郑轻软工大数据实验(手把手教你入门Hadoop、hbase、spark) |
您所在的位置:网站首页 › 删除hdfs中指定的文件 › 郑轻软工大数据实验(手把手教你入门Hadoop、hbase、spark) |
郑轻软工大数据实验(手把手教你入门Hadoop、hbase、spark)
|
写在最前面,如果你只是来找答案的,那么很遗憾,本文尽量避免给出最后结果,本文适合Linux0基础学生,给出详细的环境配置过程,实验本身其实很简单,供大家一起学习交流。 实验11.编程实现以下指定功能,并利用Hadoop提供的Shell命令完成相同任务: 向HDFS 中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件; 从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名; 将HDFS中指定文件的内容输出到终端中; 显示 HDFS中指定的文件的读写权限、大小、创建时间、路径等信息; 给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息; 提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录; 提供一个 HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录; 向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾; 删除HDFS中指定的文件; 删除HDFS中指定的目录,由用户指定目录中如果存在文件时是否删除目录; 在 HDFS 中,将文件从源路径移动到目的路径。自行下载VMware虚拟机(学校给正版软件) 我使用的是Ubuntu镜像 所有资料:https://pan.baidu.com/s/1uXvuWMKPLBb5hXSMnuB3og?pwd=lgf6 本来想把配好的环境也放网盘的 但是配好环境后26g 所以就不传了 大家加油吧
