投影分解法 |
您所在的位置:网站首页 › 分解法计算 › 投影分解法 |
投影分解法
|
一、关系数据理论
1、关系数据库逻辑设计
例子:学校开发一个学校教务的数据库,涉及的对象有: 学生的学号(Sno)、所在系(Sdept)、系主任姓名(Mname)、 课程号(Cno)和成绩(Grade)。 语义: ⒈ 一个系有若干学生, 但一个学生只属于一个系; ⒉ 一个系只有一名主任; ⒊ 一个学生可以选修多门课程, 每门课程有若干学生选修; ⒋ 每个学生所学的每门课程都有一个成绩。 存储并管理这些信息 设计了一个关系模式 STUDENT(Sno ,Sdept, Mname,Cno,Grade) 这样的模式设计会存在一些问题: 1、数据冗余度太大,浪费存储空间。 2、更新异常,如果更换系主任,必须修改每一个元组。 3、插入异常,该插入的数据插不进去。比如新成立软件工程系,但是还没有招生,因为sno不能为空,所以无法插入。 4、删除异常,若计算机的学生都毕业了,在删除学生信息的时候,把系主任的信息也都丢失了。 所以该关系模式不是一个好的关系模式。 好的模式不会发生插入异常、删除异常、更新异常、数据冗余应尽可能少。 上述错误的解决办法: 把这个单一模式分成3个关系模式: S(Sno,Sdept,Sno → Sdept); SC(Sno,Cno,Grade,(Sno,Cno) → Grade); DEPT(Sdept,Mname,Sdept→ Mname) 这3个模式不会发生插入异常、删除异常毛病;数据冗余得到控制。用规范化理论改造关系模式,消除其中不合适的数据依赖。 2、数据依赖 (1)例子在关系STUDENT(Sno ,Sdept, Mname,Cno,Grade)中,存在依赖 F ={ Sno→Sdept, Sdept→Mname, (Sno, Cno)→Grade} 即sno确定,sdept也随之确定,称为数据依赖。 可以用下面的图来表示函数依赖: R(U, D, DOM, F) R:关系名,是符号化的元组语义 U:该关系的属性集合 D:属性组U中属性所来自的域 DOM:属性向域的映象集合 F:属性间数据的依赖关系集合 简化表示R 将关系模式简化为一个三元组,影响数据库模式设计的主要是 U 和 F. 当且仅当U上的一个关系 r 满足F时, r 称为关系模式 R(U, F) 例如在上述例子中: 关系模式 STUDENT U = { Sno,Sdept,Mname,Cno,Grade } F ={ Sno→Sdept, Sdept→Mname, (Sno, Cno)→Grade} 关系模式 STUDENT存在诸多问题 如何解决关系模式中存在的问题? 规范化理论—找出关系模式中不合适的数据依赖,消除它们,可以在不同程度上解决插入异常、删除异常、更新异常和数据冗余问题。 二、规范化 1、函数依赖设R(U)是一个属性集U上的关系模式,X和Y是U的子集。若对于R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等, 而在Y上的属性值不等则称“X 函数确定Y”或“Y 函数依赖于X”,记作X→Y。 X称为这个函数依赖的决定属性组,也称为 决定因素(Determinant)。 例: S(Sno, Sname, Ssex, Sage, Sdept) F= {Sno→Sname,Sno→Ssex,Sno→Sage,Sno→Sdept} 函数依赖在任何条件下都要满足。 2、平凡与非平凡函数依赖
R类:所有依赖关系中仅出现在函数依赖右部的属性。 LR类:所有依赖关系中即出现在函数依赖左部又出现在函数依赖右部的属性。 N类:所有依赖关系中没有出现的属性。 如下图例所示,即为求解过程。 范式是符合某一种级别的关系模式的集合。 1、第一范式(对关系数据库模式的最基本要求)如果一个关系模式R的所有属性都是不可分的基本数据项,则R属于第一范式。 第一范式是对关系模式的最基本要求,不满足第一范式的数据库模式不能成为关系数据模式。 若关系模式R∈1NF,并且每一个非主属性都完全函数依赖于R的码,则R∈2NF。 例如: S-L-C(Sno, Cno, Sdept, Sloc, Grade) ∈1NF S-L-C(Sno, Cno, Sdept,Sloc, Grade) 不属于 2NF 非主属性 Sdept 和 Sloc 部分函数依赖于码( Sno , Cno) 。 