爬取百度国内新冠疫情数据 |
您所在的位置:网站首页 › 刘亚百科 › 爬取百度国内新冠疫情数据 |
爬取百度国内新冠疫情数据
|
一.选课的背景 2020年初,新冠病毒突然爆发并蔓延全国,疫情对我国的经济社会造成巨大的影响。工业、制造业劳动力闲置,产品积压过剩,服务业持续低迷,失业率攀升,物价上涨,一系列连锁反应导致民众心理压力过大,导致社会不稳定的因素颇多,为了能够实时掌握我国疫情的动态,至此我对百度国内疫情实时动态进行监测,了解疫情实时情况。
二:主题式网络爬虫设计方案 爬虫名称:爬取百度国内新冠疫情数据 爬取内容:百度新闻实时疫情数据,对各省所对应的累计确诊人数、死亡人数、治愈人数、现有确诊人数、累计确诊增量、死亡增量、治愈增量和现有确诊增量进行监测。 爬虫设计方案概述(1)requestst:实现网络请求 (2)lxml:实现HTML\XML数据解析 (3)operpyxl:实现对excel的操作 (4)Wordcloud:实现词云图生成 (5)数据清洗 (6)数据可视化
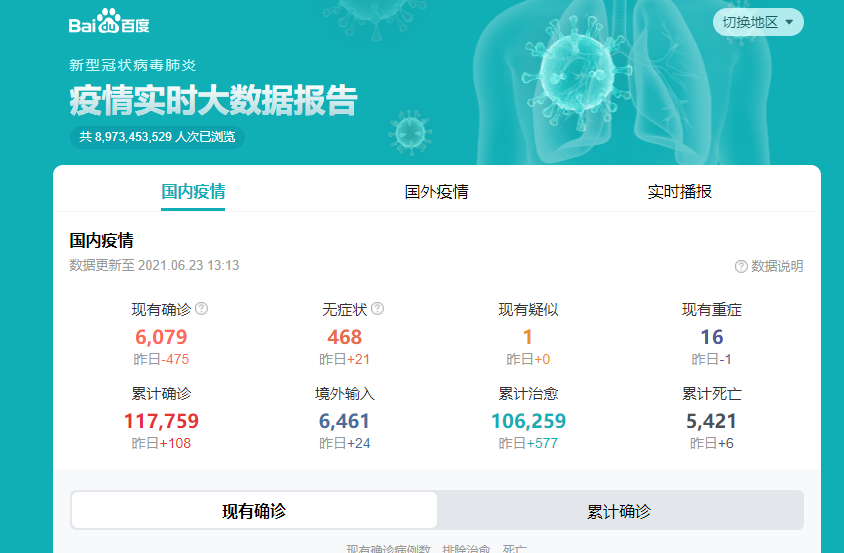
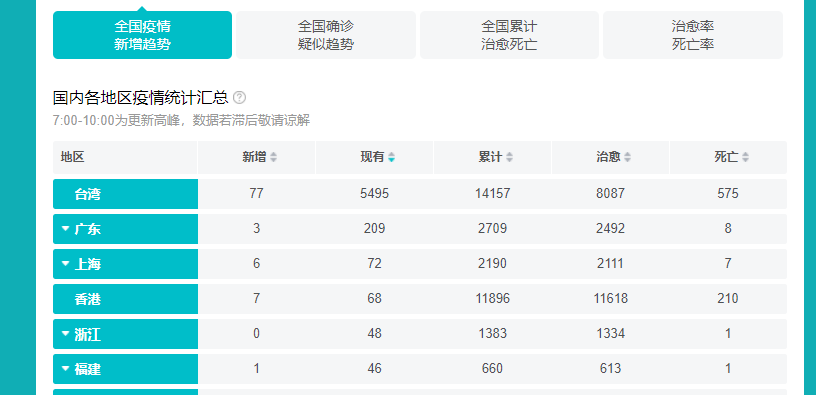
三:主题页面结构分析 1.主题页面结构与特征分析
2.htmls页面解析
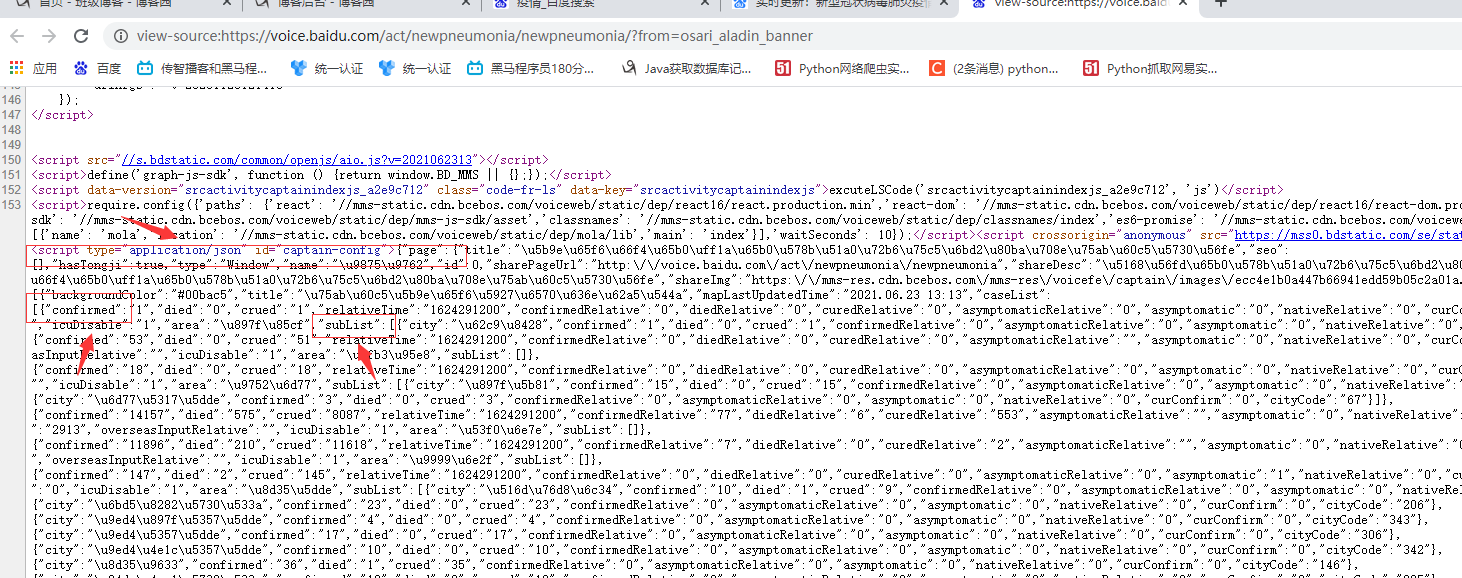
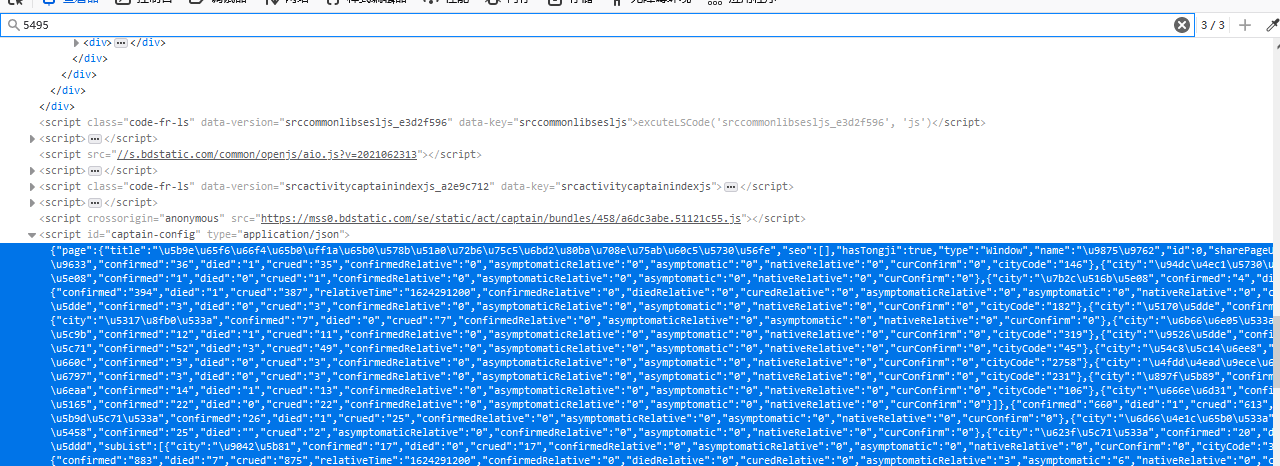
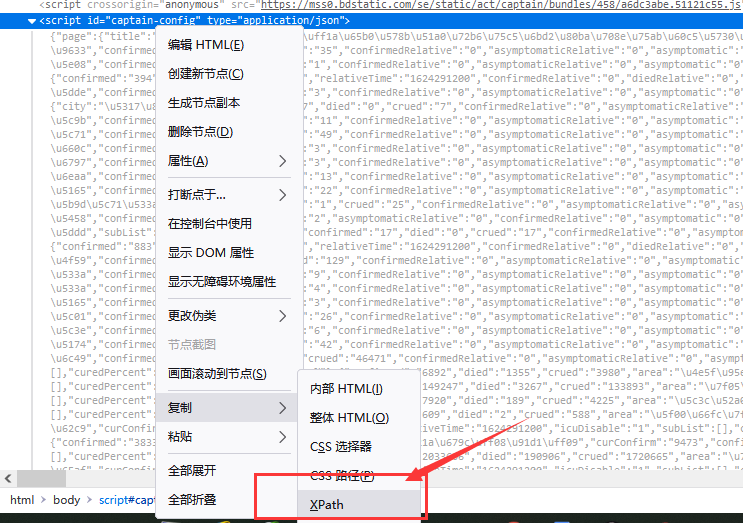
3.节点查找办法(xpath值的获取) (1)点击你需要的任意一个数据 (2)右键点击检查(例如:)
(3)进行搜索,收到对应存储位置即可
(4)点击所在标签,右键复制-->xpath
四.网络爬虫程序设计 1.数据爬取与采集 #导入相关库 import requests #爬取的网址(百度疫情) url="https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_pc_3" #伪装请求头 headers ={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'} #获取网页地址 response=requests.get(url,timeout=30,headers=headers) print(response.text)
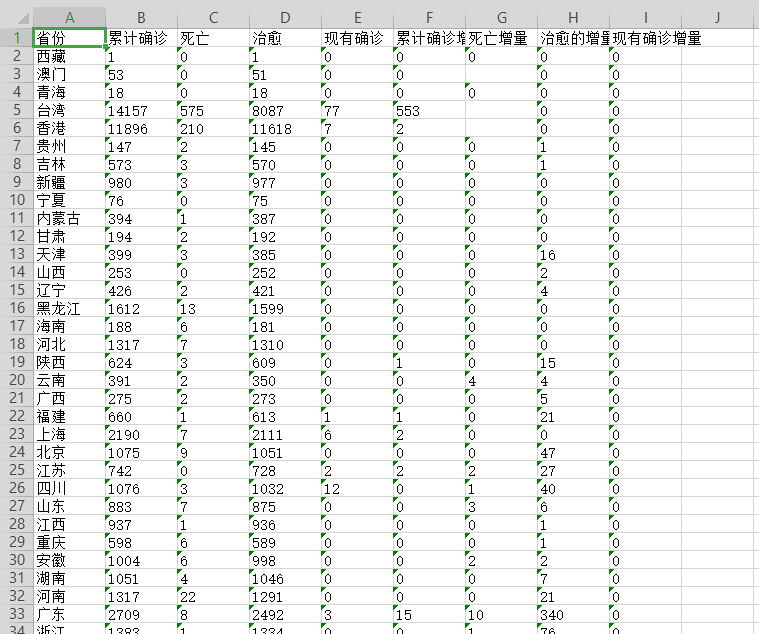
#解析数据内容 from lxml import etree import json from openpyxl import Workbook html=etree.HTML(response.text) #在网页中寻找我们想要的数据(可以找到对应标签右键复制xpath) result=html.xpath('//*[@id="captain-config"]/text()') #print(result) #result[0]不是真正的字典类型,而是json字符串 #需要通过json.loads转化json字符串为Python的字典类型 result=json.loads(result[0]) #print(result) #一层一层找自己所用到的数据 result_out=result["component"][0] #print(result_out) #获取国内疫情数据(找到了 