镜像安装需要一些时间,同时去官方或者网盘里下载 Apache Download Mirrors 下好之后怎么安装呢?当然是看官方文档了 Apache Hadoop 3.3.6 – Hadoop: Setting up a Single Node Cluster. 因为是java体系下的东西,所以你需要确保linux里有jdk才可以启动服务。
带图形化界面还是很方便的,不过我们也经常用终端敲命令(就是windows里的cmd)。 sudo apt-get install openjdk-8-jdk输入用户密码 按y继续 sudo是管理员权限 apt是管理下载包的 下载jdk8 sudo apt install vim sudo apt-get install ssh sudo apt-get install pdsh然后下载一个 vim 文本编辑器和 ssh ,和windows上一样下好东西需要配环境变量,这样打开终端就可以用java命令 vim ~/.bashrc这里要注意,vim对新手很不友好 一定要学会怎么用 后面会频繁用的vim 滑倒最下面 按i进入编辑模式 粘贴 export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/ export PATH=$JAVA_HOME/bin:$PATH export PDSH_RCMD_TYPE=ssh然后按 esc 退出编辑模式 再按 :wq 保存退出 如果有权限问题:wq! 强制退出 chmod 777 xxx 命令可以修改权限 7代表可读可写可执行 三个7三个用户组 source ~/.bashrc使用 java -version 看一下有没有成功
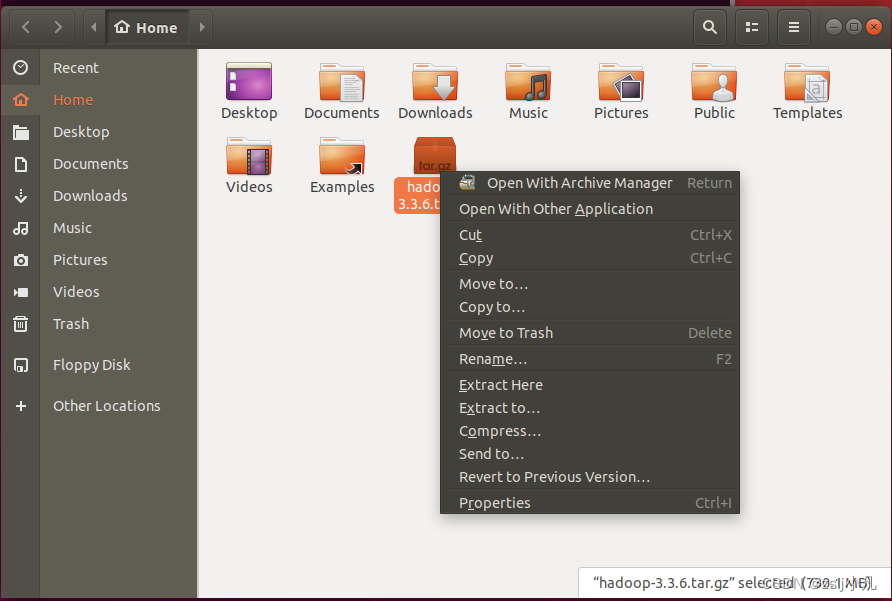
可以使用 tar -zxvf hadoop-3.3.6.tar.gz -C . 解压 -C 注意c是大写 后面写你想解压到的路径 但我们有图形化界面 直接解压 Extract Here 改下名字 hadoop 用命令是mv
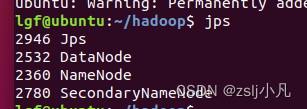
