ForkJoin从原理设计到使用图解 |
您所在的位置:网站首页 › 分割线的用法图解 › ForkJoin从原理设计到使用图解 |
ForkJoin从原理设计到使用图解
|
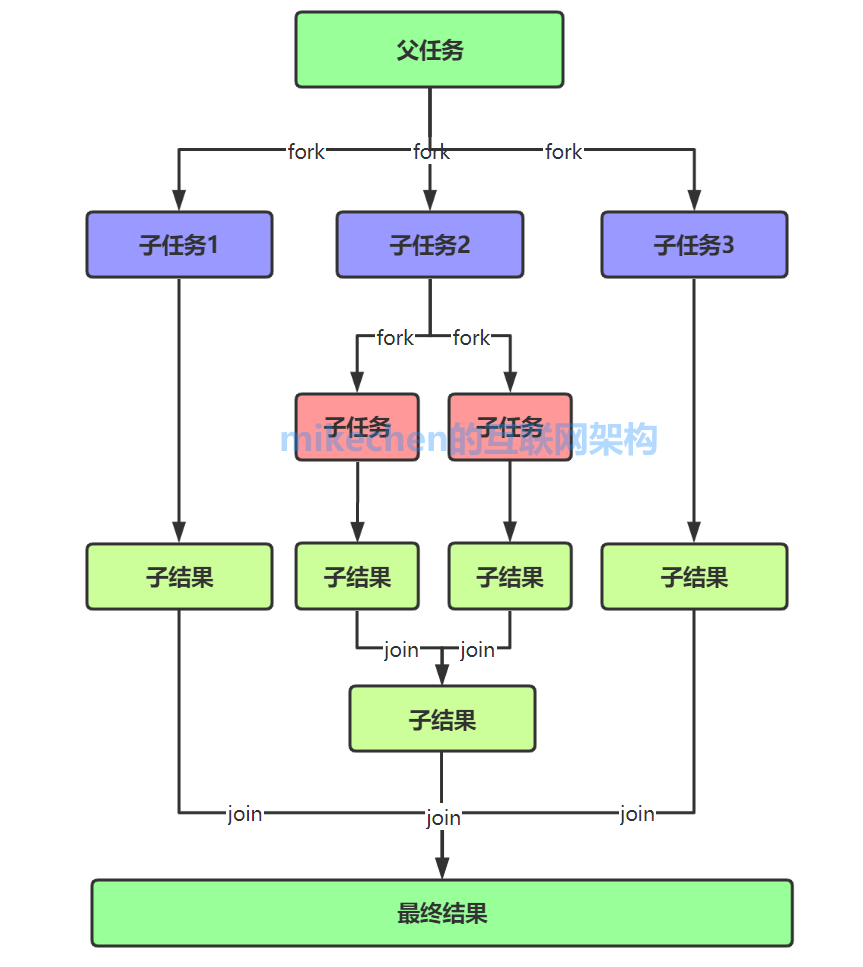
ForkJoin是并发编程中一个比较重要的知识技能,ForkJoin并行框架能方便的利用多核处理器的计算能力实现并发任务的拆分,建议重点掌握。 以下我会从ForkJoin框架的整体设计、原理、算法、以及使用案例来全面详解ForkJoin。 ForkJoin简介从JDK1.7开始,Java提供ForkJoin框架用于并行执行任务,它的思想就是讲一个大任务分割成若干小任务,最终汇总每个小任务的结果得到这个大任务的结果。 Fork-Join执行后会创建一个执行队列;在compute方法中根据实现的分隔规则,分隔出多个子任务,一个子任务对应一个工作线程,并被加入到执行队列中(注意,并不是fork出一个子任务就创建一个子线程,ForkJoinPool的线程数是可以指定的(构造中的parallelism),任务可以拆分成无数个,但实际处理任务的线程数是固定的);执行队列中的任务,正常得到执行结果;如果需要返回结果,会将工作线程的执行结果汇合到一起得到最终结果返回。
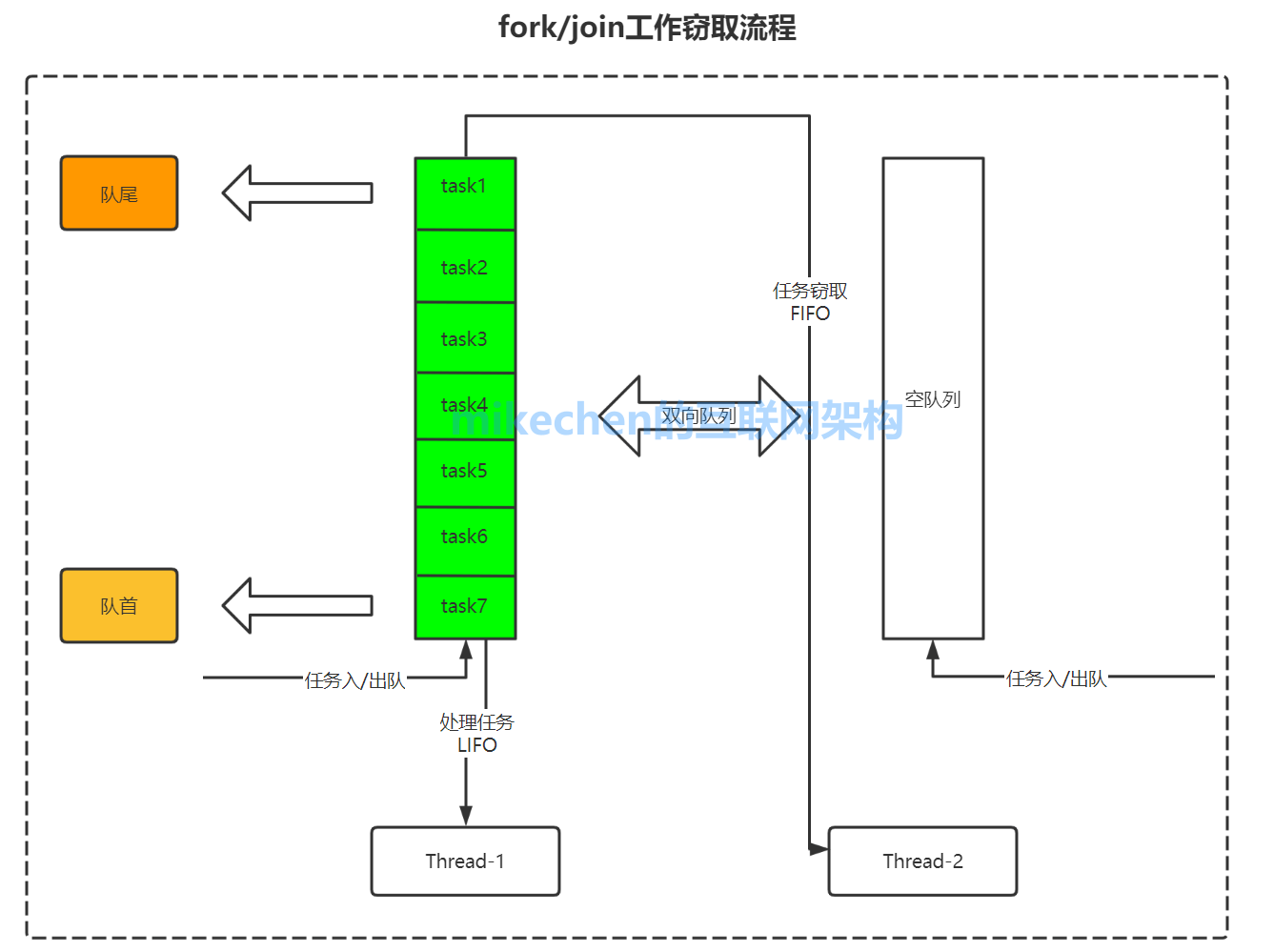
Fork/Join 框架采用了工作窃取(work-stealing)算法来实现,其算法核心是指某个线程从其他队列里窃取任务来执行。 假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。 但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理,干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。 而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行(每个工作线程处理自己的任务使用LIFO,窃取其他工作线程的任务使用FIFO),其工作原理如下图所示:
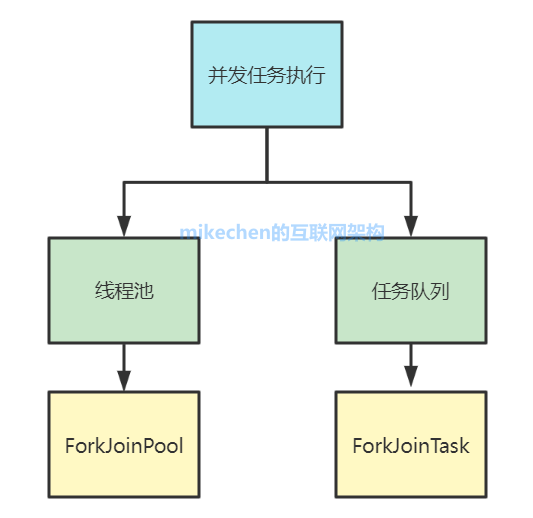
