Redis和本地缓存的对比:为什么你需要两者兼备? |
您所在的位置:网站首页 › 分布式内存库的优缺点 › Redis和本地缓存的对比:为什么你需要两者兼备? |
Redis和本地缓存的对比:为什么你需要两者兼备?
 封面引言 封面引言在一次面试中,面试官询问我对于本地缓存的运用经验,脑中第一时间闪现出的是Redis,然而经过一番思考,感觉似乎并非完全正确。在犹豫不决之后,我只好回答并无相关经验。回家后,我立即查阅了相关资料,这才发现,原来在本地缓存这个领域,隐藏着如此多的奥妙。 一. Redis 简介The open source, in-memory data store used by millions of developers as a database, cache, streaming engine, and message broker. 简单翻译:被百万开发者作为数据库、缓存、流引擎以及消息代理而使用的开源的,内存型的数据存储软件。 1.1 Redis是什么从官方介绍来看,除了缓存功能外,它还拥有许多引人注目的特性。然而,今天我们将只聚焦于缓存功能的讨论。我第一次了解它时,是将其与MySQL进行对比,它作为一款NoSQL内存型数据库而备受瞩目。考虑到数据库在IO方面存在的瓶颈,以及大多数操作仅涉及读取数据的特性,我们考虑引入一个中间层来缓存部分数据并提供给客户端。 在计算机历史上,一直有这样一种观点,即在任何计算机领域的问题中,都可以通过加入一个中间层来解决。 一般磁盘和内存的独写速度的差值有10X以上 Redis的诞生源于类似的场景。在网站初期,由于访问量较小,使用JavaScript来统计和监控各类数据是可行的。然而,随着数据量的增长,维护的工作量不断增加,磁盘成为了瓶颈。因此,Redis的作者使用C语言编写了这个内存数据库。 Redis之所以叫Redis,因为他的全程是REmote DIctionary Service,解释为远程字典服务。(正好也对应本地)。  特点存储非结构化的数据
由于它是一种字典服务,因此本质上是一种存储非结构化数据(键:值)类型的服务。海量存储和高并发独写
在存储层面,Redis为各种业务提供了丰富的特殊数据结构。此外,作为内存数据库,Redis具有快速的读写性能。分布式
Redis的分布式实现主要依赖于Redis哨兵(Sentinel)和Redis集群(Cluster)这两个核心概念。1.2 Redis的主要功能 特点存储非结构化的数据
由于它是一种字典服务,因此本质上是一种存储非结构化数据(键:值)类型的服务。海量存储和高并发独写
在存储层面,Redis为各种业务提供了丰富的特殊数据结构。此外,作为内存数据库,Redis具有快速的读写性能。分布式
Redis的分布式实现主要依赖于Redis哨兵(Sentinel)和Redis集群(Cluster)这两个核心概念。1.2 Redis的主要功能根据官方简介,其主要功能分为数据库、缓存、流引擎和消息代理四个部分。 Ⅰ作为数据库因为其本身作为内存型数据库,所以断电或者出现故障后,很容易导致数据丢失。那么其本身也设计了策略。就是持久化,分为RDB和AOF。 RDB是在指定的实践间隔内将数据写入硬盘。AOF则会将每一个收到的命令都写入硬盘。那么哪一个更好呢?答案是我全都要。好不好很大程度取决于你的使用场景。适合的才是最好的。  Ⅱ 缓存 Ⅱ 缓存这通常是我们使用Redis最主要的功能,发展至今,在NoSQL数据库上已经没有任何对手。 Ⅲ 流引擎那我就好奇了,什么是流引擎呢? 流引擎是处理持久化、事件驱动的数据流的一种方式。在数据流中,每个事件对应一个数据元素,每个元素在特定的时间间隔内被添加、修改或删除。流引擎通常使用在实时数据处理场景,如消息队列、事件驱动架构、实时数据分析等。 看来它与消息队列(MQ)确实相似,配合Redis的持久化操作,使用起来更加得心应手。在实际应用场景中,它可作为IM(即时通讯)的中间消息流转、Web数据分析和系统日志等。 Ⅳ 消息代理这个功能主要是用来让Redis在多个节点之间进行异步通信和实时的事件驱动的应用。 因为Redis支持发布/订阅模式,所以这作为一个很重要的手段。 