进到hadoop根目录里 然后打开一个终端配置dfs vim etc/hadoop/hadoop-env.sh 到下面找 然后加上java路径 export JAVA_HOME= //你自己java路径vim etc/hadoop/core-site.xml fs.defaultFS hdfs://localhost:9000vim etc/hadoop/hdfs-site.xml dfs.replication 1然后设置ssh ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys 完了ssh localhost试一下 bin/hdfs namenode -format注意 每次重新启动虚拟机都需要执行这个命令进行格式化 然后才能启动hadoop服务 sbin/start-dfs.sh 启动! jps查看运行状态
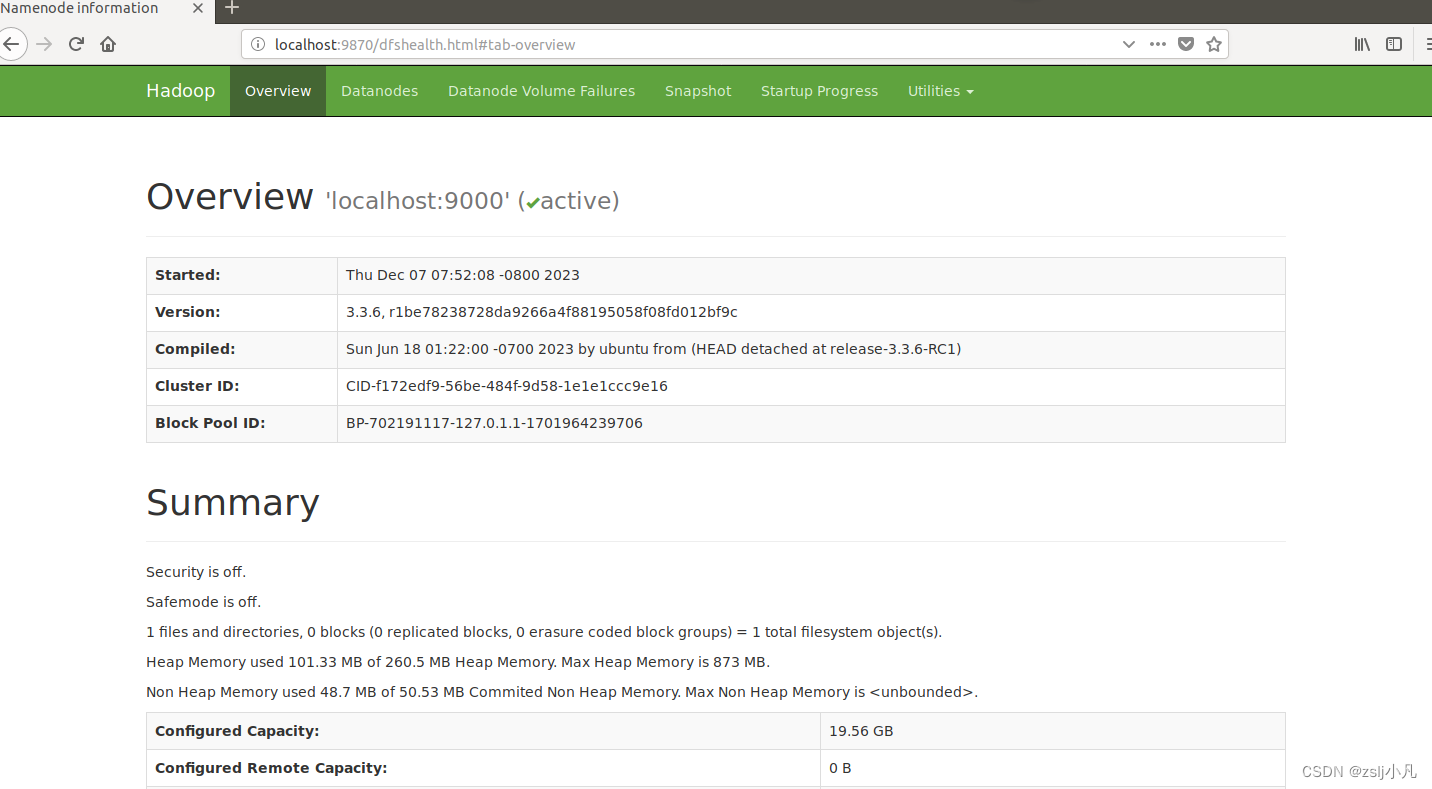
可以使用ifconfig看看本机ip地址 然后在本地浏览器打开 http://localhost:9870/ 或者在虚拟机中的浏览器输入这个网址 如果能打开以下页面 hadoop就配好了
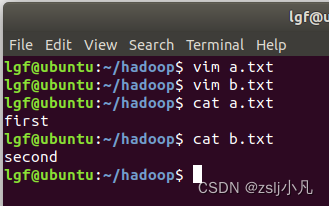
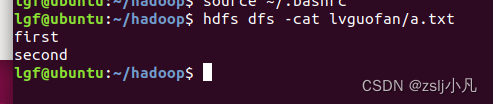
创建两个txt文件 然后配置hdfs环境变量 vim ~/.bashrc export PATH=/home/lgf/hadoop/bin:$PATH //你自己的hadoo路径 source ~/.bashrchdfs dfs -mkdir -p lvguofan 创建文件夹 hdfs dfs -put a.txt lvguofan 上传文件 hdfs dfs -cat lvguofan/b.txt 查看文件内容 hdfs dfs -appendToFile ./b.txt lvguofan/a.txt 追加本地文件到hdfs文件中