result_in=result["component"][0]["caseList"] print(result_in) #把数据写到excel表格中 #创建工作簿 wb=Workbook() #使用工作表 ws=wb.active #改工作表名字 ws.title="国内疫情" #用append生成表第一行 ws.append(['省份','累计确诊','死亡','治愈','现有确诊', '累计确诊增量','死亡增量','治愈的增量','现有确诊增量']) #循环遍历数据,按照位置顺序,将数据加入到excel中 for each in result_in: temp_list=[each['area'],each['confirmed'],each['died'],each['crued'],each['confirmedRelative'],each['curedRelative'],each['asymptomaticRelative'],each['asymptomatic'],each['nativeRelative']] ws.append(temp_list) wb.save("china_data.xlsx")
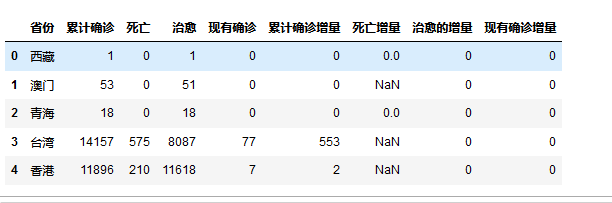
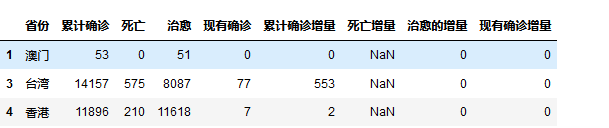
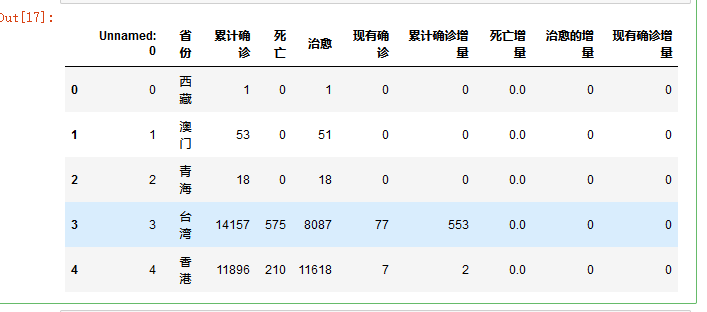
2.对数据进行清洗 #数据请洗 import pandas as pd titanic=pd.DataFrame(pd.read_excel('china_data.xlsx')) titanic.head()
#查看各列数据类型 titanic.info()
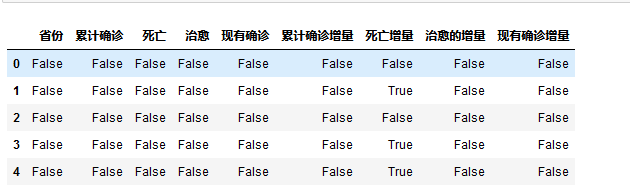
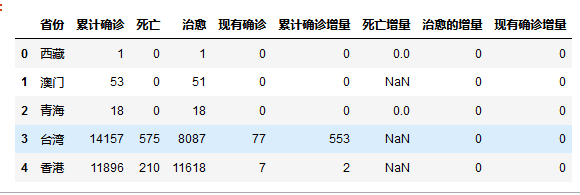
titanic.isnull().head()
#死亡增量有3个空值 titanic['死亡增量'].isnull().value_counts()
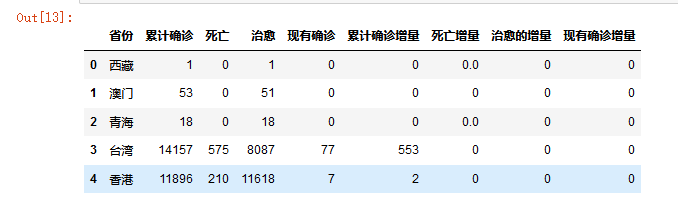
# 使用fillna方法为死亡增量字段填充0 titanic['死亡增量'] = titanic['死亡增量'] .fillna('0') titanic.head()
#数据保存 #在完成数据清洗之后,一般会把结果再以 csv 的格式保存下来,以便后续其他程序的处理。 #同样,Pandas 提供了非常易用的方法: titanic.to_csv('china_data.csv',encoding='utf-8')
3.生成词云图 #读保存数据生成词云 wordcloud #导入需要用的包 from openpyxl import load_workbook from wordcloud import WordCloud #读取文件 wb=load_workbook("china_data.xlsx") ws=wb["国内疫情"] #应为生成一个词云图,需要一个字典格式{词:词频,词:词频} #{省份:累计确诊数} 注:词频是数字类型 #创建一个空字典 free={} #遍历工作表数据 for row in ws.values: #不取省份 if row[0] !="省份": free[row[0]]=int(row[1]) print(free) #生成词云图 wc=WordCloud(font_path="msyh.ttc",width=400,height=600,background_color="white") wc.generate_from_frequencies(free) #保存文件 wc.to_file("国内疫情数据.png") print(wc)