当然,这也可以作为微服务的中间代理。 1.3 Redis的应用场景如果光想缓存可以节约什么资源,可能一时间无法回答。但是从Redis的数据结构出发,那么将会有很多灵感。 ① 字符串 分布式锁、全局ID② 哈希 存储对象,购物车信息。③ List列表 消息队列、用户消息时间线④ set集合 抽奖、点赞、签到、打卡、 商品标签 用户关注: 相互关注?交集 我关注的人也关注了他? 交集 可能认识的人?差集这里还有很多案例,这都依托于丰富的数据结构。 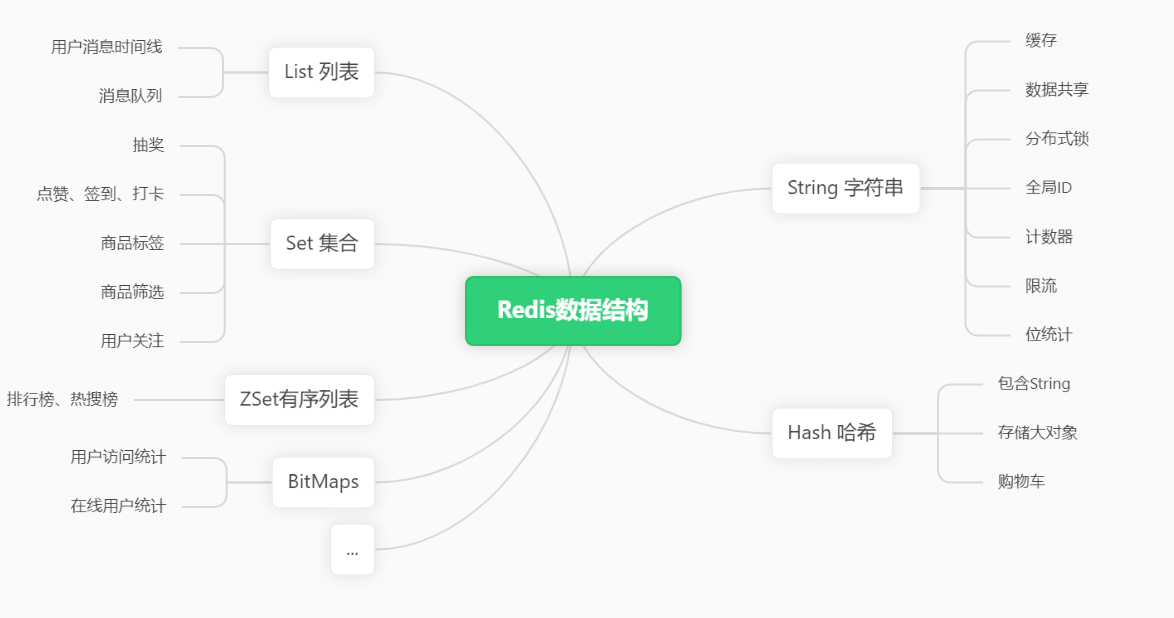 Redis数据结构与功能二. 本地缓存简介 Redis数据结构与功能二. 本地缓存简介在引用远程缓存之前,其实在悄无声息的过程中,隐式的使用了很多缓存,比如ORM的缓存,JDK对字符串的缓存(常量池)。 在Java中对于他的理解,其实就是一种大Map。 2.1 本地缓存如果我们想自己动手实现一种缓存,需要考虑些什么呢? 调用范围。 如果依托于Spring Boot,那么可以在启动类中,注册一下,就可以全局使用了(有点危险)。过期时间 如果长期占用内存,那么必然导致程序崩溃,所得考虑过期消除问题。一致性 这是缓存中很常见的一种问题,关键在于业务是否要对他完全信任,来采取不同策略。并发与锁 JDK提供了JUC包,里面的集合很有用。可扩展性 能够进行插拔应用的再扩展?综合考虑下来,这其实是一个很大的挑战,好在Java的生态足够强大。 2.2 成熟的框架Guava CacheGuava Cache是Google开源的一款本地缓存工具库,设计灵感来源于ConcurrentHashMap,使用多个segments方式的细粒度锁,在保证线程安全的同时,支持高并发场景需求,同时支持多种类型的缓存清理策略,包括基于容量的清理、基于时间的清理、基于引用的清理等。 JUC包的一个重要容器就是ConcurrentHashMap,灵感来自于他,并且锁粒度更细。再加上思考中的全实现,那么,这样的一个框架就诞生了。来自于Google,就有了一定的实力保障。早期一度成为Spring的内置缓存。 CaffeineCaffeine是一个开源的Java缓存库,它能提供高命中率和出色的并发能力。Caffeine通过支持并发和O(1)时间复杂度的数据存取,类似于ConcurrentMap数据结构,但提供了自动移除“不常用”数据的策略,以保持内存的合理占用。 在Caffeine中,数据可以从Java应用程序的本地内存中缓存起来,以提高应用程序的性能和响应速度。Caffeine提供了四种缓存添加策略,包括手动加载,自动加载,手动异步加载和自动异步加载。 由Guava改进,并在Spring 5中成为缓存框架首选,它就是Caffeine,名字和Java都是那么相似。 Java 爪哇岛,当地盛产咖啡。所以Java的图标是一个咖啡的造型。 Caffeine:咖啡因  Java2.2 本地缓存的主要场景 Java2.2 本地缓存的主要场景不止上述框架,其实本地缓存经历了很长一段时间的发展,那么开发者们都用他们都做了什么呢? 数据库缓存 这和远程缓存的想法类似,在ORM框架中,都有这种缓存特性。比如MyBatis的三级缓存。当然,如果缓存不了解,非常容易读取或修改数据造成错乱。网络请求缓存 IO的几个场景之一,网络请求的缓存也是比较重要的一部分。三. 为什么需要两者兼备在对比完两者的优缺点后,相信您已经有了心中的答案。不过在这里,我还是简单说明一下我的观点。 适应不同场景的需要 即使在分布式系统中,框架已经为我们实现了本地缓存的需求,我们仍然需要关注和优化它。 本地缓存:更针对于单个服务/应用,减少IO,提升性能 分布式缓存:适用于更大场景的综合应用,全局性的缓存。成本和效益的权衡 尽管引入新技术可能会带来高收益,但同时也伴随着高风险。因此,企业在开发过程中应注重节约技术成本和运维成本,即使新技术确实很好用。结论无论哪种技术,最适合业务需求的技术才是最好的选择。 我正在参与2023腾讯技术创作特训营第二期有奖征文,瓜分万元奖池和键盘手表 |
【本文地址】
今日新闻 |
推荐新闻 |