上述模式的依赖关系如图所示: 一个关系模式R不属于2NF ,就会产生问题。 插入异常 删除异常 数据冗余过大 同一个学生选修了8门课程,则sdept和sloc的重复次数太多。 修改复杂 在修改学生sdept或sloc时候特别复杂。 出现问题的原因:sdept和sloc部分函数依赖于码,即(Sno,Cno) 所以采用投影分解法,把上述一个关系模式分解为两个: 采用投影分解法,分解为多个2NF的关系模式,可以一定程度上减轻原1NF关系模式中存在的插入异常、删除异常、数据冗余度大、修改复杂等问题。 但是还不能完全消除关系模式中的各种异常情况和数据冗余。 例如:2NF关系模式S-L(Sno, Sdept, Sloc)中,Sloc传递函数依赖于Sno,即S-L中存在非主属性 对码的传递函数依赖Sno→ Sloc 。 插入异常 删除异常 数据冗余度过大 S-L 中Sloc 传递函数依赖于 于Sno ,即:非主属性传递函数依赖码 (3)解决方法采用投影分解法,把S-L 分解为两个 关系模式,以消除传递函数依赖: S-D (Sno , Sdept ) D-L (Sdept , Sloc ) S-D 的码为Sno , D-L 的码为Sdept (4)解决后
关系模式STJ (S ,T ,J )中,S 表示学生,T 表示教师,J 表示课程 假设每一教师只教一门课 T→J 每门课由若干教师教,但某一学生选定某门课,就确定了一个固定的教师 (S ,J )→T 某个学生选修某个教师的课就确定了所选课的名称 (S ,T)→J 主属性J部分函数依赖于(S,T)。因为T→J或者S→J。 (3)解决方法采用投影分解法,将STJ分解为二个关系模式:SJ(S,J);TJ(T,J) (4)解决的问题在分解后的关系模式中没有任何属性对码的部分函数依赖和传递函数依赖。 它解决了上述四个问题: (1) TJ关系中可以存储所开课程尚未有学生选修的教师信息。 (2) 选修过某门课程的学生全部毕业了,只是删除SJ关系中的相应元组,不会响TJ关系中相应教师开设该门课程的信息。 (3) 关于每个教师开设课程的信息只在TJ关系中存储一次。 (4) 某个教师开设的某门课程改名后,只需修改TJ关系中的一个相应元组即可。 (5)BC范式的定义
手工设计法 数据库运行一段时间后常常又不同程度地发现各种问题,增加了维护代价 规范设计法(新奥尔良设计法) 将数据库设计分为若干阶段和步骤,采用辅助手段实现每一过程。按设计规程用工程化方法设计数据库。 基于E-R模型的设计方法 逻辑设计阶段广泛采用 3NF(第三范式)的设计方法 逻辑阶段可采用的有效方法 ODL(Object Definition Language)方法 面向对象的数据库设计方法 UML(Unified Modeling Language)方法 面向对象的建模方法 2、数据库设计的工具SYBASE PowerDesigner 数据库建模-UML工具 3、数据库设计的基本步骤
数据字典是关于数据库中数据的描述,称为元数据。它不是数据本身,而是数据的数据。 由数据项、数据结构、 数据流、数据存储、处理过程组成 ②、数据项数据项是不可再分的数据单位,数据项描述={ 数据项名, 数据项含义说明, 别名, 数据类型, 长度, 取值范围, 取值含义,与其他数据项的逻辑关系, 数据项之间的联系 } 例:学生学籍管理子系统的数据字典。 数据项: 学号 含义说明:唯一标识每个学生 别名: 学生编号 类型: 字符型 长度: 9 取值范围:0000 00 000至9999 99 999 取值含义:前4位标别该学生入学年份,第5第6位所在专业系编号,后3位按顺序编号,例如201615008 与其他数据项的逻辑关系:学号的值确定了其他数据项的值 ③、数据结构数据结构反映了数据之间的组合关系。数据结构描述= {数据结构名,含义说明,组成: {数据项或数据结构} 例:以“学生”为例,写出其数据结构 数据结构:学生 含义说明:学籍管理子系统的主体数据结构, 定义了一个学生的有关信息 组成:学号,姓名,性别,年龄,所在系,年级 ④、数据流数据流是数据结构在系统内部传输的路径。