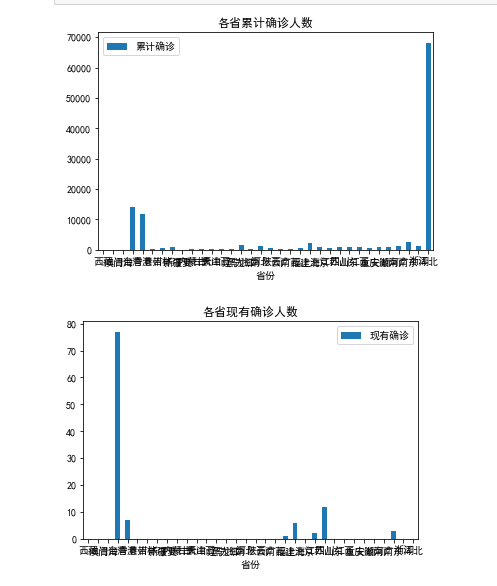
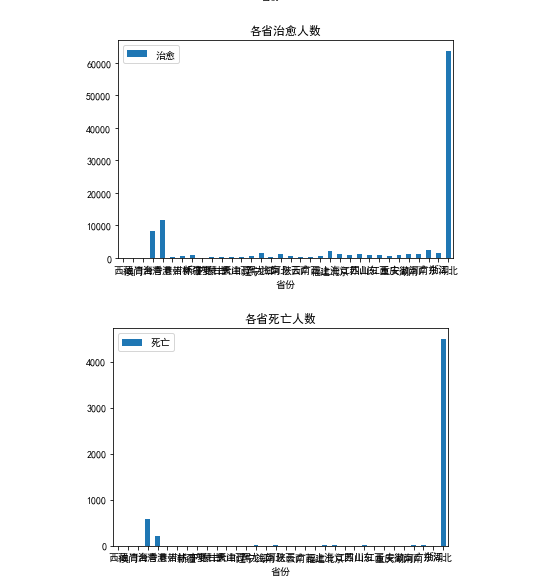
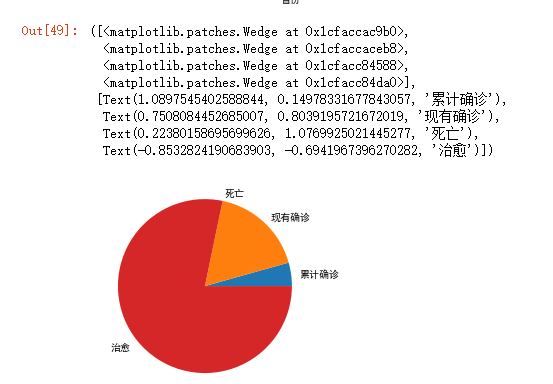
4.数据可视化 #数据分析与可视化 import pandas as pd import matplotlib.pyplot as plt from matplotlib import rcParams #正常显示中文 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus']=False # 绘制各省累计确诊人数垂直柱状图 rcParams['font.family'] = 'simhei' people = pd.read_excel('china_data.xlsx') people.plot.bar(x='省份',y='累计确诊') plt.xticks(rotation=360) plt.title('各省累计确诊人数') plt.show() # 绘制各省现有确诊人数垂直柱状图 rcParams['font.family'] = 'simhei' people = pd.read_excel('china_data.xlsx') people.plot.bar(x='省份',y='现有确诊') plt.xticks(rotation=360) plt.title('各省现有确诊人数') plt.show() # 绘制各省治愈人数垂直柱状图 rcParams['font.family'] = 'simhei' people = pd.read_excel('china_data.xlsx') people.plot.bar(x='省份',y='治愈') plt.xticks(rotation=360) plt.title('各省治愈人数') plt.show() # 绘制各省死亡人数垂直柱状图 rcParams['font.family'] = 'simhei' people = pd.read_excel('china_data.xlsx') people.plot.bar(x='省份',y='死亡') plt.xticks(rotation=360) plt.title('各省死亡人数') plt.show() #绘制累计确诊人数,现有确诊人数,死亡人数,治愈人数的饼图 a=[result_in[0]['confirmed'],result_in[4]['confirmedRelative'], result_in[1]['died'],result_in[2]['crued']] plt.pie(a,labels=['累计确诊','现有确诊','死亡','治愈'])
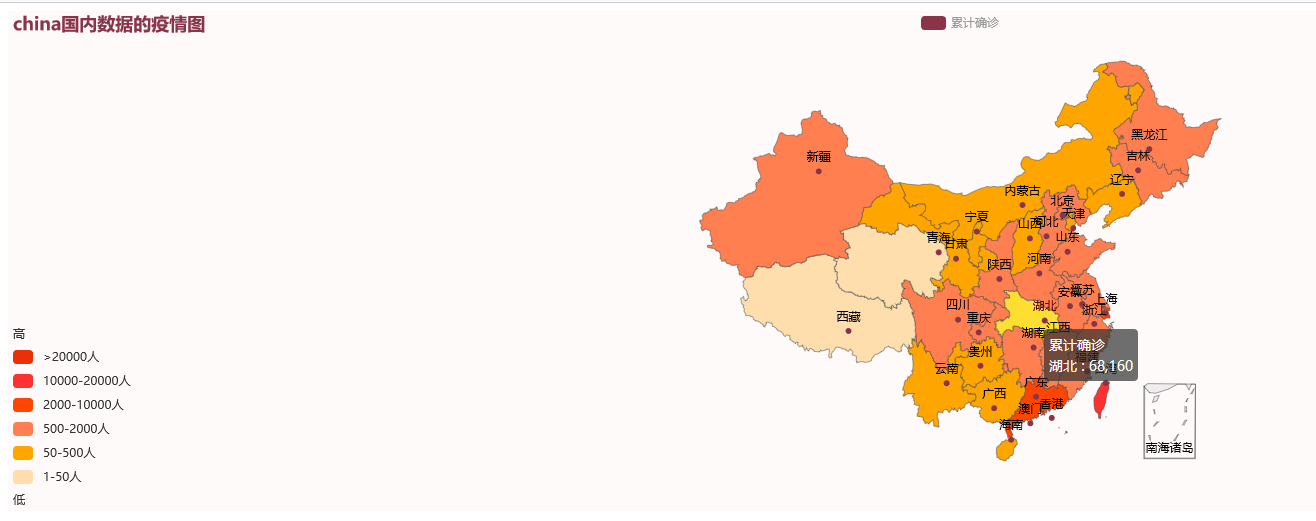