因为当我们需要处理一个大任务时,我们会把这个大任务分割为若干互不依赖的子任务。 为了减少线程间的竞争,我们会把这些子任务分别放到不同的队列里,然后为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。 各个线程执行效率各有差异,为了提高效率,引入“工作窃取算法”,允许“快线程”窃取“慢线程”任务执行 工作窃取算法充分利用多线程进行并行计算,提高了执行效率,同时使用双端队列减少了线程间的冲突竞争,然后不能完全避免冲突,比如某个任务队列中仅有一个任务的时候,两个线程同时竞争。 ForkJoin核心设计除了要了解ForkJoin整个的实现思路, 还需要了解ForkJoin为了实现这个框架定义了哪些角色,并了解这些角色的职责范围是什么的。 ForkJoin框架核心设计类为:任务(ForkJoinTask)和线程池(ForkJoinPool),并发任务执行流程图下图所示:
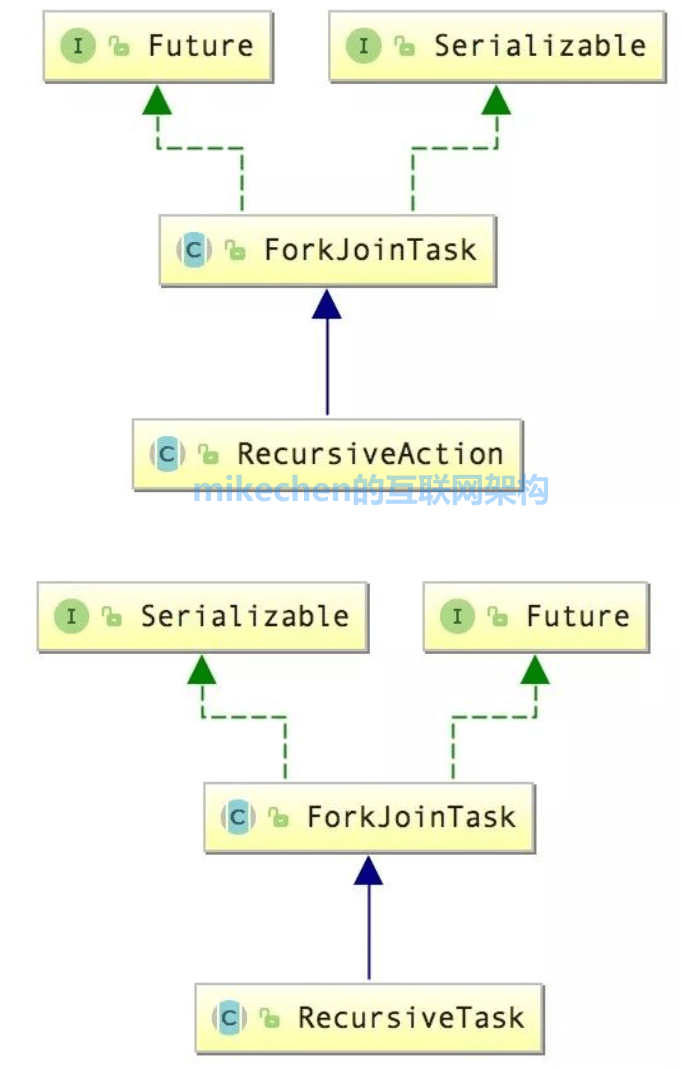
下面分别谈谈两者的核心作用。 ForkJoinPoolForkJoinPool 里有三个重要的角色: ForkJoinWorkerThread(继承 Thread):即WorkerWorkQueue:双向的任务队列ForkJoinTask:Worker 执行的对象既然任务是被逐渐的细化的,那就需要把这些任务存在一个池子里面,这个池子就是ForkJoinPool,充当fork/join框架里面的管理者,最原始的任务都要交给它才能处理。 它负责控制整个fork/join有多少个workerThread,workerThread的创建,激活都是由它来掌控。 它还负责workQueue队列的创建和分配,每当创建一个workerThread,它负责分配相应的workQueue(每个工作线程workerThread都维护一个队列workQueue),然后它把接到的活都交给workerThread去处理,它可以说是整个frok/join的容器。 它与其它的ExecutorService区别主要在于它使用“工作窃取“,主要管理ForkJoin框架里面线程的执行。 ForkJoinTask我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务,而这个类就是一个将在ForkJoinPool中执行的任务的基类。 