数据流描述={ 数据流名,说明,数据流来源,数据流去向, 组成: {数据结构}, 平均流量,高峰期流量 } 数据流来源:说明该数据流来自哪个处理过程/数据存储 数据流去向:说明该数据流将到哪个处理过程/数据存储去 平均流量:在单位时间(每天、每周、每月等)里的传输次数 高峰期流量:在高峰时期的数据流量 例:数据流“体检结果”可如下描述 数据流: 体检结果 说明: 学生参加体格检查的最终报告 数据流来源:体检(处理过程) 数据流去向:批准(处理过程) 组成: { 学号, {血常规},{尿常规},{血液生化},{心电图}, {B超}, … … {其他体检} } 平均流量: 每天200 高峰期流量:每天400 ⑤、数据存储是数据结构停留或保存的地方,也是数据流的来源和去向之一。数据存储描述={数据存储名,说明,编号,输入的数据流 ,输出的数据流, 组成:{数据结构}, 数据量, 存取频度, 存取方式} 存取频度:每小时、每天或每周存取次数,每次存取的数据量等信息 存取方法:批处理 / 联机处理;检索 / 更新;顺序检索 / 随机检索 输入的数据流:数据来源 输出的数据流:数据去向 例:数据存储“学生登记表”可如下描述 数据存储: 学生登记表 说明: 记录学生的基本情况 流入数据流:每学期5000 流出数据流:每学期5000 组成: {学号,姓名,性别,年龄,所在系,年级,{学习成绩},{体检结果}, {奖惩记录} … … } 数据量: 每年10000张 存取方式: 随机存取+按照专业系/班级打印 ⑥、处理过程具体处理逻辑一般用判定表或判定树来描述。处理过程描述={ 处理过程名, 说明, 输入:{数据流},输出:{数据流}, 处理:{简要说明} } 例:处理过程“分配宿舍”可如下描述 处理过程:分配宿舍 说明:为所有新生分配学生宿舍 输入:学生,宿舍 输出:宿舍安排 处理:在新生报到后,为所有新生分配学生宿舍。 要求同一间宿舍只能安排同一年级同一性别的学生 一个学生只能安排在一个宿舍中。每个学生的居住面积不小于6平方米。 安排新生宿舍其处理时间应不超过15分钟。 六、概念结构的设计 1、概念模型 (1)概念模型的设计将需求分析得到的用户需求抽象为信息结构即概念模型的过程就是概念结构设计。 (2)概念模型的基本概念 ①实体( Entity )客观存在并可相互区别的事物称为实体。 可以是具体的人 、事 、物或抽象的概念。 ② 属性(Attribute )实体所具有的某一特性称为属性 。 一个实体可以由若干个属性来刻画。 ③ 码(Key )唯一标识实体的属性集称为码。 ④实体型(Entity Type )用实体名及其属性名集合来抽象和刻画同类实体称为实体型 ⑤ 实体集(Entity Set )同一类型实体的集合称为实体集 ⑥ 联系(Relationship)现实世界中事物内部以及事物之间的联系在信息世界中反映为实体 ( 型 ) 内部的联系和实体 ( 型 ) 之间的联系。 实体内部的联系: 是指组成实体的各属性之间的联系 实体之间的联系: 通常是指不同实体集之间的联系 实体之间的联系有一对一(1:1)、 一对多(1:m) 和多对多(m:n)型 。 (3)概念模型的描述方法 实体- 联系方法(Entity-Relationship Approach ) 用 用E-R 图来描述现实世界的概念模型 E-R 方法也称为E-R 图 2、E-R模型 (1)实体间的关系 ①一对一联系如果对于实体集A 中的每一个实体,实体集B 中最多有一个(也可以没有)实体与之联系,反之亦然,则称实体集A 与实体集B 具有一对一联系,记为1 ∶1 。 例如,学校里一个班级只有一个正班长,而一个班长只在一个班中任职,则班级与班长之间具有一对一联系。 ②一对多联系如果对于实体集A 中的每一个实体,实体集B 中有n 个实体(n≥0 )与之联系,反之,对于实体集B 中的每一个实体,实体集A 中至多只有一个实体与之联系,则称实体集A 与实体集B 有一对多联系,记为1∶ n。 例如,一个班级中有若干名学生,而每个学生只在一个班级中学习,则班级与学生之间具有一对多联系。 ③多对多联系如果对于实体集A 中的每一个实体,实体集B 中有n 个实体(n≥0 )与之联系,反之,对于实体集B 中的每一个实体,实体集A 中也有m 个实体(m≥0 )与之联系,则称实体集A 与实体集B 具有多对多联系,记为m ∶n。 