#绘制国内疫情地图 from pyecharts import options as opts from pyecharts.charts import Map from pyecharts.globals import ThemeType # 主题 from snapshot_selenium import snapshot as driver import xlrd filename = 'china_data.xlsx' file = xlrd.open_workbook(filename) sheet = file.sheet_by_name('国内疫情') cityname = sheet.col_values(0) # 获取城市名 #print(cityname) number = sheet.col_values(1) # 获取城市累计确诊人数 #print(number) data = [] for i in range(1, len(cityname)): list = [] list.append(cityname[i]) list.append(number[i]) data.append(list) #print(list) # 设置地图参数 map = ( Map(init_opts=opts.InitOpts(bg_color="#FFFAFA", theme=ThemeType.ESSOS, width="1000")) .add("累计确诊", data) .set_global_opts( title_opts=opts.TitleOpts(title=filename[0:5] + "国内数据的疫情图"), visualmap_opts=opts.VisualMapOpts( is_piecewise=True, # 设置是否为分段显示 # 自定义的每一段的范围,以及每一段的文字,以及每一段的特别的样式。例如: pieces=[ {"min": 20000, "label": '>20000人', "color": "#eb2f06"}, {"min": 10000, "max": 20000, "label": '10000-20000人', "color": "#FF3030"}, # 不指定 max,表示 max 为无限大(Infinity)。 {"min": 2000, "max": 10000, "label": '2000-10000人', "color": "#FF4500"}, {"min": 500, "max": 2000, "label": '500-2000人', "color": "#FF7F50"}, {"min": 50, "max": 500, "label": '50-500人', "color": "#FFA500"}, {"min": 1, "max": 50, "label": '1-50人', "color": "#FFDEAD"}, ], # 两端的文本,如['High', 'Low']。 range_text=['高', '低'], ), ) ) map.render(r'国内疫情.html')
#生成散点图建立回归方程 # 导入包 import numpy as np import pandas as pd import scipy.stats as stats import matplotlib.pyplot as plt import sklearn boston_df=pd.read_csv('china_data.csv') boston_df.head()
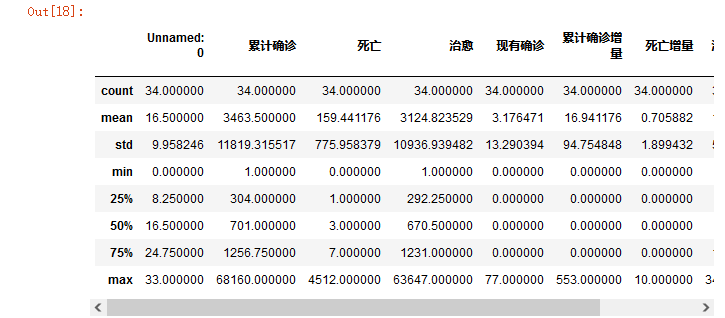
boston_df.describe()
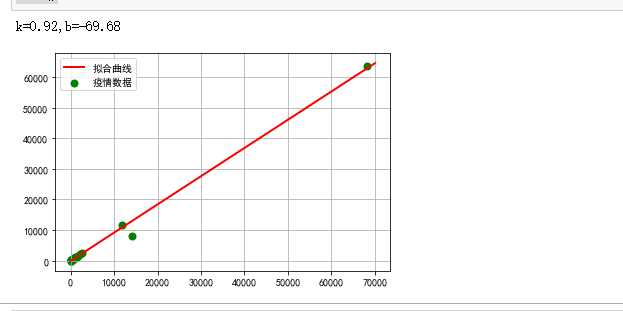
