详解sklearn中的r2 |
您所在的位置:网站首页 › 分数的平方怎么算出来 › 详解sklearn中的r2 |
详解sklearn中的r2
|
1.为什么RMSE不便于做过拟合的评判标准?
在机器学习中,在讨论模型的性能时,我们常常会讲,一个好的模型,不仅要在训练集合上有好的表现,在新样本(或测试集)上也有上佳的表现才行。 也就是说,我们要追求模型性能,也要兼顾模型的泛化指标,尽量避免让模型陷入过拟合陷阱。 判断过拟合的一个简单方法就是,在同一种性能标准下,训练集合的误差显著小于在测试集合上的误差。 自然,我们可以利用均方根误差(Root Mean Squared Error,简称RMSE)来衡量模型的好坏,但用它来衡量模型对数据的拟合程度,是有较大的缺陷。 这是因为,RMSE容易受到因变量(目标)和自变量(特征)量纲大小的影响,比如说,A模型中的因变量的数量级都是诸如1000、2000…这样的数值,而B模型中因变量都是1、2…这样数量级的值。 很显然,相对于模型B,A模型中RMSE很可能会比较大,但这不能说明A模型的泛化能力就比第B模型差。 解决上述问题的办法,除了可以做归一化处理之外,我们还可以用另外一个衡量拟合程度的标准——决定系数(coefficient of determination)来刻画。 2. 什么是决定系数?在统计学中,决定系数反映了因变量 假设一数据集包括 于是,回归残差(residual)可定义为:
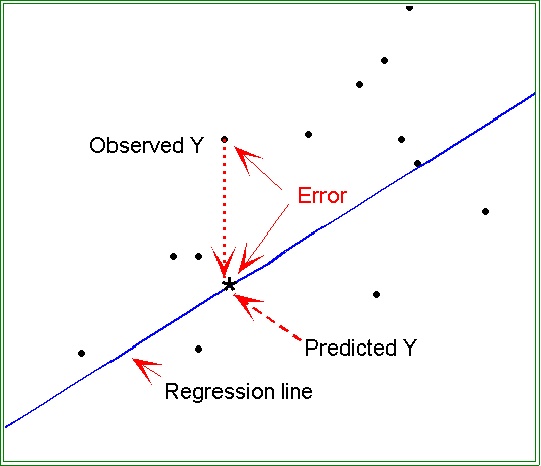
图1 残差示意图 在本质上,残差就是模型的预测误差(实际值-预测值),如图1所示的Error。 那么,平均观察值可定义为:
于是,总体离差平方和(Sum of Squares for total,亦简称SST)为:
回归平方和(Sum of Squares for regression,简称亦SSR)为:
请注意公式(3)和公式(4)的差别。其中, 用数学语言简单描述,决定系数
事实上, 也就是说, 结合公式(5)和(7),推导可得 通常来说,对于训练数据集来说,
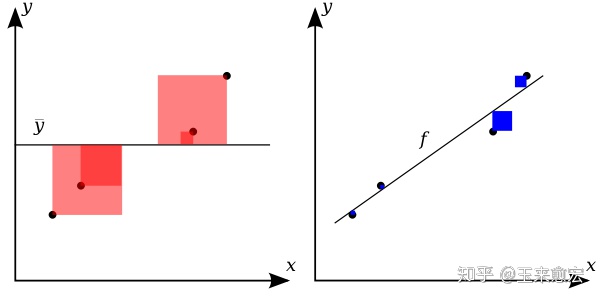
图2 决 定系数示意图 如图2所示,线性回归(右侧子图)的拟合效果很好,蓝色方块的边长代表残差大小,蓝色方块的面积就是残差的平方,很显然,蓝色方块越小,残差就越小,说明拟合的效果越棒! 观察可知,如果 相比而已,图2的右侧子图 红色正方形,它的边长表示因变量( 反之,R²的值越小,说明拟合程度越差。 但具体问题还得具体分析。对时间序列数据, 在Scikit-learn中,回归模型的性能分数,就是利用用 在下面的范例中,我们将分别查看在训练集和测试集中的决定系数。 我们使用皮马印第安人糖尿病数据集(pima Indians Diabetes Data Set)测试。这也是Scikit-learn中一个内置的经典数据集。 在该数据集中,包括442个病人的生理数据及一年以后的病情发展情况。 数据集中的特征值总共10项:年龄、性别、体质指数、血压、s1~s6(6种血清的化验数据)。但需要注意的,以上的数据是经过预处理, 10个特征都做了归一化处理。 第11项数据,是我们的要预测的目标值,一年疾后的病情定量测量,它是一个连续的实数值,符合线性回归模型评估的范畴。 我们可以利用sklearn的常用操作来了解这个数据集合的更多信息。在成功安装Scikit-Learn软件包,只用如下指令即可完成数据的加载: from sklearn.datasets import load_diabetes #导入pima数据的API pima = load_diabetes() #导入数据 pima.keys() #输出该数据集相关的key。运行上述代码,得到结果是: dict_keys(['data', 'target', 'DESCR', 'feature_names', 'data_filename', 'target_filename'])需要指出的是,在Scikit-Learn中,所有内置数据集都有这5个关键字(key),其中,data并不是泛指数据,而是在狭义上指除标签之外的特征数据,针对pima数据集,它指的是前面的10个特征值。 相对而言, target本意是“目标”,这里是指标签数据。针对pima数据集,它指的是我们要预测病情。feature_names给出的是data对应的各个特征的名称。 大写的“DESCR”是对这个数据集的详细描述(description),相当于数据集的说明文档。filename指的就是这个数据集的名称及存储的路径。读者可分别尝试输出这5个关键字,感性认识一下它们的含义。 