hdfs dfs -get lvguofan/a.txt c.txt 下载到本地
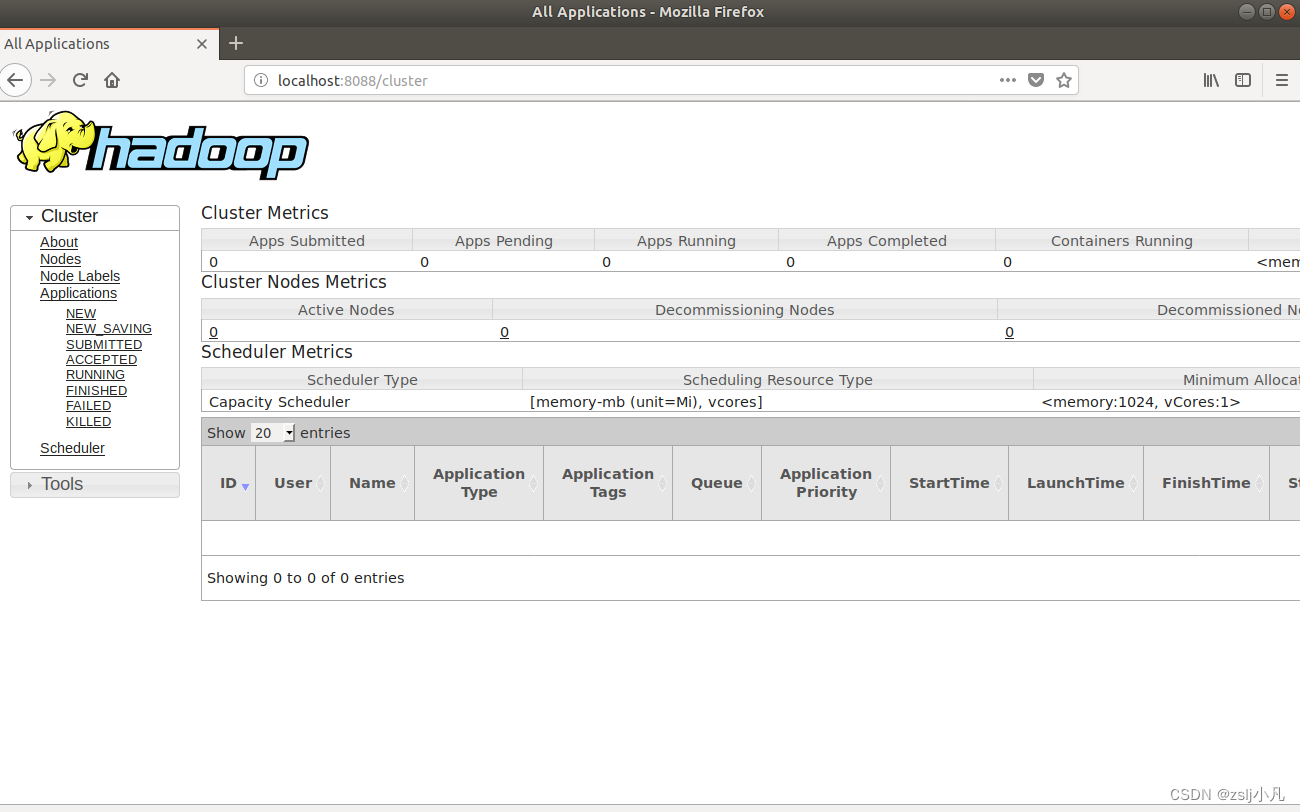
hdfs dfs -ls -h lvguofan/a.txt 看读写权限、大小、创建时间、路径等信息 hdfs dfs -ls -R 遍历所有文件 hdfs dfs -touch lvguofan/test.txt //所在目录不存在时,创建新的空白文件 hdfs dfs -rm -r lvguofan/test.txt //删除文件 hdfs dfs -mv lvguofan/a.txt lgf/a.txt 其他借鉴chatgpt吧 实验21.利用MapReduce编程实现以下功能。 文件合并与去重;对输入的多个文件内容进行排序;跟定表示父子关系的表格,挖掘出祖孙关系,并以表格形式输出。配置yarn 因为mapreduce要用到 vim etc/hadoop/mapred-site.xml mapreduce.framework.name yarn mapreduce.application.classpath $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*vim etc/hadoop/yarn-site.xml yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.env-whitelist JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME sbin/start-yarn.sh 启动!http://localhost:8088/ 如果能打开 yarn就配好了
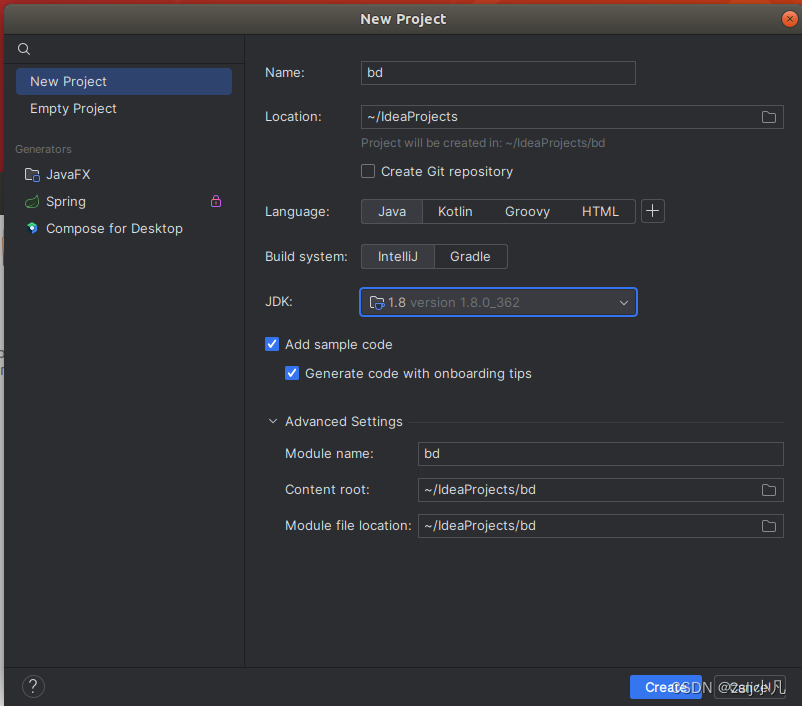
在左侧应用商店或者去官网下载一个Eclipse或者idea 我们用的是x86架构 我用的eclipse 不过也提供idea的安装教程
如果是idea 安装后pwd 记一下路径然后配环境变量
idea.sh 启动!