#绘制散点图建立回归方程 from scipy.optimize import leastsq X=boston_df.loc[:,'累计确诊'] Y=boston_df.loc[:,'治愈']#计算相关性 X.corr(Y) def func(params,x): k,b=params return k*x+b #设误差函数 def error(params,x,y): return func(params,x)-y #主程序,输出最后的结果 def main(): plt.figure() p0=[1,1] Para=leastsq(error,p0,args=(X,Y)) k,b=Para[0] print("k={:.2f},b={:.2f}".format(k,b)) plt.scatter(X,Y,color="green",label="疫情数据",linewidth=2) #画拟合曲线 x=np.linspace(1,70000,1000) y=k*x+b plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) plt.legend()#绘制图例 plt.grid() plt.show() main()
5.代码汇总 #导入相关库 import requests import json from openpyxl import Workbook from lxml import etree import pandas as pd from openpyxl import load_workbook from wordcloud import WordCloud import matplotlib.pyplot as plt from matplotlib import rcParams import numpy as np import scipy.stats as stats import sklearn from pyecharts import options as opts from pyecharts.charts import Map from pyecharts.globals import ThemeType # 主题 from snapshot_selenium import snapshot as driver import xlrd #爬取的网址(百度疫情) url="https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_pc_3" #伪装请求头 headers ={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'} #获取网页地址 response=requests.get(url,timeout=30,headers=headers) #print(response.text) #解析数据内容 html=etree.HTML(response.text) #在网页中寻找我们想要的数据(可以找到对应标签右键复制xpath) result=html.xpath('//*[@id="captain-config"]/text()') #print(result) #result[0]不是真正的字典类型,而是json字符串 #需要通过json.loads转化json字符串为Python的字典类型 result=json.loads(result[0]) #print(result) #一层一层找自己所用到的数据 