比如说,我们输出一下这个数据集的data部分(利用Jupyter作为前端): pima.data【输出结果】: array([[ 0.03807591, 0.05068012, 0.06169621, ..., -0.00259226, 0.01990842, -0.01764613], [-0.00188202, -0.04464164, -0.05147406, ..., -0.03949338, -0.06832974, -0.09220405], [ 0.08529891, 0.05068012, 0.04445121, ..., -0.00259226, 0.00286377, -0.02593034], ..., [ 0.04170844, 0.05068012, -0.01590626, ..., -0.01107952, -0.04687948, 0.01549073], [-0.04547248, -0.04464164, 0.03906215, ..., 0.02655962, 0.04452837, -0.02593034], [-0.04547248, -0.04464164, -0.0730303 , ..., -0.03949338, -0.00421986, 0.00306441]])聪慧如你,如果我们想输出第一条数据的第三个特征,就用boston.data[0][2]即可完成数据的输出: pima.data[0][2]【输出结果】 0.0616962065186885如果对这个数据集合比较陌生,或许你想知道,data数据集合中的每条数据都有10个特征,它们分别是什么意思呢?这里我们可以用输出feature_names这个关键字来看看它们的含义: print(pima.feature_names)【输出结果】 ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6'] 当你一一把数据集合的5个key输出,并研读一番,相信你已经能对这个数据了然于心。 好了,言归正卷。下面我们用这个数据集来评估一下线性回归在训练集合和测试集合的『决定系数』,从而在某种程度上推断,拟合的模型是否过拟合了。 【范例】训练集合和测试集合的『决定系数』 from sklearn.datasets import load_diabetes from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression import numpy as np from sklearn.metrics import r2_score #(1)导入数据 X, y = load_diabetes().data, load_diabetes().target #(2)分割数据 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0) #(3)训练 LR = LinearRegression() performance = LR.fit(X_train, y_train) #(4)预测(本例分必要) y_pred_train = LR.predict(X_train) #在测试集合上预测 y_pred_test = LR.predict(X_test) #在测试集合上预测 #(5) 评估模型 print("训练集合上R^2 = {:.3f}".format(performance.score(X_train, y_train))) print("测试集合上R^2 = {:.3f} ".format(performance.score(X_test, y_test))) print("训练集合上R^2 = {:.3f}".format(r2_score(y_train, y_pred_train))) print("测试集合上R^2 = {:.3f} ".format(r2_score(y_test,y_pred_test))) np.set_printoptions(precision = 3, suppress = True) print('w0 = {0:.3f}'.format(LR.intercept_)) print('W = {}'.format(LR.coef_))【运行结果】 训练集合上R^2 = 0.555 测试集合上R^2 = 0.359 训练集合上R^2 = 0.555 测试集合上R^2 = 0.359 w0 = 153.068 W = [ -43.268 -208.671 593.398 302.898 -560.277 261.477 -8.833 135.937 703.227 28.348] 【代码分析】 在本例中,我们利用了Scikit-learn中的普通线性规划模型。从运行结果可以看出,训练集合的拟合优度R2(0.555)高于测试集合(0.359),这是符合预期的。 简单来说,R2→1模型的数据拟合性就越好,反之,R2→0,表明模型的数据拟合度越差。 但如果测试集合和训练集合这二者的R2值差别如果过大,则我们有理由怀疑,训练出来的模型存在一定程度上的过拟合。 此外,我们还可以看到,在模型的评估部分,在训练集合上,performance.score(X_train, y_train))和r2_score(y_train, y_pred_train))的输出结果是一致的。在测试结合上,亦是如此。 这表明,Scikit-learn框架中,性能评估的分数(Score),其实使用的就是『决定系数』( |
【本文地址】
今日新闻 |
推荐新闻 |