(深入理解)强化学习中的policy |
您所在的位置:网站首页 › 刘建平ddpg › (深入理解)强化学习中的policy |
(深入理解)强化学习中的policy
|
想要知道区别,我们得先知道他们分别是怎么做的。 value-based:输入s,输出Q(s,a) policy-based:输入s,输出p(s,a) 不但如此,还有区别 value-based:输入s,输出Q(s,a)后,我们要选一个动作。其选取方法是: 训练时使用epsilon-greedy(有一定探索)测试时使用argmax Q(s,a)(确定),也就是1-greedy(确定)。policy-based:输入s,输出p(s,a)后,我们要选一个动作。其选取方法是: 训练时根据概率p(s,a)选取动作,因此一开始由于模型什么都没学到,所以相当于随机选取(有探索能力),因而和上面的epsilon-greedy有异曲同工之妙。测试时依然根据根据概率p(s,a)选取动作,由于测试阶段,模型学得差不多了,好的动作往往概率非常高,所以极容易抽中。这又与上面的argmax有异曲同工之妙。所以从上面可以看出区别之外,我们还可以发现,value-based相当于绕过了Q值,不去计算那个东西,原来是用Q值来决策,现在用概率决策,相当于把Q值隐含在概率里了,那么就有了一个问题, 就是:我不能把value-based中的Q(s,a)进行softmax归一化吗?这样不就是概率了吗?不就是policy-based了吗? 解答: 这个操作其实根本不本质,我们想强调的是policy-based不显示建模Q值,而你上面那样做,其实就是显示建模了Q值,然后归一化而已。 另外,另外一个问题是:对Q值进行softmax归一化不一定合适,因为softmax喜欢放大Q值的差别。这跟你的环境和设置的奖励有很大关系,有的时候放大差别是一件好事,但有的时候可能不合理。所以说还不如直接输出概率,不要建模Q值。 总结 大家对上面我说的缕一缕思路。我上面说的大部分是从决策的角度上(输入-》输出)说区别。其实训练这个模型所使用的方法例如损失函数也是完全不一样的。建模了Q值得我们就选那个MSE损失函数对吧,没有建模的比如算法policy-gradient采用的是如下:
其中R表示Q(s,a)值(这里才用上,之前都不用Q,和value-based完全不一样)。 所以说两者的区别已经够明显了吧!两者的经典算法如下: value-based:sarsa,q-learning,DQN policy-based:policy-gradient思想下属的REINFORCE算法 当然了,最近有将两者结合的方法,如下: |
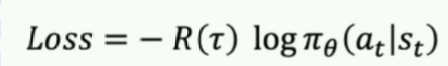

【本文地址】
今日新闻 |
推荐新闻 |