result_out=result["component"][0] #print(result_out) #获取国内疫情数据(找到了) result_in=result["component"][0]["caseList"] print(result_in) #把数据写到excel表格中 #创建工作簿 wb=Workbook() #使用工作表 ws=wb.active #改工作表名字 ws.title="国内疫情" #用append生成表第一行 ws.append(['省份','累计确诊','死亡','治愈','现有确诊', '累计确诊增量','死亡增量','治愈的增量','现有确诊增量']) #循环遍历数据,按照位置顺序,将数据加入到excel中 for each in result_in: temp_list=[each['area'],each['confirmed'],each['died'],each['crued'],each['confirmedRelative'],each['curedRelative'],each['asymptomaticRelative'],each['asymptomatic'],each['nativeRelative']] ws.append(temp_list) wb.save("china_data.xlsx") #数据请洗 titanic=pd.DataFrame(pd.read_excel('china_data.xlsx')) titanic.head() #查看各列数据类型 titanic.info() titanic.isnull().head() #只显示存在缺失值的行列,清楚的确定缺失值的位置 #[titanic.isnull().values==True]是条件表达式 titanic[titanic.isnull().values==True].head() titanic.head()#与上表比较,1和2行没有缺失值,所以不显示 #统计各列的空值情况 print('\n===各列的空值情况如下:===') titanic.isnull().sum() #死亡增量有3个空值 titanic['死亡增量'].isnull().value_counts() # 使用fillna方法为死亡增量字段填充0 titanic['死亡增量'] = titanic['死亡增量'] .fillna('0') titanic.head() #数据保存 #在完成数据清洗之后,一般会把结果再以 csv 的格式保存下来,以便后续其他程序的处理。 #同样,Pandas 提供了非常易用的方法: titanic.to_csv('china_data.csv',encoding='utf-8') #读保存数据生成词云 wordcloud #读取文件 wb=load_workbook("china_data.xlsx") ws=wb["国内疫情"] #应为生成一个词云图,需要一个字典格式{词:词频,词:词频} #{省份:累计确诊数} 注:词频是数字类型 #创建一个空字典 free={} #遍历工作表数据 for row in ws.values: #不取省份 if row[0] !