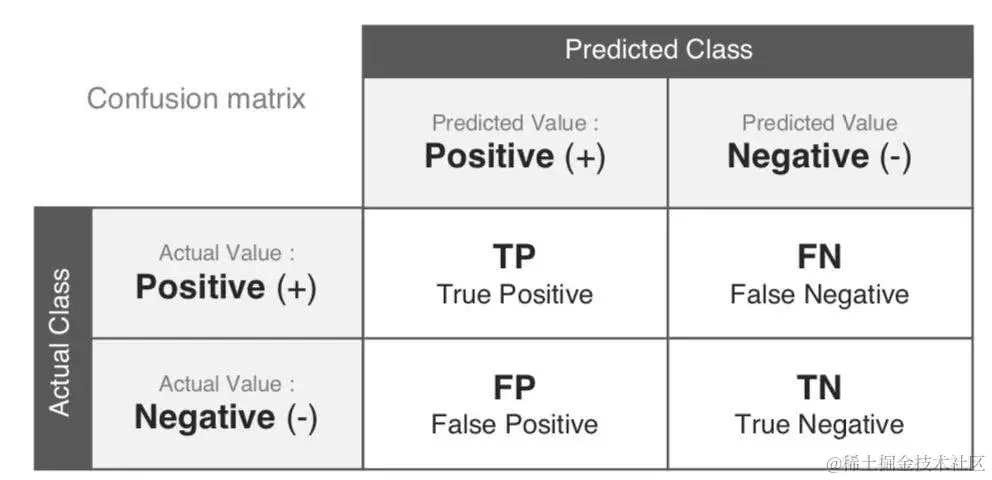
之前我们介绍了机器学习的一些基础性工作,介绍了如何对数据进行预处理,接下来我们可以根据这些数据以及我们的研究目标建立模型。那么如何选择合适的模型呢?首先需要对这些模型的效果进行评估。本文介绍如何使用sklearn代码进行模型评估 模型评估 对模型评估的基本步骤如下: 首先将要将数据集分为训练集和测试集对训练集进行模型拟合确定合适的评估指标计算在测试集上的评估指标 💮1 数据集划分在机器学习问题中,从理论上我们需要对数据集划分为训练集、验证集、测试集。 训练集:拟合模型(平常的作业和测试)验证集:计算验证集误差,选择模型(模拟考)测试集:评估模型(最终考试) 但是在实际应用中,一般分为训练集和测试集两个。其中训练集:70%,测试集:30%.这个比例在深度学习中可以进行相应的调整。 我们可以使用sklearn中的train_test_split划分数据集 # 导入相关库 from sklearn.model_selection import train_test_split from sklearn import datasets from sklearn import metrics from sklearn.model_selection import KFold, cross_val_score from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import StandardScaler import pandas as pd # 导入数据 df = pd.read_csv(r'C:\Users\DELL\data-science-learning\seaborn-data\iris.csv') df.shape (150, 5) # 划分数据集和测试集 train_set, test_set = train_test_split(df, test_size=0.3, random_state=12345) train_set.shape, test_set.shape ((105, 5), (45, 5))可以看出此时训练集只有105个数据,测试集有45个数据。 🏵️2.交叉验证模型评估模型时,我们最常用的方法之一就是交叉验证,具体原理看看我这篇文章统计学习导论(ISLR)(五):重采样方法(交叉验证和bootstrap),下面以一个具体案例来看如何实现,代码如下 # 加载数据 digits = datasets.load_digits() # 创建特征矩阵 features = digits.data target = digits.target # 进行标准化 stand = StandardScaler() # 创建logistic回归器 logistic = LogisticRegression() # 创建一个包含数据标准化和逻辑回归的流水线 pipline = make_pipeline(stand, logistic)# 先对数据进行标准化,再用logistic回归拟合 # 创建k折交叉验证对象 kf = KFold(n_splits=10, shuffle=True, random_state=1)使用shuffle打乱数据,保证我们验证集和训练集是独立同分布的(IID)的 # 进行k折交叉验证 cv_results = cross_val_score(pipline, features, target, cv=kf, scoring='accuracy',#评估的指标 n_jobs=-1)#调用所有的cpu cv_results.mean() 0.9693916821849783使用pipeline方法可以使得我们这个过程很方便,上述我们是直接对数据集进行了交叉验证,在实际应用中,建议先对数据集进行划分,再对训练集使用交叉验证。 from sklearn.model_selection import train_test_split # 划分数据集 features_train, features_test, target_train, target_test = train_test_split(features, target, test_size=0.1,random_state=1) # 使用训练集来计算标准化参数 stand.fit(features_train) StandardScaler() # 然后在训练集和测试集上运用 features_train_std = stand.transform(features_train) features_test_std = stand.transform(features_test)这里之所以这样处理是因为我们的测试集是未知数据,如果使用测试集和训练集一起训练预处理器的话,测试集的信息有一部分就会泄露,因此是不科学的。在这里我认为更general的做法是先将训练集训练模型,用验证集评估选择模型,最后再用训练集和验证集一起来训练选择好的模型,再来在测试集上进行测试。 pipeline = make_pipeline(stand, logistic) cv_results = cross_val_score(pipline, features_train_std, target_train, cv=kf, scoring='accuracy', n_jobs=-1) cv_results.mean() 0.9635112338010889 🌹3.回归模型评估指标评估回归模型的主要指标有以下几个 MAE:平均绝对误差: MAE=1m∑i=1N∣yi−yi∣MAE=\frac{1}{m}\sum_{i=1}{N}|y_i-\hat{y}_i|MAE=m1∑i=1N∣yi−y^i∣MSE:均方误差: MSE=1m∑i=1N(yi−yi)2MSE=\frac{1}{m}\sum_{i=1}{N}(y_i-\hat{y}_i)2MSE=m1∑i=1N(yi−yi)2RMSE: RMSE=1m∑i=1N(yi−yi)2RMSE=\sqrt{\frac{1}{m}\sum_{i=1}{N}(y_i-\hat{y}_i)2}RMSE=m1∑i=1N(yi−yi)2r2: R2=ESSTSSR^2 = \frac{ESS}{TSS}R2=TSSESS 下面我们来看看具体代码 # 导入相关库 from sklearn.datasets import make_regression from sklearn.model_selection import cross_val_score from sklearn.linear_model import LinearRegression from sklearn import metrics # 建立模拟数据集 features, target = make_regression(n_samples=100, n_features=3, n_informative=3, n_targets=1, noise=50, coef=False, random_state=1) # 创建LinerRegression回归器 ols = LinearRegression() metrics.SCORERS.keys() dict_keys(['explained_variance', 'r2', 'max_error', 'neg_median_absolute_error', 'neg_mean_absolute_error', 'neg_mean_absolute_percentage_error', 'neg_mean_squared_error', 'neg_mean_squared_log_error', 'neg_root_mean_squared_error', 'neg_mean_poisson_deviance', 'neg_mean_gamma_deviance', 'accuracy', 'top_k_accuracy', 'roc_auc', 'roc_auc_ovr', 'roc_auc_ovo', 'roc_auc_ovr_weighted', 'roc_auc_ovo_weighted', 'balanced_accuracy', 'average_precision', 'neg_log_loss', 'neg_brier_score', 'adjusted_rand_score', 'rand_score', 'homogeneity_score', 'completeness_score', 'v_measure_score', 'mutual_info_score', 'adjusted_mutual_info_score', 'normalized_mutual_info_score', 'fowlkes_mallows_score', 'precision', 'precision_macro', 'precision_micro', 'precision_samples', 'precision_weighted', 'recall', 'recall_macro', 'recall_micro', 'recall_samples', 'recall_weighted', 'f1', 'f1_macro', 'f1_micro', 'f1_samples', 'f1_weighted', 'jaccard', 'jaccard_macro', 'jaccard_micro', 'jaccard_samples', 'jaccard_weighted']) # 使用MSE对线性回归做交叉验证 cross_val_score(ols, features, target, scoring='neg_mean_squared_error', cv=5) array([-1974.65337976, -2004.54137625, -3935.19355723, -1060.04361386, -1598.74104702]) cross_val_score(ols, features, target, scoring='r2') array([0.8622399 , 0.85838075, 0.74723548, 0.91354743, 0.84469331]) 🌺4.创建一个基准回归模型 from sklearn.datasets import load_boston from sklearn.dummy import DummyRegressor from sklearn.model_selection import train_test_split # 加载数据 boston = load_boston() features, target = boston.data, boston.target # 将数据分为测试集和训练集 features_train, features_test, target_train, target_test = train_test_split(features, target, random_state=0) # 创建dummyregression对象 dummy = DummyRegressor(strategy='mean') # 训练模型 dummy.fit(features_train, target_train) DummyRegressor() dummy.score(features_test, target_test) -0.001119359203955339 # 下面我们训练自己的模型进行对比 from sklearn.linear_model import LinearRegression ols = LinearRegression() ols.fit(features_train, target_train) LinearRegression() ols.score(features_test, target_test) 0.6354638433202129通过与基准模型的对比,我们可以发现我们线性回归模型的优势 🌻5.混淆矩阵评估分类器性能一个重要方法是查看混淆矩阵。一般的想法是计算A类实例被分类为B类的次数,以及B类被预测为A类的个数。要计算混淆矩阵,首先需要有一组预测,以便与实际目标进行比较。混淆矩阵如下图所示:
其中: TP:正确预测正类的个数FP:错误预测正类的个数TN:正确预测负类的个数FN:错误预测负类的个数下面我们来看如何使用具体的代码得到混淆矩阵 # 导入相关库 import matplotlib.pyplot as plt import seaborn as sns from sklearn import datasets from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix import pandas as pd # 加载数据 iris = load_iris() features = iris.data target = iris.target class_names = iris.target_names features_train, features_test, target_train, target_test = train_test_split( features, target, random_state = 1) classfier = LogisticRegression() target_predicted = classfier.fit(features_train, target_train).predict(features_test) # 创建一个混淆矩阵 matrix = confusion_matrix(target_test, target_predicted) df = pd.DataFrame(matrix, index = class_names, columns=class_names) sns.heatmap(df, annot=True, cbar=None, cmap='Blues') plt.ylabel('True Class') plt.xlabel('Predict Class') plt.title('Confusion matrix') Text(0.5, 1.0, 'Confusion matrix') 对于分类问题的评估指标主要包含以下几个: F1-score:21prection+1recall\frac{2}{\frac{1}{prection}+\frac{1}{recall}}prection1+recall12准确率: TP+TNFP+TP+FN+TN\frac{TP + TN}{FP + TP + FN + TN}FP+TP+FN+TNTP+TN召回率:TPTP+FN\frac{TP}{TP+FN}TP+FNTP精确率:TPTP+FP\frac{TP}{TP+FP}TP+FPTP其中,对于非均衡数据,使用F1-score比较合理。下面我们来看具体如何得到这些评估指标 from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.datasets import make_classification # 创建模拟数据集 X, y = make_classification(random_state=1, n_samples=1000, n_features=3, n_informative=3, n_redundant=0, n_classes=2) # 创建逻辑回归器 logit = LogisticRegression() # 使用准确率对模型进行交叉验证 cross_val_score(logit, X, y, scoring='accuracy') array([0.87, 0.88, 0.85, 0.93, 0.9 ]) cross_val_score(logit, X, y, scoring='f1') array([0.87735849, 0.88235294, 0.85849057, 0.92708333, 0.90384615]) cross_val_score(logit,X,y,scoring='precision') array([0.83035714, 0.86538462, 0.8125 , 0.9673913 , 0.86238532])其中,我们可以看出,召回率和精确率两个往往不会同时增加(增加样本量可能可以让两个指标同时增加),这里有点像我们假设检验中的第一类错误和第二类错误。因此,我们要保证这两个指标都不能太小。下面我们介绍ROC和AUC 🌷7.ROC和AUC 🌱7.1 ROC曲线RUC曲线是用于二分类器的另一个常用工具。它与精密度/召回率非常相似,但不是绘制精密度与召回率的关系,而是绘制真阳性率(召回率的另一个名称)与假阳性率(FPR)的关系。FPR是未正确归类为正的负实例的比率。通过ROC曲线来进行评估,计算出每个阈值下的真阳性率和假阳性率 TPR=TP/(TP+FN)TPR = TP/(TP + FN)TPR=TP/(TP+FN)FPR=FP/(FP+TN)FPR = FP/(FP + TN)FPR=FP/(FP+TN) # 导入相关库 import matplotlib.pyplot as plt from sklearn.datasets import make_classification from sklearn.linear_model import LogisticRegression from sklearn.metrics import roc_curve, roc_auc_score from sklearn.model_selection import train_test_split features, target = make_classification(n_samples=1000, n_features=10, n_classes=2, n_informative=3, random_state=3) features_train, features_test, target_train, target_test = train_test_split(features, target, test_size=.1, random_state=1) logit.fit(features_train, target_train) LogisticRegression() # 预测为1的概率 target_probabilities = logit.predict_proba(features_test)[:,1] target_test array([0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1])这里我们选取所有第二列的概率的值,也就是所有为正类的值 false_positive_rate, true_positive_rate, thresholds = roc_curve(target_test,target_probabilities)我们默认是将概率大于50%的判断为正类,但当我们实际应用时,可以对阈值进行相应的调整,例如我们可以增加阈值,保证正类的准确度更高,如下所示 y_predict = target_probabilities>0.6 y_predict array([False, False, True, False, True, True, False, True, False, False, False, True, False, False, False, True, False, False, False, False, True, True, True, False, True, True, True, False, True, False, True, False, True, True, False, False, True, True, True, True, True, False, False, True, False, True, True, False, False, False, False, True, False, False, True, True, True, False, True, False, True, False, False, True, True, False, True, True, True, True, True, True, False, True, False, False, True, False, False, False, False, True, True, False, True, False, True, False, True, False, False, True, False, False, True, False, True, False, False, True]) # 绘制AUC曲线 plt.plot(false_positive_rate, true_positive_rate) plt.plot([0, 1], ls='--') plt.plot([0, 0], [1, 0], c='.7') plt.plot([1,1], c='.7') 比较分类器的一种方法是测量曲线下面积(AUC)。