例如,一门课程同时有若干个学生选修,而一个学生可以同时选修多门课程,则课程与学生之间具有多对多联系。 (2)例题解析 例1:: 某工厂生产若干产品,每种产品由不同的零件组成,有的零件可用在不同的产品。这些零件由不同的原材料制成,不同零件所用的材料可以相同。有的零件可用在不同的产品,这些零件按照所属的不同产品:分别放在仓库中,原材料按照类别放在若干仓库中。请用E-R图画出此工厂产品、零件、材料、仓库的概念模型。 每种产品由不同的零件组成,有的零件可用在不同的产品 产品和零件为多对多的组成关系零件由不同的原材料制成,不同零件所用的材料可以相同 零件和材料为多对多的制造关系原材料按照类别放在若干仓库中 材料和仓库为一对多的存放关系有的零件可用在不同的产品,这些零件按照所属的不同产品分别放在仓库中 仓库和零件为多对多的存储关系 |
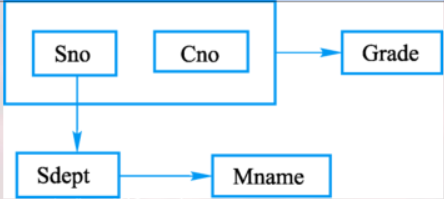 不合适的数据依赖会造成各种异常。
不合适的数据依赖会造成各种异常。





 使用算法求关系R的候选码。 L类:所有依赖关系中仅出现在函数依赖左部的属性。
使用算法求关系R的候选码。 L类:所有依赖关系中仅出现在函数依赖左部的属性。
 例如这个表中,借方和贷方的余额,可以拆成两张表。所以不满足第一范式。
例如这个表中,借方和贷方的余额,可以拆成两张表。所以不满足第一范式。



 此时SC的码为(sno,cno),S-L的码为sno 非主属性为对码为完全函数依赖,所以满足了第二范式。解决了以下的问题:
此时SC的码为(sno,cno),S-L的码为sno 非主属性为对码为完全函数依赖,所以满足了第二范式。解决了以下的问题: 


 等等一系列问题。
等等一系列问题。 在分解后的关系模式中 既没有非主属性对码的部分函数依赖,也没有非主属性对码的传递函数依赖 ,进一步解决了上述四个问题。
在分解后的关系模式中 既没有非主属性对码的部分函数依赖,也没有非主属性对码的传递函数依赖 ,进一步解决了上述四个问题。 采用投影分解法将一个2NF的关系分解为多个3NF的关系,可以在一定程度上解决原2NF关系中存在的插入异常、删除异常、数据冗余度大、修改复杂等问题。 但是,将一个2NF关系分解为多个3NF的关系后,并不能完全消除关系模式中的各种异常情况和数据冗余。
采用投影分解法将一个2NF的关系分解为多个3NF的关系,可以在一定程度上解决原2NF关系中存在的插入异常、删除异常、数据冗余度大、修改复杂等问题。 但是,将一个2NF关系分解为多个3NF的关系后,并不能完全消除关系模式中的各种异常情况和数据冗余。 虽然STJ属于第三范式,但是仍存在异常情况,不是一个理想的关系模式。 (1) 插入异常 据 如果某个教师开设了某门课程,但尚未有学生选修,则有关信息也无法存入数据库中。 (2) 删除异常 如果选修过某门课程的学生全部毕业了,在删除这些学生元组的同时,相应教师开设该门课程的信息也同时丢掉了。 (3) 数据冗余度大 一虽然一个教师只教一门课,但每个选修该教师该门课程的学生元组都要记录这一信息。 (4) 修改复杂 进某个教师开设的某门课程改名后,所有选修了该教师该门课程的学生元组都要进行相应修改。
虽然STJ属于第三范式,但是仍存在异常情况,不是一个理想的关系模式。 (1) 插入异常 据 如果某个教师开设了某门课程,但尚未有学生选修,则有关信息也无法存入数据库中。 (2) 删除异常 如果选修过某门课程的学生全部毕业了,在删除这些学生元组的同时,相应教师开设该门课程的信息也同时丢掉了。 (3) 数据冗余度大 一虽然一个教师只教一门课,但每个选修该教师该门课程的学生元组都要记录这一信息。 (4) 修改复杂 进某个教师开设的某门课程改名后,所有选修了该教师该门课程的学生元组都要进行相应修改。 在上面的STJ关系中,T出现在左边,也为决定因素,但是此关系的码为(S,J)或(S,T),T作为决定因素没有被包含在码中,所以不是BC范式。
在上面的STJ关系中,T出现在左边,也为决定因素,但是此关系的码为(S,J)或(S,T),T作为决定因素没有被包含在码中,所以不是BC范式。



【本文地址】
今日新闻 |
推荐新闻 |