和windows的一摸一样 创一个工程可以跑通
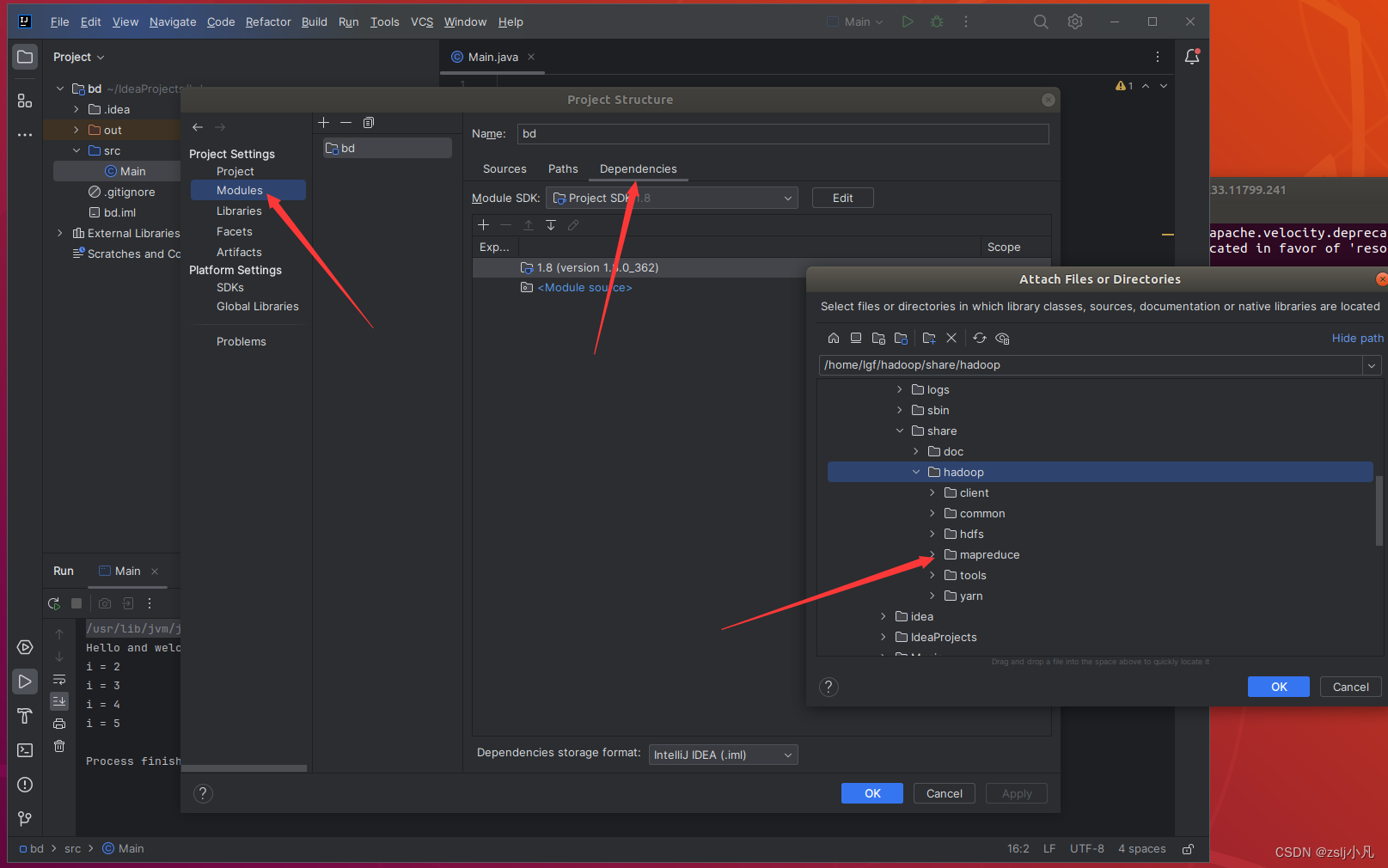
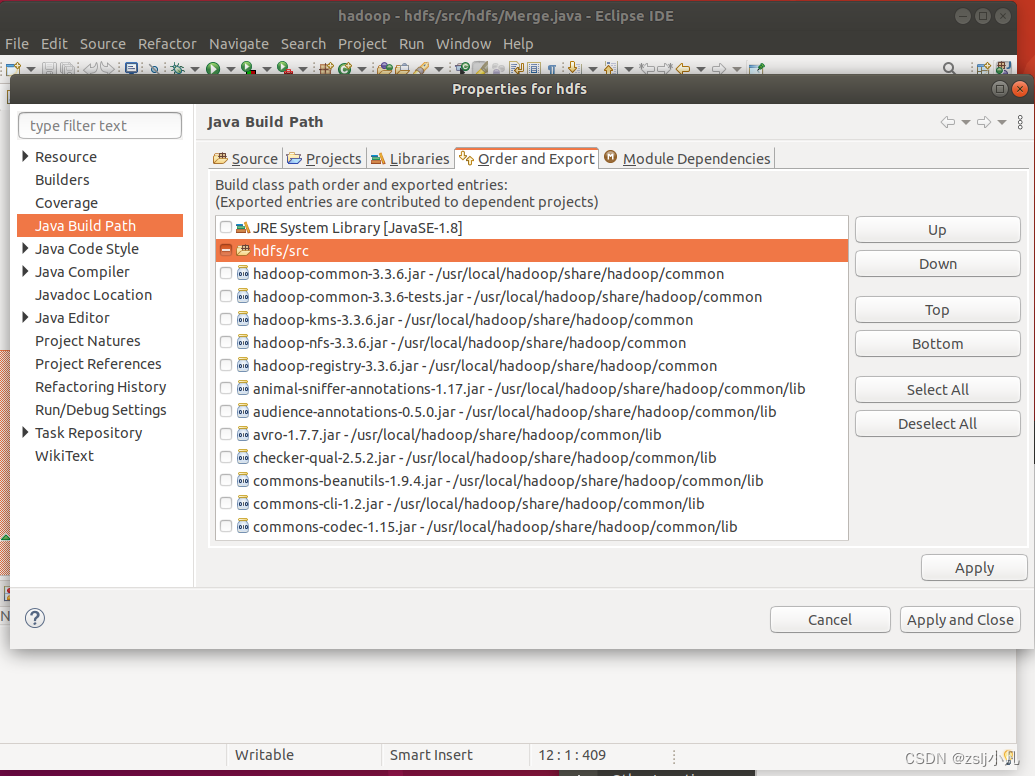
接下来导hadoop根目录里/share/hadoop文件夹中的hdfs、mapreduce、yarn、common的包
其实可以再下一个maven管理包,就不用导包了,挺麻烦还容易出错的。 如果是eclipse也要导包
数据和代码借鉴头歌大数据 文件合并与去重; a.txt first second b.txt second third package hdfs; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Merge { /** * @param args * 对A,B两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C */ //重载map函数,直接将输入中的value复制到输出数据的key上 public static class Map extends Mapper{ private static Text text = new Text(); public void map(Object key, Text value, Context context) throws IOException,InterruptedException{ text = value; context.write(text, new Text("")); } } //重载reduce函数,直接将输入中的key复制到输出数据的key上 public static class Reduce extends Reducer{ public void reduce(Text key, Iterable values, Context context ) throws IOException,InterruptedException{ context.write(key, new Text("")); } } public static void main(String[] args) throws Exception{ // TODO Auto-generated method stub Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://localhost:9000"); String[] otherArgs = new String[]{"/xxx","/out"}; /* 直接设置输入参数 */ if (otherArgs.length != 2) { System.err.println("Usage: wordcount "); System.exit(2); } Job job = Job.getInstance(conf,"Merge and duplicate removal"); job.setJarByClass(Merge.class); job.setMapperClass(Map.class); job.setCombinerClass(Reduce.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
记得把之前的删了,或者换个位置,别把上个问题的数据也合并了
|






【本文地址】
今日新闻 |
推荐新闻 |