ForkJoin框架提供了在一个任务里执行fork和join操作的机制和控制任务状态的方法。 通常,为了实现Fork/Join任务,需要实现一个以下两个类之一的子类(继承于ForkJoinTask)。 它的两个子类分别是:RecursiveAction、RecursiveTask,下面简要谈谈两者的区别。 RecursiveAction:是并发包内现成的ForkJoinTask实现之一,继承自ForkJoinTask,负责处理那些不需要返回结果的任务。RecursiveTask:也是并发包内现成的ForkJoinTask实现之一,继承自ForkJoinTask,负责处理那些需要返回结果的任务。这两个区别在于RecursiveTask任务是有返回值,RecursiveAction没有返回值,下面是二者的类图关系结构:
上面主要谈了ForkJoin并发任务执行的核心设计,下面我们就来看看如何去使用ForkJoin。 ForkJoin的使用案例在使用之前,我们需要记住两个概念: ForkJoinTask,我们需要自己定义一个ForkJoinTask,用来定义我们需要执行的任务,它可以继承RecursiveAction或者RecursiveTask,从而获取fork和join操作的能力,前者表示不需要返回值,后者则是需要返回值。ForkJoinPool类似于线程池,连接池的概念,ForkJoinTask都需要交给ForkJoinPool才能执行。 /** * ForkJoin计算1+2+3+4+5+6+7+8 * * @author mikechen */ public class ForkJoinTaskTest extends RecursiveTask { public static final int threshold = 2; private int start; private int end; public ForkJoinTaskTest(int start, int end) { this.start = start; this.end = end; } @Override protected Integer compute() { int sum = 0; //如果任务足够小就计算任务 boolean canCompute = (end - start) |

【本文地址】
今日新闻 |
推荐新闻 |