完美分类器的AUC等于1,而适当的随机分类器的AUC等于0.5。Sklearn提供了一个计算AUC的函数roc_auc_score 计算AUC值 roc_auc_score(target_test,target_probabilities) 0.9747899159663865可以看出该分类器的AUC值为0.97,说明该模型的效果很好。 由于ROC曲线与精度/召回(PR)曲线非常相似,您可能想知道如何决定使用哪一条曲线。根据经验,当阳性类别很少,或者当你更关心假阳性而不是假阴性时,你应该更喜欢PR曲线。否则,使用ROC曲线。 🌳8.创建一个基准分类模型 from sklearn.datasets import load_iris from sklearn.dummy import DummyClassifier from sklearn.model_selection import train_test_split iris = load_iris() features, target = iris.data, iris.target # 划分数据集 features_train, features_test, target_train, target_test = train_test_split(features, target, random_state=0) dummy = DummyClassifier(strategy='uniform', random_state=1) dummy.fit(features_train, target_train) DummyClassifier(random_state=1, strategy='uniform') dummy.score(features_test, target_test) 0.42105263157894735 # 接下来我们创建自己的模型 from sklearn.ensemble import RandomForestClassifier#随机森林分类,考虑在后面分享 classfier = RandomForestClassifier() classfier.fit(features_train, target_train) RandomForestClassifier() classfier.score(features_test, target_test) 0.9736842105263158可以看出,随机森林模型效果更好 🌴9.可视化训练集规模的影响我们都知道,只要给我们足够多的数据集,那我们基本能训练一个效果很好的模型,接下来我们来看看如何绘制训练集大小对模型效果的影响(learning curve) import numpy as np import matplotlib.pyplot as plt from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_digits from sklearn.model_selection import learning_curve digits = load_digits() features, target = digits.data, digits.target # 使用交叉验证为不同规模的训练集计算训练和测试得分 train_sizes, train_scores, test_scores = learning_curve(RandomForestClassifier(), features, target, cv=10, scoring='accuracy', n_jobs=-1, train_sizes=np.linspace(0.01,1,50)) # 计算训练集得分的平均值和标准差 train_mean = np.mean(train_scores, axis=1) train_std = np.std(train_scores, axis=1) test_mean = np.mean(test_scores, axis=1) test_std = np.std(test_scores, axis=1) plt.plot(train_sizes, train_mean, '--', color='black', label='Training score') plt.plot(train_sizes, test_mean, color='black', label='Cross-validation score') plt.fill_between(train_sizes, train_mean-train_std, train_mean + train_std, color='#DDDDDD') plt.fill_between(train_sizes, test_mean-test_std, test_mean + test_std, color='#DDDDDD') plt.title('learning_curve') plt.xlabel('Training Set Size') plt.ylabel('Accuracy Score') plt.legend(loc='best') plt.tight_layout() plt.show()
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。 👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击) 
一、Python所有方向的学习路线 Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具 工具都帮大家整理好了,安装就可直接上手! 三、最新Python学习笔记 当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python视频合集 观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例 纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典

👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击) |












【本文地址】