="省份": free[row[0]]=int(row[1]) print(free) #生成词云图 wc=WordCloud(font_path="msyh.ttc",width=400,height=600,background_color="white") wc.generate_from_frequencies(free) #保存文件 wc.to_file("国内疫情数据.png") print(wc) #数据分析与可视化 #正常显示中文 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus']=False # 绘制各省累计确诊人数垂直柱状图 rcParams['font.family'] = 'simhei' people = pd.read_excel('china_data.xlsx') people.plot.bar(x='省份',y='累计确诊') plt.xticks(rotation=360) plt.title('各省累计确诊人数') plt.show() # 绘制各省现有确诊人数垂直柱状图 rcParams['font.family'] = 'simhei' people = pd.read_excel('china_data.xlsx') people.plot.bar(x='省份',y='现有确诊') plt.xticks(rotation=360) plt.title('各省现有确诊人数') plt.show() # 绘制各省治愈人数垂直柱状图 rcParams['font.family'] = 'simhei' people = pd.read_excel('china_data.xlsx') people.plot.bar(x='省份',y='治愈') plt.xticks(rotation=360) plt.title('各省治愈人数') plt.show() # 绘制各省死亡人数垂直柱状图 rcParams['font.family'] = 'simhei' people = pd.read_excel('china_data.xlsx') people.plot.bar(x='省份',y='死亡') plt.xticks(rotation=360) plt.title('各省死亡人数') plt.show() #绘制累计确诊人数,现有确诊人数,死亡人数,治愈人数的饼图 a=[result_in[0]['confirmed'],result_in[4]['confirmedRelative'], result_in[1]['died'],result_in[2]['crued']] plt.pie(a,labels=['累计确诊','现有确诊','死亡','治愈']) #绘制国内疫情地图 filename = 'china_data.xlsx' file = xlrd.open_workbook(filename) sheet = file.sheet_by_name('国内疫情') cityname = sheet.col_values(0) # 获取城市名 #print(cityname) number = sheet.col_values(1) # 获取城市累计确诊人数 #print(number) data = [] for i in range(1, len(cityname)): list = [] list.append(cityname[i]) list.append(number[i]) data.append(list) #print(list) # 设置地图参数 map = ( Map(init_opts=opts.InitOpts(bg_color="#FFFAFA", theme=ThemeType.ESSOS, width="1000")) .add("累计确诊", data) .set_global_opts( title_opts=opts.TitleOpts(title=filename[0:5] + "国内数据的疫情图"), visualmap_opts=opts.VisualMapOpts( is_piecewise=True, # 设置是否为分段显示 # 自定义的每一段的范围,以及每一段的文字,以及每一段的特别的样式。例如: pieces=[ {"min": 20000, "label": '>20000人', "color": "#eb2f06"}, {"min": 10000, "max": 20000, "label": '10000-20000人', "color": "#FF3030"}, # 不指定 max,表示 max 为无限大(Infinity)。 {"min": 2000, "max": 10000, "label": '2000-10000人', "color": "#FF4500"}, {"min": 500, "max": 2000, "label": '500-2000人', "color": "#FF7F50"}, {"min": 50, "max": 500, "label": '50-500人', "color": "#FFA500"}, {"min": 1, "max": 50, "label": '1-50人', "color": "#FFDEAD"}, ], # 两端的文本,如['High', 'Low']。 range_text=['高', '低'], ), ) ) map.render(r'国内疫情.html') #生成散点图建立回归方程 boston_df=pd.read_csv('china_data.csv') boston_df.head() boston_df.describe() #绘制散点图建立回归方程 from scipy.optimize import leastsq X=boston_df.loc[:,'累计确诊'] Y=boston_df.loc[:,'治愈']#计算相关性 X.corr(Y) def func(params,x): k,b=params return k*x+b #设误差函数 def error(params,x,y): return func(params,x)-y #主程序,输出最后的结果 def main(): plt.figure() p0=[1,1] Para=leastsq(error,p0,args=(X,Y)) k,b=Para[0] print("k={:.2f},b={:.2f}".format(k,b)) plt.scatter(X,Y,color="green",label="疫情数据",linewidth=2) #画拟合曲线 x=np.linspace(1,70000,1000) y=k*x+b plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) plt.legend()#绘制图例 plt.grid() plt.show() main() 复制代码
五、总结 1.经过主题数据的分析和可视化,累计确诊人数湖北最高,其次是台湾,而后香港。现有确诊台湾最高,大陆较为安全,达到了预期目标。 2.在这过程中学习到了lxml对HTML\XML数据解析 operpyxl对excel的操作,但是在数据可视化的学习还要进一步的加强。
|









【本文地址】